 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness In Sparse Autoencoders via Masked Regularization
Apr 07, 2026Sparse autoencoders (SAEs) are widely used in mechanistic interpretability to project LLM activations onto sparse latent spaces. However, sparsity alone is an imperfect proxy for interpretability, and current training objectives often result in brittle latent representations. SAEs are known to be prone to feature absorption, where general features are subsumed by more specific ones due to co-occurrence, degrading interpretability despite high reconstruction fidelity. Recent negative results on Out-of-Distribution (OOD) performance further underscore broader robustness related failures tied to under-specified training objectives. We address this by proposing a masking-based regularization that randomly replaces tokens during training to disrupt co-occurrence patterns. This improves robustness across SAE architectures and sparsity levels reducing absorption, enhancing probing performance, and narrowing the OOD gap. Our results point toward a practical path for more reliable interpretability tools.
The Anatomy of Uncertainty in LLMs
Mar 26, 2026Understanding why a large language model (LLM) is uncertain about the response is important for their reliable deployment. Current approaches, which either provide a single uncertainty score or rely on the classical aleatoric-epistemic dichotomy, fail to offer actionable insights for improving the generative model. Recent studies have also shown that such methods are not enough for understanding uncertainty in LLMs. In this work, we advocate for an uncertainty decomposition framework that dissects LLM uncertainty into three distinct semantic components: (i) input ambiguity, arising from ambiguous prompts; (ii) knowledge gaps, caused by insufficient parametric evidence; and (iii) decoding randomness, stemming from stochastic sampling. Through a series of experiments we demonstrate that the dominance of these components can shift across model size and task. Our framework provides a better understanding to audit LLM reliability and detect hallucinations, paving the way for targeted interventions and more trustworthy systems.
Interpretable and Steerable Concept Bottleneck Sparse Autoencoders
Dec 11, 2025



Sparse autoencoders (SAEs) promise a unified approach for mechanistic interpretability, concept discovery, and model steering in LLMs and LVLMs. However, realizing this potential requires that the learned features be both interpretable and steerable. To that end, we introduce two new computationally inexpensive interpretability and steerability metrics and conduct a systematic analysis on LVLMs. Our analysis uncovers two observations; (i) a majority of SAE neurons exhibit either low interpretability or low steerability or both, rendering them ineffective for downstream use; and (ii) due to the unsupervised nature of SAEs, user-desired concepts are often absent in the learned dictionary, thus limiting their practical utility. To address these limitations, we propose Concept Bottleneck Sparse Autoencoders (CB-SAE) - a novel post-hoc framework that prunes low-utility neurons and augments the latent space with a lightweight concept bottleneck aligned to a user-defined concept set. The resulting CB-SAE improves interpretability by +32.1% and steerability by +14.5% across LVLMs and image generation tasks. We will make our code and model weights available.
Leveraging Registers in Vision Transformers for Robust Adaptation
Jan 08, 2025


Vision Transformers (ViTs) have shown success across a variety of tasks due to their ability to capture global image representations. Recent studies have identified the existence of high-norm tokens in ViTs, which can interfere with unsupervised object discovery. To address this, the use of "registers" which are additional tokens that isolate high norm patch tokens while capturing global image-level information has been proposed. While registers have been studied extensively for object discovery, their generalization properties particularly in out-of-distribution (OOD) scenarios, remains underexplored. In this paper, we examine the utility of register token embeddings in providing additional features for improving generalization and anomaly rejection. To that end, we propose a simple method that combines the special CLS token embedding commonly employed in ViTs with the average-pooled register embeddings to create feature representations which are subsequently used for training a downstream classifier. We find that this enhances OOD generalization and anomaly rejection, while maintaining in-distribution (ID) performance. Extensive experiments across multiple ViT backbones trained with and without registers reveal consistent improvements of 2-4\% in top-1 OOD accuracy and a 2-3\% reduction in false positive rates for anomaly detection. Importantly, these gains are achieved without additional computational overhead.
DECIDER: Leveraging Foundation Model Priors for Improved Model Failure Detection and Explanation
Aug 01, 2024



Reliably detecting when a deployed machine learning model is likely to fail on a given input is crucial for ensuring safe operation. In this work, we propose DECIDER (Debiasing Classifiers to Identify Errors Reliably), a novel approach that leverages priors from large language models (LLMs) and vision-language models (VLMs) to detect failures in image classification models. DECIDER utilizes LLMs to specify task-relevant core attributes and constructs a ``debiased'' version of the classifier by aligning its visual features to these core attributes using a VLM, and detects potential failure by measuring disagreement between the original and debiased models. In addition to proactively identifying samples on which the model would fail, DECIDER also provides human-interpretable explanations for failure through a novel attribute-ablation strategy. Through extensive experiments across diverse benchmarks spanning subpopulation shifts (spurious correlations, class imbalance) and covariate shifts (synthetic corruptions, domain shifts), DECIDER consistently achieves state-of-the-art failure detection performance, significantly outperforming baselines in terms of the overall Matthews correlation coefficient as well as failure and success recall. Our codes can be accessed at~\url{https://github.com/kowshikthopalli/DECIDER/}
On the Use of Anchoring for Training Vision Models
Jun 01, 2024



Anchoring is a recent, architecture-agnostic principle for training deep neural networks that has been shown to significantly improve uncertainty estimation, calibration, and extrapolation capabilities. In this paper, we systematically explore anchoring as a general protocol for training vision models, providing fundamental insights into its training and inference processes and their implications for generalization and safety. Despite its promise, we identify a critical problem in anchored training that can lead to an increased risk of learning undesirable shortcuts, thereby limiting its generalization capabilities. To address this, we introduce a new anchored training protocol that employs a simple regularizer to mitigate this issue and significantly enhances generalization. We empirically evaluate our proposed approach across datasets and architectures of varying scales and complexities, demonstrating substantial performance gains in generalization and safety metrics compared to the standard training protocol.
PAGER: A Framework for Failure Analysis of Deep Regression Models
Sep 20, 2023



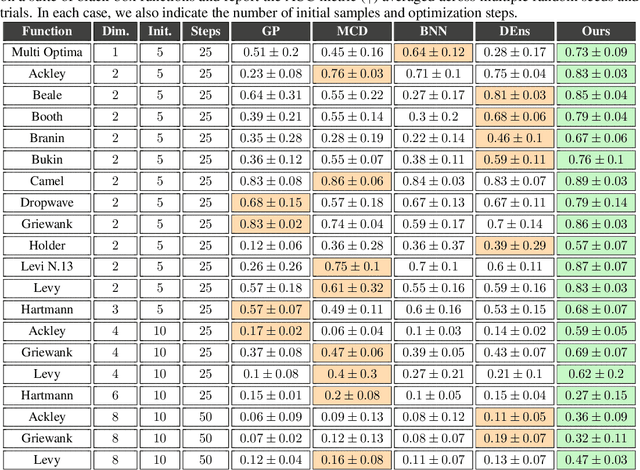
Safe deployment of AI models requires proactive detection of potential prediction failures to prevent costly errors. While failure detection in classification problems has received significant attention, characterizing failure modes in regression tasks is more complicated and less explored. Existing approaches rely on epistemic uncertainties or feature inconsistency with the training distribution to characterize model risk. However, we show that uncertainties are necessary but insufficient to accurately characterize failure, owing to the various sources of error. In this paper, we propose PAGER (Principled Analysis of Generalization Errors in Regressors), a framework to systematically detect and characterize failures in deep regression models. Built upon the recently proposed idea of anchoring in deep models, PAGER unifies both epistemic uncertainties and novel, complementary non-conformity scores to organize samples into different risk regimes, thereby providing a comprehensive analysis of model errors. Additionally, we introduce novel metrics for evaluating failure detectors in regression tasks. We demonstrate the effectiveness of PAGER on synthetic and real-world benchmarks. Our results highlight the capability of PAGER to identify regions of accurate generalization and detect failure cases in out-of-distribution and out-of-support scenarios.
An L2-Normalized Spatial Attention Network For Accurate And Fast Classification Of Brain Tumors In 2D T1-Weighted CE-MRI Images
Aug 01, 2023


We propose an accurate and fast classification network for classification of brain tumors in MRI images that outperforms all lightweight methods investigated in terms of accuracy. We test our model on a challenging 2D T1-weighted CE-MRI dataset containing three types of brain tumors: Meningioma, Glioma and Pituitary. We introduce an l2-normalized spatial attention mechanism that acts as a regularizer against overfitting during training. We compare our results against the state-of-the-art on this dataset and show that by integrating l2-normalized spatial attention into a baseline network we achieve a performance gain of 1.79 percentage points. Even better accuracy can be attained by combining our model in an ensemble with the pretrained VGG16 at the expense of execution speed. Our code is publicly available at https://github.com/juliadietlmeier/MRI_image_classification
Single Model Uncertainty Estimation via Stochastic Data Centering
Jul 14, 2022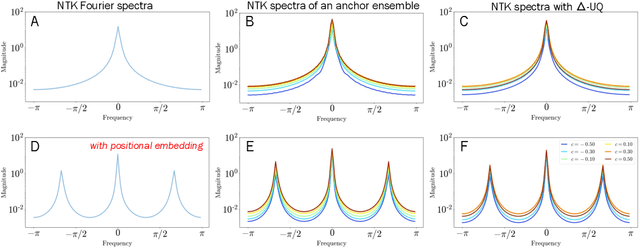
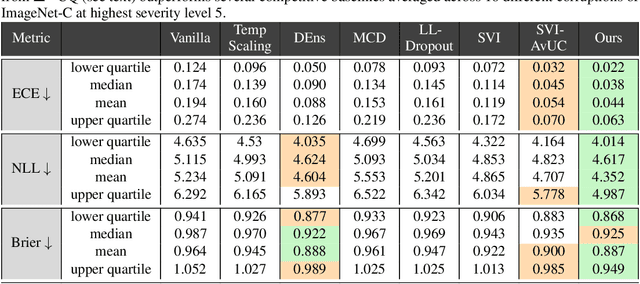

We are interested in estimating the uncertainties of deep neural networks, which play an important role in many scientific and engineering problems. In this paper, we present a striking new finding that an ensemble of neural networks with the same weight initialization, trained on datasets that are shifted by a constant bias gives rise to slightly inconsistent trained models, where the differences in predictions are a strong indicator of epistemic uncertainties. Using the neural tangent kernel (NTK), we demonstrate that this phenomena occurs in part because the NTK is not shift-invariant. Since this is achieved via a trivial input transformation, we show that it can therefore be approximated using just a single neural network -- using a technique that we call $\Delta-$UQ -- that estimates uncertainty around prediction by marginalizing out the effect of the biases. We show that $\Delta-$UQ's uncertainty estimates are superior to many of the current methods on a variety of benchmarks -- outlier rejection, calibration under distribution shift, and sequential design optimization of black box functions.
Revisiting Inlier and Outlier Specification for Improved Out-of-Distribution Detection
Jul 12, 2022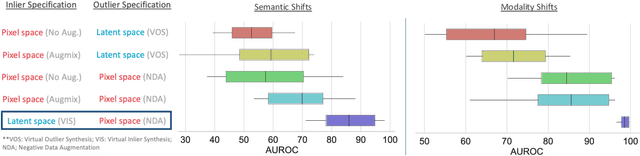
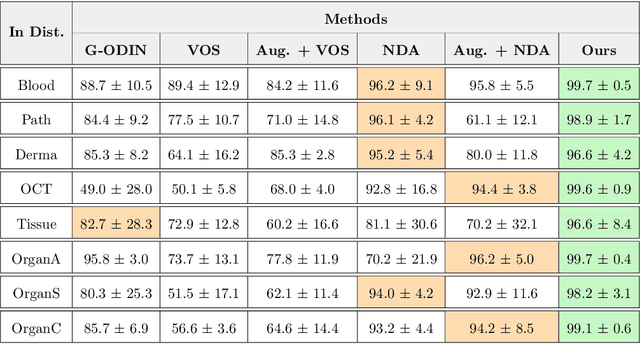
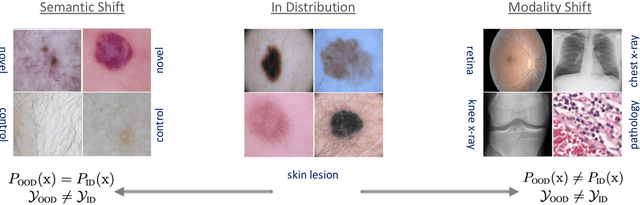
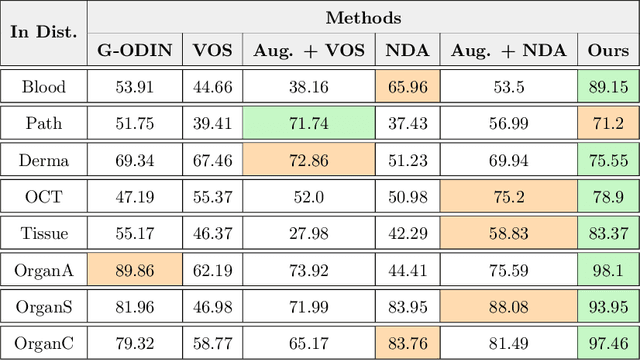
Accurately detecting out-of-distribution (OOD) data with varying levels of semantic and covariate shifts with respect to the in-distribution (ID) data is critical for deployment of safe and reliable models. This is particularly the case when dealing with highly consequential applications (e.g. medical imaging, self-driving cars, etc). The goal is to design a detector that can accept meaningful variations of the ID data, while also rejecting examples from OOD regimes. In practice, this dual objective can be realized by enforcing consistency using an appropriate scoring function (e.g., energy) and calibrating the detector to reject a curated set of OOD data (referred to as outlier exposure or shortly OE). While OE methods are widely adopted, assembling representative OOD datasets is both costly and challenging due to the unpredictability of real-world scenarios, hence the recent trend of designing OE-free detectors. In this paper, we make a surprising finding that controlled generalization to ID variations and exposure to diverse (synthetic) outlier examples are essential to simultaneously improving semantic and modality shift detection. In contrast to existing methods, our approach samples inliers in the latent space, and constructs outlier examples via negative data augmentation. Through a rigorous empirical study on medical imaging benchmarks (MedMNIST, ISIC2019 and NCT), we demonstrate significant performance gains ($15\% - 35\%$ in AUROC) over existing OE-free, OOD detection approaches under both semantic and modality shifts.