 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgnostic Learning of General ReLU Activation Using Gradient Descent
Aug 04, 2022We provide a convergence analysis of gradient descent for the problem of agnostically learning a single ReLU function under Gaussian distributions. Unlike prior work that studies the setting of zero bias, we consider the more challenging scenario when the bias of the ReLU function is non-zero. Our main result establishes that starting from random initialization, in a polynomial number of iterations gradient descent outputs, with high probability, a ReLU function that achieves a competitive error guarantee when compared to the error of the best ReLU function. We also provide finite sample guarantees, and these techniques generalize to a broader class of marginal distributions beyond Gaussians.
Efficient Algorithms for Learning Depth-2 Neural Networks with General ReLU Activations
Aug 01, 2021We present polynomial time and sample efficient algorithms for learning an unknown depth-2 feedforward neural network with general ReLU activations, under mild non-degeneracy assumptions. In particular, we consider learning an unknown network of the form $f(x) = {a}^{\mathsf{T}}\sigma({W}^\mathsf{T}x+b)$, where $x$ is drawn from the Gaussian distribution, and $\sigma(t) := \max(t,0)$ is the ReLU activation. Prior works for learning networks with ReLU activations assume that the bias $b$ is zero. In order to deal with the presence of the bias terms, our proposed algorithm consists of robustly decomposing multiple higher order tensors arising from the Hermite expansion of the function $f(x)$. Using these ideas we also establish identifiability of the network parameters under minimal assumptions.
Amazon SageMaker Autopilot: a white box AutoML solution at scale
Dec 16, 2020
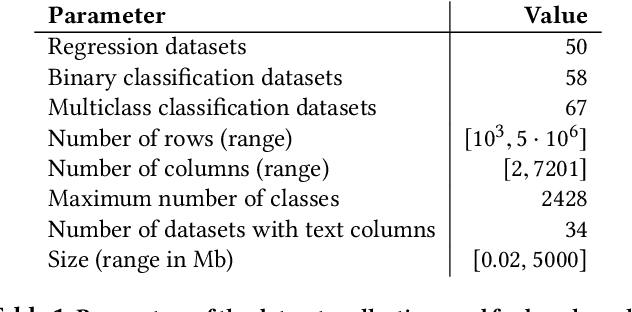
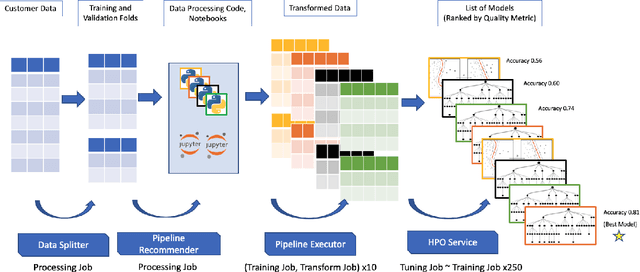
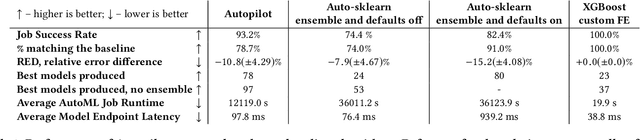
AutoML systems provide a black-box solution to machine learning problems by selecting the right way of processing features, choosing an algorithm and tuning the hyperparameters of the entire pipeline. Although these systems perform well on many datasets, there is still a non-negligible number of datasets for which the one-shot solution produced by each particular system would provide sub-par performance. In this paper, we present Amazon SageMaker Autopilot: a fully managed system providing an automated ML solution that can be modified when needed. Given a tabular dataset and the target column name, Autopilot identifies the problem type, analyzes the data and produces a diverse set of complete ML pipelines including feature preprocessing and ML algorithms, which are tuned to generate a leaderboard of candidate models. In the scenario where the performance is not satisfactory, a data scientist is able to view and edit the proposed ML pipelines in order to infuse their expertise and business knowledge without having to revert to a fully manual solution. This paper describes the different components of Autopilot, emphasizing the infrastructure choices that allow scalability, high quality models, editable ML pipelines, consumption of artifacts of offline meta-learning, and a convenient integration with the entire SageMaker suite allowing these trained models to be used in a production setting.