 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecomposer: Event-roll-guided generative audio editing
Sep 05, 2025Editing complex real-world sound scenes is difficult because individual sound sources overlap in time. Generative models can fill-in missing or corrupted details based on their strong prior understanding of the data domain. We present a system for editing individual sound events within complex scenes able to delete, insert, and enhance individual sound events based on textual edit descriptions (e.g., ``enhance Door'') and a graphical representation of the event timing derived from an ``event roll'' transcription. We present an encoder-decoder transformer working on SoundStream representations, trained on synthetic (input, desired output) audio example pairs formed by adding isolated sound events to dense, real-world backgrounds. Evaluation reveals the importance of each part of the edit descriptions -- action, class, timing. Our work demonstrates ``recomposition'' is an important and practical application.
Dataset balancing can hurt model performance
Jun 30, 2023



Machine learning from training data with a skewed distribution of examples per class can lead to models that favor performance on common classes at the expense of performance on rare ones. AudioSet has a very wide range of priors over its 527 sound event classes. Classification performance on AudioSet is usually evaluated by a simple average over per-class metrics, meaning that performance on rare classes is equal in importance to the performance on common ones. Several recent papers have used dataset balancing techniques to improve performance on AudioSet. We find, however, that while balancing improves performance on the public AudioSet evaluation data it simultaneously hurts performance on an unpublished evaluation set collected under the same conditions. By varying the degree of balancing, we show that its benefits are fragile and depend on the evaluation set. We also do not find evidence indicating that balancing improves rare class performance relative to common classes. We therefore caution against blind application of balancing, as well as against paying too much attention to small improvements on a public evaluation set.
* 5 pages, 3 figures, ICASSP 2023
Audiovisual Masked Autoencoders
Dec 09, 2022



Can we leverage the audiovisual information already present in video to improve self-supervised representation learning? To answer this question, we study various pretraining architectures and objectives within the masked autoencoding framework, motivated by the success of similar methods in natural language and image understanding. We show that we can achieve significant improvements on audiovisual downstream classification tasks, surpassing the state-of-the-art on VGGSound and AudioSet. Furthermore, we can leverage our audiovisual pretraining scheme for multiple unimodal downstream tasks using a single audiovisual pretrained model. We additionally demonstrate the transferability of our representations, achieving state-of-the-art audiovisual results on Epic Kitchens without pretraining specifically for this dataset.
Description and analysis of novelties introduced in DCASE Task 4 2022 on the baseline system
Oct 14, 2022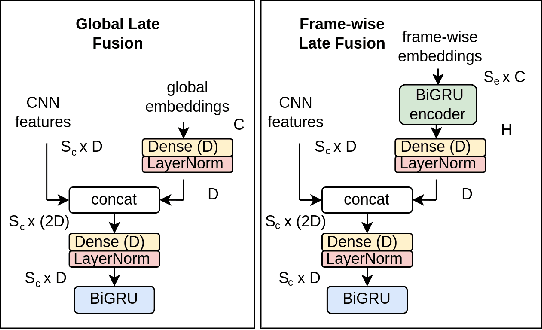
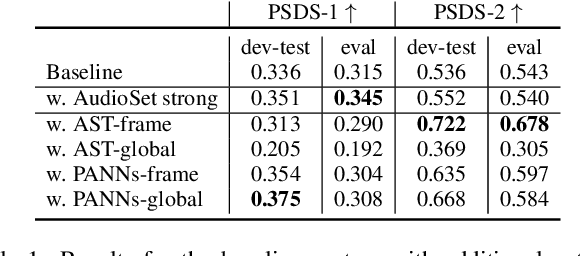
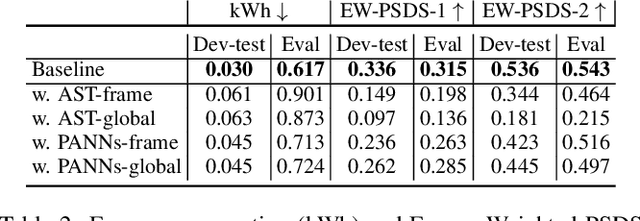
The aim of the Detection and Classification of Acoustic Scenes and Events Challenge Task 4 is to evaluate systems for the detection of sound events in domestic environments using an heterogeneous dataset. The systems need to be able to correctly detect the sound events present in a recorded audio clip, as well as localize the events in time. This year's task is a follow-up of DCASE 2021 Task 4, with some important novelties. The goal of this paper is to describe and motivate these new additions, and report an analysis of their impact on the baseline system. We introduced three main novelties: the use of external datasets, including recently released strongly annotated clips from Audioset, the possibility of leveraging pre-trained models, and a new energy consumption metric to raise awareness about the ecological impact of training sound events detectors. The results on the baseline system show that leveraging open-source pretrained on AudioSet improves the results significantly in terms of event classification but not in terms of event segmentation.
HEAR 2021: Holistic Evaluation of Audio Representations
Mar 26, 2022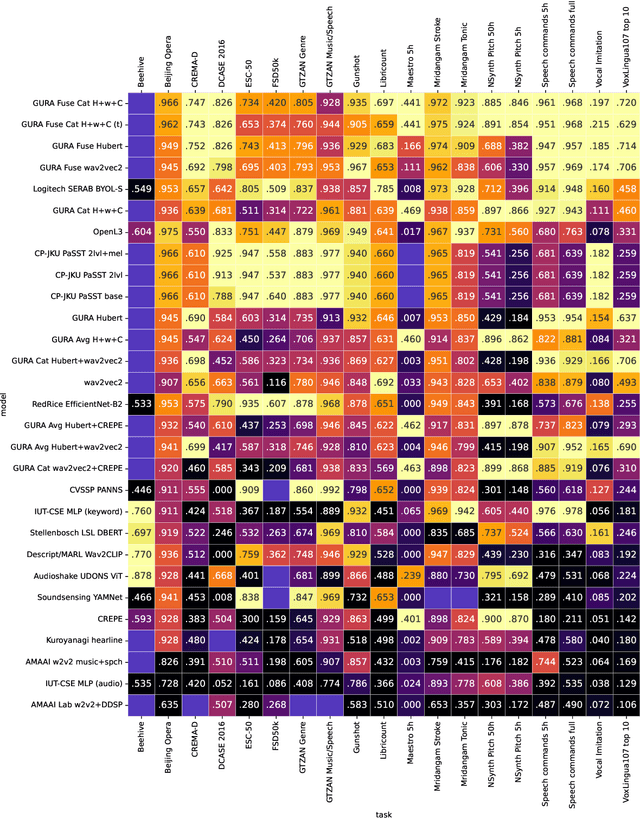
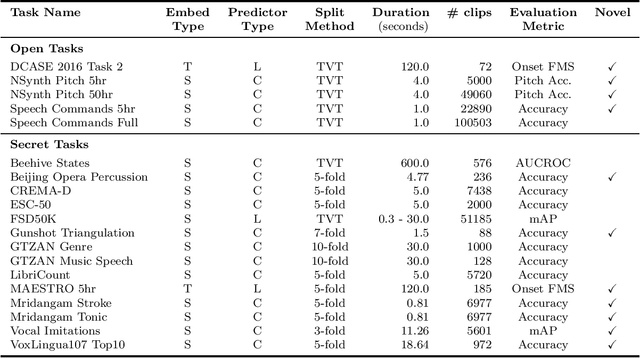

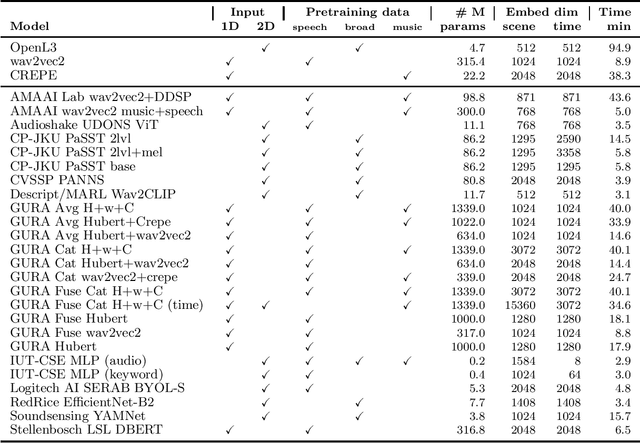
What audio embedding approach generalizes best to a wide range of downstream tasks across a variety of everyday domains without fine-tuning? The aim of the HEAR 2021 NeurIPS challenge is to develop a general-purpose audio representation that provides a strong basis for learning in a wide variety of tasks and scenarios. HEAR 2021 evaluates audio representations using a benchmark suite across a variety of domains, including speech, environmental sound, and music. In the spirit of shared exchange, each participant submitted an audio embedding model following a common API that is general-purpose, open-source, and freely available to use. Twenty-nine models by thirteen external teams were evaluated on nineteen diverse downstream tasks derived from sixteen datasets. Open evaluation code, submitted models and datasets are key contributions, enabling comprehensive and reproducible evaluation, as well as previously impossible longitudinal studies. It still remains an open question whether one single general-purpose audio representation can perform as holistically as the human ear.
Improving Sound Event Classification by Increasing Shift Invariance in Convolutional Neural Networks
Jul 22, 2021
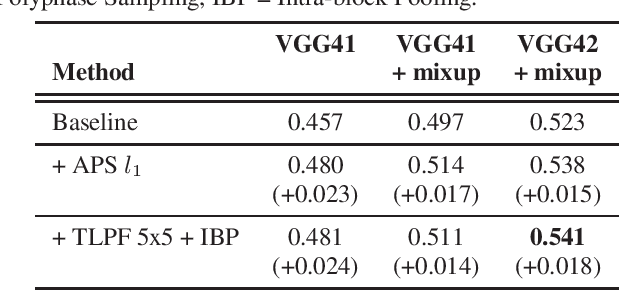

Recent studies have put into question the commonly assumed shift invariance property of convolutional networks, showing that small shifts in the input can affect the output predictions substantially. In this paper, we analyze the benefits of addressing lack of shift invariance in CNN-based sound event classification. Specifically, we evaluate two pooling methods to improve shift invariance in CNNs, based on low-pass filtering and adaptive sampling of incoming feature maps. These methods are implemented via small architectural modifications inserted into the pooling layers of CNNs. We evaluate the effect of these architectural changes on the FSD50K dataset using models of different capacity and in presence of strong regularization. We show that these modifications consistently improve sound event classification in all cases considered. We also demonstrate empirically that the proposed pooling methods increase shift invariance in the network, making it more robust against time/frequency shifts in input spectrograms. This is achieved by adding a negligible amount of trainable parameters, which makes these methods an appealing alternative to conventional pooling layers. The outcome is a new state-of-the-art mAP of 0.541 on the FSD50K classification benchmark.
The Benefit Of Temporally-Strong Labels In Audio Event Classification
May 14, 2021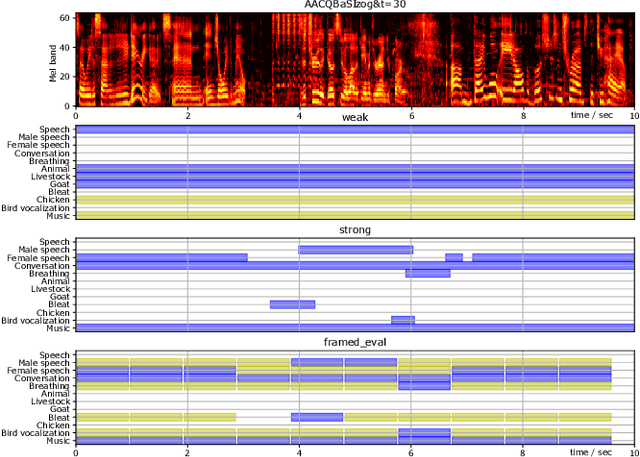
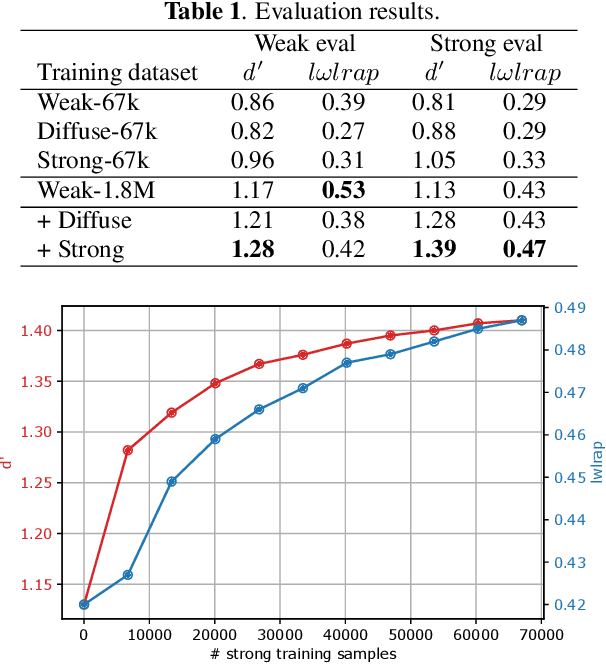
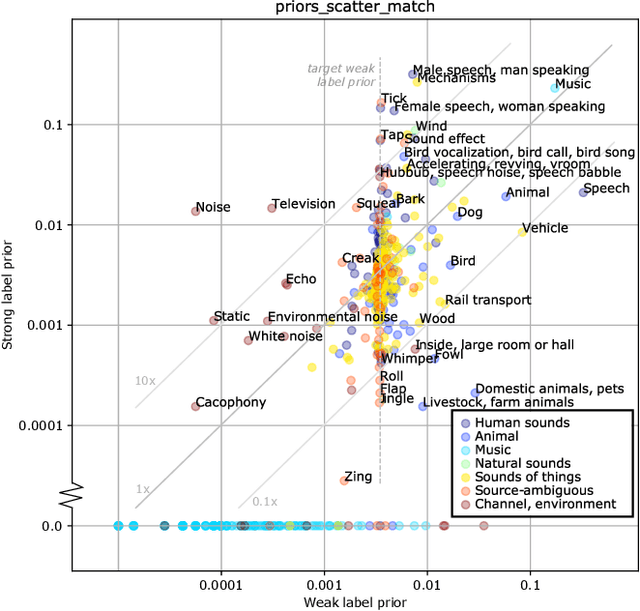
To reveal the importance of temporal precision in ground truth audio event labels, we collected precise (~0.1 sec resolution) "strong" labels for a portion of the AudioSet dataset. We devised a temporally strong evaluation set (including explicit negatives of varying difficulty) and a small strong-labeled training subset of 67k clips (compared to the original dataset's 1.8M clips labeled at 10 sec resolution). We show that fine-tuning with a mix of weak and strongly labeled data can substantially improve classifier performance, even when evaluated using only the original weak labels. For a ResNet50 architecture, d' on the strong evaluation data including explicit negatives improves from 1.13 to 1.41. The new labels are available as an update to AudioSet.
Self-Supervised Learning from Automatically Separated Sound Scenes
May 05, 2021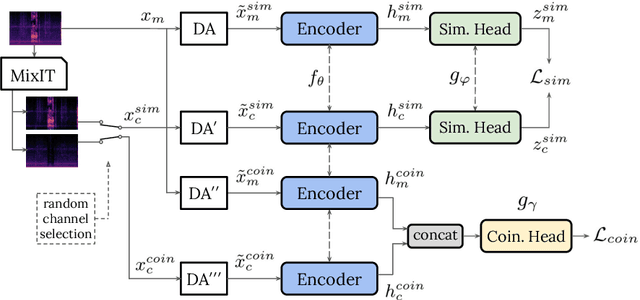
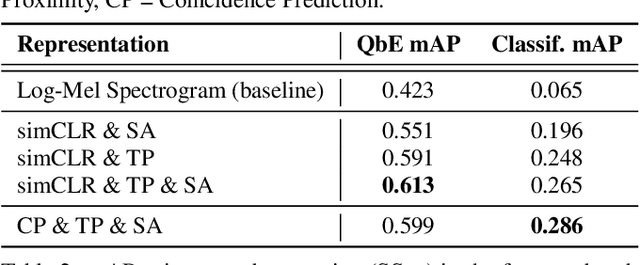

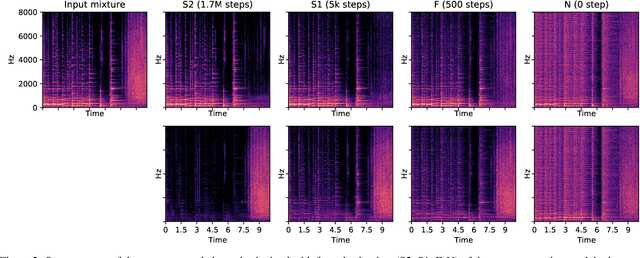
Real-world sound scenes consist of time-varying collections of sound sources, each generating characteristic sound events that are mixed together in audio recordings. The association of these constituent sound events with their mixture and each other is semantically constrained: the sound scene contains the union of source classes and not all classes naturally co-occur. With this motivation, this paper explores the use of unsupervised automatic sound separation to decompose unlabeled sound scenes into multiple semantically-linked views for use in self-supervised contrastive learning. We find that learning to associate input mixtures with their automatically separated outputs yields stronger representations than past approaches that use the mixtures alone. Further, we discover that optimal source separation is not required for successful contrastive learning by demonstrating that a range of separation system convergence states all lead to useful and often complementary example transformations. Our best system incorporates these unsupervised separation models into a single augmentation front-end and jointly optimizes similarity maximization and coincidence prediction objectives across the views. The result is an unsupervised audio representation that rivals state-of-the-art alternatives on the established shallow AudioSet classification benchmark.
Unsupervised Contrastive Learning of Sound Event Representations
Nov 15, 2020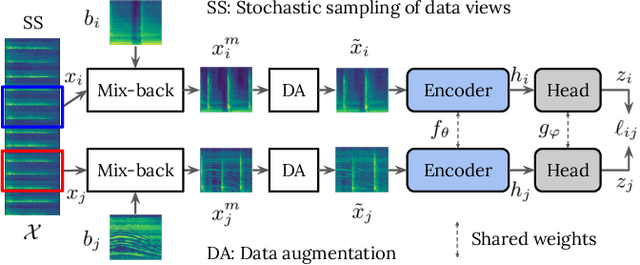

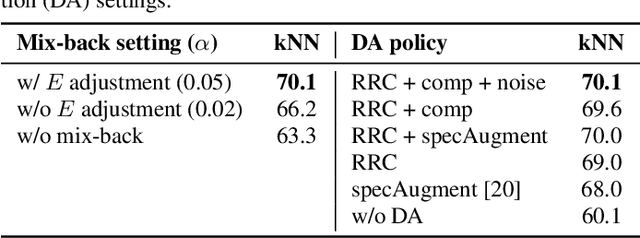
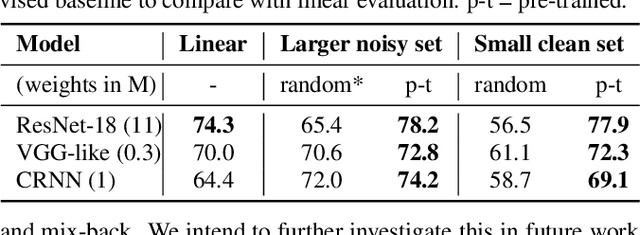
Self-supervised representation learning can mitigate the limitations in recognition tasks with few manually labeled data but abundant unlabeled data---a common scenario in sound event research. In this work, we explore unsupervised contrastive learning as a way to learn sound event representations. To this end, we propose to use the pretext task of contrasting differently augmented views of sound events. The views are computed primarily via mixing of training examples with unrelated backgrounds, followed by other data augmentations. We analyze the main components of our method via ablation experiments. We evaluate the learned representations using linear evaluation, and in two in-domain downstream sound event classification tasks, namely, using limited manually labeled data, and using noisy labeled data. Our results suggest that unsupervised contrastive pre-training can mitigate the impact of data scarcity and increase robustness against noisy labels, outperforming supervised baselines.
FSD50K: an Open Dataset of Human-Labeled Sound Events
Oct 01, 2020
Most existing datasets for sound event recognition (SER) are relatively small and/or domain-specific, with the exception of AudioSet, based on a massive amount of audio tracks from YouTube videos and encompassing over 500 classes of everyday sounds. However, AudioSet is not an open dataset---its release consists of pre-computed audio features (instead of waveforms), which limits the adoption of some SER methods. Downloading the original audio tracks is also problematic due to constituent YouTube videos gradually disappearing and usage rights issues, which casts doubts over the suitability of this resource for systems' benchmarking. To provide an alternative benchmark dataset and thus foster SER research, we introduce FSD50K, an open dataset containing over 51k audio clips totalling over 100h of audio manually labeled using 200 classes drawn from the AudioSet Ontology. The audio clips are licensed under Creative Commons licenses, making the dataset freely distributable (including waveforms). We provide a detailed description of the FSD50K creation process, tailored to the particularities of Freesound data, including challenges encountered and solutions adopted. We include a comprehensive dataset characterization along with discussion of limitations and key factors to allow its audio-informed usage. Finally, we conduct sound event classification experiments to provide baseline systems as well as insight on the main factors to consider when splitting Freesound audio data for SER. Our goal is to develop a dataset to be widely adopted by the community as a new open benchmark for SER research.