 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Devil Is in the Details: An Efficient Convolutional Neural Network for Transport Mode Detection
Sep 16, 2021
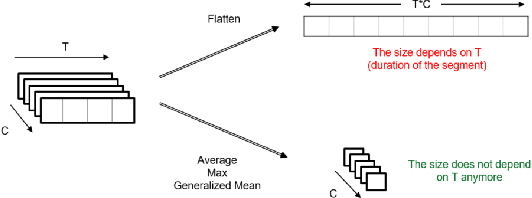
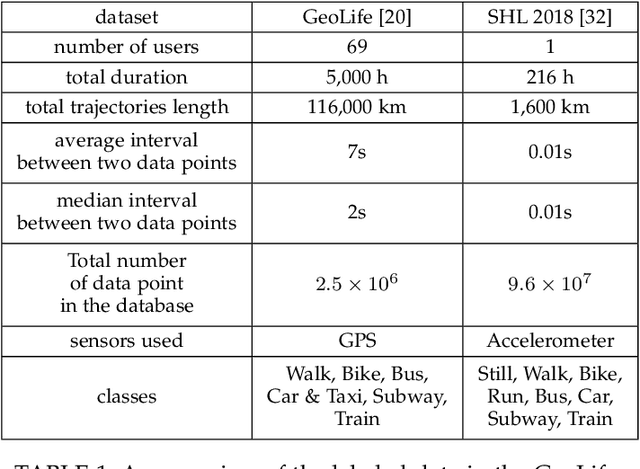
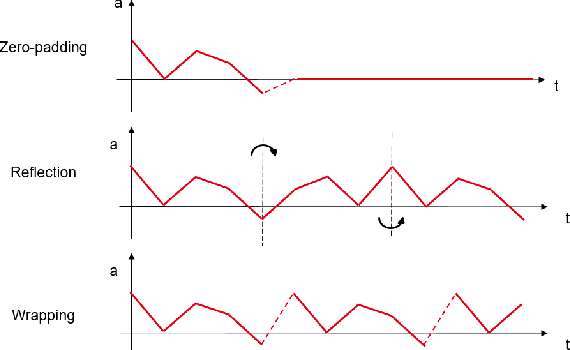
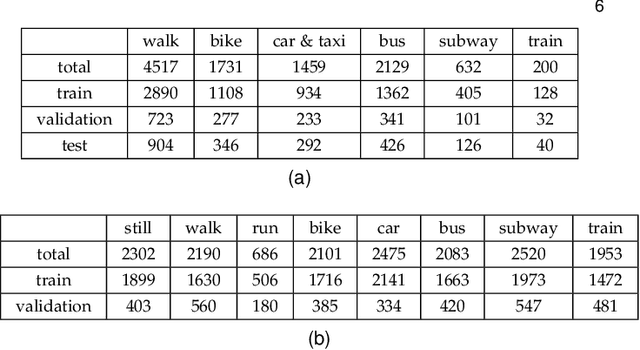
Transport mode detection is a classification problem aiming to design an algorithm that can infer the transport mode of a user given multimodal signals (GPS and/or inertial sensors). It has many applications, such as carbon footprint tracking, mobility behaviour analysis, or real-time door-to-door smart planning. Most current approaches rely on a classification step using Machine Learning techniques, and, like in many other classification problems, deep learning approaches usually achieve better results than traditional machine learning ones using handcrafted features. Deep models, however, have a notable downside: they are usually heavy, both in terms of memory space and processing cost. We show that a small, optimized model can perform as well as a current deep model. During our experiments on the GeoLife and SHL 2018 datasets, we obtain models with tens of thousands of parameters, that is, 10 to 1,000 times less parameters and operations than networks from the state of the art, which still reach a comparable performance. We also show, using the aforementioned datasets, that the current preprocessing used to deal with signals of different lengths is suboptimal, and we provide better replacements. Finally, we introduce a way to use signals with different lengths with the lighter Convolutional neural networks, without using the heavier Recurrent Neural Networks.
* 13 pages, 5 figures, 6 tables. Published in IEEE Transactions on Intelligent Transportation Systems
Adversarial Robustness Verification and Attack Synthesis in Stochastic Systems
Oct 05, 2021
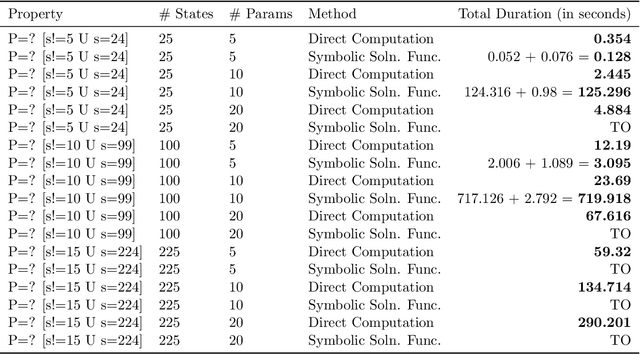
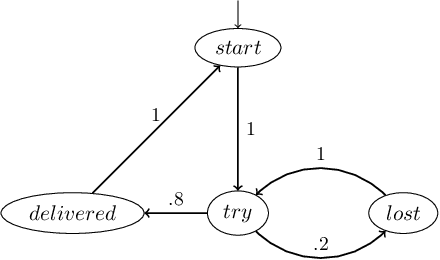

Probabilistic model checking is a useful technique for specifying and verifying properties of stochastic systems including randomized protocols and the theoretical underpinnings of reinforcement learning models. However, these methods rely on the assumed structure and probabilities of certain system transitions. These assumptions may be incorrect, and may even be violated in the event that an adversary gains control of some or all components in the system. In this paper, motivated by research in adversarial machine learning on adversarial examples, we develop a formal framework for adversarial robustness in systems defined as discrete time Markov chains (DTMCs), and extend to include deterministic, memoryless policies acting in Markov decision processes (MDPs). Our framework includes a flexible approach for specifying several adversarial models with different capabilities to manipulate the system. We outline a class of threat models under which adversaries can perturb system transitions, constrained by an $\varepsilon$ ball around the original transition probabilities and define four specific instances of this threat model. We define three main DTMC adversarial robustness problems and present two optimization-based solutions, leveraging traditional and parametric probabilistic model checking techniques. We then evaluate our solutions on two stochastic protocols and a collection of GridWorld case studies, which model an agent acting in an environment described as an MDP. We find that the parametric solution results in fast computation for small parameter spaces. In the case of less restrictive (stronger) adversaries, the number of parameters increases, and directly computing property satisfaction probabilities is more scalable. We demonstrate the usefulness of our definitions and solutions by comparing system outcomes over various properties, threat models, and case studies.
Learning Latent Actions without Human Demonstrations
Sep 21, 2021

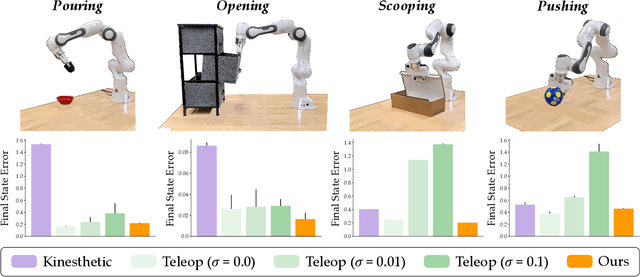
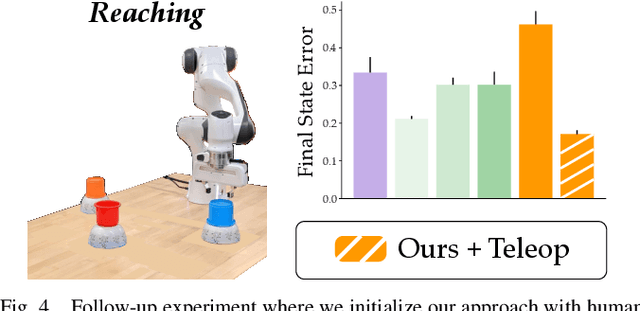
We can make it easier for disabled users to control assistive robots by mapping the user's low-dimensional joystick inputs to high-dimensional, complex actions. Prior works learn these mappings from human demonstrations: a non-disabled human either teleoperates or kinesthetically guides the robot arm through a variety of motions, and the robot learns to reproduce the demonstrated behaviors. But this framework is often impractical -- disabled users will not always have access to external demonstrations! Here we instead learn diverse teleoperation mappings without either human demonstrations or pre-defined tasks. Under our unsupervised approach the robot first optimizes for object state entropy: i.e., the robot autonomously learns to push, pull, open, close, or otherwise change the state of nearby objects. We then embed these diverse, object-oriented behaviors into a latent space for real-time control: now pressing the joystick causes the robot to perform dexterous motions like pushing or opening. We experimentally show that -- with a best-case human operator -- our unsupervised approach actually outperforms the teleoperation mappings learned from human demonstrations, particularly if those demonstrations are noisy or imperfect. But user study results are less clear-cut: although our approach enables participants to complete tasks with multiple objects more quickly, the unsupervised mapping also learns motions that the human does not need, and these additional behaviors may confuse the human. Videos of the user study: https://youtu.be/BkqHQjsUKDg
RoR: Read-over-Read for Long Document Machine Reading Comprehension
Sep 10, 2021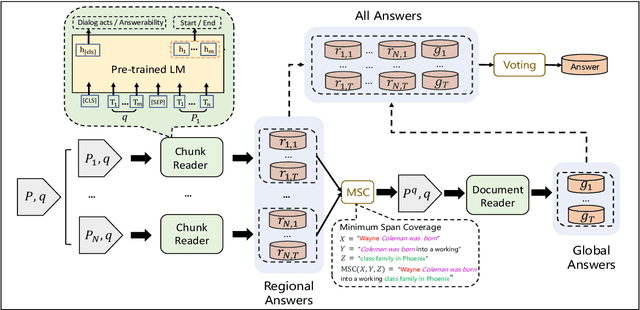
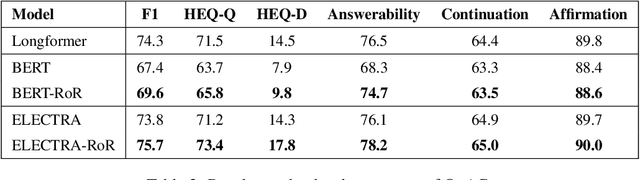
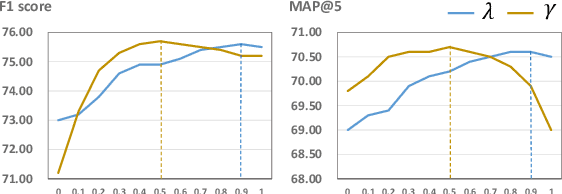
Transformer-based pre-trained models, such as BERT, have achieved remarkable results on machine reading comprehension. However, due to the constraint of encoding length (e.g., 512 WordPiece tokens), a long document is usually split into multiple chunks that are independently read. It results in the reading field being limited to individual chunks without information collaboration for long document machine reading comprehension. To address this problem, we propose RoR, a read-over-read method, which expands the reading field from chunk to document. Specifically, RoR includes a chunk reader and a document reader. The former first predicts a set of regional answers for each chunk, which are then compacted into a highly-condensed version of the original document, guaranteeing to be encoded once. The latter further predicts the global answers from this condensed document. Eventually, a voting strategy is utilized to aggregate and rerank the regional and global answers for final prediction. Extensive experiments on two benchmarks QuAC and TriviaQA demonstrate the effectiveness of RoR for long document reading. Notably, RoR ranks 1st place on the QuAC leaderboard (https://quac.ai/) at the time of submission (May 17th, 2021).
Learning Observation-Based Certifiable Safe Policy for Decentralized Multi-Robot Navigation
Sep 16, 2021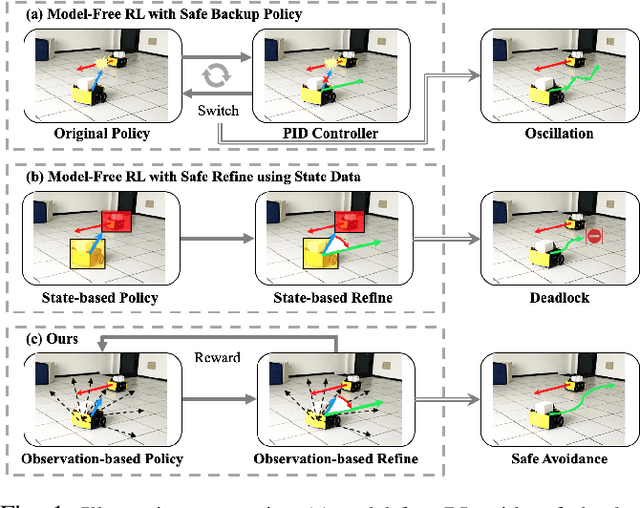
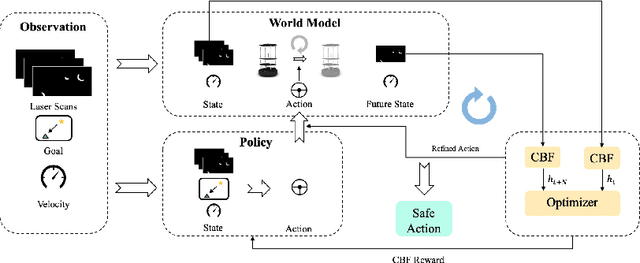
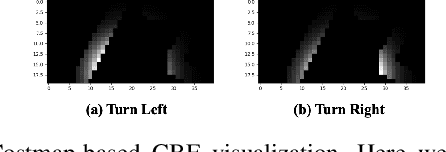
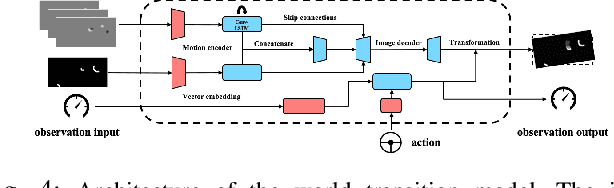
Safety is of great importance in multi-robot navigation problems. In this paper, we propose a control barrier function (CBF) based optimizer that ensures robot safety with both high probability and flexibility, using only sensor measurement. The optimizer takes action commands from the policy network as initial values and then provides refinement to drive the potentially dangerous ones back into safe regions. With the help of a deep transition model that predicts the evolution of surrounding dynamics and the consequences of different actions, the CBF module can guide the optimization in a reasonable time horizon. We also present a novel joint training framework that improves the cooperation between the Reinforcement Learning (RL) based policy and the CBF-based optimizer both in training and inference procedures by utilizing reward feedback from the CBF module. We observe that the policy using our method can achieve a higher success rate while maintaining the safety of multiple robots in significantly fewer episodes compared with other methods. Experiments are conducted in multiple scenarios both in simulation and the real world, the results demonstrate the effectiveness of our method in maintaining the safety of multi-robot navigation. Code is available at \url{https://github.com/YuxiangCui/MARL-OCBF
Detecting Anomalies in Semantic Segmentation with Prototypes
Jun 01, 2021
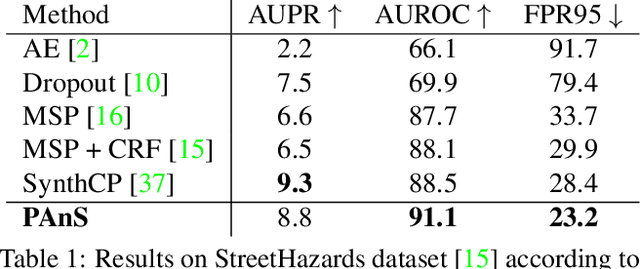


Traditional semantic segmentation methods can recognize at test time only the classes that are present in the training set. This is a significant limitation, especially for semantic segmentation algorithms mounted on intelligent autonomous systems, deployed in realistic settings. Regardless of how many classes the system has seen at training time, it is inevitable that unexpected, unknown objects will appear at test time. The failure in identifying such anomalies may lead to incorrect, even dangerous behaviors of the autonomous agent equipped with such segmentation model when deployed in the real world. Current state of the art of anomaly segmentation uses generative models, exploiting their incapability to reconstruct patterns unseen during training. However, training these models is expensive, and their generated artifacts may create false anomalies. In this paper we take a different route and we propose to address anomaly segmentation through prototype learning. Our intuition is that anomalous pixels are those that are dissimilar to all class prototypes known by the model. We extract class prototypes from the training data in a lightweight manner using a cosine similarity-based classifier. Experiments on StreetHazards show that our approach achieves the new state of the art, with a significant margin over previous works, despite the reduced computational overhead. Code is available at https://github.com/DarioFontanel/PAnS.
On the Equivalence Between Temporal and Static Graph Representations for Observational Predictions
Mar 12, 2021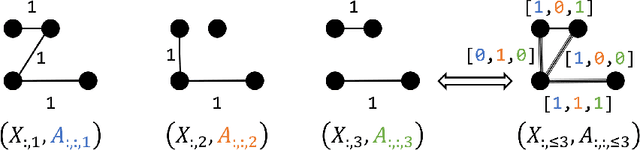
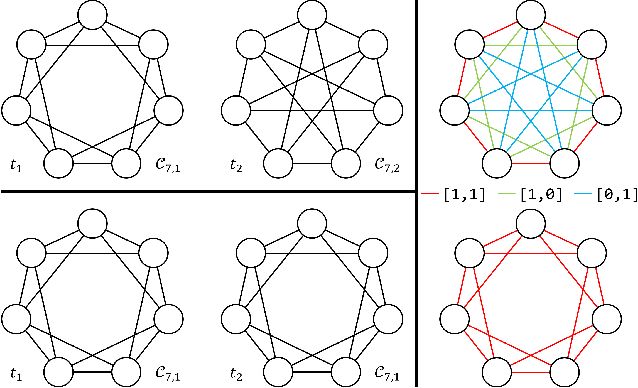
In this work we formalize the (pure observational) task of predicting node attribute evolution in temporal graphs. We show that node representations of temporal graphs can be cast into two distinct frameworks: (a) The de-facto standard approach, which we denote {\em time-and-graph}, where equivariant graph (e.g., GNN) and sequence (e.g., RNN) representations are intertwined to represent the temporal evolution of the graph; and (b) an approach that we denote {\em time-then-graph}, where the sequences describing the node and edge dynamics are represented first (e.g., RNN), then fed as node and edge attributes into a (static) equivariant graph representation that comes after (e.g., GNN). In real-world datasets, we show that our {\em time-then-graph} framework achieves the same prediction performance as state-of-the-art {\em time-and-graph} methods. Interestingly, {\em time-then-graph} representations have an expressiveness advantage over {\em time-and-graph} representations when both use component GNNs that are not most-expressive (e.g., 1-Weisfeiler-Lehman GNNs). We introduce a task where this expressiveness advantage allows {\em time-then-graph} methods to succeed while state-of-the-art {\em time-and-graph} methods fail.
Dynamic Terminology Integration for COVID-19 and other Emerging Domains
Sep 10, 2021
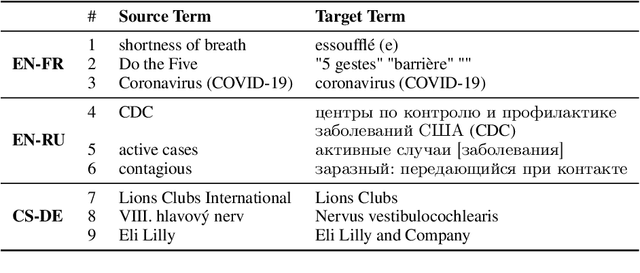
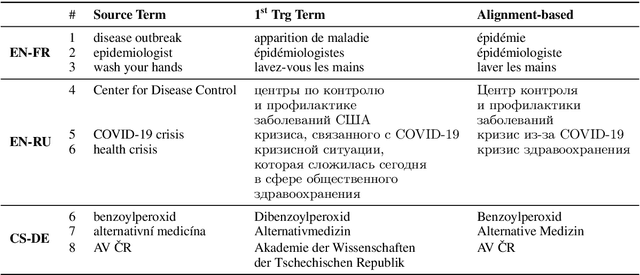
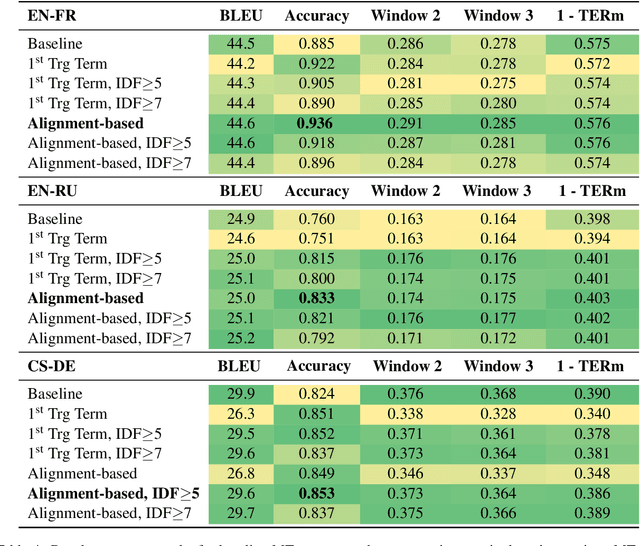
The majority of language domains require prudent use of terminology to ensure clarity and adequacy of information conveyed. While the correct use of terminology for some languages and domains can be achieved by adapting general-purpose MT systems on large volumes of in-domain parallel data, such quantities of domain-specific data are seldom available for less-resourced languages and niche domains. Furthermore, as exemplified by COVID-19 recently, no domain-specific parallel data is readily available for emerging domains. However, the gravity of this recent calamity created a high demand for reliable translation of critical information regarding pandemic and infection prevention. This work is part of WMT2021 Shared Task: Machine Translation using Terminologies, where we describe Tilde MT systems that are capable of dynamic terminology integration at the time of translation. Our systems achieve up to 94% COVID-19 term use accuracy on the test set of the EN-FR language pair without having access to any form of in-domain information during system training. We conclude our work with a broader discussion considering the Shared Task itself and terminology translation in MT.
Functional Nanomaterials Design in the Workflow of Building Machine-Learning Models
Aug 16, 2021Machine-learning (ML) techniques have revolutionized a host of research fields of chemical and materials science with accelerated, high-efficiency discoveries in design, synthesis, manufacturing, characterization and application of novel functional materials, especially at the nanometre scale. The reason is the time efficiency, prediction accuracy and good generalization abilities, which gradually replaces the traditional experimental or computational work. With enormous potentiality to tackle more real-world problems, ML provides a more comprehensive insight into combinations with molecules/materials under the fundamental procedures for constructing ML models, like predicting properties or functionalities from given parameters, nanoarchitecture design and generating specific models for other purposes. The key to the advances in nanomaterials discovery is how input fingerprints and output values can be linked quantitatively. Finally, some great opportunities and technical challenges are concluded in this fantastic field.
Real-time texturing for 6D object instance detection from RGB Images
Dec 13, 2019
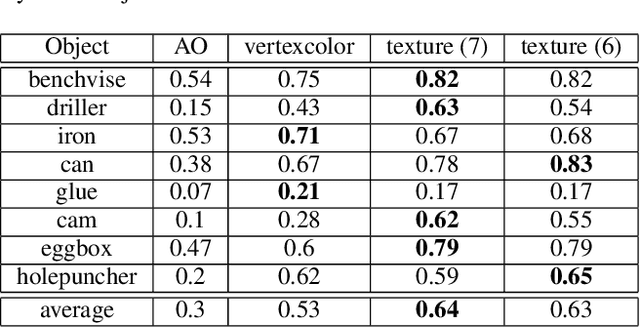

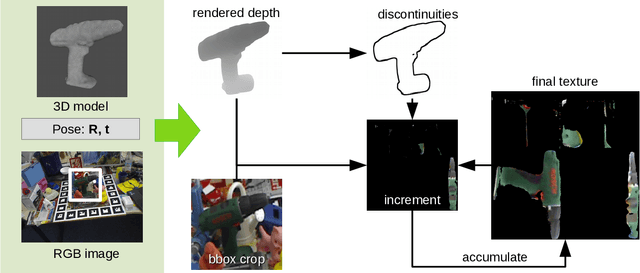
For objected detection, the availability of color cues strongly influences detection rates and is even a prerequisite for many methods. However, when training on synthetic CAD data, this information is not available. We therefore present a method for generating a texture-map from image sequences in real-time. The method relies on 6 degree-of-freedom poses and a 3D-model being available. In contrast to previous works this allows interleaving detection and texturing for upgrading the detector on-the-fly. Our evaluation shows that the acquired texture-map significantly improves detection rates using the LINEMOD detector on RGB images only. Additionally, we use the texture-map to differentiate instances of the same object by surface color.