 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stimuli-Aware Visual Emotion Analysis
Sep 04, 2021
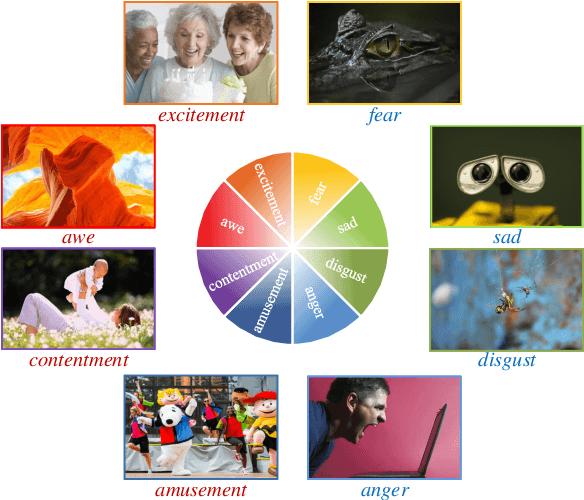
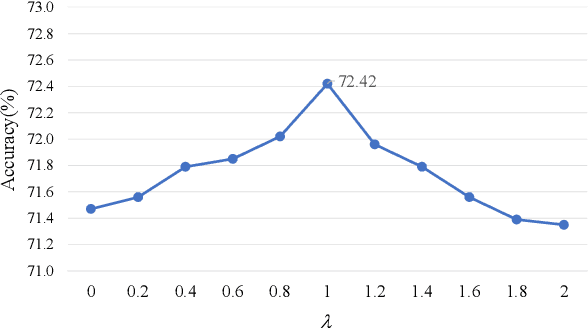
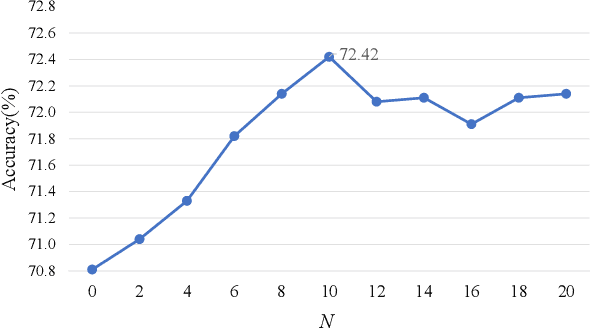

Visual emotion analysis (VEA) has attracted great attention recently, due to the increasing tendency of expressing and understanding emotions through images on social networks. Different from traditional vision tasks, VEA is inherently more challenging since it involves a much higher level of complexity and ambiguity in human cognitive process. Most of the existing methods adopt deep learning techniques to extract general features from the whole image, disregarding the specific features evoked by various emotional stimuli. Inspired by the \textit{Stimuli-Organism-Response (S-O-R)} emotion model in psychological theory, we proposed a stimuli-aware VEA method consisting of three stages, namely stimuli selection (S), feature extraction (O) and emotion prediction (R). First, specific emotional stimuli (i.e., color, object, face) are selected from images by employing the off-the-shelf tools. To the best of our knowledge, it is the first time to introduce stimuli selection process into VEA in an end-to-end network. Then, we design three specific networks, i.e., Global-Net, Semantic-Net and Expression-Net, to extract distinct emotional features from different stimuli simultaneously. Finally, benefiting from the inherent structure of Mikel's wheel, we design a novel hierarchical cross-entropy loss to distinguish hard false examples from easy ones in an emotion-specific manner. Experiments demonstrate that the proposed method consistently outperforms the state-of-the-art approaches on four public visual emotion datasets. Ablation study and visualizations further prove the validity and interpretability of our method.
* Accepted by TIP
Automatic Detection of COVID-19 Vaccine Misinformation with Graph Link Prediction
Aug 30, 2021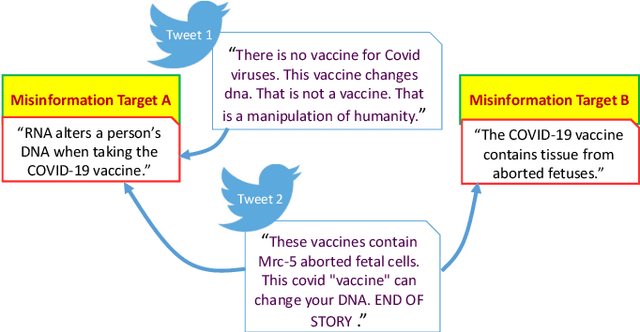
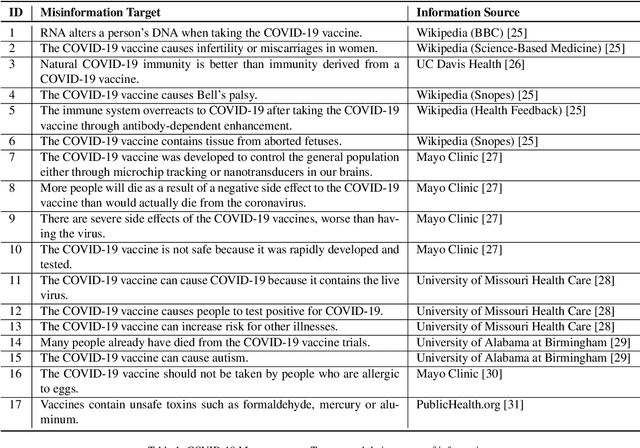
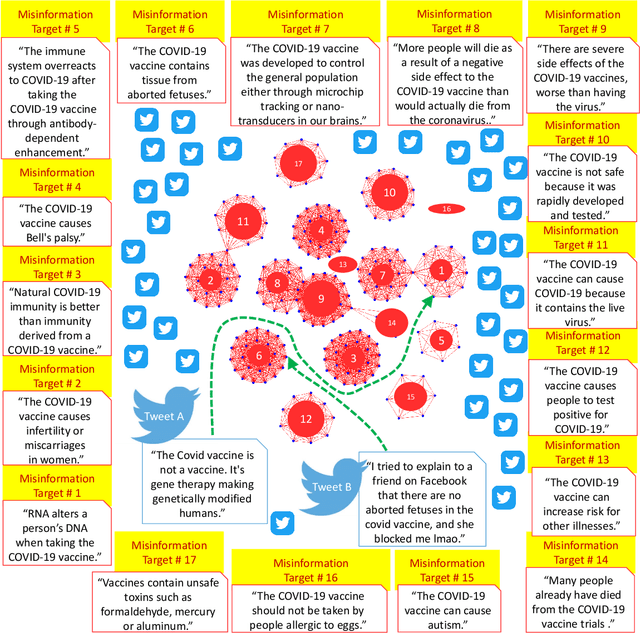
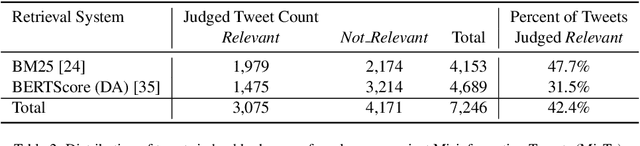
Enormous hope in the efficacy of vaccines became recently a successful reality in the fight against the COVID-19 pandemic. However, vaccine hesitancy, fueled by exposure to social media misinformation about COVID-19 vaccines became a major hurdle. Therefore, it is essential to automatically detect where misinformation about COVID-19 vaccines on social media is spread and what kind of misinformation is discussed, such that inoculation interventions can be delivered at the right time and in the right place, in addition to interventions designed to address vaccine hesitancy. This paper is addressing the first step in tackling hesitancy against COVID-19 vaccines, namely the automatic detection of known misinformation about the vaccines on Twitter, the social media platform that has the highest volume of conversations about COVID-19 and its vaccines. We present CoVaxLies, a new dataset of tweets judged relevant to several misinformation targets about COVID-19 vaccines on which a novel method of detecting misinformation was developed. Our method organizes CoVaxLies in a Misinformation Knowledge Graph as it casts misinformation detection as a graph link prediction problem. The misinformation detection method detailed in this paper takes advantage of the link scoring functions provided by several knowledge embedding methods. The experimental results demonstrate the superiority of this method when compared with classification-based methods, widely used currently.
Collaborative Human-Agent Planning for Resilience
Apr 29, 2021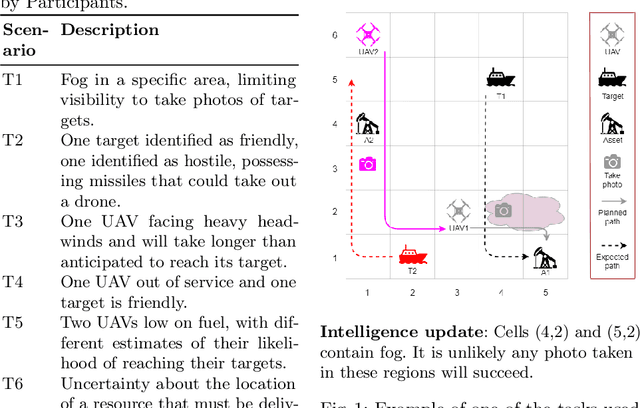

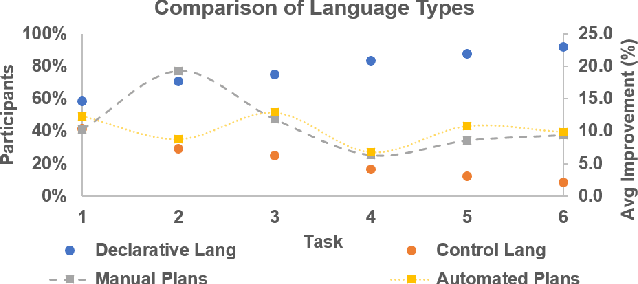
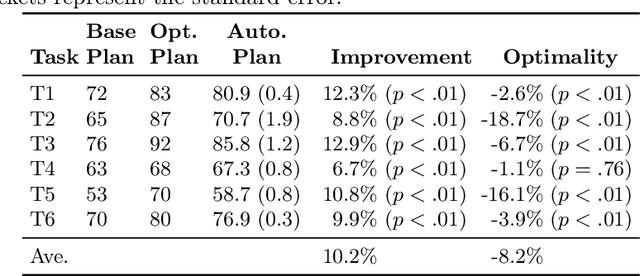
Intelligent agents powered by AI planning assist people in complex scenarios, such as managing teams of semi-autonomous vehicles. However, AI planning models may be incomplete, leading to plans that do not adequately meet the stated objectives, especially in unpredicted situations. Humans, who are apt at identifying and adapting to unusual situations, may be able to assist planning agents in these situations by encoding their knowledge into a planner at run-time. We investigate whether people can collaborate with agents by providing their knowledge to an agent using linear temporal logic (LTL) at run-time without changing the agent's domain model. We presented 24 participants with baseline plans for situations in which a planner had limitations, and asked the participants for workarounds for these limitations. We encoded these workarounds as LTL constraints. Results show that participants' constraints improved the expected return of the plans by 10% ($p < 0.05$) relative to baseline plans, demonstrating that human insight can be used in collaborative planning for resilience. However, participants used more declarative than control constraints over time, but declarative constraints produced plans less similar to the expectation of the participants, which could lead to potential trust issues.
Leveraging Pre-Images to Discover Nonlinear Relationships in Multivariate Environments
Jun 01, 2021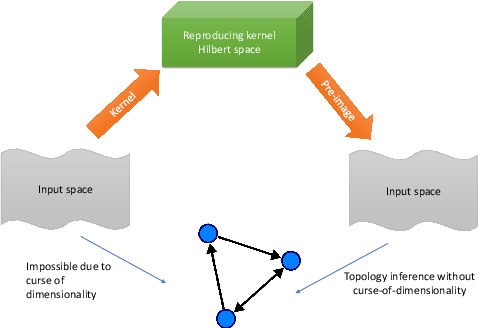
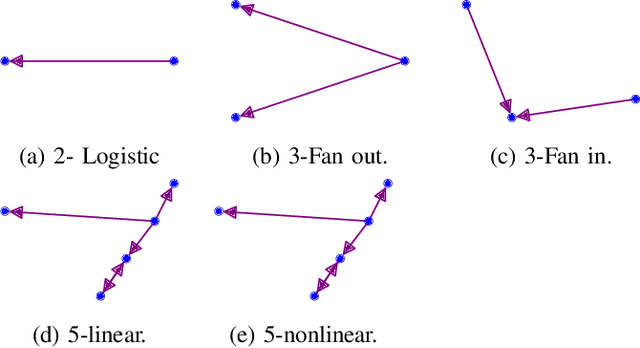
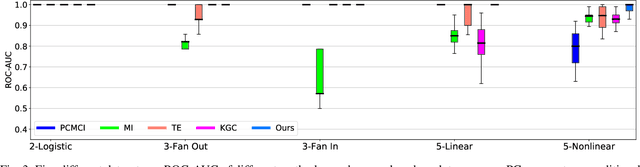
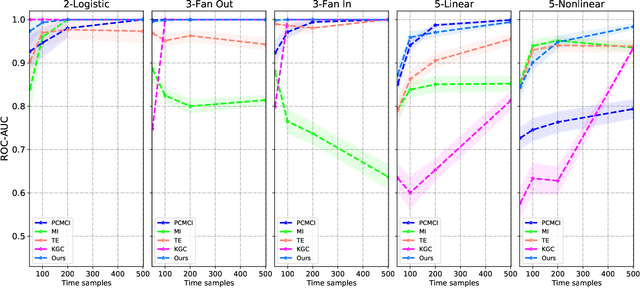
Causal discovery, beyond the inference of a network as a collection of connected dots, offers a crucial functionality in scientific discovery using artificial intelligence. The questions that arise in multiple domains, such as physics, physiology, the strategic decision in uncertain environments with multiple agents, climatology, among many others, have roots in causality and reasoning. It became apparent that many real-world temporal observations are nonlinearly related to each other. While the number of observations can be as high as millions of points, the number of temporal samples can be minimal due to ethical or practical reasons, leading to the curse-of-dimensionality in large-scale systems. This paper proposes a novel method using kernel principal component analysis and pre-images to obtain nonlinear dependencies of multivariate time-series data. We show that our method outperforms state-of-the-art causal discovery methods when the observations are restricted by time and are nonlinearly related. Extensive simulations on both real-world and synthetic datasets with various topologies are provided to evaluate our proposed methods.
Task-Sensitive Concept Drift Detector with Constraint Embedding
Aug 24, 2021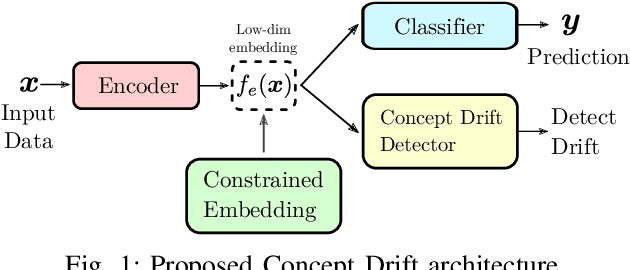
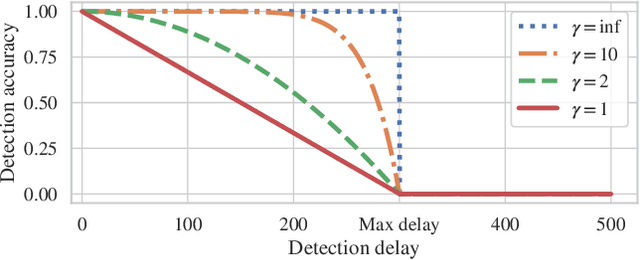
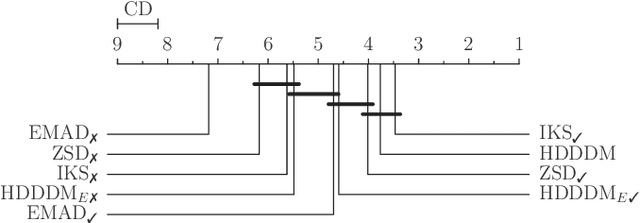
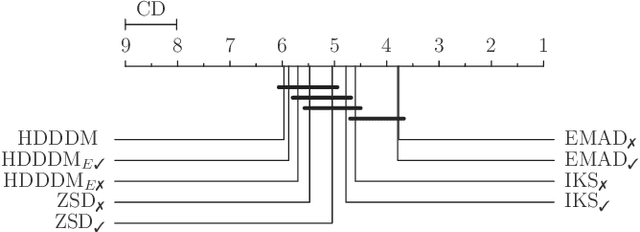
Detecting drifts in data is essential for machine learning applications, as changes in the statistics of processed data typically has a profound influence on the performance of trained models. Most of the available drift detection methods are either supervised and require access to the true labels during inference time, or they are completely unsupervised and aim for changes in distributions without taking label information into account. We propose a novel task-sensitive semi-supervised drift detection scheme, which utilizes label information while training the initial model, but takes into account that supervised label information is no longer available when using the model during inference. It utilizes a constrained low-dimensional embedding representation of the input data. This way, it is best suited for the classification task. It is able to detect real drift, where the drift affects the classification performance, while it properly ignores virtual drift, where the classification performance is not affected by the drift. In the proposed framework, the actual method to detect a change in the statistics of incoming data samples can be chosen freely. Experimental evaluation on nine benchmarks datasets, with different types of drift, demonstrates that the proposed framework can reliably detect drifts, and outperforms state-of-the-art unsupervised drift detection approaches.
Time-Dependent Deep Image Prior for Dynamic MRI
Oct 03, 2019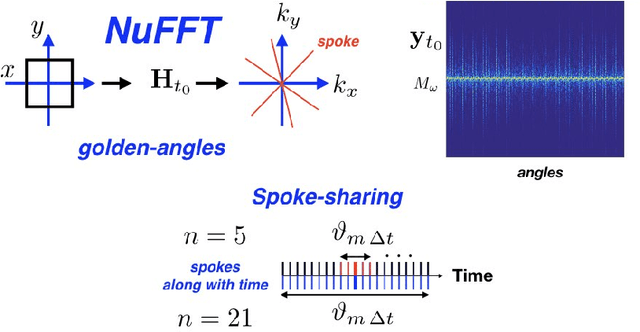


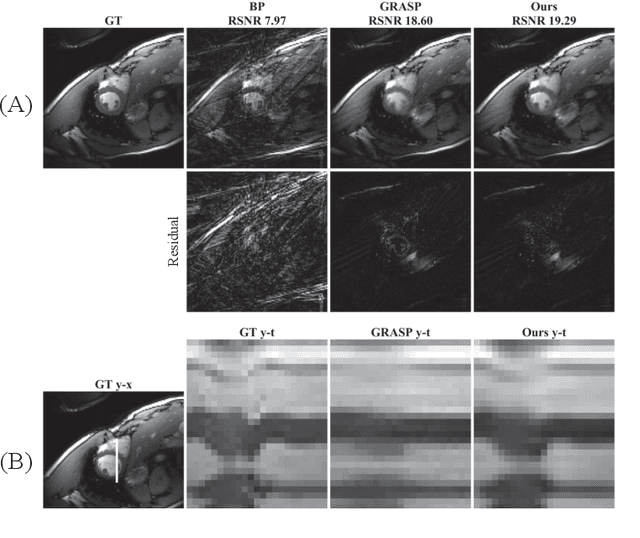
We propose a novel unsupervised deep-learning-based algorithm to solve the inverse problem found in dynamic magnetic resonance imaging (MRI). Our method needs neither prior training nor additional data; in particular, it does not require either electrocardiogram or spokes-reordering in the context of cardiac images. It generalizes to sequences of images the recently introduced deep-image-prior approach. The essence of the proposed algorithm is to proceed in two steps to fit k-space synthetic measurements to sparsely acquired dynamic MRI data. In the first step, we deploy a convolutional neural network (CNN) driven by a sequence of low-dimensional latent variables to generate a dynamic series of MRI images. In the second step, we submit the generated images to a nonuniform fast Fourier transform that represents the forward model of the MRI system. By manipulating the weights of the CNN, we fit our synthetic measurements to the acquired MRI data. The corresponding images from the CNN then provide the output of our system; their evolution through time is driven by controlling the sequence of latent variables whose interpolation gives access to the sub-frame---or even continuous---temporal control of reconstructed dynamic images. We perform experiments on simulated and real cardiac images of a fetus acquired through 5-spoke-based golden-angle measurements. Our results show improvement over the current state-of-the-art.
Large-Scale Modeling of Mobile User Click Behaviors Using Deep Learning
Aug 11, 2021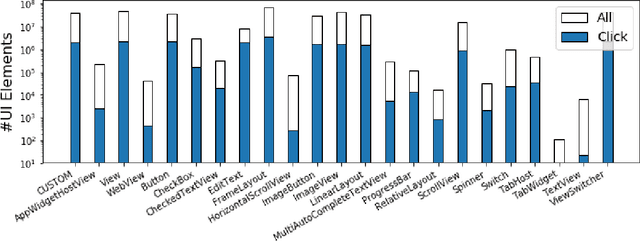
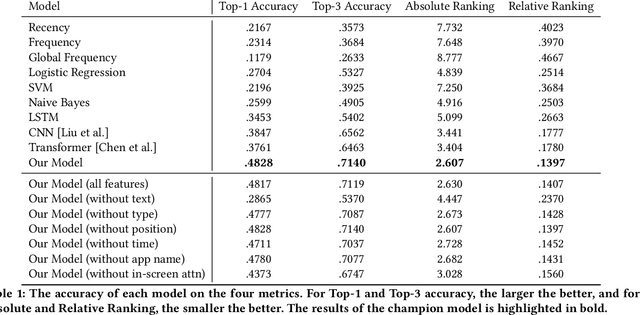
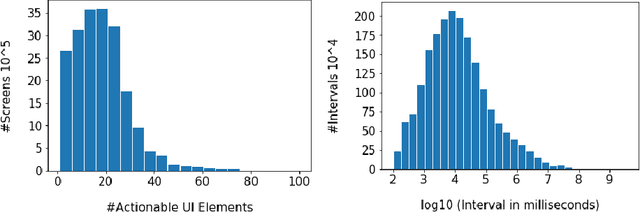
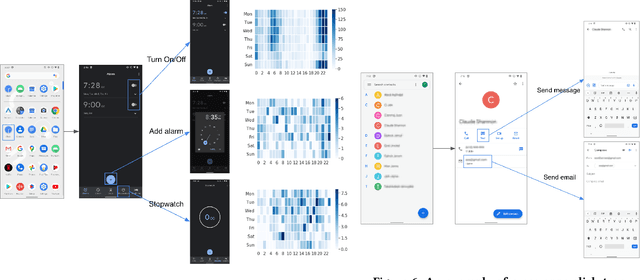
Modeling tap or click sequences of users on a mobile device can improve our understandings of interaction behavior and offers opportunities for UI optimization by recommending next element the user might want to click on. We analyzed a large-scale dataset of over 20 million clicks from more than 4,000 mobile users who opted in. We then designed a deep learning model that predicts the next element that the user clicks given the user's click history, the structural information of the UI screen, and the current context such as the time of the day. We thoroughly investigated the deep model by comparing it with a set of baseline methods based on the dataset. The experiments show that our model achieves 48% and 71% accuracy (top-1 and top-3) for predicting next clicks based on a held-out dataset of test users, which significantly outperformed all the baseline methods with a large margin. We discussed a few scenarios for integrating the model in mobile interaction and how users can potentially benefit from the model.
DeepCVA: Automated Commit-level Vulnerability Assessment with Deep Multi-task Learning
Aug 18, 2021
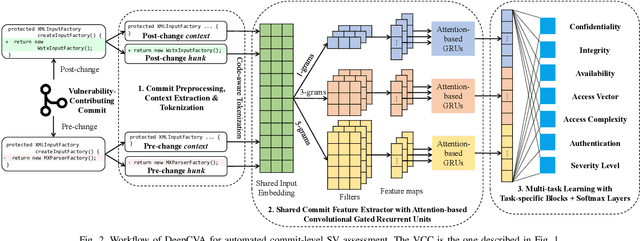

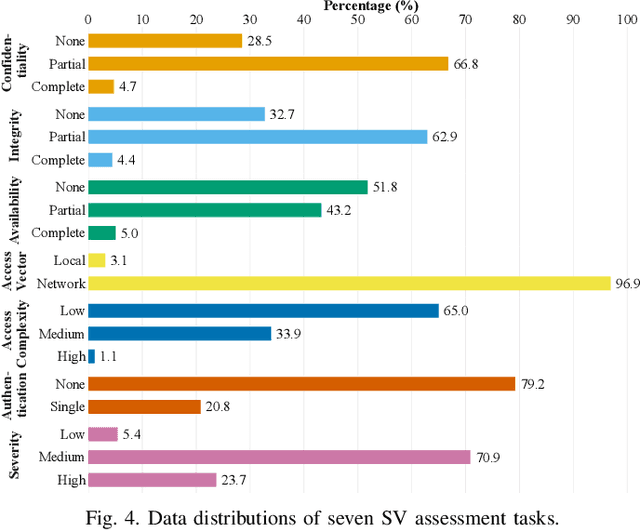
It is increasingly suggested to identify Software Vulnerabilities (SVs) in code commits to give early warnings about potential security risks. However, there is a lack of effort to assess vulnerability-contributing commits right after they are detected to provide timely information about the exploitability, impact and severity of SVs. Such information is important to plan and prioritize the mitigation for the identified SVs. We propose a novel Deep multi-task learning model, DeepCVA, to automate seven Commit-level Vulnerability Assessment tasks simultaneously based on Common Vulnerability Scoring System (CVSS) metrics. We conduct large-scale experiments on 1,229 vulnerability-contributing commits containing 542 different SVs in 246 real-world software projects to evaluate the effectiveness and efficiency of our model. We show that DeepCVA is the best-performing model with 38% to 59.8% higher Matthews Correlation Coefficient than many supervised and unsupervised baseline models. DeepCVA also requires 6.3 times less training and validation time than seven cumulative assessment models, leading to significantly less model maintenance cost as well. Overall, DeepCVA presents the first effective and efficient solution to automatically assess SVs early in software systems.
Data-Free Evaluation of User Contributions in Federated Learning
Aug 24, 2021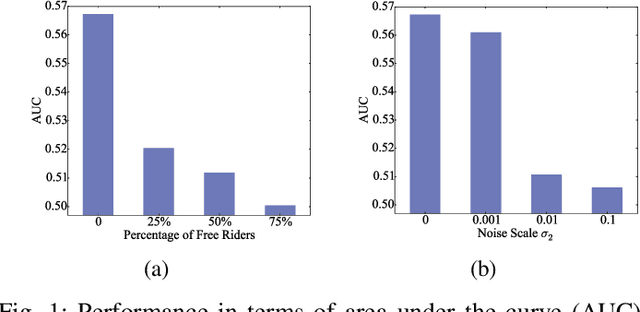
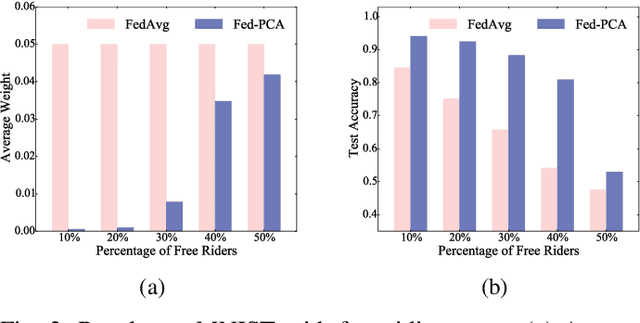
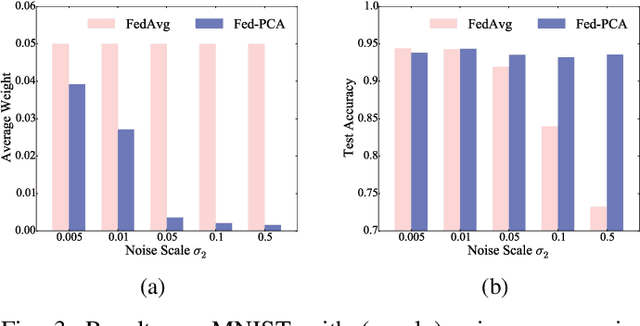
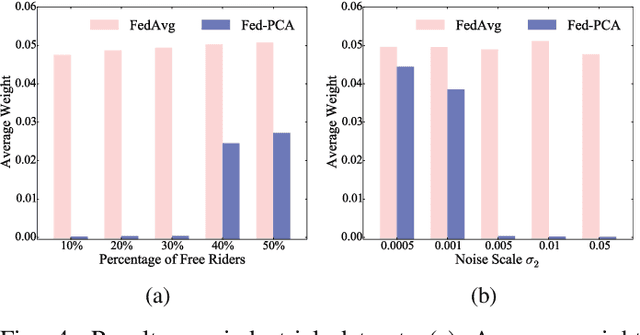
Federated learning (FL) trains a machine learning model on mobile devices in a distributed manner using each device's private data and computing resources. A critical issues is to evaluate individual users' contributions so that (1) users' effort in model training can be compensated with proper incentives and (2) malicious and low-quality users can be detected and removed. The state-of-the-art solutions require a representative test dataset for the evaluation purpose, but such a dataset is often unavailable and hard to synthesize. In this paper, we propose a method called Pairwise Correlated Agreement (PCA) based on the idea of peer prediction to evaluate user contribution in FL without a test dataset. PCA achieves this using the statistical correlation of the model parameters uploaded by users. We then apply PCA to designing (1) a new federated learning algorithm called Fed-PCA, and (2) a new incentive mechanism that guarantees truthfulness. We evaluate the performance of PCA and Fed-PCA using the MNIST dataset and a large industrial product recommendation dataset. The results demonstrate that our Fed-PCA outperforms the canonical FedAvg algorithm and other baseline methods in accuracy, and at the same time, PCA effectively incentivizes users to behave truthfully.
A Neighbourhood Framework for Resource-Lean Content Flagging
Mar 31, 2021
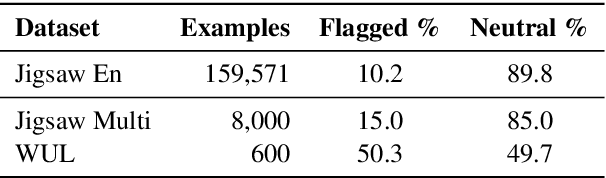
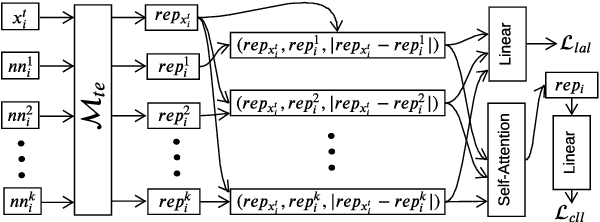
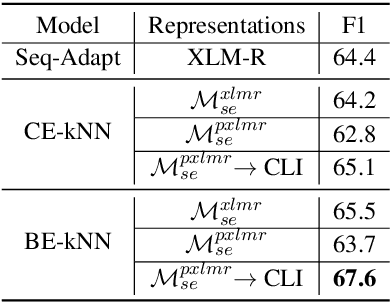
We propose a novel interpretable framework for cross-lingual content flagging, which significantly outperforms prior work both in terms of predictive performance and average inference time. The framework is based on a nearest-neighbour architecture and is interpretable by design. Moreover, it can easily adapt to new instances without the need to retrain it from scratch. Unlike prior work, (i) we encode not only the texts, but also the labels in the neighbourhood space (which yields better accuracy), and (ii) we use a bi-encoder instead of a cross-encoder (which saves computation time). Our evaluation results on ten different datasets for abusive language detection in eight languages shows sizable improvements over the state of the art, as well as a speed-up at inference time.