 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DPCRN: Dual-Path Convolution Recurrent Network for Single Channel Speech Enhancement
Jul 12, 2021
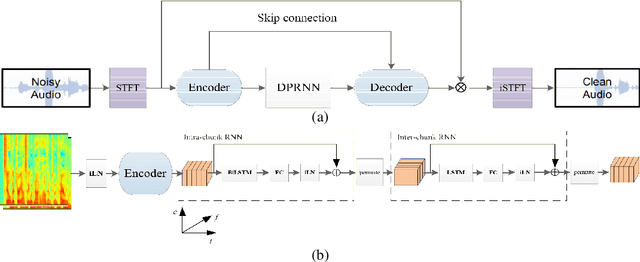
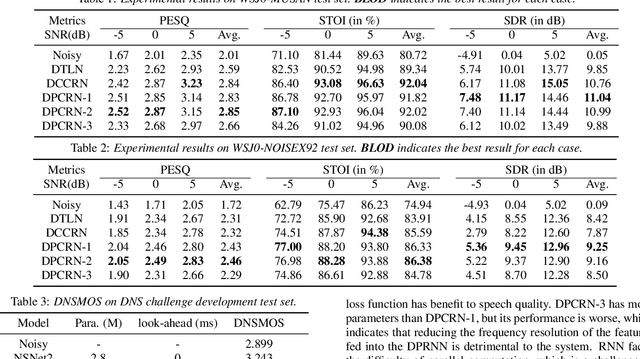
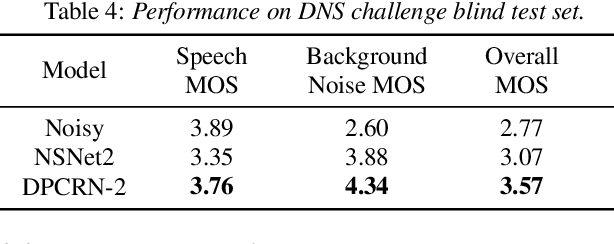
The dual-path RNN (DPRNN) was proposed to more effectively model extremely long sequences for speech separation in the time domain. By splitting long sequences to smaller chunks and applying intra-chunk and inter-chunk RNNs, the DPRNN reached promising performance in speech separation with a limited model size. In this paper, we combine the DPRNN module with Convolution Recurrent Network (CRN) and design a model called Dual-Path Convolution Recurrent Network (DPCRN) for speech enhancement in the time-frequency domain. We replace the RNNs in the CRN with DPRNN modules, where the intra-chunk RNNs are used to model the spectrum pattern in a single frame and the inter-chunk RNNs are used to model the dependence between consecutive frames. With only 0.8M parameters, the submitted DPCRN model achieves an overall mean opinion score (MOS) of 3.57 in the wide band scenario track of the Interspeech 2021 Deep Noise Suppression (DNS) challenge. Evaluations on some other test sets also show the efficacy of our model.
Small-Bench NLP: Benchmark for small single GPU trained models in Natural Language Processing
Sep 23, 2021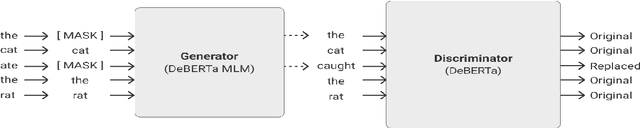
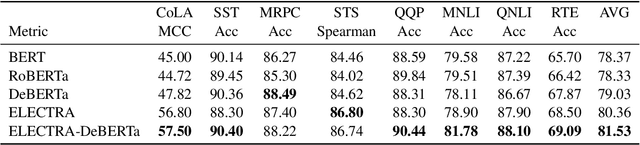
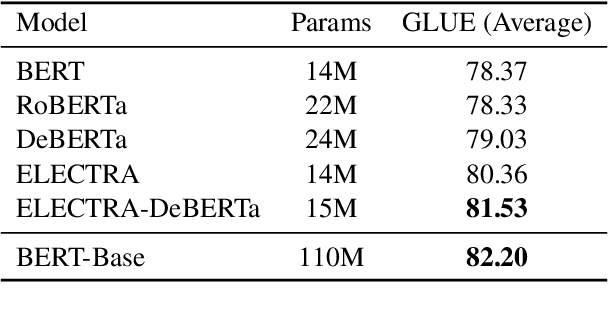
Recent progress in the Natural Language Processing domain has given us several State-of-the-Art (SOTA) pretrained models which can be finetuned for specific tasks. These large models with billions of parameters trained on numerous GPUs/TPUs over weeks are leading in the benchmark leaderboards. In this paper, we discuss the need for a benchmark for cost and time effective smaller models trained on a single GPU. This will enable researchers with resource constraints experiment with novel and innovative ideas on tokenization, pretraining tasks, architecture, fine tuning methods etc. We set up Small-Bench NLP, a benchmark for small efficient neural language models trained on a single GPU. Small-Bench NLP benchmark comprises of eight NLP tasks on the publicly available GLUE datasets and a leaderboard to track the progress of the community. Our ELECTRA-DeBERTa (15M parameters) small model architecture achieves an average score of 81.53 which is comparable to that of BERT-Base's 82.20 (110M parameters). Our models, code and leaderboard are available at https://github.com/smallbenchnlp
Designing Counterfactual Generators using Deep Model Inversion
Sep 29, 2021
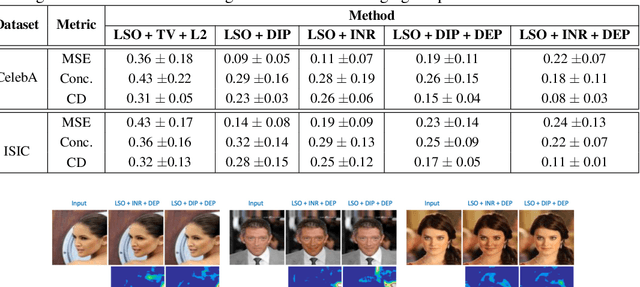
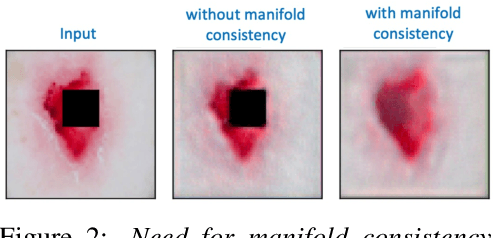

Explanation techniques that synthesize small, interpretable changes to a given image while producing desired changes in the model prediction have become popular for introspecting black-box models. Commonly referred to as counterfactuals, the synthesized explanations are required to contain discernible changes (for easy interpretability) while also being realistic (consistency to the data manifold). In this paper, we focus on the case where we have access only to the trained deep classifier and not the actual training data. While the problem of inverting deep models to synthesize images from the training distribution has been explored, our goal is to develop a deep inversion approach to generate counterfactual explanations for a given query image. Despite their effectiveness in conditional image synthesis, we show that existing deep inversion methods are insufficient for producing meaningful counterfactuals. We propose DISC (Deep Inversion for Synthesizing Counterfactuals) that improves upon deep inversion by utilizing (a) stronger image priors, (b) incorporating a novel manifold consistency objective and (c) adopting a progressive optimization strategy. We find that, in addition to producing visually meaningful explanations, the counterfactuals from DISC are effective at learning classifier decision boundaries and are robust to unknown test-time corruptions.
Formulation and validation of a car-following model based on deep reinforcement learning
Sep 29, 2021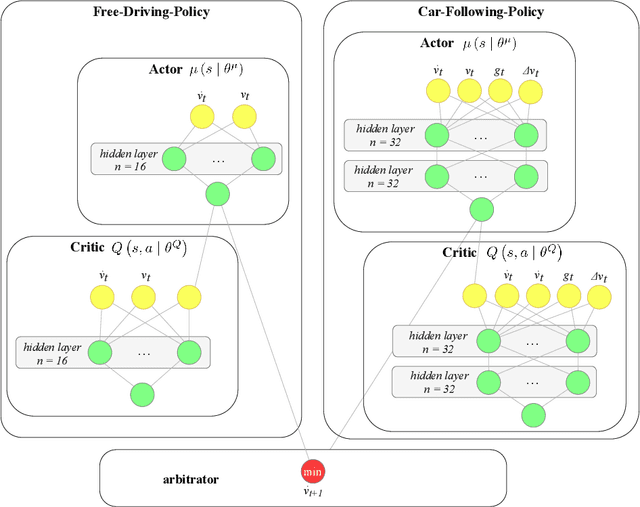
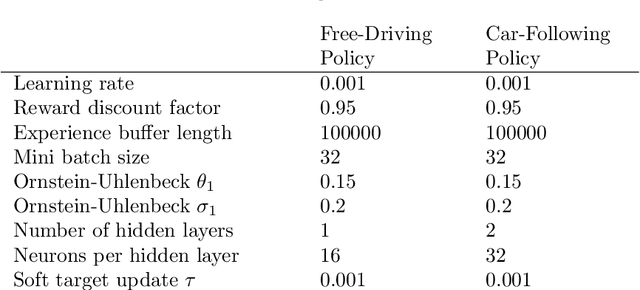
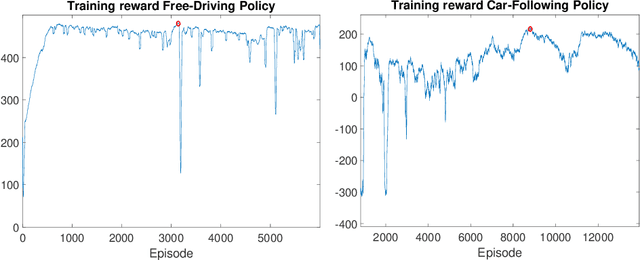

We propose and validate a novel car following model based on deep reinforcement learning. Our model is trained to maximize externally given reward functions for the free and car-following regimes rather than reproducing existing follower trajectories. The parameters of these reward functions such as desired speed, time gap, or accelerations resemble that of traditional models such as the Intelligent Driver Model (IDM) and allow for explicitly implementing different driving styles. Moreover, they partially lift the black-box nature of conventional neural network models. The model is trained on leading speed profiles governed by a truncated Ornstein-Uhlenbeck process reflecting a realistic leader's kinematics. This allows for arbitrary driving situations and an infinite supply of training data. For various parameterizations of the reward functions, and for a wide variety of artificial and real leader data, the model turned out to be unconditionally string stable, comfortable, and crash-free. String stability has been tested with a platoon of five followers following an artificial and a real leading trajectory. A cross-comparison with the IDM calibrated to the goodness-of-fit of the relative gaps showed a higher reward compared to the traditional model and a better goodness-of-fit.
Routine Modeling with Time Series Metric Learning
Jul 08, 2019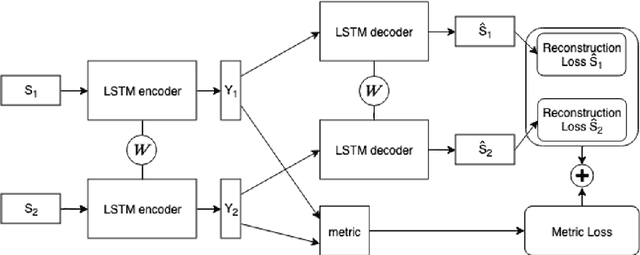
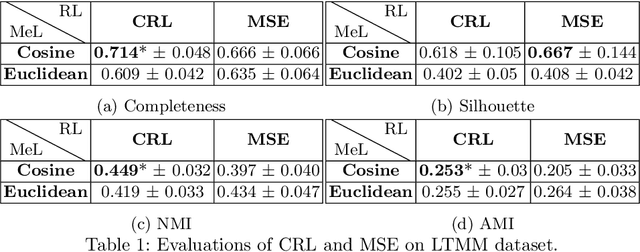
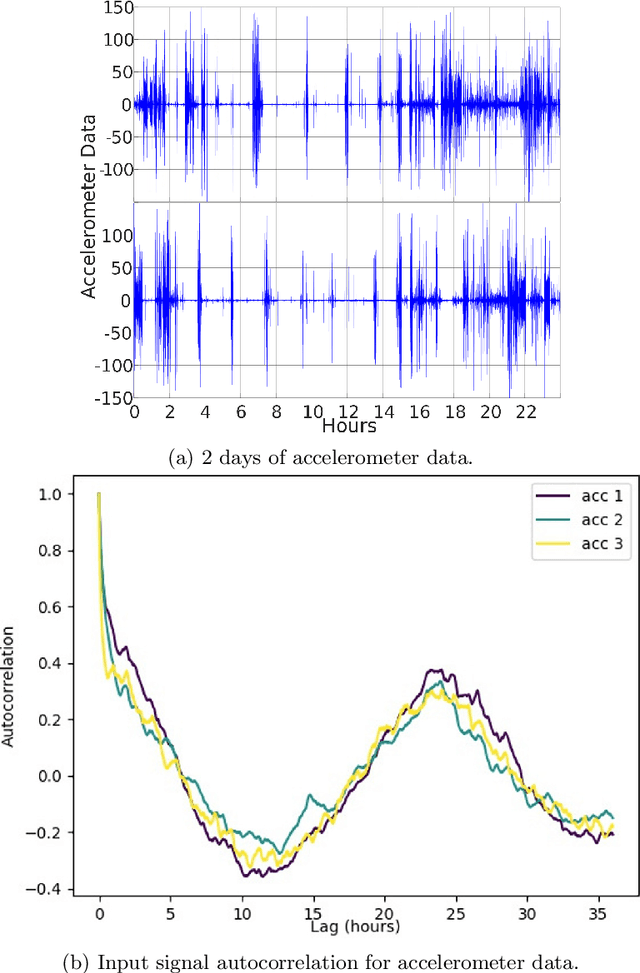
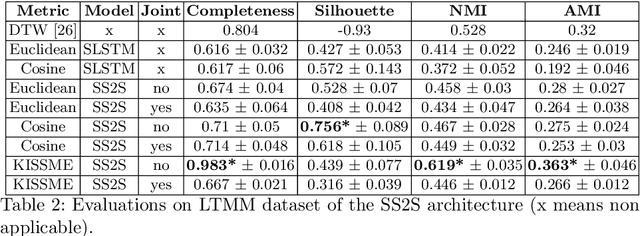
Traditionally, the automatic recognition of human activities is performed with supervised learning algorithms on limited sets of specific activities. This work proposes to recognize recurrent activity patterns, called routines, instead of precisely defined activities. The modeling of routines is defined as a metric learning problem, and an architecture, called SS2S, based on sequence-to-sequence models is proposed to learn a distance between time series. This approach only relies on inertial data and is thus non intrusive and preserves privacy. Experimental results show that a clustering algorithm provided with the learned distance is able to recover daily routines.
Design and Characterization of a 3D-printed Pneumatically-driven Bistable Valve with Tunable Characteristics
Oct 04, 2021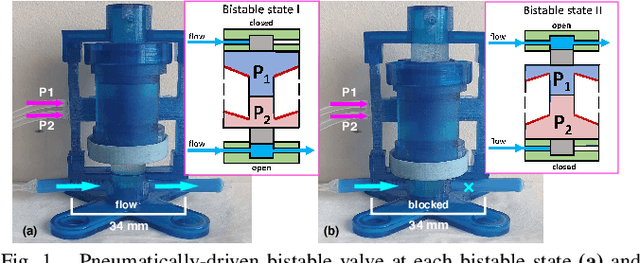
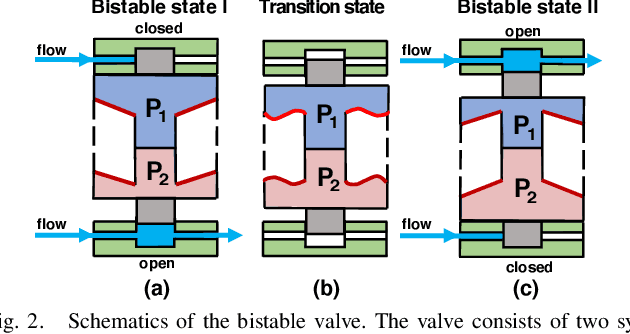
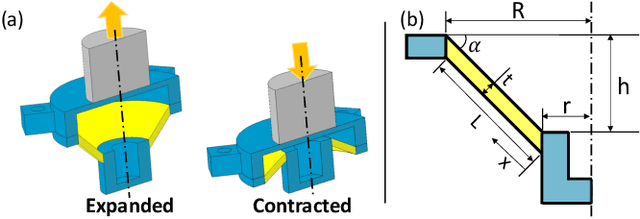
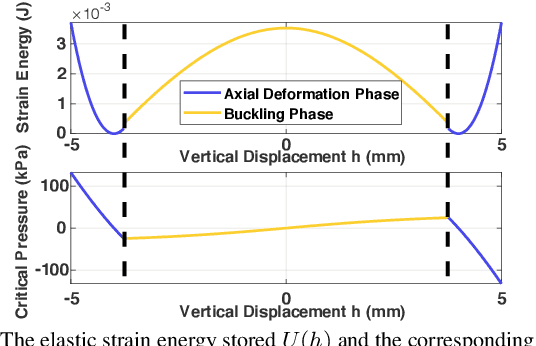
Although research studies in pneumatic soft robots develop rapidly, most pneumatic actuators are still controlled by rigid valves and conventional electronics. The existence of these rigid, electronic components sacrifices the compliance and adaptability of soft robots.} Current electronics-free valve designs based on soft materials are facing challenges in behaviour consistency, design flexibility, and fabrication complexity. Taking advantages of soft material 3D printing, this paper presents a new design of a bi-stable pneumatic valve, which utilises two soft, pneumatically-driven, and symmetrically-oriented conical shells with structural bistability to stabilise and regulate the airflow. The critical pressure required to operate the valve can be adjusted by changing the design features of the soft bi-stable structure. Multi-material printing simplifies the valve fabrication, enhances the flexibility in design feature optimisations, and improves the system repeatability. In this work, both a theoretical model and physical experiments are introduced to examine the relationships between the critical operating pressure and the key design features. Results with valve characteristic tuning via material stiffness changing show better effectiveness compared to the change of geometry design features (demonstrated largest tunable critical pressure range from 15.3 to 65.2 kPa and fastest response time $\leq$ 1.8 s.
Physical System for Non Time Sequence Data
Oct 07, 2020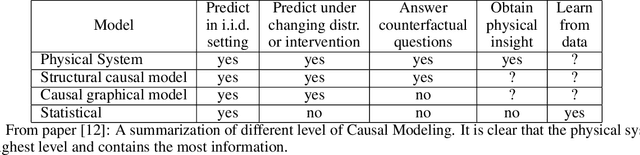
We propose a novelty approach to connect machine learning to causal structure learning by jacobian matrix of neural network w.r.t. input variables. In this paper, we extend the jacobian-based approach to physical system which is the method human explore and reason the world and it is the highest level of causality. By functions fitting with Neural ODE, we can read out causal structure from functions. This method also enforces a important acylicity constraint on continuous adjacency matrix of graph nodes and significantly reduce the computational complexity of search space of graph.
Granger Causality: A Review and Recent Advances
May 07, 2021
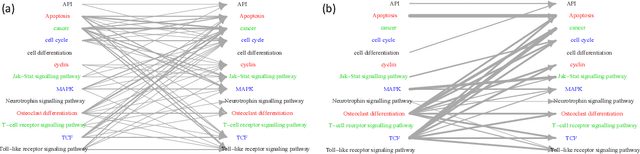
Introduced more than a half century ago, Granger causality has become a popular tool for analyzing time series data in many application domains, from economics and finance to genomics and neuroscience. Despite this popularity, the validity of this notion for inferring causal relationships among time series has remained the topic of continuous debate. Moreover, while the original definition was general, limitations in computational tools have primarily limited the applications of Granger causality to simple bivariate vector auto-regressive processes or pairwise relationships among a set of variables. Starting with a review of early developments and debates, this paper discusses recent advances that address various shortcomings of the earlier approaches, from models for high-dimensional time series to more recent developments that account for nonlinear and non-Gaussian observations and allow for sub-sampled and mixed frequency time series.
Improved Algorithms for Misspecified Linear Markov Decision Processes
Sep 12, 2021
For the misspecified linear Markov decision process (MLMDP) model of Jin et al. [2020], we propose an algorithm with three desirable properties. (P1) Its regret after $K$ episodes scales as $K \max \{ \varepsilon_{\text{mis}}, \varepsilon_{\text{tol}} \}$, where $\varepsilon_{\text{mis}}$ is the degree of misspecification and $\varepsilon_{\text{tol}}$ is a user-specified error tolerance. (P2) Its space and per-episode time complexities remain bounded as $K \rightarrow \infty$. (P3) It does not require $\varepsilon_{\text{mis}}$ as input. To our knowledge, this is the first algorithm satisfying all three properties. For concrete choices of $\varepsilon_{\text{tol}}$, we also improve existing regret bounds (up to log factors) while achieving either (P2) or (P3) (existing algorithms satisfy neither). At a high level, our algorithm generalizes (to MLMDPs) and refines the Sup-Lin-UCB algorithm, which Takemura et al. [2021] recently showed satisfies (P3) in the contextual bandit setting.
STD-Trees: Spatio-temporal Deformable Trees for Multirotors Kinodynamic Planning
Sep 16, 2021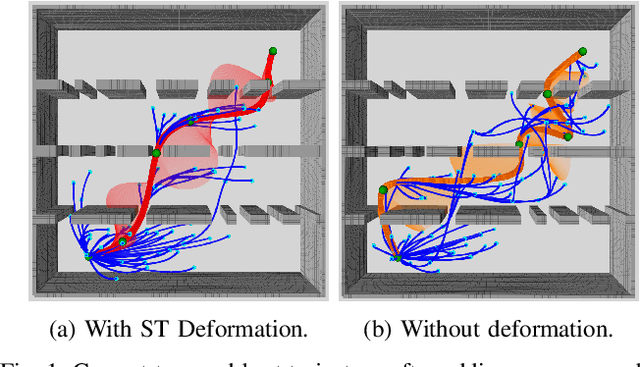
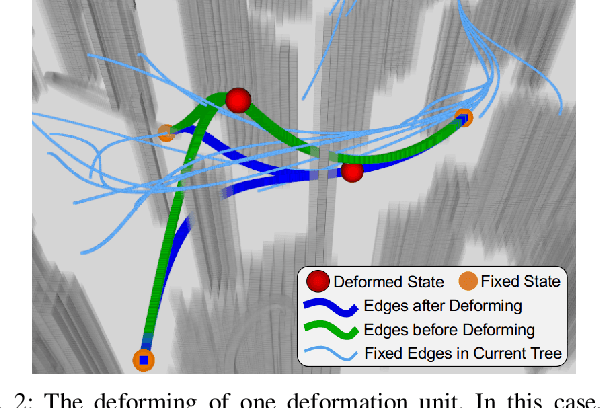
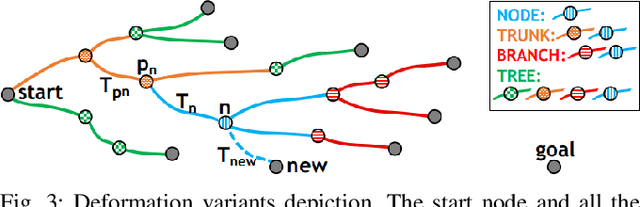
In constrained solution spaces with a huge number of homotopy classes, stand-alone sampling-based kinodynamic planners suffer low efficiency in convergence. Local optimization is integrated to alleviate this problem. In this paper, we propose to thrive the trajectory tree growing by optimizing the tree in the forms of deformation units, and each unit contains one tree node and all the edges connecting it. The deformation proceeds both spatially and temporally by optimizing the node state and edge time durations efficiently. The unit only changes the tree locally yet improves the overall quality of a corresponding sub-tree. Further, variants to deform different tree parts considering the computation burden and optimizing level are studied and compared, all showing much faster convergence. The proposed deformation is compatible with different RRT-based kinodynamic planning methods, and numerical experiments show that integrating the spatio-temporal deformation greatly accelerates the convergence and outperforms the spatial-only deformation.