 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-level Decisions from a Safe Maneuver Catalog with Reinforcement Learning for Safe and Cooperative Automated Merging
Jul 15, 2021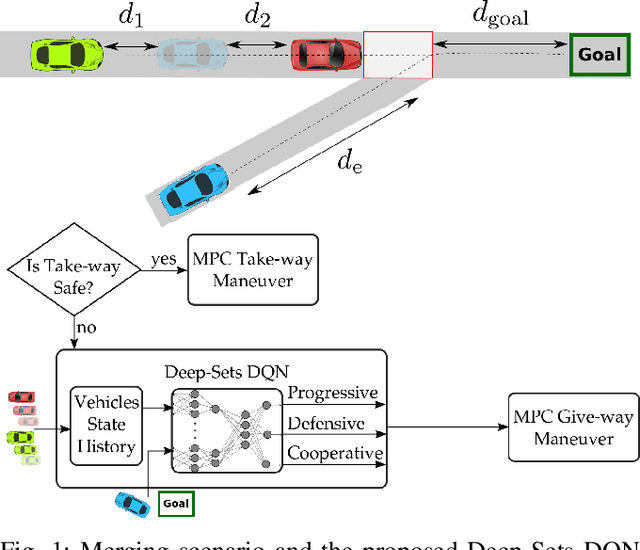
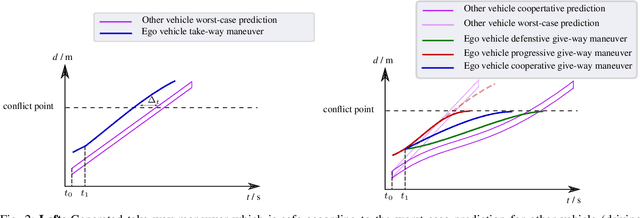
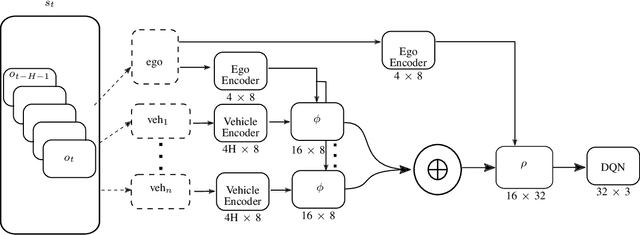
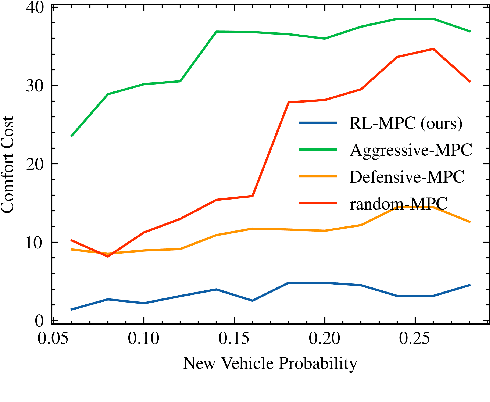
Reinforcement learning (RL) has recently been used for solving challenging decision-making problems in the context of automated driving. However, one of the main drawbacks of the presented RL-based policies is the lack of safety guarantees, since they strive to reduce the expected number of collisions but still tolerate them. In this paper, we propose an efficient RL-based decision-making pipeline for safe and cooperative automated driving in merging scenarios. The RL agent is able to predict the current situation and provide high-level decisions, specifying the operation mode of the low level planner which is responsible for safety. In order to learn a more generic policy, we propose a scalable RL architecture for the merging scenario that is not sensitive to changes in the environment configurations. According to our experiments, the proposed RL agent can efficiently identify cooperative drivers from their vehicle state history and generate interactive maneuvers, resulting in faster and more comfortable automated driving. At the same time, thanks to the safety constraints inside the planner, all of the maneuvers are collision free and safe.
Minimizing Safety Interference for Safe and Comfortable Automated Driving with Distributional Reinforcement Learning
Jul 15, 2021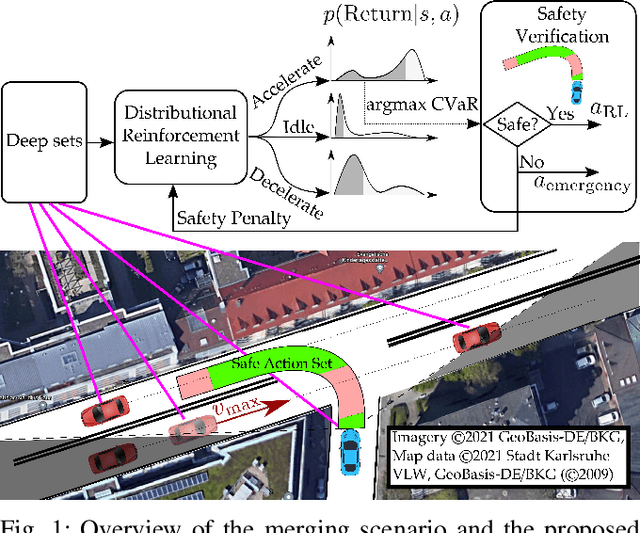
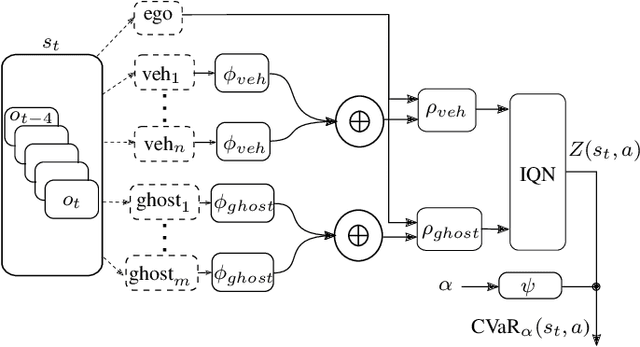
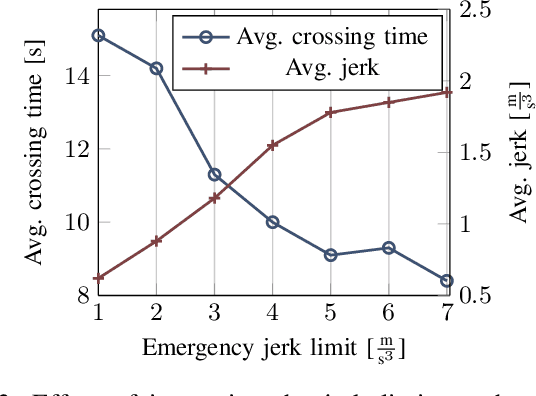
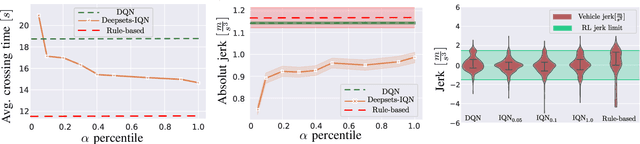
Despite recent advances in reinforcement learning (RL), its application in safety critical domains like autonomous vehicles is still challenging. Although punishing RL agents for risky situations can help to learn safe policies, it may also lead to highly conservative behavior. In this paper, we propose a distributional RL framework in order to learn adaptive policies that can tune their level of conservativity at run-time based on the desired comfort and utility. Using a proactive safety verification approach, the proposed framework can guarantee that actions generated from RL are fail-safe according to the worst-case assumptions. Concurrently, the policy is encouraged to minimize safety interference and generate more comfortable behavior. We trained and evaluated the proposed approach and baseline policies using a high level simulator with a variety of randomized scenarios including several corner cases which rarely happen in reality but are very crucial. In light of our experiments, the behavior of policies learned using distributional RL can be adaptive at run-time and robust to the environment uncertainty. Quantitatively, the learned distributional RL agent drives in average 8 seconds faster than the normal DQN policy and requires 83\% less safety interference compared to the rule-based policy with slightly increasing the average crossing time. We also study sensitivity of the learned policy in environments with higher perception noise and show that our algorithm learns policies that can still drive reliable when the perception noise is two times higher than the training configuration for automated merging and crossing at occluded intersections.
Risk-Aware High-level Decisions for Automated Driving at Occluded Intersections with Reinforcement Learning
Apr 09, 2020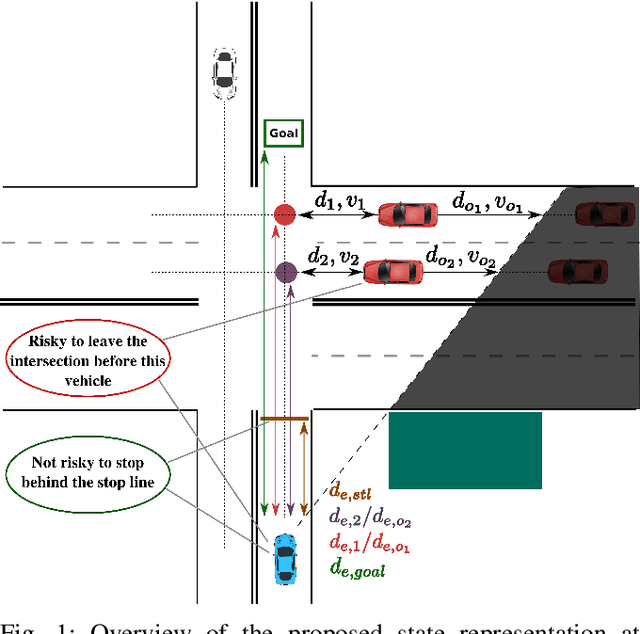
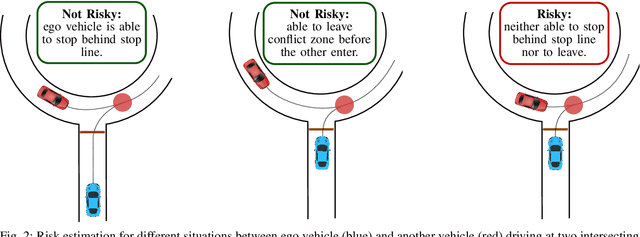
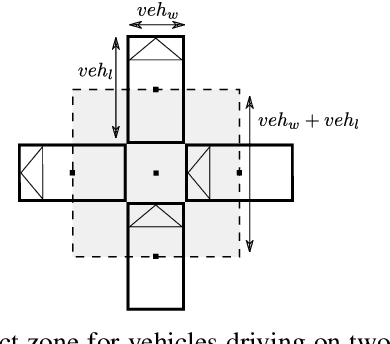
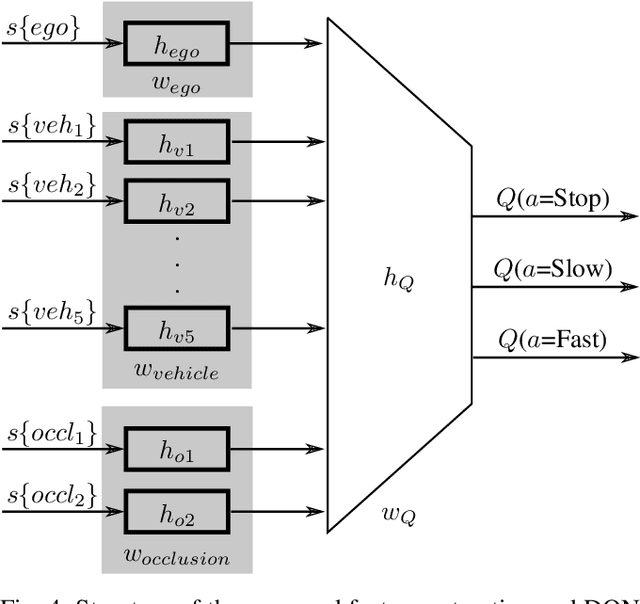
Reinforcement learning is nowadays a popular framework for solving different decision making problems in automated driving. However, there are still some remaining crucial challenges that need to be addressed for providing more reliable policies. In this paper, we propose a generic risk-aware DQN approach in order to learn high level actions for driving through unsignalized occluded intersections. The proposed state representation provides lane based information which allows to be used for multi-lane scenarios. Moreover, we propose a risk based reward function which punishes risky situations instead of only collision failures. Such rewarding approach helps to incorporate risk prediction into our deep Q network and learn more reliable policies which are safer in challenging situations. The efficiency of the proposed approach is compared with a DQN learned with conventional collision based rewarding scheme and also with a rule-based intersection navigation policy. Evaluation results show that the proposed approach outperforms both of these methods. It provides safer actions than collision-aware DQN approach and is less overcautious than the rule-based policy.