 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrowing Networks with Autonomous Pruning
Mar 20, 2026This paper introduces Growing Networks with Autonomous Pruning (GNAP) for image classification. Unlike traditional convolutional neural networks, GNAP change their size, as well as the number of parameters they are using, during training, in order to best fit the data while trying to use as few parameters as possible. This is achieved through two complementary mechanisms: growth and pruning. GNAP start with few parameters, but their size is expanded periodically during training to add more expressive power each time the network has converged to a saturation point. Between these growing phases, model parameters are trained for classification and pruned simultaneously, with complete autonomy by gradient descent. Growing phases allow GNAP to improve their classification performance, while autonomous pruning allows them to keep as few parameters as possible. Experimental results on several image classification benchmarks show that our approach can train extremely sparse neural networks with high accuracy. For example, on MNIST, we achieved 99.44% accuracy with as few as 6.2k parameters, while on CIFAR10, we achieved 92.2\ accuracy with 157.8k parameters.
RAViT: Resolution-Adaptive Vision Transformer
Feb 27, 2026Vision transformers have recently made a breakthrough in computer vision showing excellent performance in terms of precision for numerous applications. However, their computational cost is very high compared to alternative approaches such as Convolutional Neural Networks. To address this problem, we propose a novel framework for image classification called RAViT based on a multi-branch network that operates on several copies of the same image with different resolutions to reduce the computational cost while preserving the overall accuracy. Furthermore, our framework includes an early exit mechanism that makes our model adaptive and allows to choose the appropriate trade-off between accuracy and computational cost at run-time. For example in a two-branch architecture, the original image is first resized to reduce its resolution, then a prediction is performed on it using a first transformer and the resulting prediction is reused together with the original-size image to perform a final prediction on a second transformer with less computation than a classical Vision transformer architecture. The early-exit process allows the model to make a final prediction at intermediate branches, saving even more computation. We evaluated our approach on CIFAR-10, Tiny ImageNet, and ImageNet. We obtained an equivalent accuracy to the classical Vision transformer model with only around 70% of FLOPs.
ERDE: Entropy-Regularized Distillation for Early-exit
Oct 06, 2025Although deep neural networks and in particular Convolutional Neural Networks have demonstrated state-of-the-art performance in image classification with relatively high efficiency, they still exhibit high computational costs, often rendering them impractical for real-time and edge applications. Therefore, a multitude of compression techniques have been developed to reduce these costs while maintaining accuracy. In addition, dynamic architectures have been introduced to modulate the level of compression at execution time, which is a desirable property in many resource-limited application scenarios. The proposed method effectively integrates two well-established optimization techniques: early exits and knowledge distillation, where a reduced student early-exit model is trained from a more complex teacher early-exit model. The primary contribution of this research lies in the approach for training the student early-exit model. In comparison to the conventional Knowledge Distillation loss, our approach incorporates a new entropy-based loss for images where the teacher's classification was incorrect. The proposed method optimizes the trade-off between accuracy and efficiency, thereby achieving significant reductions in computational complexity without compromising classification performance. The validity of this approach is substantiated by experimental results on image classification datasets CIFAR10, CIFAR100 and SVHN, which further opens new research perspectives for Knowledge Distillation in other contexts.
Towards Sharper Object Boundaries in Self-Supervised Depth Estimation
Sep 19, 2025Accurate monocular depth estimation is crucial for 3D scene understanding, but existing methods often blur depth at object boundaries, introducing spurious intermediate 3D points. While achieving sharp edges usually requires very fine-grained supervision, our method produces crisp depth discontinuities using only self-supervision. Specifically, we model per-pixel depth as a mixture distribution, capturing multiple plausible depths and shifting uncertainty from direct regression to the mixture weights. This formulation integrates seamlessly into existing pipelines via variance-aware loss functions and uncertainty propagation. Extensive evaluations on KITTI and VKITTIv2 show that our method achieves up to 35% higher boundary sharpness and improves point cloud quality compared to state-of-the-art baselines.
On GNN explanability with activation rules
Jun 17, 2024



GNNs are powerful models based on node representation learning that perform particularly well in many machine learning problems related to graphs. The major obstacle to the deployment of GNNs is mostly a problem of societal acceptability and trustworthiness, properties which require making explicit the internal functioning of such models. Here, we propose to mine activation rules in the hidden layers to understand how the GNNs perceive the world. The problem is not to discover activation rules that are individually highly discriminating for an output of the model. Instead, the challenge is to provide a small set of rules that cover all input graphs. To this end, we introduce the subjective activation pattern domain. We define an effective and principled algorithm to enumerate activations rules in each hidden layer. The proposed approach for quantifying the interest of these rules is rooted in information theory and is able to account for background knowledge on the input graph data. The activation rules can then be redescribed thanks to pattern languages involving interpretable features. We show that the activation rules provide insights on the characteristics used by the GNN to classify the graphs. Especially, this allows to identify the hidden features built by the GNN through its different layers. Also, these rules can subsequently be used for explaining GNN decisions. Experiments on both synthetic and real-life datasets show highly competitive performance, with up to 200% improvement in fidelity on explaining graph classification over the SOTA methods.
Whole-brain radiomics for clustered federated personalization in brain tumor segmentation
Oct 17, 2023



Federated learning and its application to medical image segmentation have recently become a popular research topic. This training paradigm suffers from statistical heterogeneity between participating institutions' local datasets, incurring convergence slowdown as well as potential accuracy loss compared to classical training. To mitigate this effect, federated personalization emerged as the federated optimization of one model per institution. We propose a novel personalization algorithm tailored to the feature shift induced by the usage of different scanners and acquisition parameters by different institutions. This method is the first to account for both inter and intra-institution feature shift (multiple scanners used in a single institution). It is based on the computation, within each centre, of a series of radiomic features capturing the global texture of each 3D image volume, followed by a clustering analysis pooling all feature vectors transferred from the local institutions to the central server. Each computed clustered decentralized dataset (potentially including data from different institutions) then serves to finetune a global model obtained through classical federated learning. We validate our approach on the Federated Brain Tumor Segmentation 2022 Challenge dataset (FeTS2022). Our code is available at (https://github.com/MatthisManthe/radiomics_CFFL).
Improving Information Extraction on Business Documents with Specific Pre-Training Tasks
Sep 11, 2023Transformer-based Language Models are widely used in Natural Language Processing related tasks. Thanks to their pre-training, they have been successfully adapted to Information Extraction in business documents. However, most pre-training tasks proposed in the literature for business documents are too generic and not sufficient to learn more complex structures. In this paper, we use LayoutLM, a language model pre-trained on a collection of business documents, and introduce two new pre-training tasks that further improve its capacity to extract relevant information. The first is aimed at better understanding the complex layout of documents, and the second focuses on numeric values and their order of magnitude. These tasks force the model to learn better-contextualized representations of the scanned documents. We further introduce a new post-processing algorithm to decode BIESO tags in Information Extraction that performs better with complex entities. Our method significantly improves extraction performance on both public (from 93.88 to 95.50 F1 score) and private (from 84.35 to 84.84 F1 score) datasets composed of expense receipts, invoices, and purchase orders.
* Conference: Document Analysis Systems. DAS 2022
Long-Range Transformer Architectures for Document Understanding
Sep 11, 2023Since their release, Transformers have revolutionized many fields from Natural Language Understanding to Computer Vision. Document Understanding (DU) was not left behind with first Transformer based models for DU dating from late 2019. However, the computational complexity of the self-attention operation limits their capabilities to small sequences. In this paper we explore multiple strategies to apply Transformer based models to long multi-page documents. We introduce 2 new multi-modal (text + layout) long-range models for DU. They are based on efficient implementations of Transformers for long sequences. Long-range models can process whole documents at once effectively and are less impaired by the document's length. We compare them to LayoutLM, a classical Transformer adapted for DU and pre-trained on millions of documents. We further propose 2D relative attention bias to guide self-attention towards relevant tokens without harming model efficiency. We observe improvements on multi-page business documents on Information Retrieval for a small performance cost on smaller sequences. Relative 2D attention revealed to be effective on dense text for both normal and long-range models.
* Conference: ICDAR 2023 Workshops on Document Analysis and Recognition
Learning Sparse Filters in Deep Convolutional Neural Networks with a l1/l2 Pseudo-Norm
Jul 20, 2020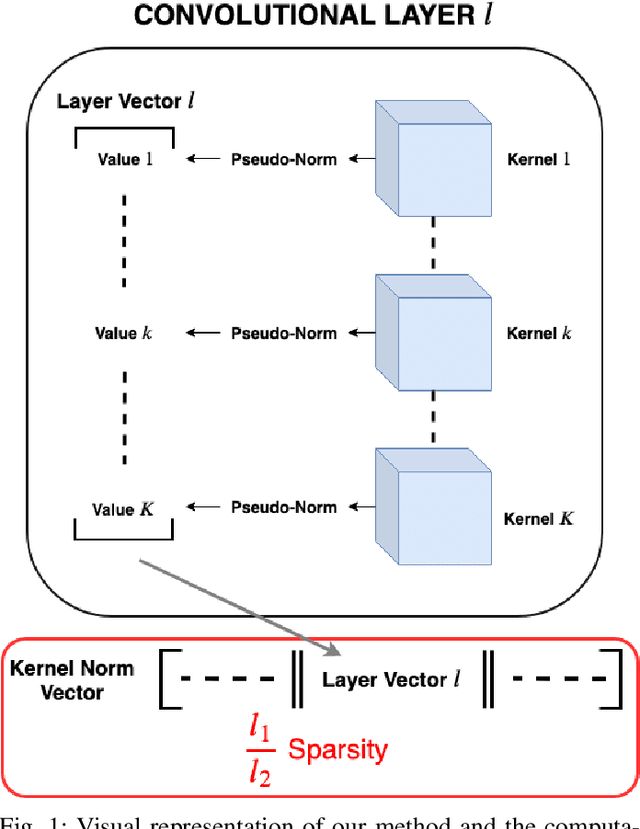
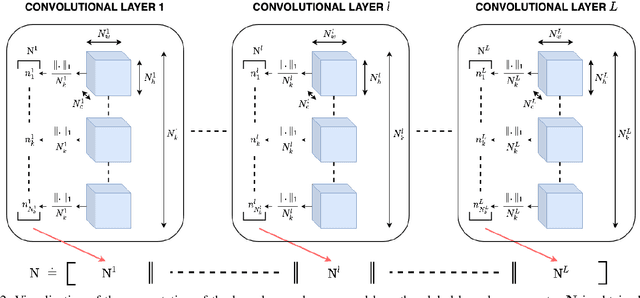
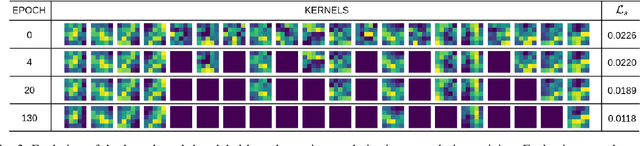
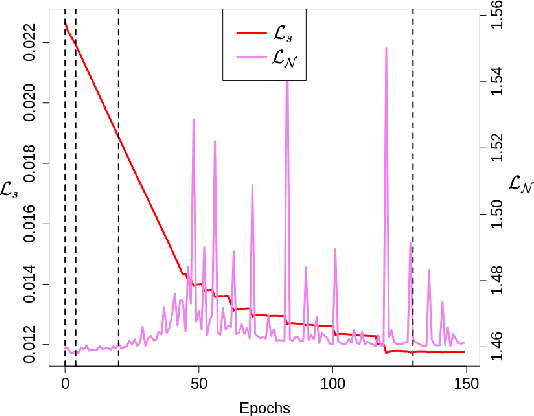
While deep neural networks (DNNs) have proven to be efficient for numerous tasks, they come at a high memory and computation cost, thus making them impractical on resource-limited devices. However, these networks are known to contain a large number of parameters. Recent research has shown that their structure can be more compact without compromising their performance. In this paper, we present a sparsity-inducing regularization term based on the ratio l1/l2 pseudo-norm defined on the filter coefficients. By defining this pseudo-norm appropriately for the different filter kernels, and removing irrelevant filters, the number of kernels in each layer can be drastically reduced leading to very compact Deep Convolutional Neural Networks (DCNN) structures. Unlike numerous existing methods, our approach does not require an iterative retraining process and, using this regularization term, directly produces a sparse model during the training process. Furthermore, our approach is also much easier and simpler to implement than existing methods. Experimental results on MNIST and CIFAR-10 show that our approach significantly reduces the number of filters of classical models such as LeNet and VGG while reaching the same or even better accuracy than the baseline models. Moreover, the trade-off between the sparsity and the accuracy is compared to other loss regularization terms based on the l1 or l2 norm as well as the SSL, NISP and GAL methods and shows that our approach is outperforming them.
Facial Landmark Correlation Analysis
Nov 24, 2019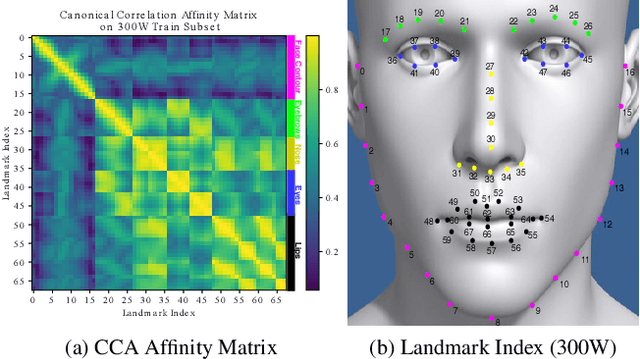


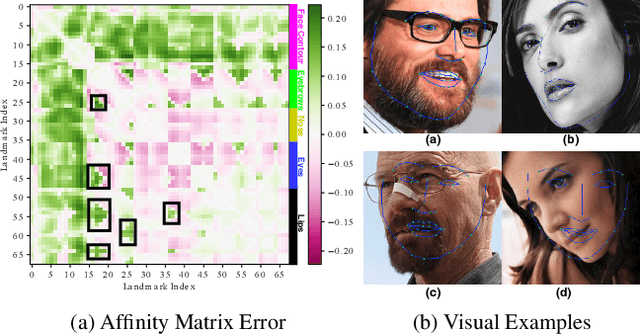
We present a facial landmark position correlation analysis as well as its applications. Although numerous facial landmark detection methods have been presented in the literature, few of them concern the intrinsic relationship among the landmarks. In order to reveal and interpret this relationship, we propose to analyze the facial landmark correlation by using Canonical Correlation Analysis (CCA). We experimentally show that dense facial landmark annotations in current benchmarks are strongly correlated, and we propose several applications based on this analysis. First, we give insights into the predictions from different facial landmark detection models (including cascaded random forests, cascaded Convolutional Neural Networks (CNNs), heatmap regression models) and interpret how CNNs progressively learn to predict facial landmarks. Second, we propose a few-shot learning method that allows to considerably reduce manual effort for dense landmark annotation. To this end, we select a portion of landmarks from the dense annotation format to form a sparse format, which is mostly correlated to the rest of them. Thanks to the strong correlation among the landmarks, the entire set of dense facial landmarks can then be inferred from the annotation in the sparse format by transfer learning. Unlike the previous methods, we mainly focus on how to find the most efficient sparse format to annotate. Overall, our correlation analysis provides new perspectives for the research on facial landmark detection.