 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Model-Based Real-Time Motion Tracking using Dynamical Inverse Kinematics
Sep 17, 2019
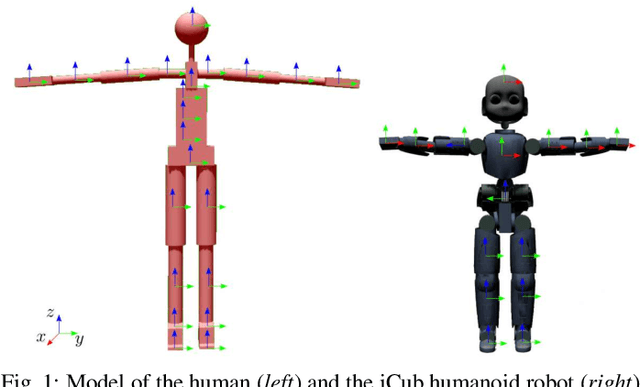
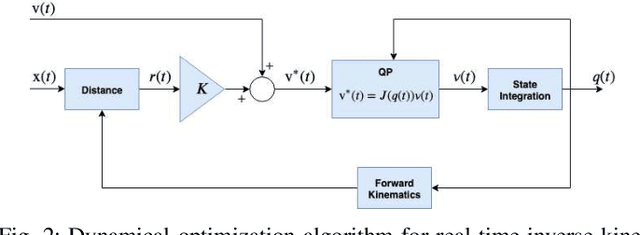
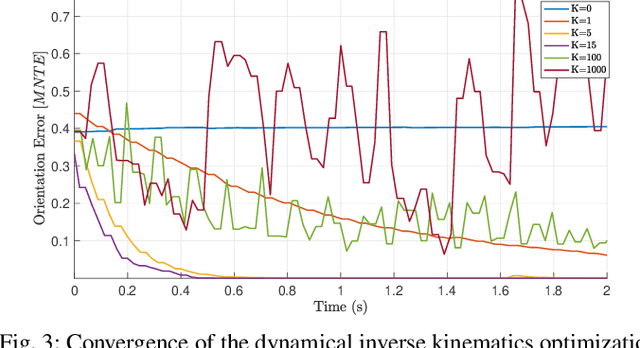
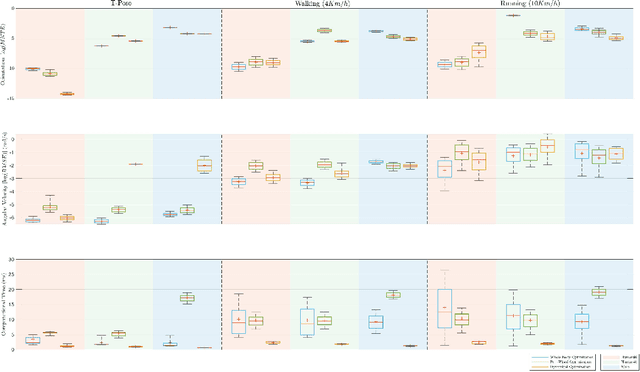
This paper contributes towards the development of motion tracking algorithms for time-critical applications, proposing an infrastructure for solving dynamically the inverse kinematics of human models. We present a method based on the integration of the differential kinematics, and for which the convergence is proved using Lyapunov analysis. The method is tested in an experimental scenario where the motion of a subject is tracked in static and dynamic configurations, and the inverse kinematics is solved both for human and humanoid models. The architecture is evaluated both terms of accuracy and computational load, and compared to iterative optimization algorithms.
One-shot domain adaptation for semantic face editing of real world images using StyleALAE
Aug 31, 2021

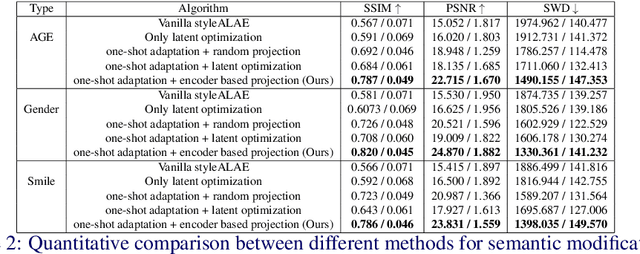

Semantic face editing of real world facial images is an important application of generative models. Recently, multiple works have explored possible techniques to generate such modifications using the latent structure of pre-trained GAN models. However, such approaches often require training an encoder network and that is typically a time-consuming and resource intensive process. A possible alternative to such a GAN-based architecture can be styleALAE, a latent-space based autoencoder that can generate photo-realistic images of high quality. Unfortunately, the reconstructed image in styleALAE does not preserve the identity of the input facial image. This limits the application of styleALAE for semantic face editing of images with known identities. In our work, we use a recent advancement in one-shot domain adaptation to address this problem. Our work ensures that the identity of the reconstructed image is the same as the given input image. We further generate semantic modifications over the reconstructed image by using the latent space of the pre-trained styleALAE model. Results show that our approach can generate semantic modifications on any real world facial image while preserving the identity.
Efficient Algorithms for Learning Depth-2 Neural Networks with General ReLU Activations
Aug 01, 2021We present polynomial time and sample efficient algorithms for learning an unknown depth-2 feedforward neural network with general ReLU activations, under mild non-degeneracy assumptions. In particular, we consider learning an unknown network of the form $f(x) = {a}^{\mathsf{T}}\sigma({W}^\mathsf{T}x+b)$, where $x$ is drawn from the Gaussian distribution, and $\sigma(t) := \max(t,0)$ is the ReLU activation. Prior works for learning networks with ReLU activations assume that the bias $b$ is zero. In order to deal with the presence of the bias terms, our proposed algorithm consists of robustly decomposing multiple higher order tensors arising from the Hermite expansion of the function $f(x)$. Using these ideas we also establish identifiability of the network parameters under minimal assumptions.
Robust Segmentation Models using an Uncertainty Slice Sampling Based Annotation Workflow
Sep 30, 2021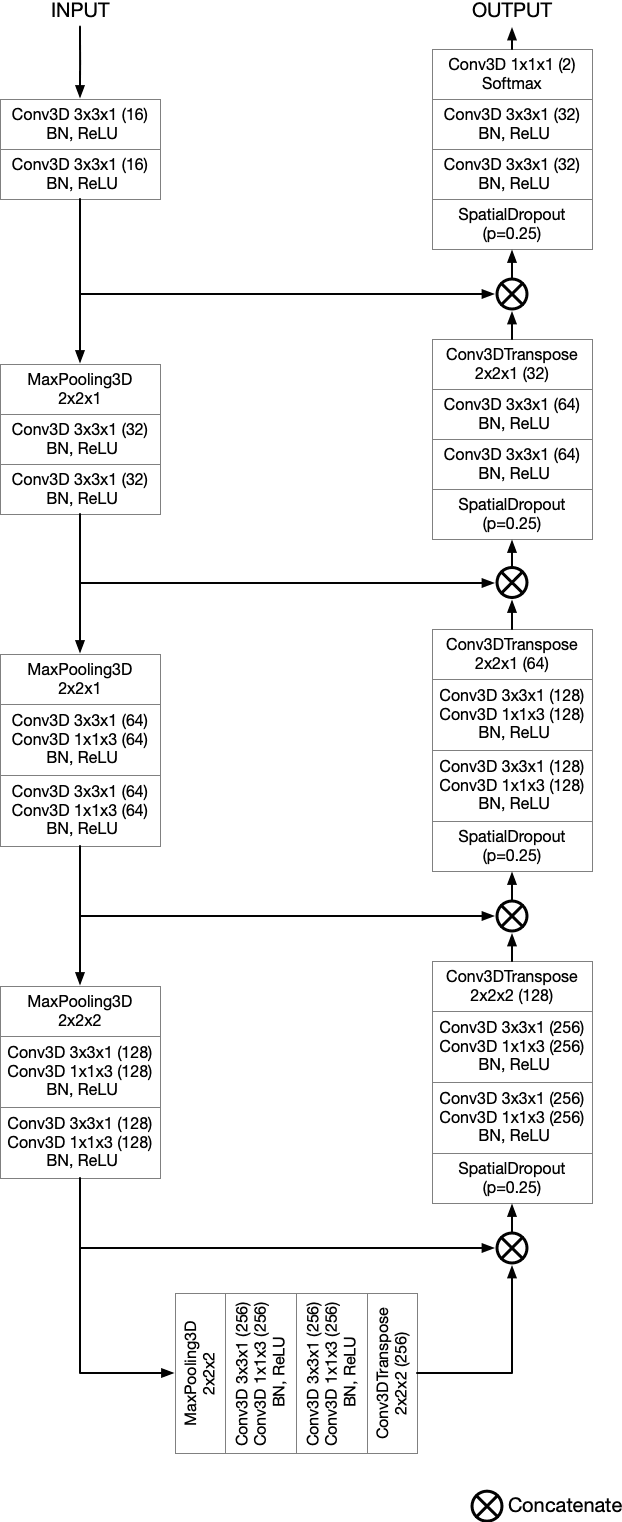
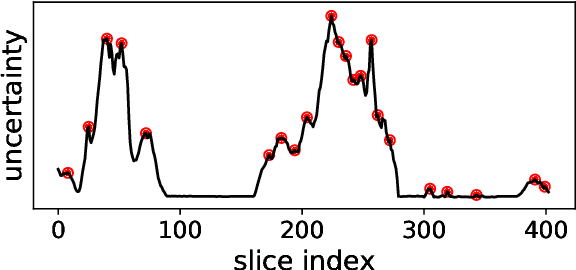
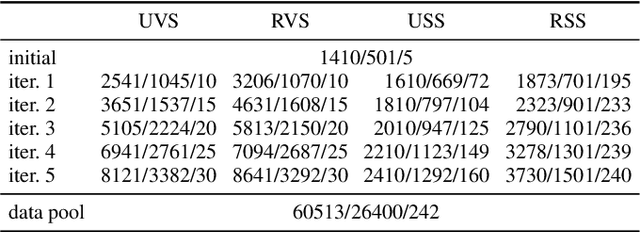
Semantic segmentation neural networks require pixel-level annotations in large quantities to achieve a good performance. In the medical domain, such annotations are expensive, because they are time-consuming and require expert knowledge. Active learning optimizes the annotation effort by devising strategies to select cases for labeling that are most informative to the model. In this work, we propose an uncertainty slice sampling (USS) strategy for semantic segmentation of 3D medical volumes that selects 2D image slices for annotation and compare it with various other strategies. We demonstrate the efficiency of USS on a CT liver segmentation task using multi-site data. After five iterations, the training data resulting from USS consisted of 2410 slices (4% of all slices in the data pool) compared to 8121 (13%), 8641 (14%), and 3730 (6%) for uncertainty volume (UVS), random volume (RVS), and random slice (RSS) sampling, respectively. Despite being trained on the smallest amount of data, the model based on the USS strategy evaluated on 234 test volumes significantly outperformed models trained according to other strategies and achieved a mean Dice index of 0.964, a relative volume error of 4.2%, a mean surface distance of 1.35 mm, and a Hausdorff distance of 23.4 mm. This was only slightly inferior to 0.967, 3.8%, 1.18 mm, and 22.9 mm achieved by a model trained on all available data, but the robustness analysis using the 5th percentile of Dice and the 95th percentile of the remaining metrics demonstrated that USS resulted not only in the most robust model compared to other sampling schemes, but also outperformed the model trained on all data according to Dice (0.946 vs. 0.945) and mean surface distance (1.92 mm vs. 2.03 mm).
From Zero-Shot Machine Learning to Zero-Day Attack Detection
Sep 30, 2021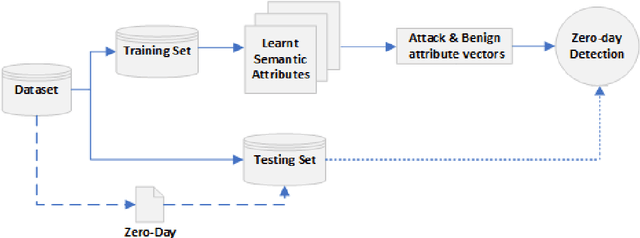
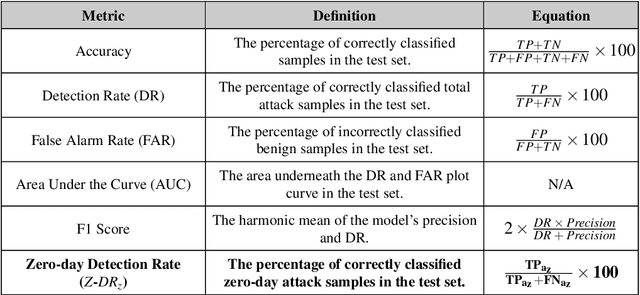

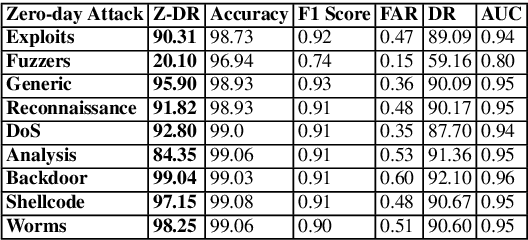
The standard ML methodology assumes that the test samples are derived from a set of pre-observed classes used in the training phase. Where the model extracts and learns useful patterns to detect new data samples belonging to the same data classes. However, in certain applications such as Network Intrusion Detection Systems, it is challenging to obtain data samples for all attack classes that the model will most likely observe in production. ML-based NIDSs face new attack traffic known as zero-day attacks, that are not used in the training of the learning models due to their non-existence at the time. In this paper, a zero-shot learning methodology has been proposed to evaluate the ML model performance in the detection of zero-day attack scenarios. In the attribute learning stage, the ML models map the network data features to distinguish semantic attributes from known attack (seen) classes. In the inference stage, the models are evaluated in the detection of zero-day attack (unseen) classes by constructing the relationships between known attacks and zero-day attacks. A new metric is defined as Zero-day Detection Rate, which measures the effectiveness of the learning model in the inference stage. The results demonstrate that while the majority of the attack classes do not represent significant risks to organisations adopting an ML-based NIDS in a zero-day attack scenario. However, for certain attack groups identified in this paper, such systems are not effective in applying the learnt attributes of attack behaviour to detect them as malicious. Further Analysis was conducted using the Wasserstein Distance technique to measure how different such attacks are from other attack types used in the training of the ML model. The results demonstrate that sophisticated attacks with a low zero-day detection rate have a significantly distinct feature distribution compared to the other attack classes.
On the Realization of Impulse Invariant Bilinear Volterra Kernels
Jul 12, 2021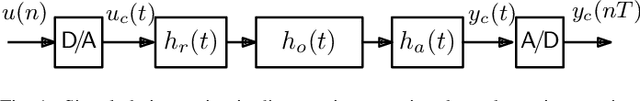

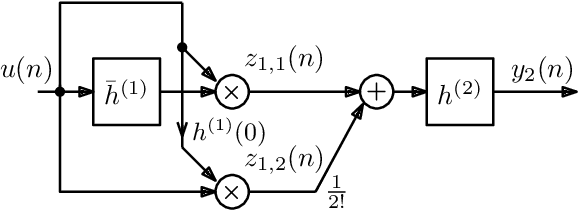
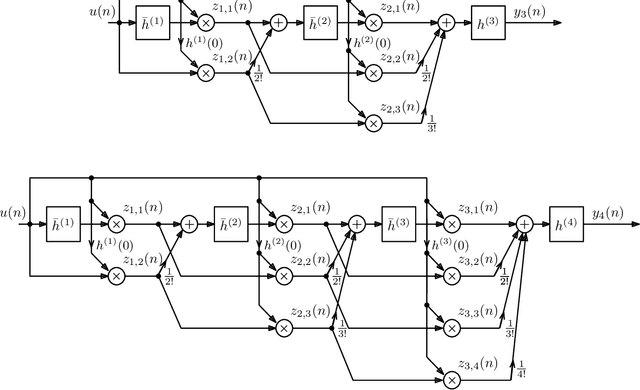
As previously shown, the direct extension of the impulse invariance principle to Volterra kernels has to be modified in order to provide a condition for the exact modeling of mixed-signal chains. At first sight this would seem to seriously complicate the otherwise simple discrete-time realization of separable kernels (among which bilinear kernels are of particular importance). We show here, however, that this not the case. By defining a cascade operator, the structure of a generalized impulse invariance can be unveiled, leading to a realization without an inordinate increase in computational complexity.
Pruning with Compensation: Efficient Channel Pruning for Deep Convolutional Neural Networks
Aug 31, 2021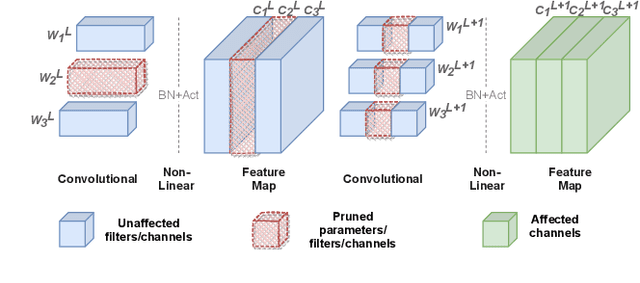
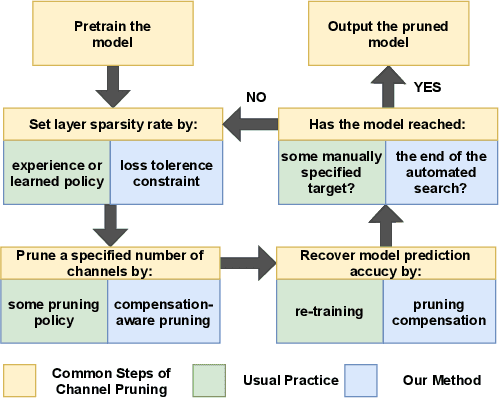
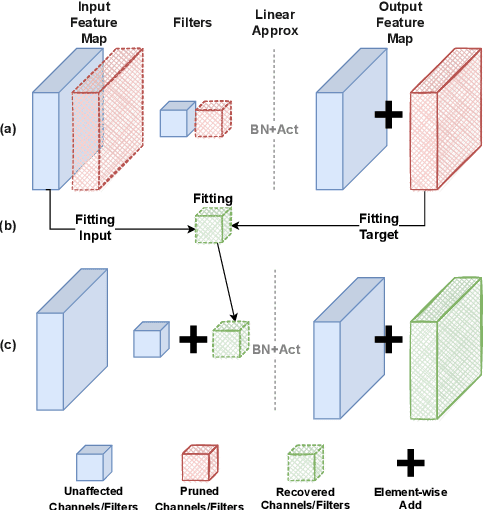
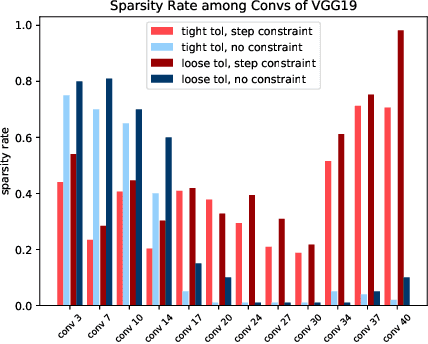
Channel pruning is a promising technique to compress the parameters of deep convolutional neural networks(DCNN) and to speed up the inference. This paper aims to address the long-standing inefficiency of channel pruning. Most channel pruning methods recover the prediction accuracy by re-training the pruned model from the remaining parameters or random initialization. This re-training process is heavily dependent on the sufficiency of computational resources, training data, and human interference(tuning the training strategy). In this paper, a highly efficient pruning method is proposed to significantly reduce the cost of pruning DCNN. The main contributions of our method include: 1) pruning compensation, a fast and data-efficient substitute of re-training to minimize the post-pruning reconstruction loss of features, 2) compensation-aware pruning(CaP), a novel pruning algorithm to remove redundant or less-weighted channels by minimizing the loss of information, and 3) binary structural search with step constraint to minimize human interference. On benchmarks including CIFAR-10/100 and ImageNet, our method shows competitive pruning performance among the state-of-the-art retraining-based pruning methods and, more importantly, reduces the processing time by 95% and data usage by 90%.
Analyzing the Abstractiveness-Factuality Tradeoff With Nonlinear Abstractiveness Constraints
Aug 05, 2021
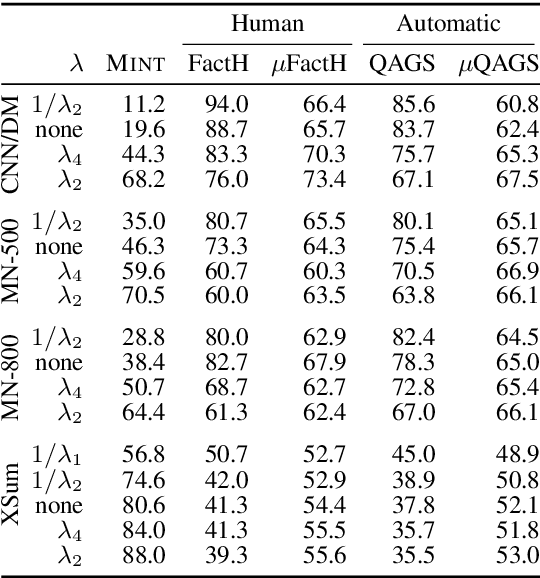
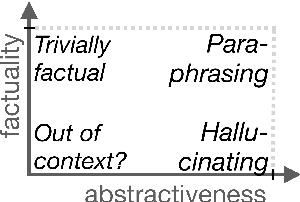
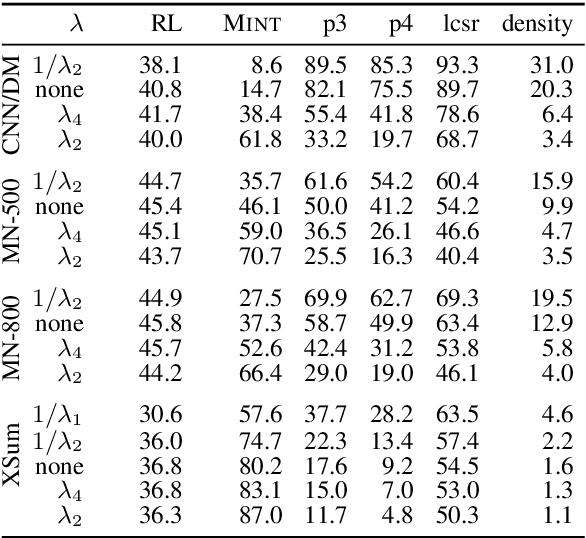
We analyze the tradeoff between factuality and abstractiveness of summaries. We introduce abstractiveness constraints to control the degree of abstractiveness at decoding time, and we apply this technique to characterize the abstractiveness-factuality tradeoff across multiple widely-studied datasets, using extensive human evaluations. We train a neural summarization model on each dataset and visualize the rates of change in factuality as we gradually increase abstractiveness using our abstractiveness constraints. We observe that, while factuality generally drops with increased abstractiveness, different datasets lead to different rates of factuality decay. We propose new measures to quantify the tradeoff between factuality and abstractiveness, incl. muQAGS, which balances factuality with abstractiveness. We also quantify this tradeoff in previous works, aiming to establish baselines for the abstractiveness-factuality tradeoff that future publications can compare against.
Inverse Aerodynamic Design of Gas Turbine Blades using Probabilistic Machine Learning
Aug 17, 2021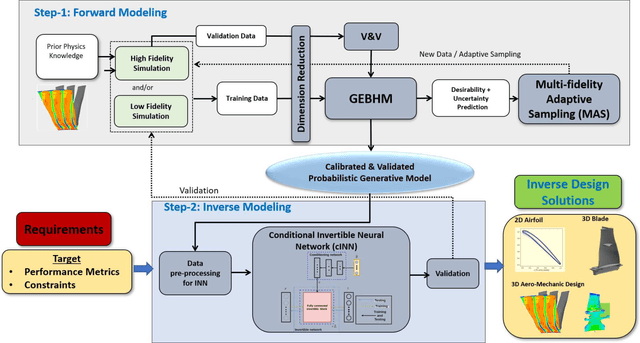

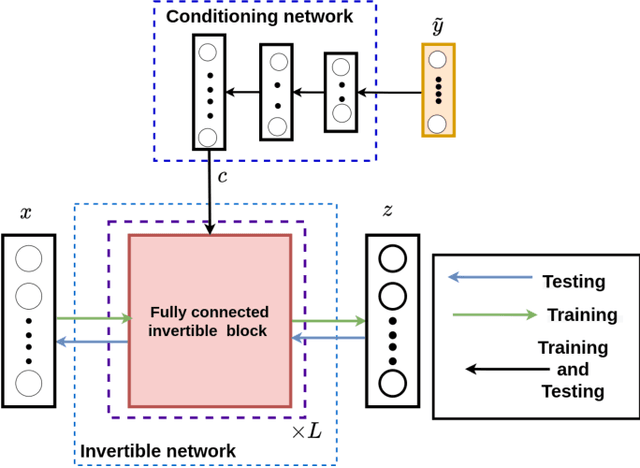
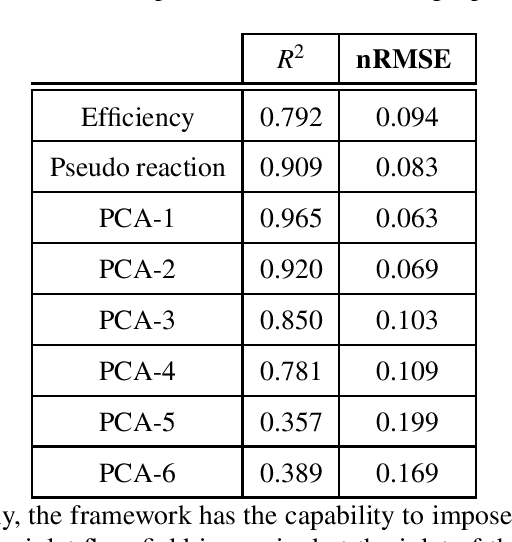
One of the critical components in Industrial Gas Turbines (IGT) is the turbine blade. Design of turbine blades needs to consider multiple aspects like aerodynamic efficiency, durability, safety and manufacturing, which make the design process sequential and iterative.The sequential nature of these iterations forces a long design cycle time, ranging from several months to years. Due to the reactionary nature of these iterations, little effort has been made to accumulate data in a manner that allows for deep exploration and understanding of the total design space. This is exemplified in the process of designing the individual components of the IGT resulting in a potential unrealized efficiency. To overcome the aforementioned challenges, we demonstrate a probabilistic inverse design machine learning framework (PMI), to carry out an explicit inverse design. PMI calculates the design explicitly without excessive costly iteration and overcomes the challenges associated with ill-posed inverse problems. In this work, the framework will be demonstrated on inverse aerodynamic design of three-dimensional turbine blades.
Streaming Belief Propagation for Community Detection
Jun 09, 2021

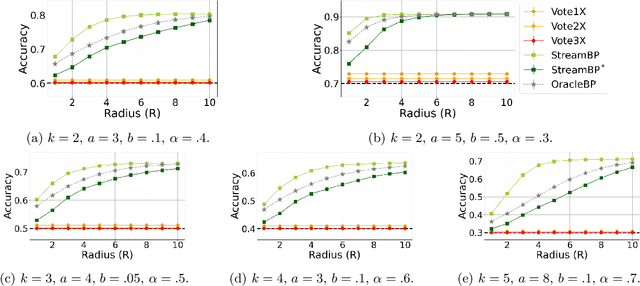
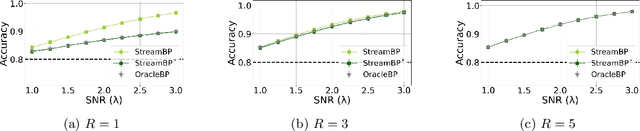
The community detection problem requires to cluster the nodes of a network into a small number of well-connected "communities". There has been substantial recent progress in characterizing the fundamental statistical limits of community detection under simple stochastic block models. However, in real-world applications, the network structure is typically dynamic, with nodes that join over time. In this setting, we would like a detection algorithm to perform only a limited number of updates at each node arrival. While standard voting approaches satisfy this constraint, it is unclear whether they exploit the network information optimally. We introduce a simple model for networks growing over time which we refer to as streaming stochastic block model (StSBM). Within this model, we prove that voting algorithms have fundamental limitations. We also develop a streaming belief-propagation (StreamBP) approach, for which we prove optimality in certain regimes. We validate our theoretical findings on synthetic and real data.