 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A New State-of-the-Art Transformers-Based Load Forecaster on the Smart Grid Domain
Aug 05, 2021
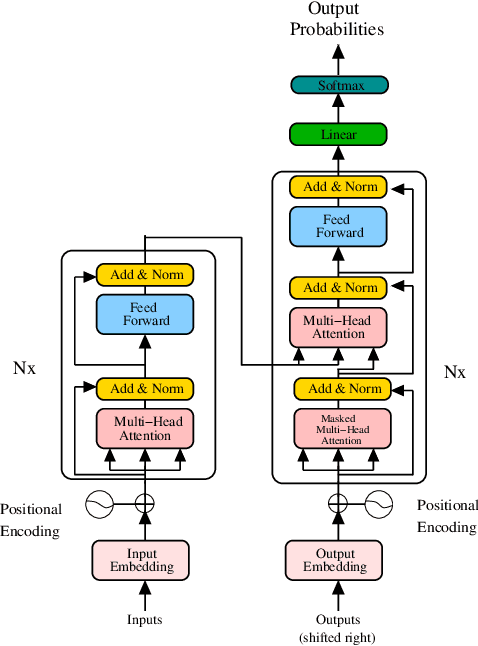
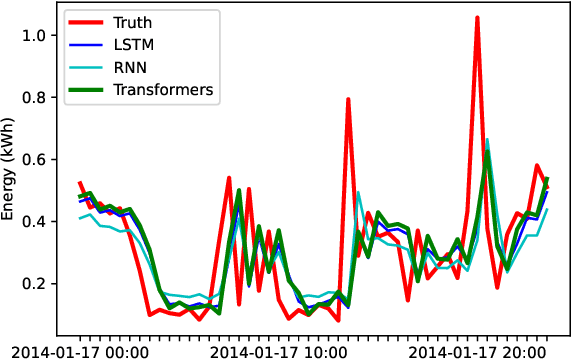
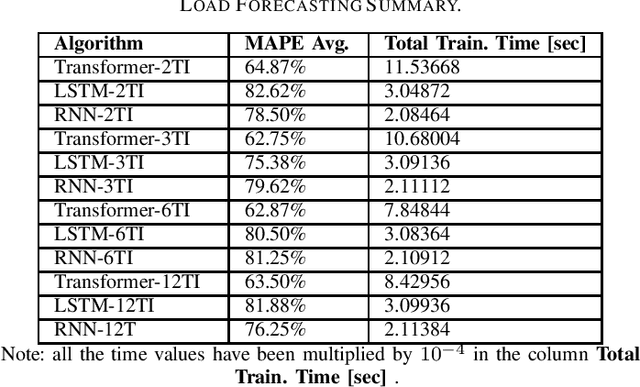
Meter-level load forecasting is crucial for efficient energy management and power system planning for Smart Grids (SGs), in tasks associated with regulation, dispatching, scheduling, and unit commitment of power grids. Although a variety of algorithms have been proposed and applied on the field, more accurate and robust models are still required: the overall utility cost of operations in SGs increases 10 million currency units if the load forecasting error increases 1%, and the mean absolute percentage error (MAPE) in forecasting is still much higher than 1%. Transformers have become the new state-of-the-art in a variety of tasks, including the ones in computer vision, natural language processing and time series forecasting, surpassing alternative neural models such as convolutional and recurrent neural networks. In this letter, we present a new state-of-the-art Transformer-based algorithm for the meter-level load forecasting task, which has surpassed the former state-of-the-art, LSTM, and the traditional benchmark, vanilla RNN, in all experiments by a margin of at least 13% in MAPE.
MSTRE-Net: Multistreaming Acoustic Modeling for Automatic Lyrics Transcription
Aug 05, 2021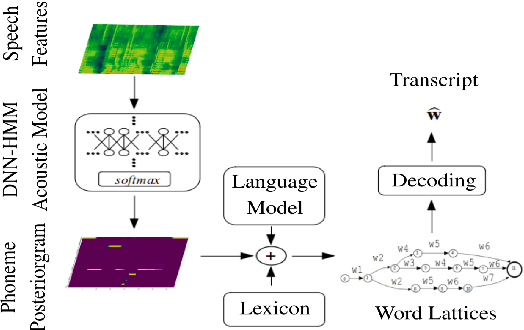
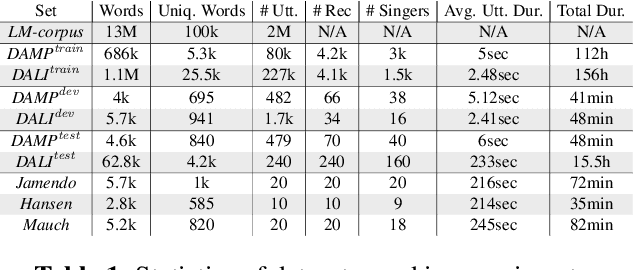
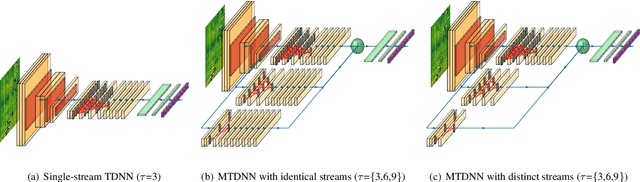

This paper makes several contributions to automatic lyrics transcription (ALT) research. Our main contribution is a novel variant of the Multistreaming Time-Delay Neural Network (MTDNN) architecture, called MSTRE-Net, which processes the temporal information using multiple streams in parallel with varying resolutions keeping the network more compact, and thus with a faster inference and an improved recognition rate than having identical TDNN streams. In addition, two novel preprocessing steps prior to training the acoustic model are proposed. First, we suggest using recordings from both monophonic and polyphonic domains during training the acoustic model. Second, we tag monophonic and polyphonic recordings with distinct labels for discriminating non-vocal silence and music instances during alignment. Moreover, we present a new test set with a considerably larger size and a higher musical variability compared to the existing datasets used in ALT literature, while maintaining the gender balance of the singers. Our best performing model sets the state-of-the-art in lyrics transcription by a large margin. For reproducibility, we publicly share the identifiers to retrieve the data used in this paper.
Moser Flow: Divergence-based Generative Modeling on Manifolds
Aug 18, 2021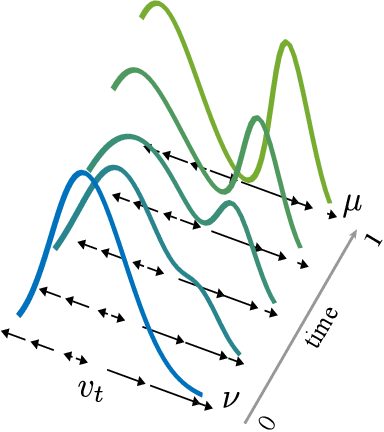
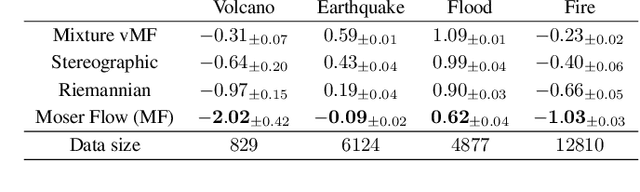
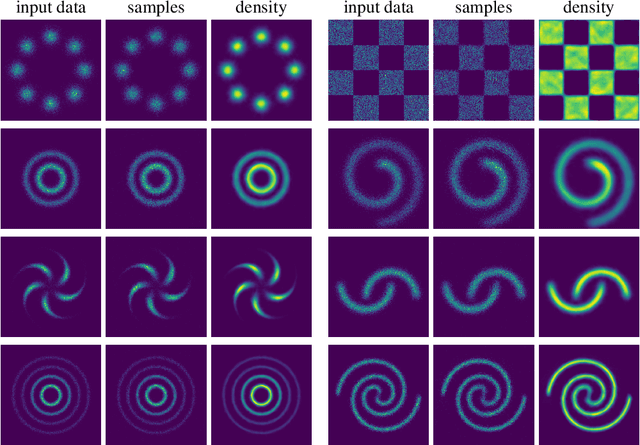
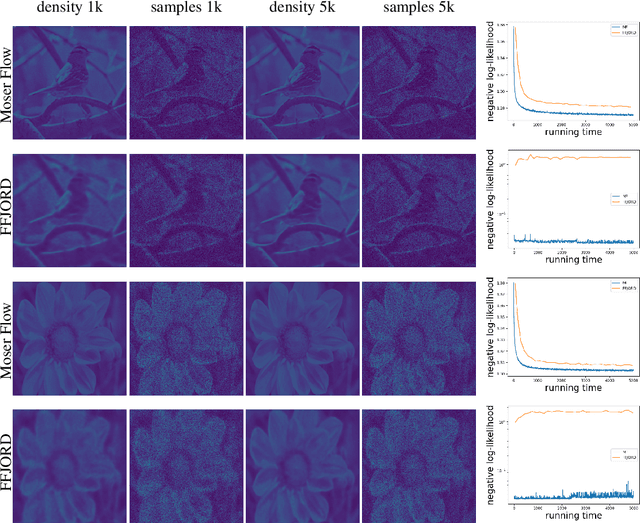
We are interested in learning generative models for complex geometries described via manifolds, such as spheres, tori, and other implicit surfaces. Current extensions of existing (Euclidean) generative models are restricted to specific geometries and typically suffer from high computational costs. We introduce Moser Flow (MF), a new class of generative models within the family of continuous normalizing flows (CNF). MF also produces a CNF via a solution to the change-of-variable formula, however differently from other CNF methods, its model (learned) density is parameterized as the source (prior) density minus the divergence of a neural network (NN). The divergence is a local, linear differential operator, easy to approximate and calculate on manifolds. Therefore, unlike other CNFs, MF does not require invoking or backpropagating through an ODE solver during training. Furthermore, representing the model density explicitly as the divergence of a NN rather than as a solution of an ODE facilitates learning high fidelity densities. Theoretically, we prove that MF constitutes a universal density approximator under suitable assumptions. Empirically, we demonstrate for the first time the use of flow models for sampling from general curved surfaces and achieve significant improvements in density estimation, sample quality, and training complexity over existing CNFs on challenging synthetic geometries and real-world benchmarks from the earth and climate sciences.
Can You Learn an Algorithm? Generalizing from Easy to Hard Problems with Recurrent Networks
Jun 08, 2021

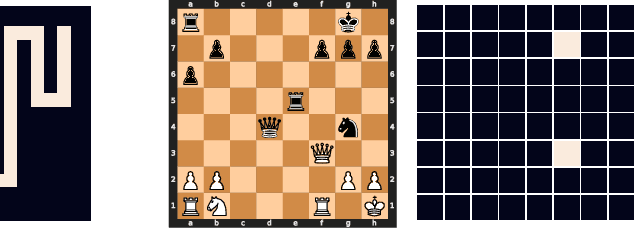

Deep neural networks are powerful machines for visual pattern recognition, but reasoning tasks that are easy for humans may still be difficult for neural models. Humans possess the ability to extrapolate reasoning strategies learned on simple problems to solve harder examples, often by thinking for longer. For example, a person who has learned to solve small mazes can easily extend the very same search techniques to solve much larger mazes by spending more time. In computers, this behavior is often achieved through the use of algorithms, which scale to arbitrarily hard problem instances at the cost of more computation. In contrast, the sequential computing budget of feed-forward neural networks is limited by their depth, and networks trained on simple problems have no way of extending their reasoning to accommodate harder problems. In this work, we show that recurrent networks trained to solve simple problems with few recurrent steps can indeed solve much more complex problems simply by performing additional recurrences during inference. We demonstrate this algorithmic behavior of recurrent networks on prefix sum computation, mazes, and chess. In all three domains, networks trained on simple problem instances are able to extend their reasoning abilities at test time simply by "thinking for longer."
Predicting Higher Education Throughput in South Africa Using a Tree-Based Ensemble Technique
Jun 12, 2021
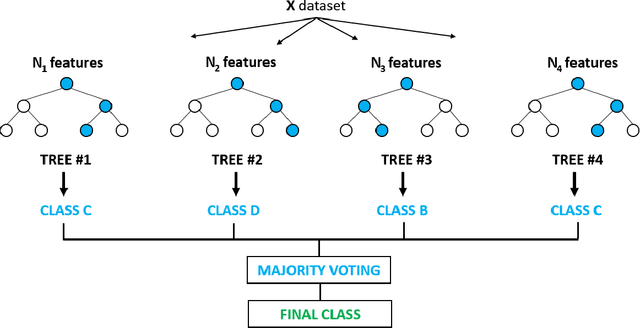

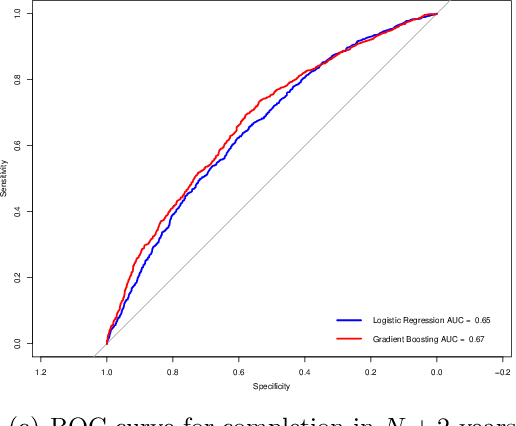
We use gradient boosting machines and logistic regression to predict academic throughput at a South African university. The results highlight the significant influence of socio-economic factors and field of study as predictors of throughput. We further find that socio-economic factors become less of a predictor relative to the field of study as the time to completion increases. We provide recommendations on interventions to counteract the identified effects, which include academic, psychosocial and financial support.
Spectrum Learning-Aided Reconfigurable Intelligent Surfaces for 'Green' 6G Networks
Sep 03, 2021
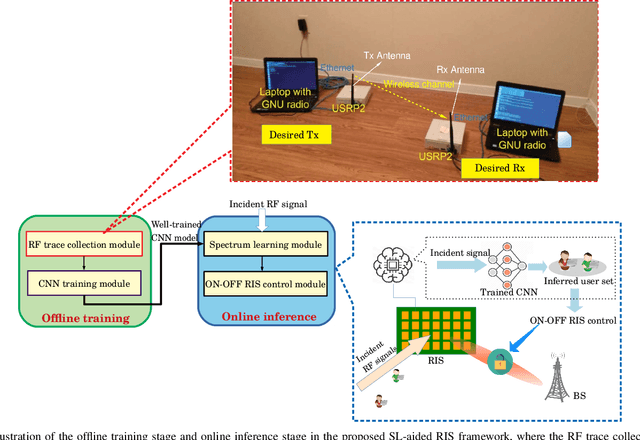
In the sixth-generation (6G) era, emerging large-scale computing based applications (for example processing enormous amounts of images in real-time in autonomous driving) tend to lead to excessive energy consumption for the end users, whose devices are usually energy-constrained. In this context, energy-efficiency becomes a critical challenge to be solved for harnessing these promising applications to realize 'green' 6G networks. As a remedy, reconfigurable intelligent surfaces (RIS) have been proposed for improving the energy efficiency by beneficially reconfiguring the wireless propagation environment. In conventional RIS solutions, however, the received signal-to-interference-plus-noise ratio (SINR) sometimes may even become degraded. This is because the signals impinging upon an RIS are typically contaminated by interfering signals which are usually dynamic and unknown. To address this issue, `learning' the properties of the surrounding spectral environment is a promising solution, motivating the convergence of artificial intelligence and spectrum sensing, termed here as spectrum learning (SL). Inspired by this, we develop an SL-aided RIS framework for intelligently exploiting the inherent characteristics of the radio frequency (RF) spectrum for green 6G networks. Given the proposed framework, the RIS controller becomes capable of intelligently `{think-and-decide}' whether to reflect or not the incident signals. Therefore, the received SINR can be improved by dynamically configuring the binary ON-OFF status of the RIS elements. The energy-efficiency benefits attained are validated with the aid of a specific case study. Finally, we conclude with a list of promising future research directions.
MLDemon: Deployment Monitoring for Machine Learning Systems
May 05, 2021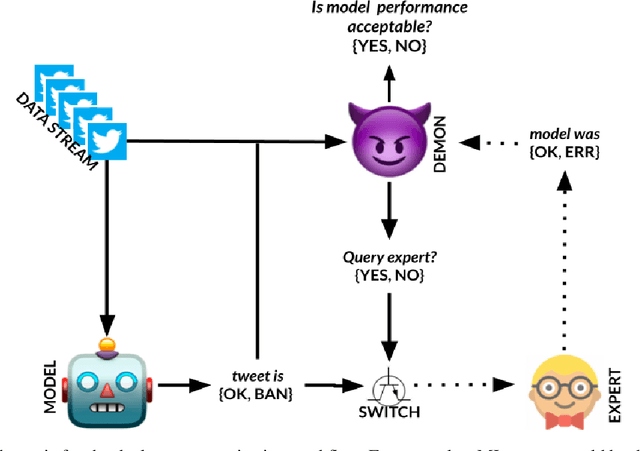
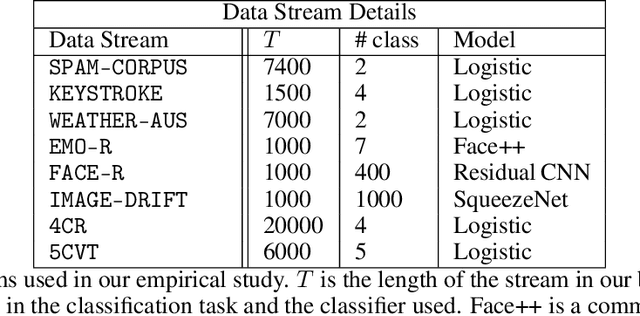
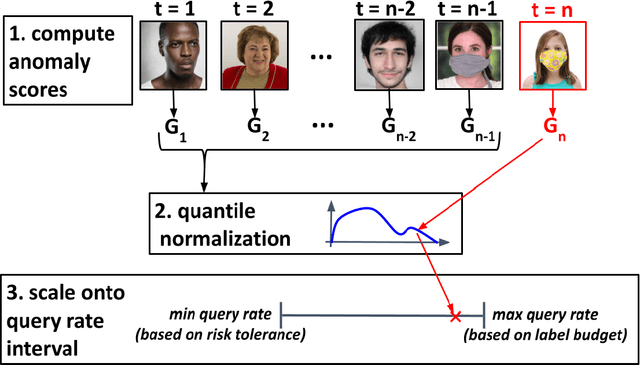
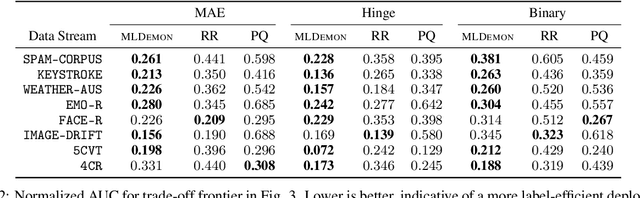
Post-deployment monitoring of the performance of ML systems is critical for ensuring reliability, especially as new user inputs can differ from the training distribution. Here we propose a novel approach, MLDemon, for ML DEployment MONitoring. MLDemon integrates both unlabeled features and a small amount of on-demand labeled examples over time to produce a real-time estimate of the ML model's current performance on a given data stream. Subject to budget constraints, MLDemon decides when to acquire additional, potentially costly, supervised labels to verify the model. On temporal datasets with diverse distribution drifts and models, MLDemon substantially outperforms existing monitoring approaches. Moreover, we provide theoretical analysis to show that MLDemon is minimax rate optimal up to logarithmic factors and is provably robust against broad distribution drifts whereas prior approaches are not.
Reduced Training Overhead for WLAN MU-MIMO Channel Feedback with Compressed Sensing
Jun 26, 2021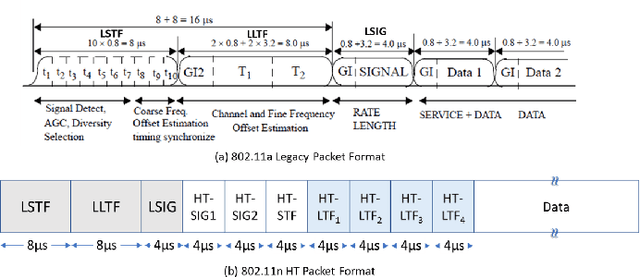
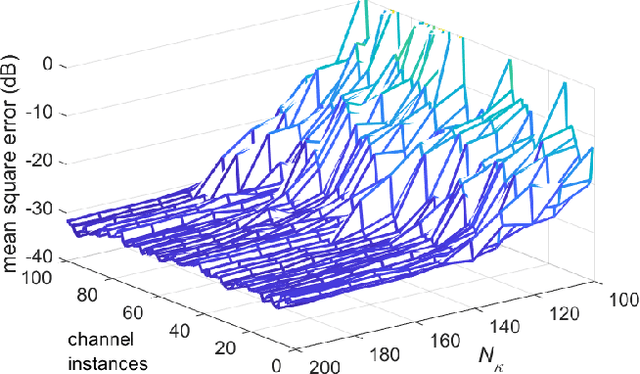
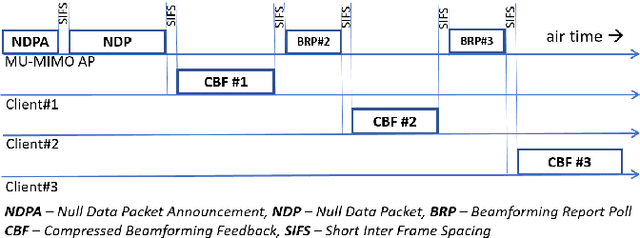
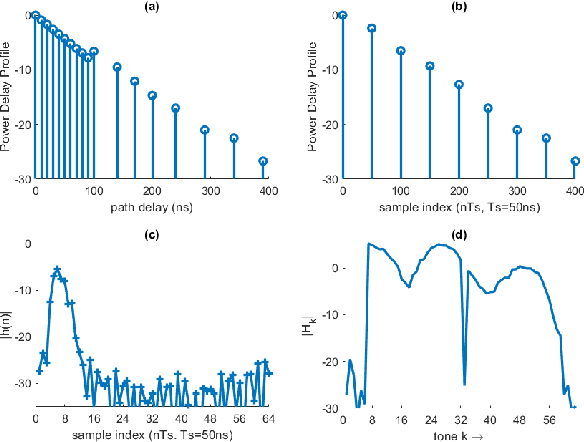
The WLAN packet format has a short training field (STF) for synchronization followed by a long training field (LTF) for channel estimation. To enable MIMO channel estimation, the LTF is repeated as many times as the number of spatial streams. For MU-MIMO, the CSI feedback in the 802.11ac/ax requires the access point (AP) to send a null data packet (NDP) where the HT/VHT/HE LTF is repeated as many times as the number of transmit antennas $N_{t}$. With each LTF being 4$\mu$s long in case of VHT and 12$\mu$s to 16$\mu$s long in case of High Efficiency WLAN (HEW), the length of NDP grows linearly with increasing $N_{t}$. Furthermore, the station (STA) with $N_{r}$ receive antennas needs to expend significant processing power to compute SVD per tone for the $N_{r}\times N_{t}$ channel matrix for generating the feedback bits, which again increases linearly with $N_{t}\cdot N_{r}$. To reduce the training and feedback overhead, this paper proposes a scheme based on Compressed Sensing that allows only a subset of tones per LTF to be transmitted in NDP, which can be used by STA to compute channel estimates that are then sent back without any further processing. Since AP knows the measurement matrix, the full dimension time domain channel estimates can be recovered by running the L1 minimization algorithms (OMP, CoSAMP). AP can further process the time domain channel estimates to generate the SVD precoding matrix.
Video Based Fall Detection Using Human Poses
Jul 29, 2021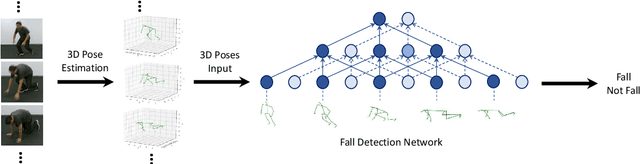
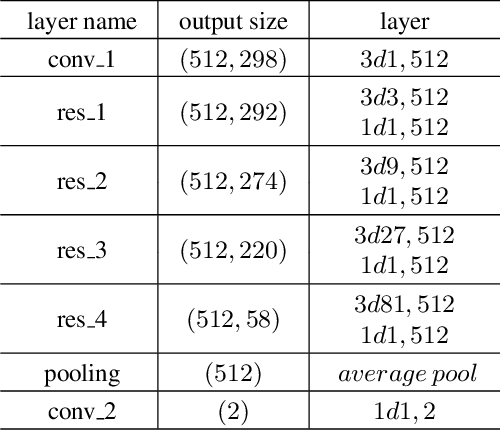
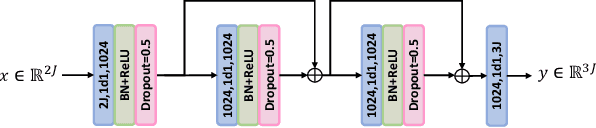

Video based fall detection accuracy has been largely improved due to the recent progress on deep convolutional neural networks. However, there still exists some challenges, such as lighting variation, complex background, which degrade the accuracy and generalization ability of these approaches. Meanwhile, large computation cost limits the application of existing fall detection approaches. To alleviate these problems, a video based fall detection approach using human poses is proposed in this paper. First, a lightweight pose estimator extracts 2D poses from video sequences and then 2D poses are lifted to 3D poses. Second, we introduce a robust fall detection network to recognize fall events using estimated 3D poses, which increases respective filed and maintains low computation cost by dilated convolutions. The experimental results show that the proposed fall detection approach achieves a high accuracy of 99.83% on large benchmark action recognition dataset NTU RGB+D and real-time performance of 18 FPS on a non-GPU platform and 63 FPS on a GPU platform.
Exploration and preference satisfaction trade-off in reward-free learning
Jun 08, 2021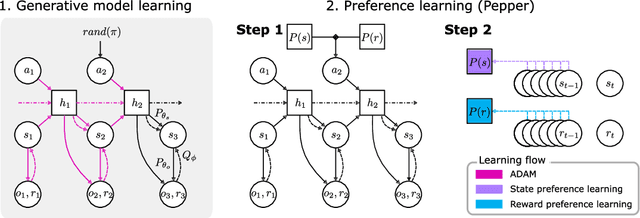

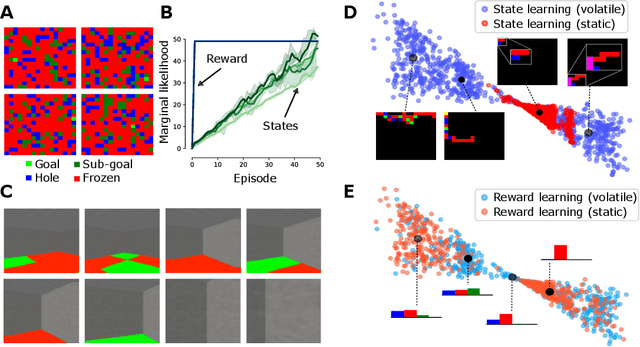

Biological agents have meaningful interactions with their environment despite the absence of a reward signal. In such instances, the agent can learn preferred modes of behaviour that lead to predictable states -- necessary for survival. In this paper, we pursue the notion that this learnt behaviour can be a consequence of reward-free preference learning that ensures an appropriate trade-off between exploration and preference satisfaction. For this, we introduce a model-based Bayesian agent equipped with a preference learning mechanism (pepper) using conjugate priors. These conjugate priors are used to augment the expected free energy planner for learning preferences over states (or outcomes) across time. Importantly, our approach enables the agent to learn preferences that encourage adaptive behaviour at test time. We illustrate this in the OpenAI Gym FrozenLake and the 3D mini-world environments -- with and without volatility. Given a constant environment, these agents learn confident (i.e., precise) preferences and act to satisfy them. Conversely, in a volatile setting, perpetual preference uncertainty maintains exploratory behaviour. Our experiments suggest that learnable (reward-free) preferences entail a trade-off between exploration and preference satisfaction. Pepper offers a straightforward framework suitable for designing adaptive agents when reward functions cannot be predefined as in real environments.