 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploration and preference satisfaction trade-off in reward-free learning
Jun 08, 2021
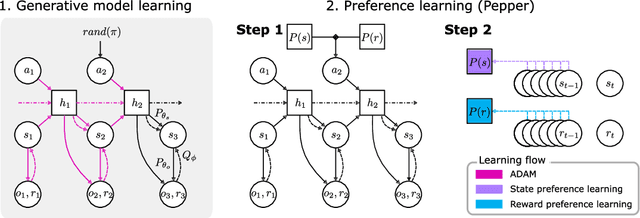

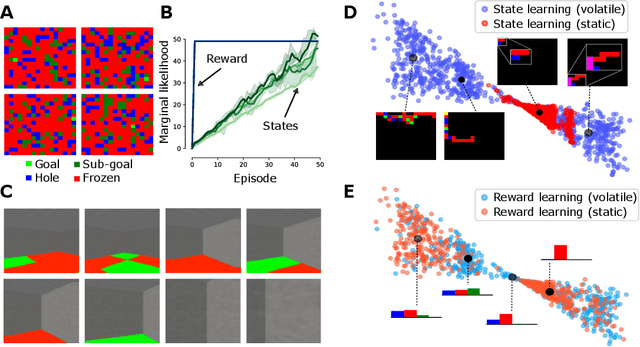

Biological agents have meaningful interactions with their environment despite the absence of a reward signal. In such instances, the agent can learn preferred modes of behaviour that lead to predictable states -- necessary for survival. In this paper, we pursue the notion that this learnt behaviour can be a consequence of reward-free preference learning that ensures an appropriate trade-off between exploration and preference satisfaction. For this, we introduce a model-based Bayesian agent equipped with a preference learning mechanism (pepper) using conjugate priors. These conjugate priors are used to augment the expected free energy planner for learning preferences over states (or outcomes) across time. Importantly, our approach enables the agent to learn preferences that encourage adaptive behaviour at test time. We illustrate this in the OpenAI Gym FrozenLake and the 3D mini-world environments -- with and without volatility. Given a constant environment, these agents learn confident (i.e., precise) preferences and act to satisfy them. Conversely, in a volatile setting, perpetual preference uncertainty maintains exploratory behaviour. Our experiments suggest that learnable (reward-free) preferences entail a trade-off between exploration and preference satisfaction. Pepper offers a straightforward framework suitable for designing adaptive agents when reward functions cannot be predefined as in real environments.
Automatic Gaze Analysis: A Survey of DeepLearning based Approaches
Aug 12, 2021
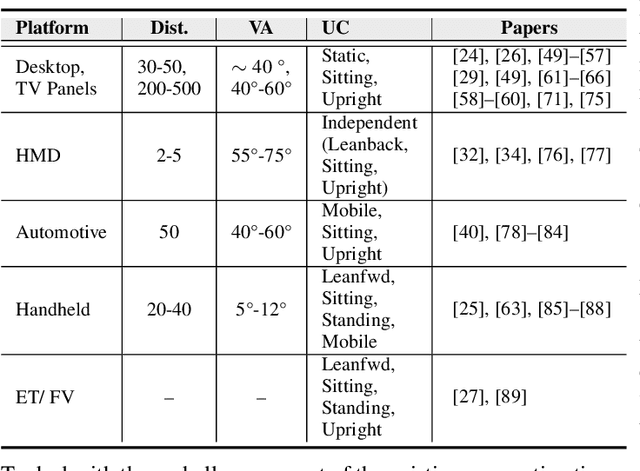
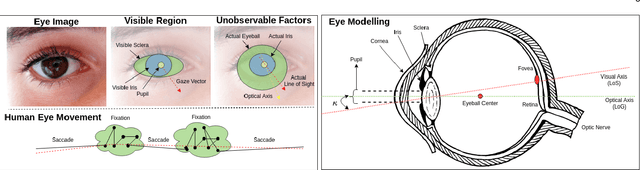
Eye gaze analysis is an important research problem in the field of computer vision and Human-Computer Interaction (HCI). Even with significant progress in the last few years, automatic gaze analysis still remains challenging due to the individuality of eyes, eye-head interplay, occlusion, image quality, and illumination conditions. There are several open questions including what are the important cues to interpret gaze direction in an unconstrained environment without prior knowledge and how to encode them in real-time. We review the progress across a range of gaze analysis tasks and applications to shed light on these fundamental questions; identify effective methods in gaze analysis and provide possible future directions. We analyze recent gaze estimation and segmentation methods, especially in the unsupervised and weakly supervised domain, based on their advantages and reported evaluation metrics. Our analysis shows that the development of a robust and generic gaze analysis method still needs to address real-world challenges such as unconstrained setup and learning with less supervision. We conclude by discussing future research directions for designing a real-world gaze analysis system that can propagate to other domains including computer vision, AR (Augmented Reality), VR (Virtual Reality), and HCI (Human Computer Interaction).
Verifying Low-dimensional Input Neural Networks via Input Quantization
Aug 18, 2021

Deep neural networks are an attractive tool for compressing the control policy lookup tables in systems such as the Airborne Collision Avoidance System (ACAS). It is vital to ensure the safety of such neural controllers via verification techniques. The problem of analyzing ACAS Xu networks has motivated many successful neural network verifiers. These verifiers typically analyze the internal computation of neural networks to decide whether a property regarding the input/output holds. The intrinsic complexity of neural network computation renders such verifiers slow to run and vulnerable to floating-point error. This paper revisits the original problem of verifying ACAS Xu networks. The networks take low-dimensional sensory inputs with training data provided by a precomputed lookup table. We propose to prepend an input quantization layer to the network. Quantization allows efficient verification via input state enumeration, whose complexity is bounded by the size of the quantization space. Quantization is equivalent to nearest-neighbor interpolation at run time, which has been shown to provide acceptable accuracy for ACAS in simulation. Moreover, our technique can deliver exact verification results immune to floating-point error if we directly enumerate the network outputs on the target inference implementation or on an accurate simulation of the target implementation.
Video-Based Camera Localization Using Anchor View Detection and Recursive 3D Reconstruction
Jul 07, 2021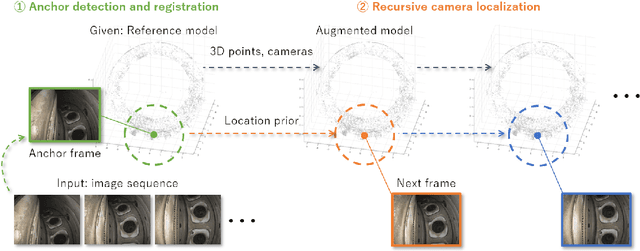
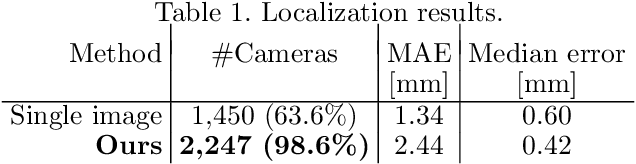
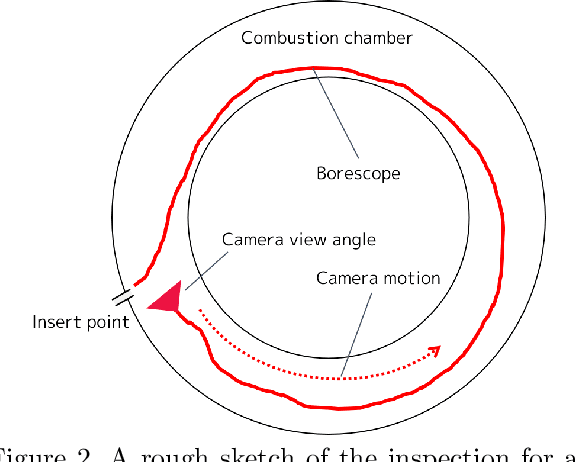
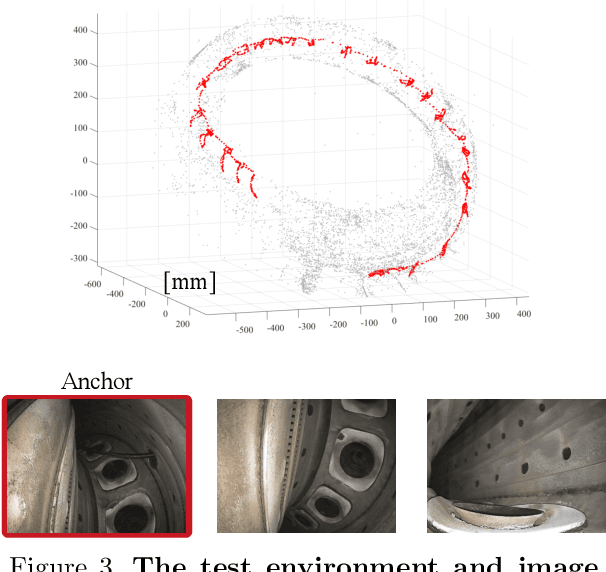
In this paper we introduce a new camera localization strategy designed for image sequences captured in challenging industrial situations such as industrial parts inspection. To deal with peculiar appearances that hurt standard 3D reconstruction pipeline, we exploit pre-knowledge of the scene by selecting key frames in the sequence (called as anchors) which are roughly connected to a certain location. Our method then seek the location of each frame in time-order, while recursively updating an augmented 3D model which can provide current camera location and surrounding 3D structure. In an experiment on a practical industrial situation, our method can localize over 99% frames in the input sequence, whereas standard localization methods fail to reconstruct a complete camera trajectory.
MLReal: Bridging the gap between training on synthetic data and real data applications in machine learning
Sep 11, 2021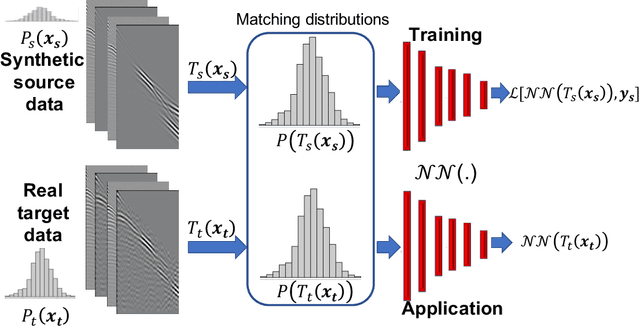
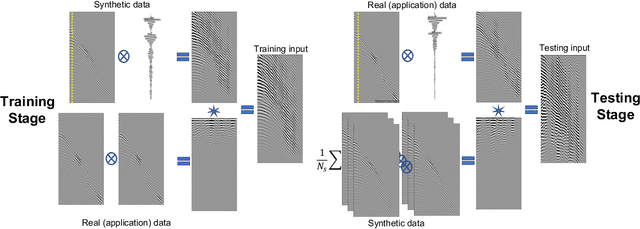
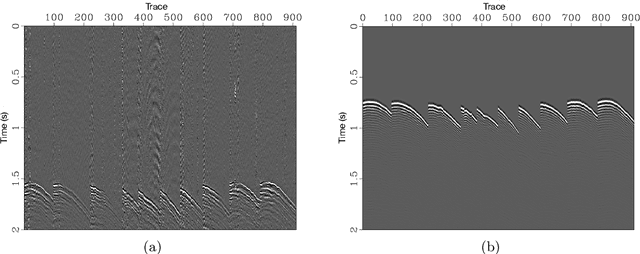
Among the biggest challenges we face in utilizing neural networks trained on waveform data (i.e., seismic, electromagnetic, or ultrasound) is its application to real data. The requirement for accurate labels forces us to develop solutions using synthetic data, where labels are readily available. However, synthetic data often do not capture the reality of the field/real experiment, and we end up with poor performance of the trained neural network (NN) at the inference stage. We describe a novel approach to enhance supervised training on synthetic data with real data features (domain adaptation). Specifically, for tasks in which the absolute values of the vertical axis (time or depth) of the input data are not crucial, like classification, or can be corrected afterward, like velocity model building using a well-log, we suggest a series of linear operations on the input so the training and application data have similar distributions. This is accomplished by applying two operations on the input data to the NN model: 1) The crosscorrelation of the input data (i.e., shot gather, seismic image, etc.) with a fixed reference trace from the same dataset. 2) The convolution of the resulting data with the mean (or a random sample) of the autocorrelated data from another domain. In the training stage, the input data are from the synthetic domain and the auto-correlated data are from the real domain, and random samples from real data are drawn at every training epoch. In the inference/application stage, the input data are from the real subset domain and the mean of the autocorrelated sections are from the synthetic data subset domain. Example applications on passive seismic data for microseismic event source location determination and active seismic data for predicting low frequencies are used to demonstrate the power of this approach in improving the applicability of trained models to real data.
A new semi-supervised inductive transfer learning framework: Co-Transfer
Aug 18, 2021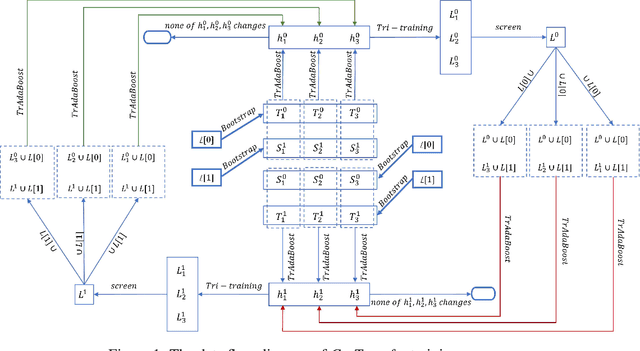
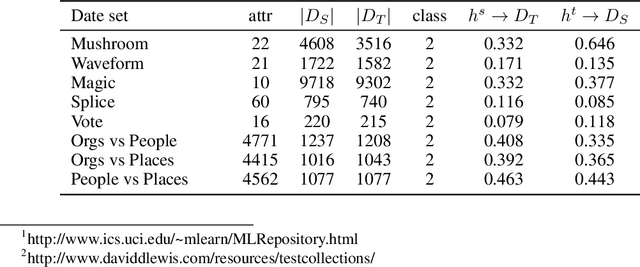
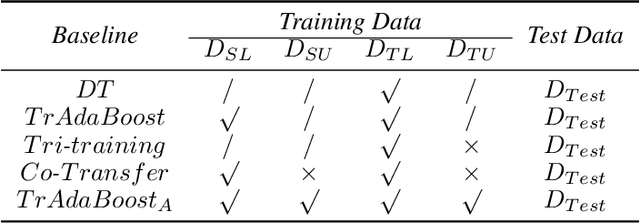
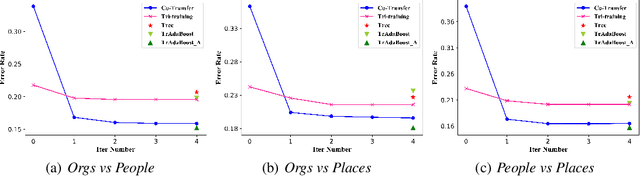
In many practical data mining scenarios, such as network intrusion detection, Twitter spam detection, and computer-aided diagnosis, a source domain that is different from but related to a target domain is very common. In addition, a large amount of unlabeled data is available in both source and target domains, but labeling each of them is difficult, expensive, time-consuming, and sometime unnecessary. Therefore, it is very important and worthwhile to fully explore the labeled and unlabeled data in source and target domains to settle the task in target domain. In this paper, a new semi-supervised inductive transfer learning framework, named \emph{Co-Transfer} is proposed. Co-Transfer first generates three TrAdaBoost classifiers for transfer learning from the source domain to the target domain, and meanwhile another three TrAdaBoost classifiers are generated for transfer learning from the target domain to the source domain, using bootstraped samples from the original labeled data. In each round of co-transfer, each group of TrAdaBoost classifiers are refined using the carefully labeled data. Finally, the group of TrAdaBoost classifiers learned to transfer from the source domain to the target domain produce the final hypothesis. Experiments results illustrate Co-Transfer can effectively exploit and reuse the labeled and unlabeled data in source and target domains.
Come back when you are charged! Self-Organized Charging for Electric Vehicles
Jun 08, 2021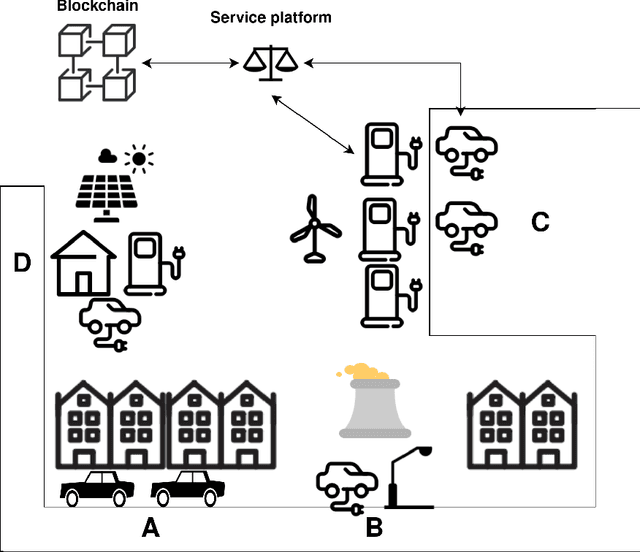
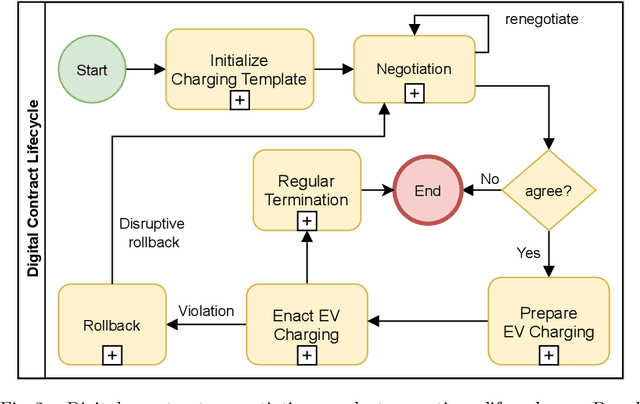
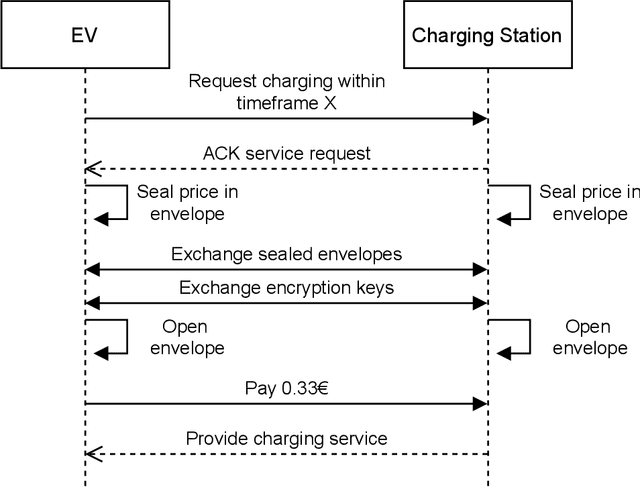
Dwindling nonrenewable fuel reserves, progressing severe environmental pollution, and accelerating climate change require society to reevaluate existing transportation concepts. While electric vehicles (EVs) have become more popular and slowly gain widespread adoption, the corresponding battery charging infrastructures still limits EVs' use in our everyday life. This is especially true for EV owners that do not have the option to operate charging hardware, such as wall boxes, at their premises. Charging an EV without an at-home wall box is time-consuming since the owner has to drive to the charger, charge the vehicle while waiting nearby, and finally drive back home. Thus, a convenient and easy-to-use solution is required to overcome the issue and incentivize EVs for daily commuters. Therefore, we propose an ecosystem and a service platform for (semi-)autonomous electric vehicles that allow them to utilize their "free"-time, e.g., at night, to access public and private charging infrastructure, charge their batteries, and get back home before the owner needs the car again. To do so, we utilize the concept of the Machine-to-Everything Economy (M2X Economy) and outline a decentralized ecosystem for smart machines that transact, interact and collaborate via blockchain-based smart contracts to enable a convenient battery charging marketplace for (semi-)autonomous EVs.
An Empirical Testing of Autonomous Vehicle Simulator System for Urban Driving
Aug 17, 2021
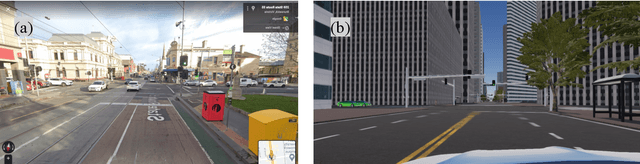


Safety is one of the main challenges that prohibit autonomous vehicles (AV), requiring them to be well tested ahead of being allowed on the road. In comparison with road tests, simulators allow us to validate the AV conveniently and affordably. However, it remains unclear how to best use the AV-based simulator system for testing effectively. Our paper presents an empirical testing of AV simulator system that combines the SVL simulator and the Apollo platform. We propose 576 test cases which are inspired by four naturalistic driving situations with pedestrians and surrounding cars. We found that the SVL can imitate realistic safe and collision situations; and at the same time, Apollo can drive the car quite safely. On the other hand, we noted that the system failed to detect pedestrians or vehicles on the road in three out of four classes, accounting for 10.0% total number of scenarios tested. We further applied metamorphic testing to identify inconsistencies in the system with additional 486 test cases. We then discussed some insights into the scenarios that may cause hazardous situations in real life. In summary, this paper provides a new empirical evidence to strengthen the assertion that the simulator-based system can be an indispensable tool for a comprehensive testing of the AV.
FMMformer: Efficient and Flexible Transformer via Decomposed Near-field and Far-field Attention
Aug 05, 2021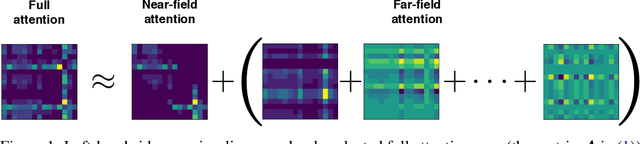

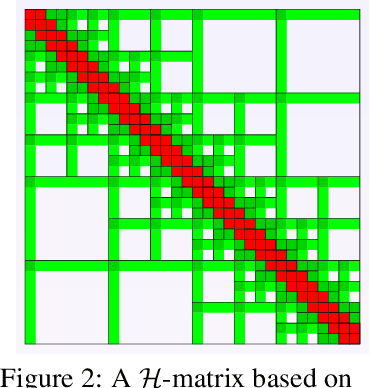
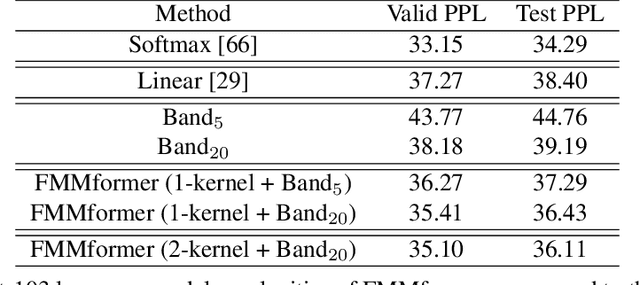
We propose FMMformers, a class of efficient and flexible transformers inspired by the celebrated fast multipole method (FMM) for accelerating interacting particle simulation. FMM decomposes particle-particle interaction into near-field and far-field components and then performs direct and coarse-grained computation, respectively. Similarly, FMMformers decompose the attention into near-field and far-field attention, modeling the near-field attention by a banded matrix and the far-field attention by a low-rank matrix. Computing the attention matrix for FMMformers requires linear complexity in computational time and memory footprint with respect to the sequence length. In contrast, standard transformers suffer from quadratic complexity. We analyze and validate the advantage of FMMformers over the standard transformer on the Long Range Arena and language modeling benchmarks. FMMformers can even outperform the standard transformer in terms of accuracy by a significant margin. For instance, FMMformers achieve an average classification accuracy of $60.74\%$ over the five Long Range Arena tasks, which is significantly better than the standard transformer's average accuracy of $58.70\%$.
Automatic Diagnosis of Schizophrenia using EEG Signals and CNN-LSTM Models
Sep 02, 2021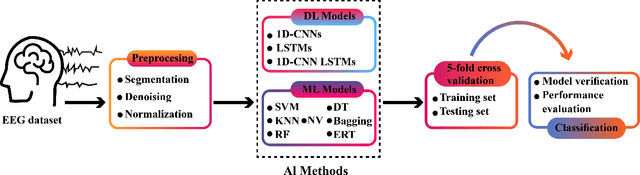
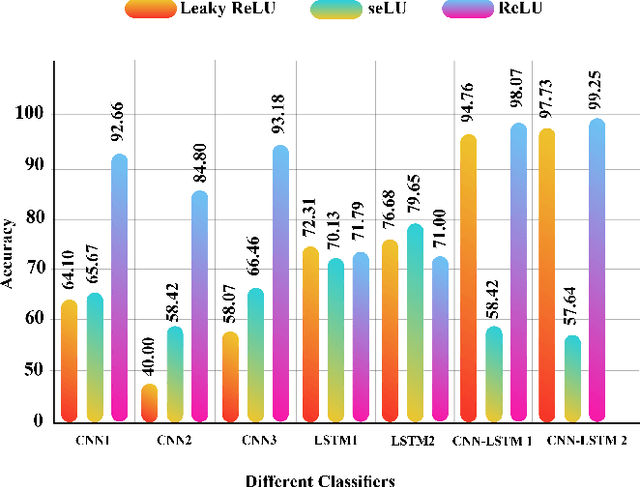

Schizophrenia (SZ) is a mental disorder whereby due to the secretion of specific chemicals in the brain, the function of some brain regions is out of balance, leading to the lack of coordination between thoughts, actions, and emotions. This study provides various intelligent Deep Learning (DL)-based methods for automated SZ diagnosis via EEG signals. The obtained results are compared with those of conventional intelligent methods. In order to implement the proposed methods, the dataset of the Institute of Psychiatry and Neurology in Warsaw, Poland, has been used. First, EEG signals are divided into 25-seconds time frames and then were normalized by z-score or norm L2. In the classification step, two different approaches are considered for SZ diagnosis via EEG signals. In this step, the classification of EEG signals is first carried out by conventional DL methods, e.g., KNN, DT, SVM, Bayes, bagging, RF, and ET. Various proposed DL models, including LSTMs, 1D-CNNs, and 1D-CNN-LSTMs, are used in the following. In this step, the DL models were implemented and compared with different activation functions. Among the proposed DL models, the CNN-LSTM architecture has had the best performance. In this architecture, the ReLU activation function and the z-score and L2 combined normalization are used. The proposed CNN-LSTM model has achieved an accuracy percentage of 99.25\%, better than the results of most former studies in this field. It is worth mentioning that in order to perform all simulations, the k-fold cross-validation method with k=5 has been used.