 Add to Chrome
Add to Chrome Add to Firefox
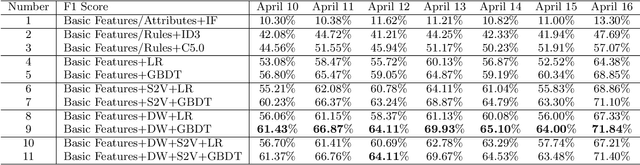
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Guiding Global Placement With Reinforcement Learning
Sep 06, 2021
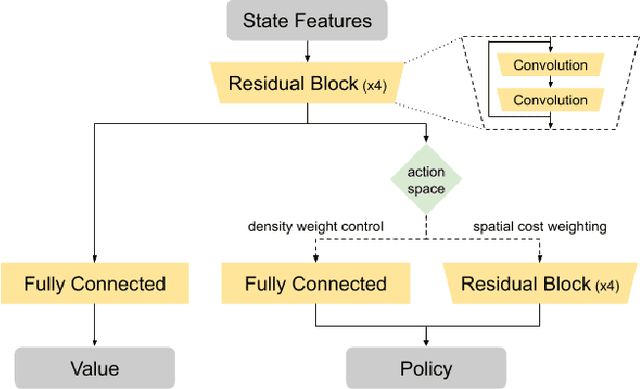
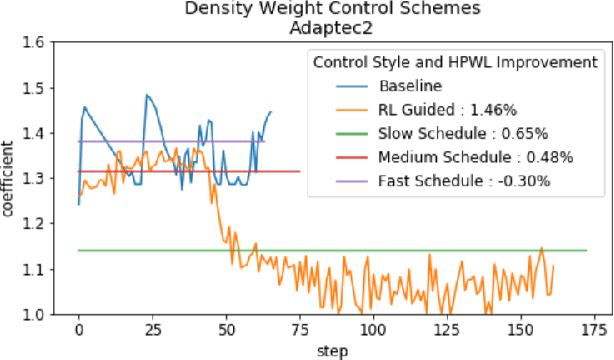
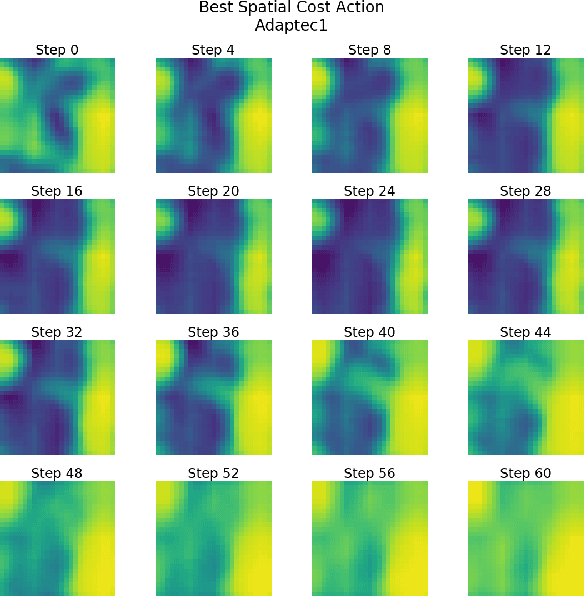
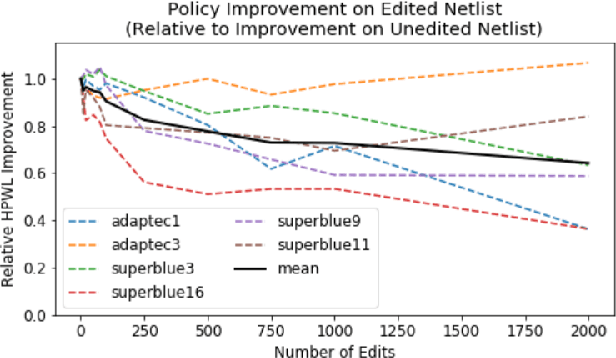
Recent advances in GPU accelerated global and detail placement have reduced the time to solution by an order of magnitude. This advancement allows us to leverage data driven optimization (such as Reinforcement Learning) in an effort to improve the final quality of placement results. In this work we augment state-of-the-art, force-based global placement solvers with a reinforcement learning agent trained to improve the final detail placed Half Perimeter Wire Length (HPWL). We propose novel control schemes with either global or localized control of the placement process. We then train reinforcement learning agents to use these controls to guide placement to improved solutions. In both cases, the augmented optimizer finds improved placement solutions. Our trained agents achieve an average 1% improvement in final detail place HPWL across a range of academic benchmarks and more than 1% in global place HPWL on real industry designs.
Real-Time EEG Classification via Coresets for BCI Applications
Jan 02, 2019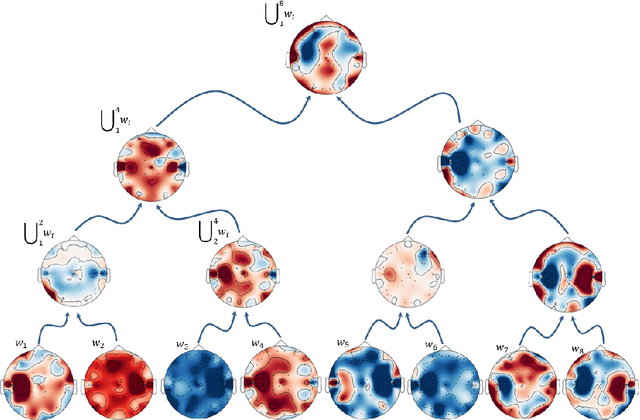

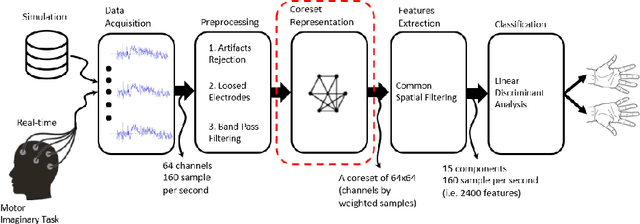
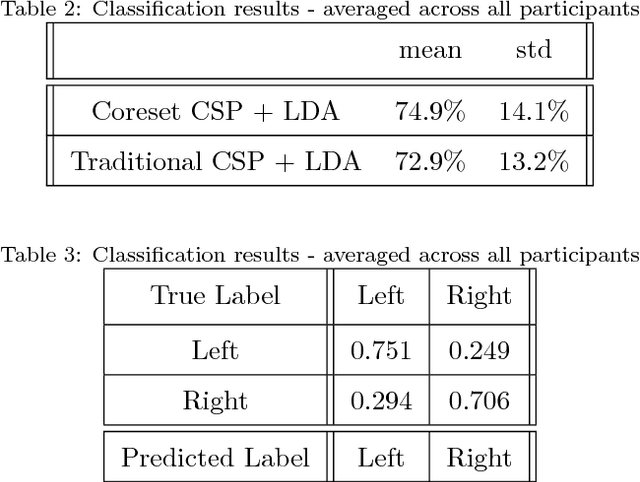
A brain-computer interface (BCI) based on the motor imagery (MI) paradigm translates one's motor intention into a control signal by classifying the Electroencephalogram (EEG) signal of different tasks. However, most existing systems either (i) use a high-quality algorithm to train the data off-line and run only classification in real-time, since the off-line algorithm is too slow, or (ii) use low-quality heuristics that are sufficiently fast for real-time training but introduces relatively large classification error. In this work, we propose a novel processing pipeline that allows real-time and parallel learning of EEG signals using high-quality but possibly inefficient algorithms. This is done by forging a link between BCI and core-sets, a technique that originated in computational geometry for handling streaming data via data summarization. We suggest an algorithm that maintains the representation such coreset tailored to handle the EEG signal which enables: (i) real time and continuous computation of the Common Spatial Pattern (CSP) feature extraction method on a coreset representation of the signal (instead on the signal itself) , (ii) improvement of the CSP algorithm efficiency with provable guarantees by applying CSP algorithm on the coreset, and (iii) real time addition of the data trials (EEG data windows) to the coreset. For simplicity, we focus on the CSP algorithm, which is a classic algorithm. Nevertheless, we expect that our coreset will be extended to other algorithms in future papers. In the experimental results we show that our system can indeed learn EEG signals in real-time for example a 64 channels setup with hundreds of time samples per second. Full open source is provided to reproduce the experiment and in the hope that it will be used and extended to more coresets and BCI applications in the future.
A Contrastive Learning Approach to Auroral Identification and Classification
Sep 29, 2021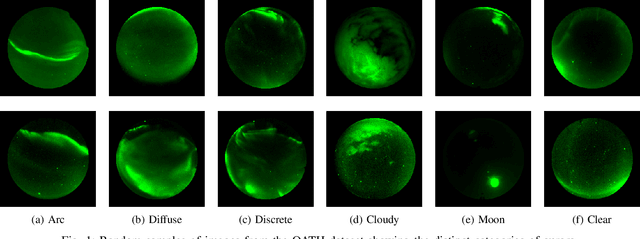
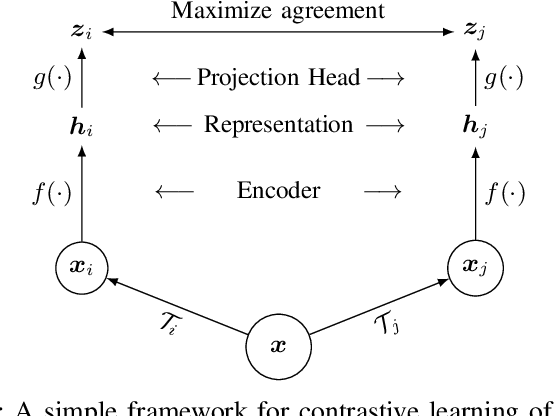
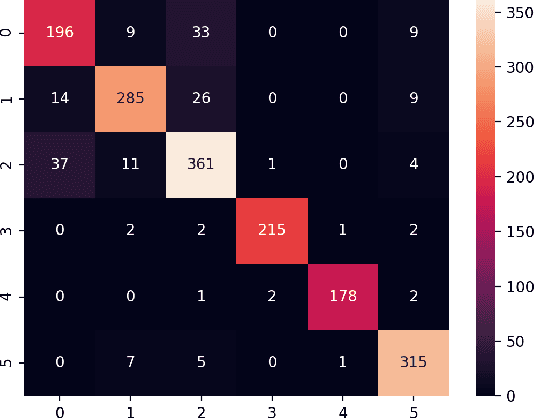
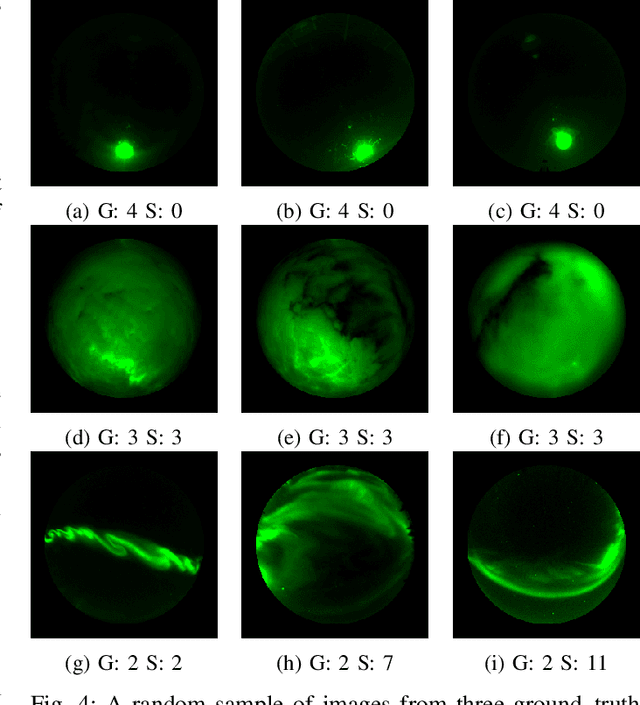
Unsupervised learning algorithms are beginning to achieve accuracies comparable to their supervised counterparts on benchmark computer vision tasks, but their utility for practical applications has not yet been demonstrated. In this work, we present a novel application of unsupervised learning to the task of auroral image classification. Specifically, we modify and adapt the Simple framework for Contrastive Learning of Representations (SimCLR) algorithm to learn representations of auroral images in a recently released auroral image dataset constructed using image data from Time History of Events and Macroscale Interactions during Substorms (THEMIS) all-sky imagers. We demonstrate that (a) simple linear classifiers fit to the learned representations of the images achieve state-of-the-art classification performance, improving the classification accuracy by almost 10 percentage points over the current benchmark; and (b) the learned representations naturally cluster into more clusters than exist manually assigned categories, suggesting that existing categorizations are overly coarse and may obscure important connections between auroral types, near-earth solar wind conditions, and geomagnetic disturbances at the earth's surface. Moreover, our model is much lighter than the previous benchmark on this dataset, requiring in the area of fewer than 25\% of the number of parameters. Our approach exceeds an established threshold for operational purposes, demonstrating readiness for deployment and utilization.
TitAnt: Online Real-time Transaction Fraud Detection in Ant Financial
Jun 18, 2019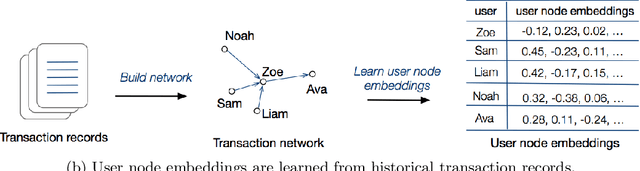
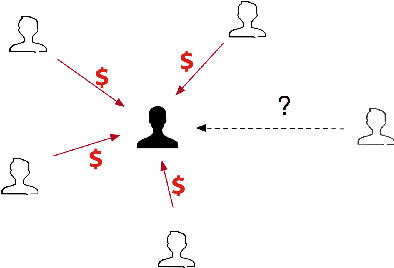

With the explosive growth of e-commerce and the booming of e-payment, detecting online transaction fraud in real time has become increasingly important to Fintech business. To tackle this problem, we introduce the TitAnt, a transaction fraud detection system deployed in Ant Financial, one of the largest Fintech companies in the world. The system is able to predict online real-time transaction fraud in mere milliseconds. We present the problem definition, feature extraction, detection methods, implementation and deployment of the system, as well as empirical effectiveness. Extensive experiments have been conducted on large real-world transaction data to show the effectiveness and the efficiency of the proposed system.
Fine-Grained Zero-Shot Learning with DNA as Side Information
Sep 29, 2021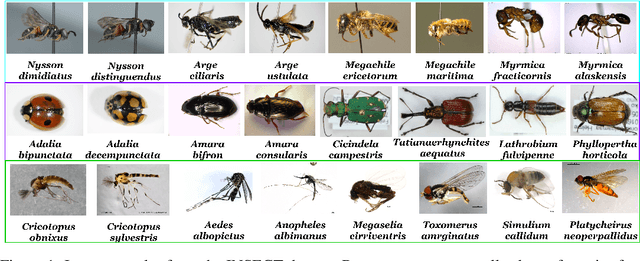
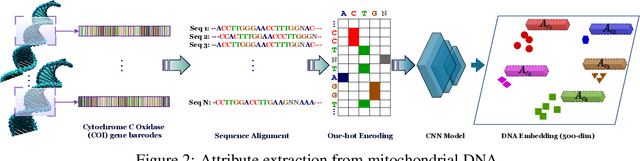
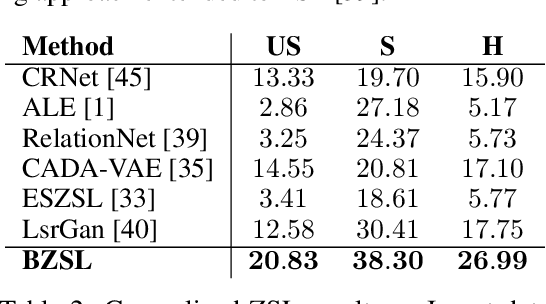
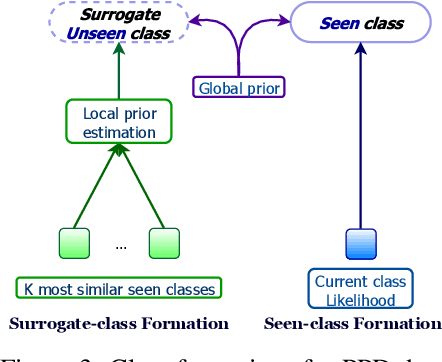
Fine-grained zero-shot learning task requires some form of side-information to transfer discriminative information from seen to unseen classes. As manually annotated visual attributes are extremely costly and often impractical to obtain for a large number of classes, in this study we use DNA as side information for the first time for fine-grained zero-shot classification of species. Mitochondrial DNA plays an important role as a genetic marker in evolutionary biology and has been used to achieve near-perfect accuracy in the species classification of living organisms. We implement a simple hierarchical Bayesian model that uses DNA information to establish the hierarchy in the image space and employs local priors to define surrogate classes for unseen ones. On the benchmark CUB dataset, we show that DNA can be equally promising yet in general a more accessible alternative than word vectors as a side information. This is especially important as obtaining robust word representations for fine-grained species names is not a practicable goal when information about these species in free-form text is limited. On a newly compiled fine-grained insect dataset that uses DNA information from over a thousand species, we show that the Bayesian approach outperforms state-of-the-art by a wide margin.
Asking Questions Like Educational Experts: Automatically Generating Question-Answer Pairs on Real-World Examination Data
Sep 17, 2021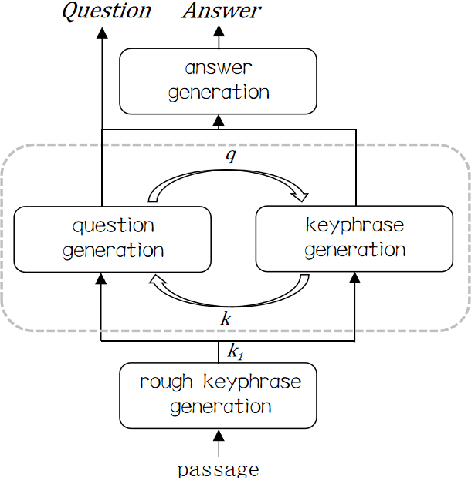

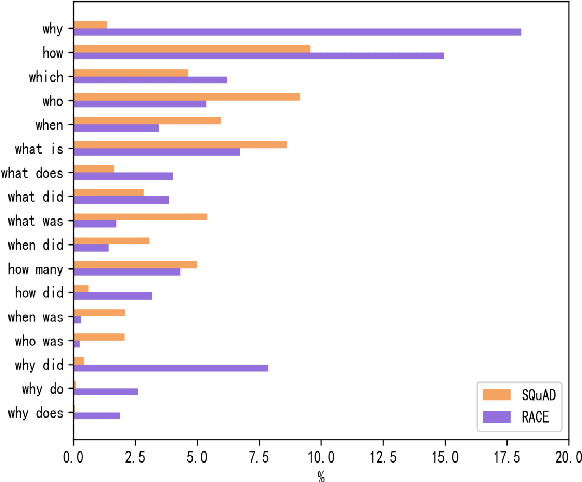
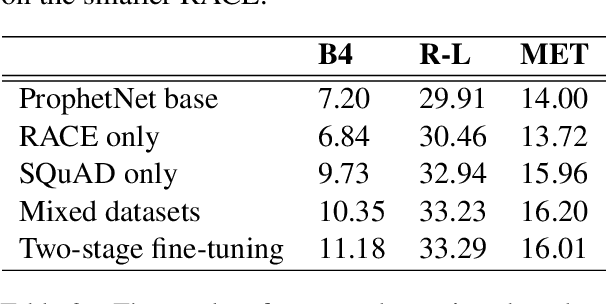
Generating high quality question-answer pairs is a hard but meaningful task. Although previous works have achieved great results on answer-aware question generation, it is difficult to apply them into practical application in the education field. This paper for the first time addresses the question-answer pair generation task on the real-world examination data, and proposes a new unified framework on RACE. To capture the important information of the input passage we first automatically generate(rather than extracting) keyphrases, thus this task is reduced to keyphrase-question-answer triplet joint generation. Accordingly, we propose a multi-agent communication model to generate and optimize the question and keyphrases iteratively, and then apply the generated question and keyphrases to guide the generation of answers. To establish a solid benchmark, we build our model on the strong generative pre-training model. Experimental results show that our model makes great breakthroughs in the question-answer pair generation task. Moreover, we make a comprehensive analysis on our model, suggesting new directions for this challenging task.
Gradient Forward-Propagation for Large-Scale Temporal Video Modelling
Jul 12, 2021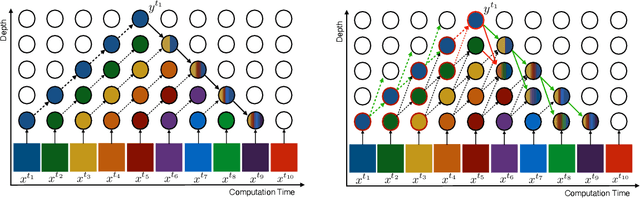
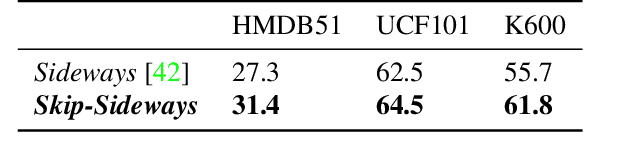
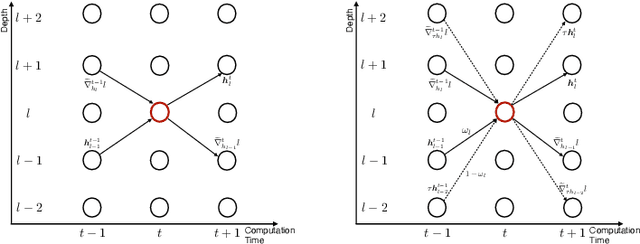

How can neural networks be trained on large-volume temporal data efficiently? To compute the gradients required to update parameters, backpropagation blocks computations until the forward and backward passes are completed. For temporal signals, this introduces high latency and hinders real-time learning. It also creates a coupling between consecutive layers, which limits model parallelism and increases memory consumption. In this paper, we build upon Sideways, which avoids blocking by propagating approximate gradients forward in time, and we propose mechanisms for temporal integration of information based on different variants of skip connections. We also show how to decouple computation and delegate individual neural modules to different devices, allowing distributed and parallel training. The proposed Skip-Sideways achieves low latency training, model parallelism, and, importantly, is capable of extracting temporal features, leading to more stable training and improved performance on real-world action recognition video datasets such as HMDB51, UCF101, and the large-scale Kinetics-600. Finally, we also show that models trained with Skip-Sideways generate better future frames than Sideways models, and hence they can better utilize motion cues.
Robust Control Under Uncertainty via Bounded Rationality and Differential Privacy
Sep 17, 2021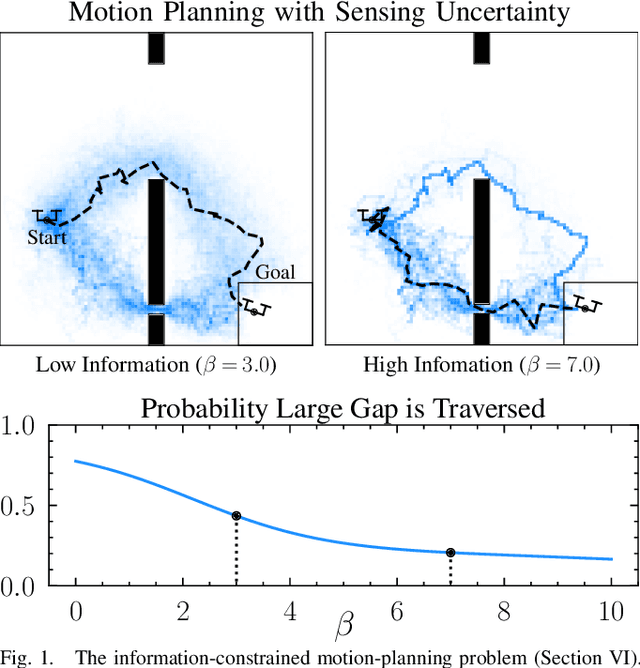
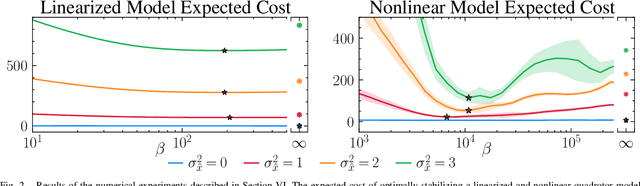
The rapid development of affordable and compact high-fidelity sensors (e.g., cameras and LIDAR) allows robots to construct detailed estimates of their states and environments. However, the availability of such rich sensor information introduces two technical challenges: (i) the lack of analytic sensing models, which makes it difficult to design controllers that are robust to sensor failures, and (ii) the computational expense of processing the high-dimensional sensor information in real time. This paper addresses these challenges using the theory of differential privacy, which allows us to (i) design controllers with bounded sensitivity to errors in state estimates, and (ii) bound the amount of state information used for control (i.e., to impose bounded rationality). The resulting framework approximates the separation principle and allows us to derive an upper-bound on the cost incurred with a faulty state estimator in terms of three quantities: the cost incurred using a perfect state estimator, the magnitude of state estimation errors, and the level of differential privacy. We demonstrate the efficacy of our framework numerically on different robotics problems, including nonlinear system stabilization and motion planning.
An Explainable-AI approach for Diagnosis of COVID-19 using MALDI-ToF Mass Spectrometry
Sep 28, 2021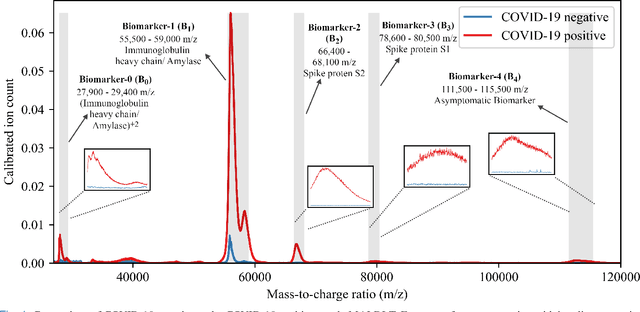
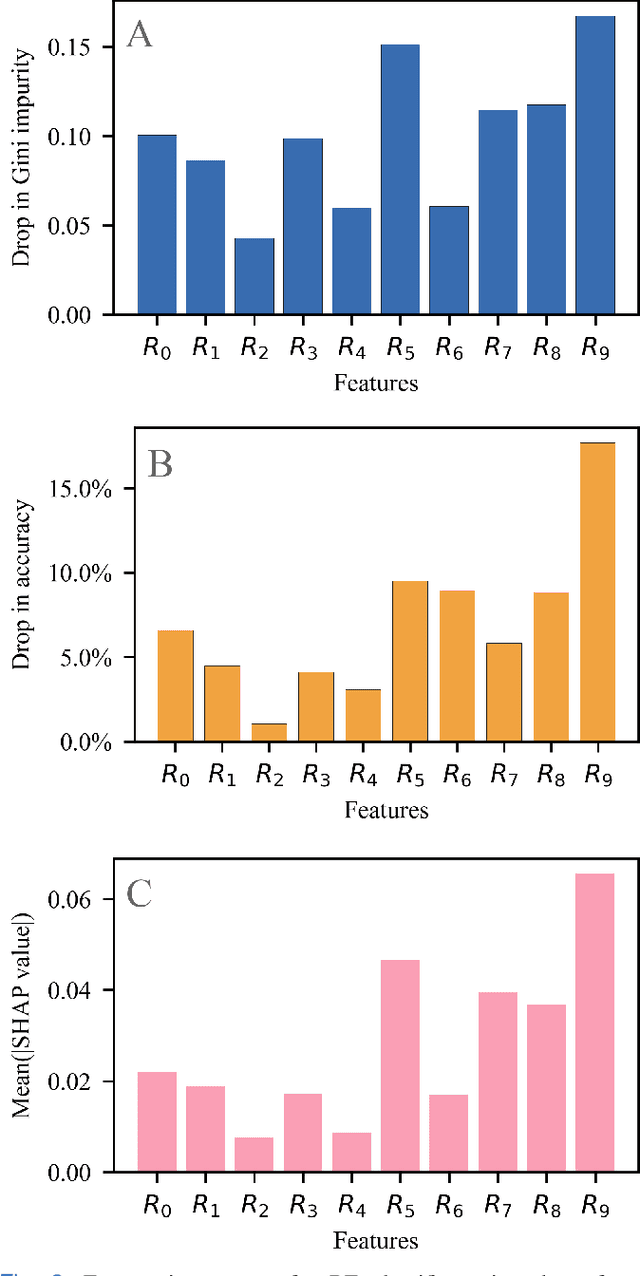
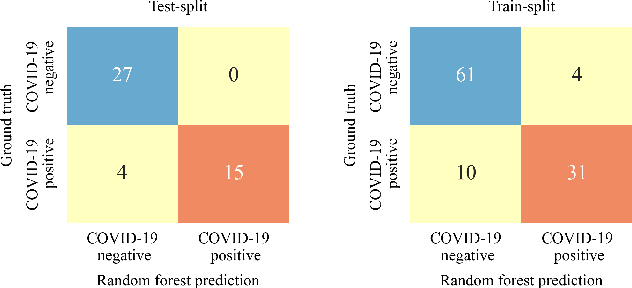
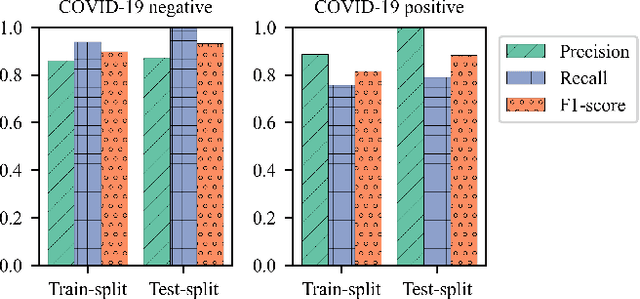
The novel severe acute respiratory syndrome coronavirus type-2 (SARS-CoV-2) caused a global pandemic that has taken more than 4.5 million lives and severely affected the global economy. To curb the spread of the virus, an accurate, cost-effective, and quick testing for large populations is exceedingly important in order to identify, isolate, and treat infected people. Current testing methods commonly use PCR (Polymerase Chain Reaction) based equipment that have limitations on throughput, cost-effectiveness, and simplicity of procedure which creates a compelling need for developing additional coronavirus disease-2019 (COVID-19) testing mechanisms, that are highly sensitive, rapid, trustworthy, and convenient to use by the public. We propose a COVID-19 testing method using artificial intelligence (AI) techniques on MALDI-ToF (matrix-assisted laser desorption/ionization time-of-flight) data extracted from 152 human gargle samples (60 COVID-19 positive tests and 92 COVID-19 negative tests). Our AI-based approach leverages explainable-AI (X-AI) methods to explain the decision rules behind the predictive algorithm both on a local (per-sample) and global (all-samples) basis to make the AI model more trustworthy. Finally, we evaluated our proposed method using a 70%-30% train-test-split strategy and achieved a training accuracy of 86.79% and a testing accuracy of 91.30%.
The AI Economist: Optimal Economic Policy Design via Two-level Deep Reinforcement Learning
Aug 05, 2021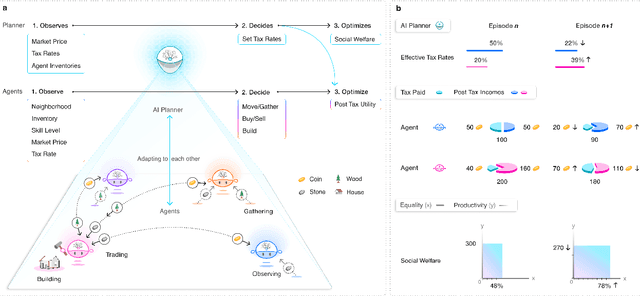
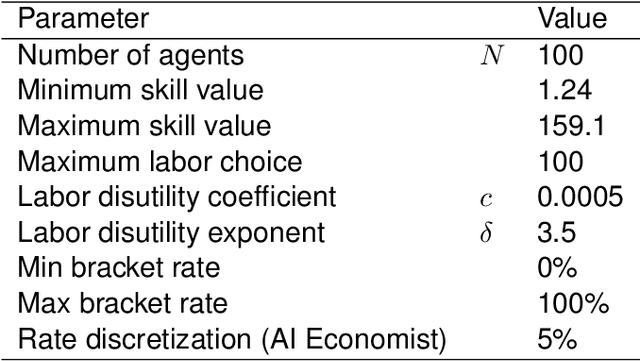
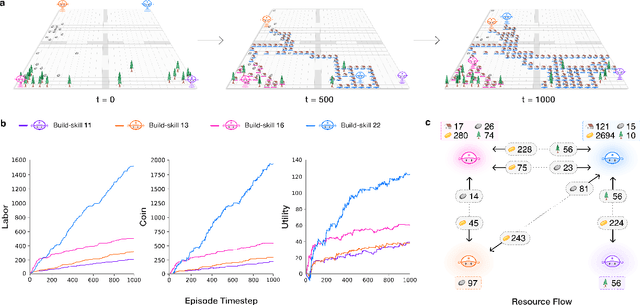
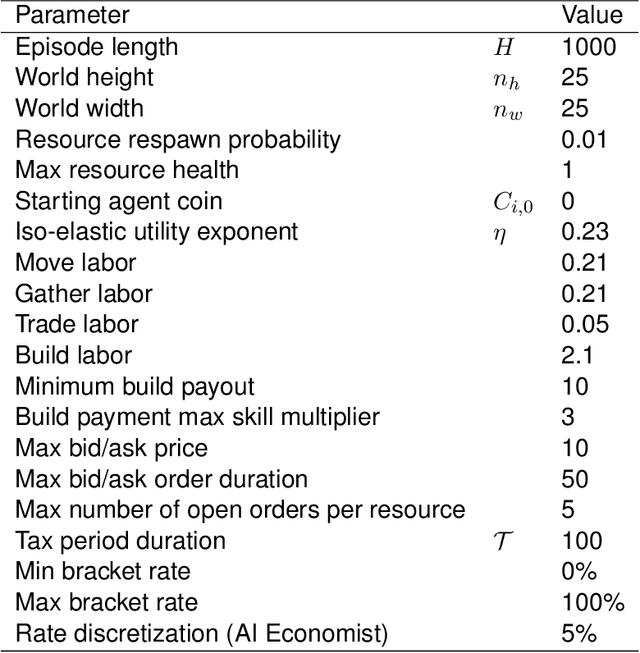
AI and reinforcement learning (RL) have improved many areas, but are not yet widely adopted in economic policy design, mechanism design, or economics at large. At the same time, current economic methodology is limited by a lack of counterfactual data, simplistic behavioral models, and limited opportunities to experiment with policies and evaluate behavioral responses. Here we show that machine-learning-based economic simulation is a powerful policy and mechanism design framework to overcome these limitations. The AI Economist is a two-level, deep RL framework that trains both agents and a social planner who co-adapt, providing a tractable solution to the highly unstable and novel two-level RL challenge. From a simple specification of an economy, we learn rational agent behaviors that adapt to learned planner policies and vice versa. We demonstrate the efficacy of the AI Economist on the problem of optimal taxation. In simple one-step economies, the AI Economist recovers the optimal tax policy of economic theory. In complex, dynamic economies, the AI Economist substantially improves both utilitarian social welfare and the trade-off between equality and productivity over baselines. It does so despite emergent tax-gaming strategies, while accounting for agent interactions and behavioral change more accurately than economic theory. These results demonstrate for the first time that two-level, deep RL can be used for understanding and as a complement to theory for economic design, unlocking a new computational learning-based approach to understanding economic policy.