 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI systems out-persuade expert humans
Jun 15, 2026Many societal decisions are settled by contests of persuasion. Conversational AI is a powerful new entrant in these contests, but whether it can out-persuade skilled and highly incentivized humans has remained unclear. Here, in a series of four preregistered experiments (n = 18,978 conversations from 6,923 people), we pitted AI systems against a range of human persuaders, including laypeople, winners of a separately preregistered four-round online persuasion tournament, professional canvassers, and world championship debaters. We found that AI systems were reliably more persuasive than expert humans, even when expert humans chose their issues, researched in advance, underwent hours of live, structured practice, and were incentivized with £1,000 cash bonuses. In a follow-up study, AI's advantage persisted after experts received a coaching tool that let them practice against the AI that beat them, review their performance history, and see what AI would have said at key moments. We found converging evidence that AI's advantage stemmed from rapidly deploying larger quantities of information: after coaching, expert humans could tie an AI constrained to respond at human speeds and with human-length messages. In a final study, we show that AI's advantage extends to consequential real-world behavior: AI was nearly 3x more effective than professional canvassers from a UK fundraising firm at raising real-money donations to Save the Children. Together, these results establish that frontier AI systems out-persuade expert humans in conversation, with significant implications for political communication.
The AI Epistemic Deference Index: A Continuous Measure of Sycophancy
Jun 05, 2026Current AI models frequently exhibit epistemic sycophancy, endorsing claims to agree with a user. Existing evaluations typically measure this either by assessing what it takes to make a model shift a binary endorsement or by eliciting an explicit probability in a proposition. However, much user-facing sycophantic behavior is demonstrated through shifts in graded support expressed through ordinary language. We propose the AI Epistemic Deference Index (AEDI): a continuous, unidimensional score representing how sensitive the support expressed in a model's output is to the attitude expressed in a user's prompt. To generate AEDI, we provide a new protocol for estimating probabilities from natural language outputs, using LLMs-as-judges validated for consistency and correlation to human judgment. We deploy it on a new curated database of 500 propositions across diverse topics and 16,000 prompts varying in user attitude, testing eight prominent models. Every model exhibits substantial deference, though with large and systematic differences across providers, with Claude models demonstrating the least, and Grok and Gemini models the most. The effect is amplified in prompts requesting a written artifact, and concentrated on propositions where models hold weaker priors. We release AEDI as an easy-to-update benchmark and measurement pipeline for output-level sycophancy evaluation.
Artificial intelligence can persuade people to take political actions
Apr 10, 2026There is substantial concern about the ability of advanced artificial intelligence to influence people's behaviour. A rapidly growing body of research has found that AI can produce large persuasive effects on people's attitudes, but whether AI can persuade people to take consequential real-world actions has remained unclear. In two large preregistered experiments N=17,950 responses from 14,779 people), we used conversational AI models to persuade participants on a range of attitudinal and behavioural outcomes, including signing real petitions and donating money to charity. We found sizable AI persuasion effects on these behavioural outcomes (e.g. +19.7 percentage points on petition signing). However, we observed no evidence of a correlation between AI persuasion effects on attitudes and behaviour. Moreover, we replicated prior findings that information provision drove effects on attitudes, but found no such evidence for our behavioural outcomes. In a test of eight behavioural persuasion strategies, all outperformed the most effective attitudinal persuasion strategy, but differences among the eight were small. Taken together, these results suggest that previous findings relying on attitudinal outcomes may generalize poorly to behaviour, and therefore risk substantially mischaracterizing the real-world behavioural impact of AI persuasion.
Outcome-based Reinforcement Learning to Predict the Future
May 26, 2025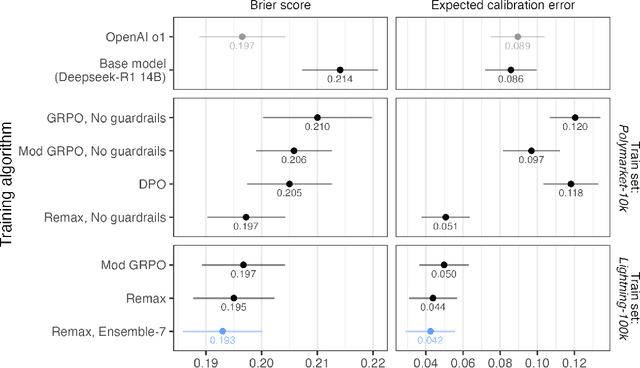
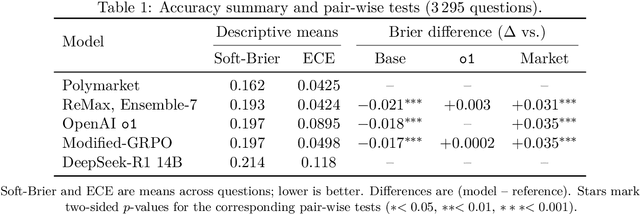
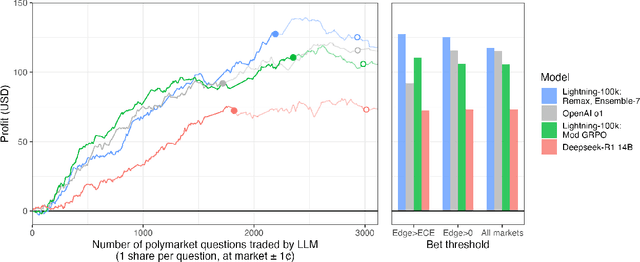
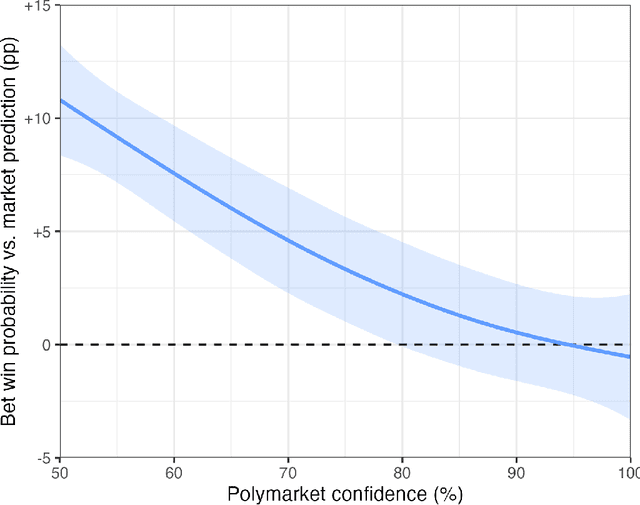
Reinforcement learning with verifiable rewards (RLVR) has boosted math and coding in large language models, yet there has been little effort to extend RLVR into messier, real-world domains like forecasting. One sticking point is that outcome-based reinforcement learning for forecasting must learn from binary, delayed, and noisy rewards, a regime where standard fine-tuning is brittle. We show that outcome-only online RL on a 14B model can match frontier-scale accuracy and surpass it in calibration and hypothetical prediction market betting by adapting two leading algorithms, Group-Relative Policy Optimisation (GRPO) and ReMax, to the forecasting setting. Our adaptations remove per-question variance scaling in GRPO, apply baseline-subtracted advantages in ReMax, hydrate training with 100k temporally consistent synthetic questions, and introduce lightweight guard-rails that penalise gibberish, non-English responses and missing rationales, enabling a single stable pass over 110k events. Scaling ReMax to 110k questions and ensembling seven predictions yields a 14B model that matches frontier baseline o1 on accuracy on our holdout set (Brier = 0.193, p = 0.23) while beating it in calibration (ECE = 0.042, p < 0.001). A simple trading rule turns this calibration edge into \$127 of hypothetical profit versus \$92 for o1 (p = 0.037). This demonstrates that refined RLVR methods can convert small-scale LLMs into potentially economically valuable forecasting tools, with implications for scaling this to larger models.
Large Language Models Are More Persuasive Than Incentivized Human Persuaders
May 14, 2025



We directly compare the persuasion capabilities of a frontier large language model (LLM; Claude Sonnet 3.5) against incentivized human persuaders in an interactive, real-time conversational quiz setting. In this preregistered, large-scale incentivized experiment, participants (quiz takers) completed an online quiz where persuaders (either humans or LLMs) attempted to persuade quiz takers toward correct or incorrect answers. We find that LLM persuaders achieved significantly higher compliance with their directional persuasion attempts than incentivized human persuaders, demonstrating superior persuasive capabilities in both truthful (toward correct answers) and deceptive (toward incorrect answers) contexts. We also find that LLM persuaders significantly increased quiz takers' accuracy, leading to higher earnings, when steering quiz takers toward correct answers, and significantly decreased their accuracy, leading to lower earnings, when steering them toward incorrect answers. Overall, our findings suggest that AI's persuasion capabilities already exceed those of humans that have real-money bonuses tied to performance. Our findings of increasingly capable AI persuaders thus underscore the urgency of emerging alignment and governance frameworks.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Hybrid Memoised Wake-Sleep: Approximate Inference at the Discrete-Continuous Interface
Jul 04, 2021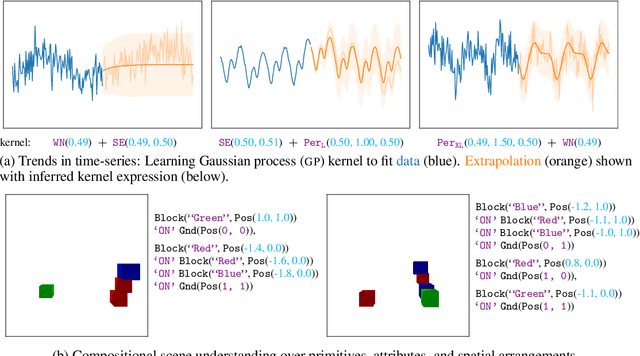
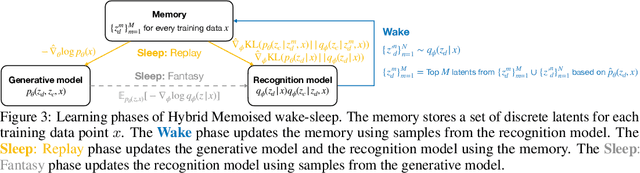
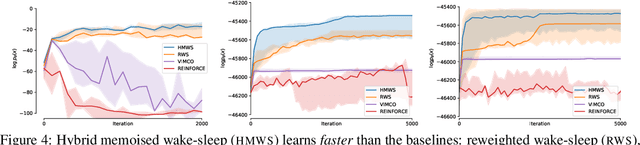
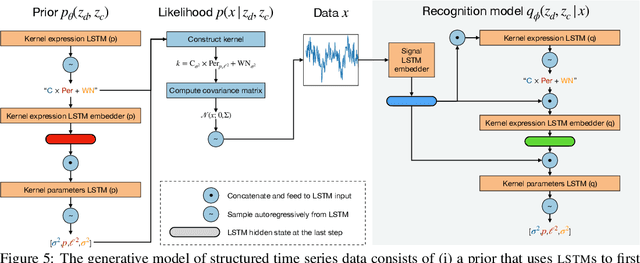
Modeling complex phenomena typically involves the use of both discrete and continuous variables. Such a setting applies across a wide range of problems, from identifying trends in time-series data to performing effective compositional scene understanding in images. Here, we propose Hybrid Memoised Wake-Sleep (HMWS), an algorithm for effective inference in such hybrid discrete-continuous models. Prior approaches to learning suffer as they need to perform repeated expensive inner-loop discrete inference. We build on a recent approach, Memoised Wake-Sleep (MWS), which alleviates part of the problem by memoising discrete variables, and extend it to allow for a principled and effective way to handle continuous variables by learning a separate recognition model used for importance-sampling based approximate inference and marginalization. We evaluate HMWS in the GP-kernel learning and 3D scene understanding domains, and show that it outperforms current state-of-the-art inference methods.
DreamCoder: Growing generalizable, interpretable knowledge with wake-sleep Bayesian program learning
Jun 15, 2020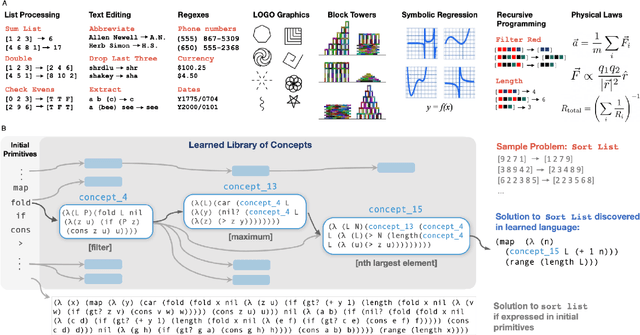
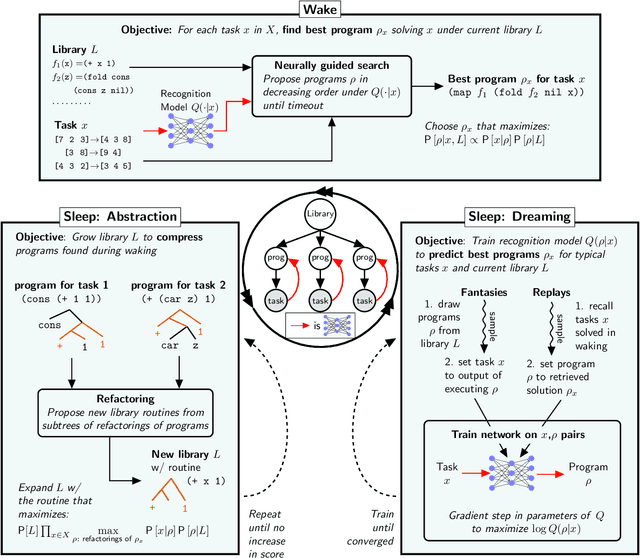
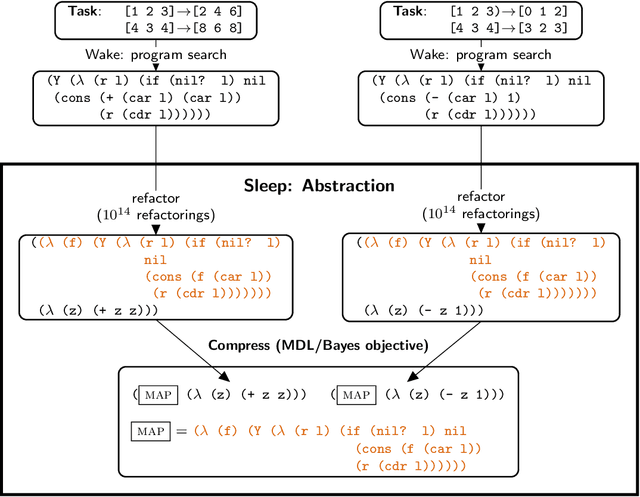

Expert problem-solving is driven by powerful languages for thinking about problems and their solutions. Acquiring expertise means learning these languages -- systems of concepts, alongside the skills to use them. We present DreamCoder, a system that learns to solve problems by writing programs. It builds expertise by creating programming languages for expressing domain concepts, together with neural networks to guide the search for programs within these languages. A ``wake-sleep'' learning algorithm alternately extends the language with new symbolic abstractions and trains the neural network on imagined and replayed problems. DreamCoder solves both classic inductive programming tasks and creative tasks such as drawing pictures and building scenes. It rediscovers the basics of modern functional programming, vector algebra and classical physics, including Newton's and Coulomb's laws. Concepts are built compositionally from those learned earlier, yielding multi-layered symbolic representations that are interpretable and transferrable to new tasks, while still growing scalably and flexibly with experience.
Learning to Infer Program Sketches
Feb 17, 2019
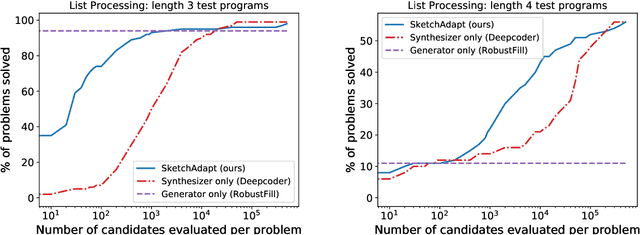

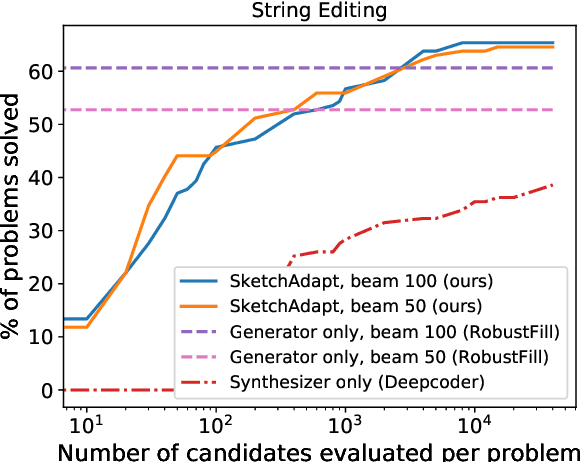
Our goal is to build systems which write code automatically from the kinds of specifications humans can most easily provide, such as examples and natural language instruction. The key idea of this work is that a flexible combination of pattern recognition and explicit reasoning can be used to solve these complex programming problems. We propose a method for dynamically integrating these types of information. Our novel intermediate representation and training algorithm allow a program synthesis system to learn, without direct supervision, when to rely on pattern recognition and when to perform symbolic search. Our model matches the memorization and generalization performance of neural synthesis and symbolic search, respectively, and achieves state-of-the-art performance on a dataset of simple English description-to-code programming problems.