 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOAST: Fast and scalable auto-partitioning based on principled static analysis
Aug 20, 2025



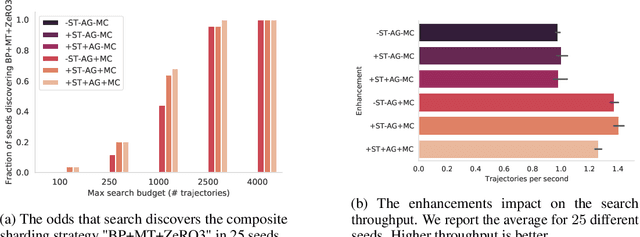
Partitioning large machine learning models across distributed accelerator systems is a complex process, requiring a series of interdependent decisions that are further complicated by internal sharding ambiguities. Consequently, existing auto-partitioners often suffer from out-of-memory errors or are prohibitively slow when exploring the exponentially large space of possible partitionings. To mitigate this, they artificially restrict the search space, but this approach frequently yields infeasible solutions that violate device memory constraints or lead to sub-optimal performance. We propose a system that combines a novel static compiler analysis with a Monte Carlo Tree Search. Our analysis constructs an efficient decision space by identifying (i) tensor dimensions requiring identical sharding, and (ii) partitioning "conflicts" that require resolution. Our system significantly outperforms state-of-the-art industrial methods across diverse hardware platforms and model architectures, discovering previously unknown, superior solutions, and the process is fully automated even for complex and large models.
PartIR: Composing SPMD Partitioning Strategies for Machine Learning
Jan 23, 2024



Training of modern large neural networks (NN) requires a combination of parallelization strategies encompassing data, model, or optimizer sharding. When strategies increase in complexity, it becomes necessary for partitioning tools to be 1) expressive, allowing the composition of simpler strategies, and 2) predictable to estimate performance analytically. We present PartIR, our design for a NN partitioning system. PartIR is focused on an incremental approach to rewriting and is hardware-and-runtime agnostic. We present a simple but powerful API for composing sharding strategies and a simulator to validate them. The process is driven by high-level programmer-issued partitioning tactics, which can be both manual and automatic. Importantly, the tactics are specified separately from the model code, making them easy to change. We evaluate PartIR on several different models to demonstrate its predictability, expressibility, and ability to reach peak performance..
Efficient and Sound Differentiable Programming in a Functional Array-Processing Language
Dec 20, 2022Automatic differentiation (AD) is a technique for computing the derivative of a function represented by a program. This technique is considered as the de-facto standard for computing the differentiation in many machine learning and optimisation software tools. Despite the practicality of this technique, the performance of the differentiated programs, especially for functional languages and in the presence of vectors, is suboptimal. We present an AD system for a higher-order functional array-processing language. The core functional language underlying this system simultaneously supports both source-to-source forward-mode AD and global optimisations such as loop transformations. In combination, gradient computation with forward-mode AD can be as efficient as reverse mode, and the Jacobian matrices required for numerical algorithms such as Gauss-Newton and Levenberg-Marquardt can be efficiently computed.
Automatic Discovery of Composite SPMD Partitioning Strategies in PartIR
Oct 07, 2022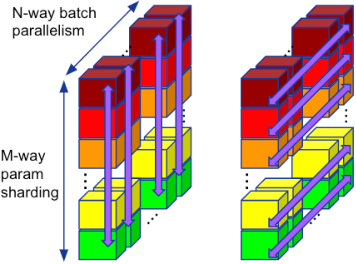


Large neural network models are commonly trained through a combination of advanced parallelism strategies in a single program, multiple data (SPMD) paradigm. For example, training large transformer models requires combining data, model, and pipeline partitioning; and optimizer sharding techniques. However, identifying efficient combinations for many model architectures and accelerator systems requires significant manual analysis. In this work, we present an automatic partitioner that identifies these combinations through a goal-oriented search. Our key findings are that a Monte Carlo Tree Search-based partitioner leveraging partition-specific compiler analysis directly into the search and guided goals matches expert-level strategies for various models.
Automap: Towards Ergonomic Automated Parallelism for ML Models
Dec 06, 2021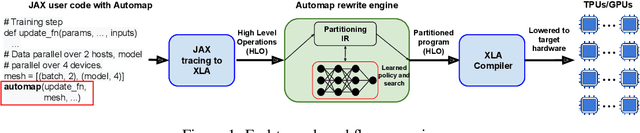
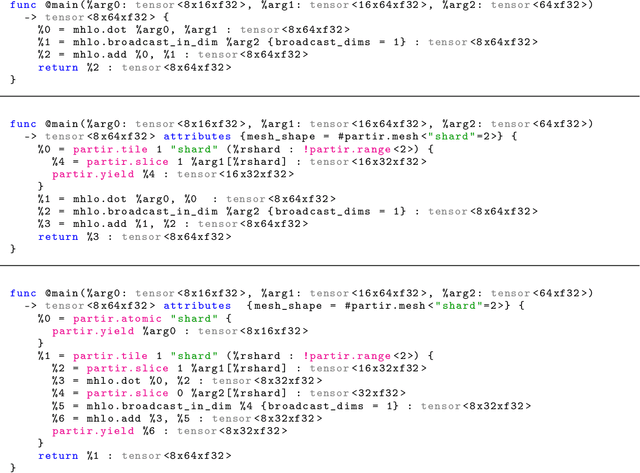


The rapid rise in demand for training large neural network architectures has brought into focus the need for partitioning strategies, for example by using data, model, or pipeline parallelism. Implementing these methods is increasingly supported through program primitives, but identifying efficient partitioning strategies requires expensive experimentation and expertise. We present the prototype of an automated partitioner that seamlessly integrates into existing compilers and existing user workflows. Our partitioner enables SPMD-style parallelism that encompasses data parallelism and parameter/activation sharding. Through a combination of inductive tactics and search in a platform-independent partitioning IR, automap can recover expert partitioning strategies such as Megatron sharding for transformer layers.
Memory-efficient array redistribution through portable collective communication
Dec 02, 2021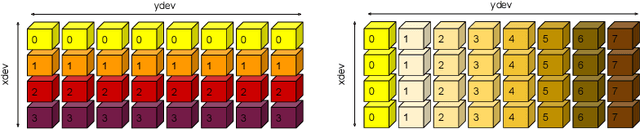
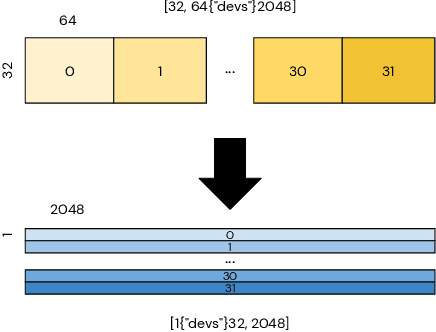
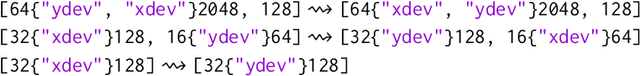

Modern large-scale deep learning workloads highlight the need for parallel execution across many devices in order to fit model data into hardware accelerator memories. In these settings, array redistribution may be required during a computation, but can also become a bottleneck if not done efficiently. In this paper we address the problem of redistributing multi-dimensional array data in SPMD computations, the most prevalent form of parallelism in deep learning. We present a type-directed approach to synthesizing array redistributions as sequences of MPI-style collective operations. We prove formally that our synthesized redistributions are memory-efficient and perform no excessive data transfers. Array redistribution for SPMD computations using collective operations has also been implemented in the context of the XLA SPMD partitioner, a production-grade tool for partitioning programs across accelerator systems. We evaluate our approach against the XLA implementation and find that our approach delivers a geometric mean speedup of $1.22\times$, with maximum speedups as a high as $5.7\times$, while offering provable memory guarantees, making our system particularly appealing for large-scale models.
Synthesizing Optimal Parallelism Placement and Reduction Strategies on Hierarchical Systems for Deep Learning
Oct 20, 2021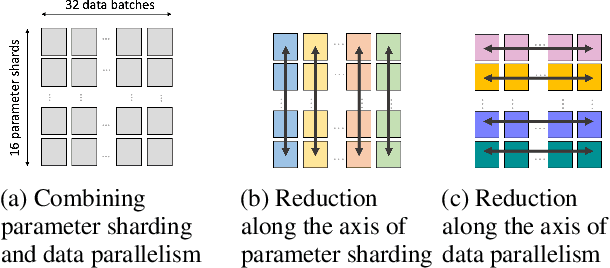
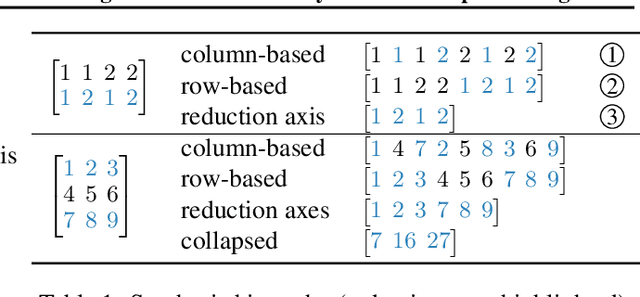
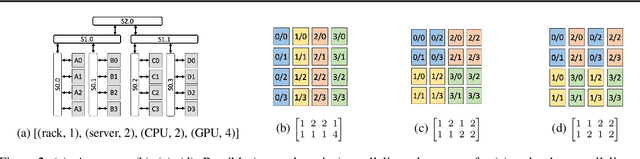
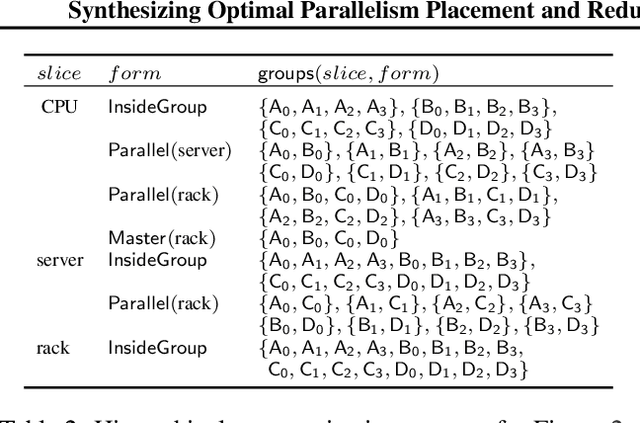
We present a novel characterization of the mapping of multiple parallelism forms (e.g. data and model parallelism) onto hierarchical accelerator systems that is hierarchy-aware and greatly reduces the space of software-to-hardware mapping. We experimentally verify the substantial effect of these mappings on all-reduce performance (up to 448x). We offer a novel syntax-guided program synthesis framework that is able to decompose reductions over one or more parallelism axes to sequences of collectives in a hierarchy- and mapping-aware way. For 69% of parallelism placements and user requested reductions, our framework synthesizes programs that outperform the default all-reduce implementation when evaluated on different GPU hierarchies (max 2.04x, average 1.27x). We complement our synthesis tool with a simulator exceeding 90% top-10 accuracy, which therefore reduces the need for massive evaluations of synthesis results to determine a small set of optimal programs and mappings.
Gradient Forward-Propagation for Large-Scale Temporal Video Modelling
Jul 12, 2021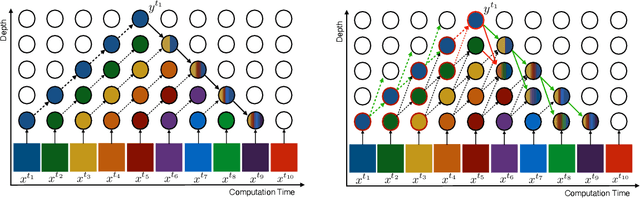
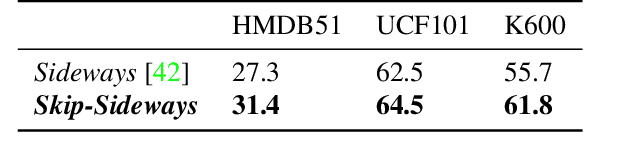
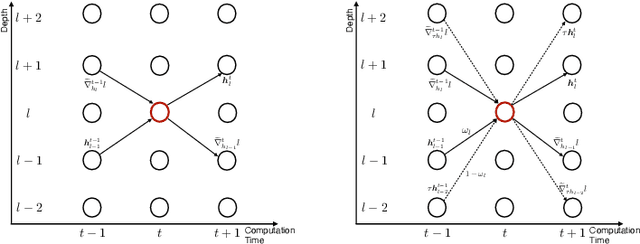

How can neural networks be trained on large-volume temporal data efficiently? To compute the gradients required to update parameters, backpropagation blocks computations until the forward and backward passes are completed. For temporal signals, this introduces high latency and hinders real-time learning. It also creates a coupling between consecutive layers, which limits model parallelism and increases memory consumption. In this paper, we build upon Sideways, which avoids blocking by propagating approximate gradients forward in time, and we propose mechanisms for temporal integration of information based on different variants of skip connections. We also show how to decouple computation and delegate individual neural modules to different devices, allowing distributed and parallel training. The proposed Skip-Sideways achieves low latency training, model parallelism, and, importantly, is capable of extracting temporal features, leading to more stable training and improved performance on real-world action recognition video datasets such as HMDB51, UCF101, and the large-scale Kinetics-600. Finally, we also show that models trained with Skip-Sideways generate better future frames than Sideways models, and hence they can better utilize motion cues.
Efficient Differentiable Programming in a Functional Array-Processing Language
Jun 06, 2018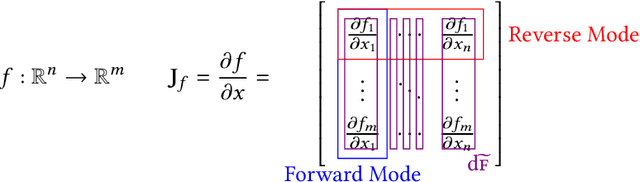

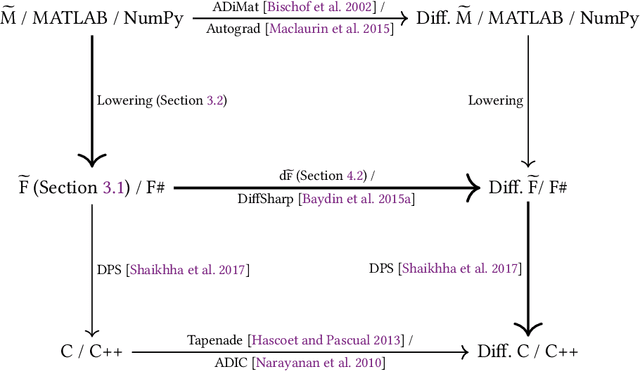

We present a system for the automatic differentiation of a higher-order functional array-processing language. The core functional language underlying this system simultaneously supports both source-to-source automatic differentiation and global optimizations such as loop transformations. Thanks to this feature, we demonstrate how for some real-world machine learning and computer vision benchmarks, the system outperforms the state-of-the-art automatic differentiation tools.
AMPNet: Asynchronous Model-Parallel Training for Dynamic Neural Networks
Jun 22, 2017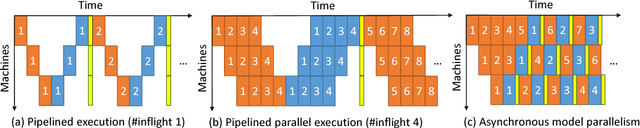
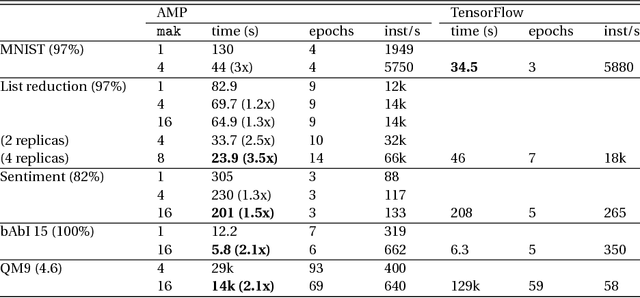
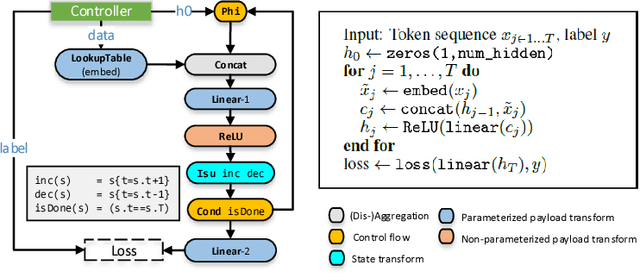
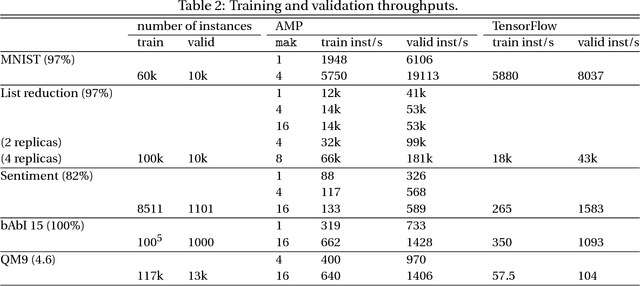
New types of machine learning hardware in development and entering the market hold the promise of revolutionizing deep learning in a manner as profound as GPUs. However, existing software frameworks and training algorithms for deep learning have yet to evolve to fully leverage the capability of the new wave of silicon. We already see the limitations of existing algorithms for models that exploit structured input via complex and instance-dependent control flow, which prohibits minibatching. We present an asynchronous model-parallel (AMP) training algorithm that is specifically motivated by training on networks of interconnected devices. Through an implementation on multi-core CPUs, we show that AMP training converges to the same accuracy as conventional synchronous training algorithms in a similar number of epochs, but utilizes the available hardware more efficiently even for small minibatch sizes, resulting in significantly shorter overall training times. Our framework opens the door for scaling up a new class of deep learning models that cannot be efficiently trained today.