 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Qualitative Study on Using ChatGPT for Software Security: Perception vs. Practicality
Aug 01, 2024



Artificial Intelligence (AI) advancements have enabled the development of Large Language Models (LLMs) that can perform a variety of tasks with remarkable semantic understanding and accuracy. ChatGPT is one such LLM that has gained significant attention due to its impressive capabilities for assisting in various knowledge-intensive tasks. Due to the knowledge-intensive nature of engineering secure software, ChatGPT's assistance is expected to be explored for security-related tasks during the development/evolution of software. To gain an understanding of the potential of ChatGPT as an emerging technology for supporting software security, we adopted a two-fold approach. Initially, we performed an empirical study to analyse the perceptions of those who had explored the use of ChatGPT for security tasks and shared their views on Twitter. It was determined that security practitioners view ChatGPT as beneficial for various software security tasks, including vulnerability detection, information retrieval, and penetration testing. Secondly, we designed an experiment aimed at investigating the practicality of this technology when deployed as an oracle in real-world settings. In particular, we focused on vulnerability detection and qualitatively examined ChatGPT outputs for given prompts within this prominent software security task. Based on our analysis, responses from ChatGPT in this task are largely filled with generic security information and may not be appropriate for industry use. To prevent data leakage, we performed this analysis on a vulnerability dataset compiled after the OpenAI data cut-off date from real-world projects covering 40 distinct vulnerability types and 12 programming languages. We assert that the findings from this study would contribute to future research aimed at developing and evaluating LLMs dedicated to software security.
DeepCVA: Automated Commit-level Vulnerability Assessment with Deep Multi-task Learning
Aug 18, 2021
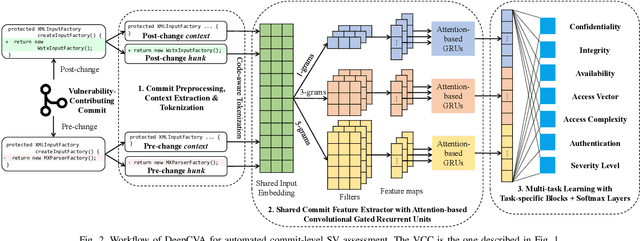

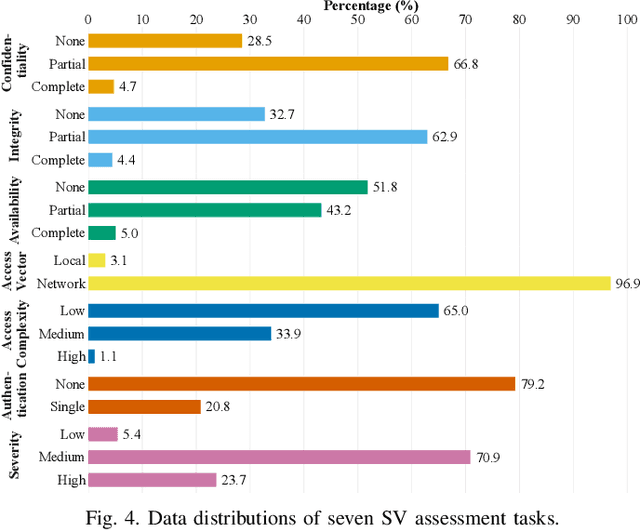
It is increasingly suggested to identify Software Vulnerabilities (SVs) in code commits to give early warnings about potential security risks. However, there is a lack of effort to assess vulnerability-contributing commits right after they are detected to provide timely information about the exploitability, impact and severity of SVs. Such information is important to plan and prioritize the mitigation for the identified SVs. We propose a novel Deep multi-task learning model, DeepCVA, to automate seven Commit-level Vulnerability Assessment tasks simultaneously based on Common Vulnerability Scoring System (CVSS) metrics. We conduct large-scale experiments on 1,229 vulnerability-contributing commits containing 542 different SVs in 246 real-world software projects to evaluate the effectiveness and efficiency of our model. We show that DeepCVA is the best-performing model with 38% to 59.8% higher Matthews Correlation Coefficient than many supervised and unsupervised baseline models. DeepCVA also requires 6.3 times less training and validation time than seven cumulative assessment models, leading to significantly less model maintenance cost as well. Overall, DeepCVA presents the first effective and efficient solution to automatically assess SVs early in software systems.
PUMiner: Mining Security Posts from Developer Question and Answer Websites with PU Learning
Mar 08, 2020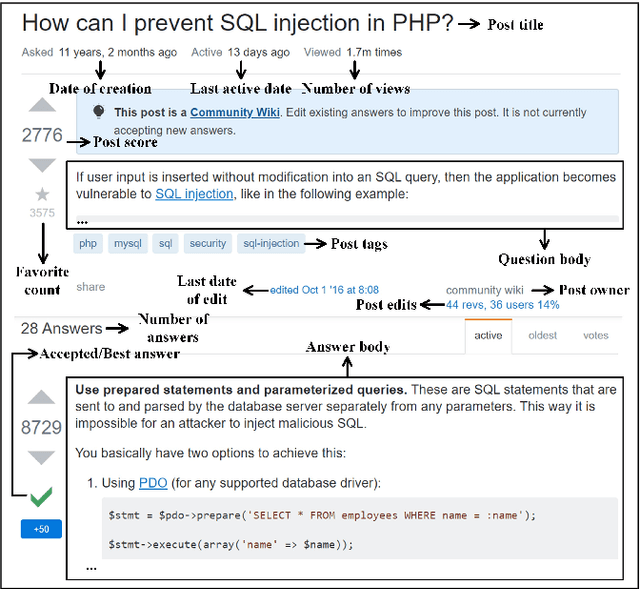
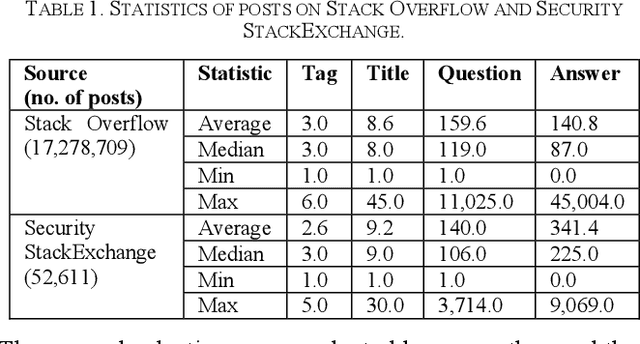
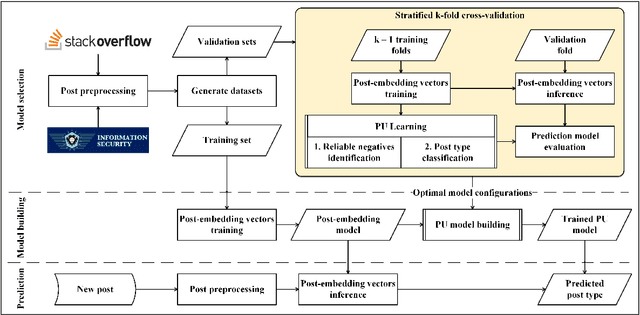
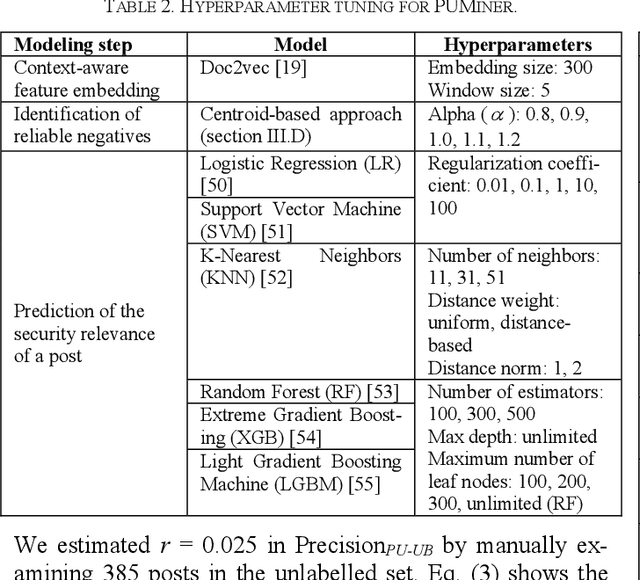
Security is an increasing concern in software development. Developer Question and Answer (Q&A) websites provide a large amount of security discussion. Existing studies have used human-defined rules to mine security discussions, but these works still miss many posts, which may lead to an incomplete analysis of the security practices reported on Q&A websites. Traditional supervised Machine Learning methods can automate the mining process; however, the required negative (non-security) class is too expensive to obtain. We propose a novel learning framework, PUMiner, to automatically mine security posts from Q&A websites. PUMiner builds a context-aware embedding model to extract features of the posts, and then develops a two-stage PU model to identify security content using the labelled Positive and Unlabelled posts. We evaluate PUMiner on more than 17.2 million posts on Stack Overflow and 52,611 posts on Security StackExchange. We show that PUMiner is effective with the validation performance of at least 0.85 across all model configurations. Moreover, Matthews Correlation Coefficient (MCC) of PUMiner is 0.906, 0.534 and 0.084 points higher than one-class SVM, positive-similarity filtering, and one-stage PU models on unseen testing posts, respectively. PUMiner also performs well with an MCC of 0.745 for scenarios where string matching totally fails. Even when the ratio of the labelled positive posts to the unlabelled ones is only 1:100, PUMiner still achieves a strong MCC of 0.65, which is 160% better than fully-supervised learning. Using PUMiner, we provide the largest and up-to-date security content on Q&A websites for practitioners and researchers.