 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfigurable Algorithms for Histopathologic Cancer Detection on Quantum Hardware
Jun 19, 2026Histopathologic cancer detection is challenging due to tissue variability, staining differences, and subtle visual distinctions between disease classes. We propose two quantum algorithms for this task: a configurable dual-gradient CSWAP circuit (DG-CSWAP) that computes multi-directional edge responses in a single execution via per-pixel local Ry encoding, and a hardware-efficient destructive swap circuit (DG-DST) natively matched to quantum processing unit (QPU) gate sets at substantially lower circuit complexity. We prove algebraic equivalence between DG-CSWAP and DG-DST, enabling a two-circuit QPU validation strategy. A three-stage NISQ mitigation pipeline, including readout error correction, bias subtraction, and slope regression, reduces single-pixel hardware MSE by ~8x. Validated on five quantum processors via Amazon Braket, the method achieves inter-platform Pearson r ~ 0.93-0.94 across all local-simulator pairs. Compared to a prior Quantum Fourier Transform (QFT) based amplitude-encoding baseline requiring 12-qubit global state preparation and a three-model ensemble (85.55% on PatchCamelyon), the proposed method uses shot-based measurements, executes on real quantum hardware, and achieves 79.80% accuracy with a single ResNet-50. A Lite configuration delivers a 17x preprocessing speedup at a 2.59% accuracy cost. To the best of our knowledge, this is the first quantum hardware implementation study with noise mitigation for histopathologic image classification.
Geospatial-Temporal Sensemaking of Remote Sensing Activity Detections with Multimodal Large Language Model
May 11, 2026We introduce SMART-HC-VQA, a Sentinel-2-based visual question answering dataset derived from the IARPA SMART Heavy Construction dataset, designed for spatiotemporal analysis of human activity. The dataset transforms construction-site annotations, construction-type labels, temporal-phase labels, geographic metadata, and observation relationships into natural language question-answer triplets. This approach redefines the existing dataset as a temporally extended automatic target recognition and visual question answering (VQA) challenge, considering a fixed geospatial site as a target whose attributes and activity states evolve across sparse satellite observations. Currently, SMART-HC-VQA comprises 21,837 accessible Sentinel-2 image chips, 65,511 single-image VQA examples, and approximately 2.3 million two-image temporal comparison examples generated via our novel Image-Pairwise Combinatorial Augmentation. We detail the workflow for retrieving and processing Sentinel-2 imagery, segmenting large satellite tiles into site-centered images, maintaining traceability to SMART-HC annotations, and analyzing the distributions of site size, observation count, temporal coverage, construction type, and phase labels. Additionally, we describe an implemented multi-image MLLM training framework based on LLaVA-NeXT Mistral-7B, adapted to accept multiple dated image inputs and train on metadata-derived VQA examples. This work offers a reproducible foundation for understanding language-guided remote sensing activities, aiming not only to detect change but also to reason about the ongoing processes, their progression, and potential future developments.
Towards a Large Language-Vision Question Answering Model for MSTAR Automatic Target Recognition
May 11, 2026Large language-vision models (LLVM), such as OpenAI's ChatGPT and GPT-4, have gained prominence as powerful tools for analyzing text and imagery. The merging of these data domains represents a significant paradigm shift with far-reaching implications for automatic target recognition (ATR). Recent transformer-based LLVM research has shown substantial improvements for geospatial perception tasks. Our study examines the application of LLVM to remote sensing image captioning and visual question-answering (VQA), with a specific focus on synthetic aperture radar (SAR) imagery. We examine newly published LLVM methods, including CLIP and LLaVA neural network transformer architectures. We have developed a work-in-progress SAR training and evaluation benchmark derived from the MSTAR Public Dataset. This has been extended to include descriptive text captions and question-answer pairs for VQA tasks. This challenge dataset is designed to push the boundaries of an LLVM in identifying nuanced ATR details in SAR imagery. Utilizing parameter-efficient fine-tuning, we train an LLVM method to identify fine-grained target qualities at 98% accuracy. We detail our data setup and experiments, addressing potential pitfalls that could lead to misleading conclusions. Accurately identifying and differentiating military vehicle types in SAR data poses a critical challenge, especially under complex environmental conditions. Mastering this target recognition skill may require a human analyst months of training and years of practice. This research represents a unique effort to apply LLVM to SAR applications, advancing machine-assisted remote sensing ATR for military and intelligence contexts.
* Accepted to SPIE Defense + Commercial Sensing, Automatic Target Recognition XXXV
Twenty-five years of J-DSP Online Labs for Signal Processing Classes and Workforce Development Programs
Feb 14, 2026This paper presents the history of the online simulation program Java-DSP (J-DSP) and the most recent function development and deployment. J-DSP was created to support online laboratories in DSP classes and was first deployed in our ASU DSP class in 2000. The development of the program and its extensions was supported by several NSF grants including CCLI and IUSE. The web-based software was developed by our team in Java and later transitioned to the more secure HTML5 environment. J-DSP supports laboratory exercises on: digital filters and their design, the FFT and its utility in spectral analysis, machine learning for signal classification, and more recently online simulations with the Quantum Fourier Transform. Throughout the J-DSP development and deployment of this tool and its associated laboratory exercises, we documented evaluations. Mobile versions of the program for iOS and Android were also developed. J-DSP is used to this day in several universities, and specific functions of the program have been used in NSF REU, IRES and RET workforce development and high school outreach.
SAR-RAG: ATR Visual Question Answering by Semantic Search, Retrieval, and MLLM Generation
Feb 04, 2026We present a visual-context image retrieval-augmented generation (ImageRAG) assisted AI agent for automatic target recognition (ATR) of synthetic aperture radar (SAR). SAR is a remote sensing method used in defense and security applications to detect and monitor the positions of military vehicles, which may appear indistinguishable in images. Researchers have extensively studied SAR ATR to improve the differentiation and identification of vehicle types, characteristics, and measurements. Test examples can be compared with known vehicle target types to improve recognition tasks. New methods enhance the capabilities of neural networks, transformer attention, and multimodal large language models. An agentic AI method may be developed to utilize a defined set of tools, such as searching through a library of similar examples. Our proposed method, SAR Retrieval-Augmented Generation (SAR-RAG), combines a multimodal large language model (MLLM) with a vector database of semantic embeddings to support contextual search for image exemplars with known qualities. By recovering past image examples with known true target types, our SAR-RAG system can compare similar vehicle categories, achieving improved ATR prediction accuracy. We evaluate this through search and retrieval metrics, categorical classification accuracy, and numeric regression of vehicle dimensions. These metrics all show improvements when SAR-RAG is added to an MLLM baseline method as an attached ATR memory bank.
Infrared Computer Vision for Utility-Scale Photovoltaic Array Inspection
Jun 29, 2024



Utility-scale solar arrays require specialized inspection methods for detecting faulty panels. Photovoltaic (PV) panel faults caused by weather, ground leakage, circuit issues, temperature, environment, age, and other damage can take many forms but often symptomatically exhibit temperature differences. Included is a mini survey to review these common faults and PV array fault detection approaches. Among these, infrared thermography cameras are a powerful tool for improving solar panel inspection in the field. These can be combined with other technologies, including image processing and machine learning. This position paper examines several computer vision algorithms that automate thermal anomaly detection in infrared imagery. We demonstrate our infrared thermography data collection approach, the PV thermal imagery benchmark dataset, and the measured performance of image processing transformations, including the Hough Transform for PV segmentation. The results of this implementation are presented with a discussion of future work.
An L2-Normalized Spatial Attention Network For Accurate And Fast Classification Of Brain Tumors In 2D T1-Weighted CE-MRI Images
Aug 01, 2023


We propose an accurate and fast classification network for classification of brain tumors in MRI images that outperforms all lightweight methods investigated in terms of accuracy. We test our model on a challenging 2D T1-weighted CE-MRI dataset containing three types of brain tumors: Meningioma, Glioma and Pituitary. We introduce an l2-normalized spatial attention mechanism that acts as a regularizer against overfitting during training. We compare our results against the state-of-the-art on this dataset and show that by integrating l2-normalized spatial attention into a baseline network we achieve a performance gain of 1.79 percentage points. Even better accuracy can be attained by combining our model in an ensemble with the pretrained VGG16 at the expense of execution speed. Our code is publicly available at https://github.com/juliadietlmeier/MRI_image_classification
Towards Live 3D Reconstruction from Wearable Video: An Evaluation of V-SLAM, NeRF, and Videogrammetry Techniques
Nov 21, 2022



Mixed reality (MR) is a key technology which promises to change the future of warfare. An MR hybrid of physical outdoor environments and virtual military training will enable engagements with long distance enemies, both real and simulated. To enable this technology, a large-scale 3D model of a physical environment must be maintained based on live sensor observations. 3D reconstruction algorithms should utilize the low cost and pervasiveness of video camera sensors, from both overhead and soldier-level perspectives. Mapping speed and 3D quality can be balanced to enable live MR training in dynamic environments. Given these requirements, we survey several 3D reconstruction algorithms for large-scale mapping for military applications given only live video. We measure 3D reconstruction performance from common structure from motion, visual-SLAM, and photogrammetry techniques. This includes the open source algorithms COLMAP, ORB-SLAM3, and NeRF using Instant-NGP. We utilize the autonomous driving academic benchmark KITTI, which includes both dashboard camera video and lidar produced 3D ground truth. With the KITTI data, our primary contribution is a quantitative evaluation of 3D reconstruction computational speed when considering live video.
Revisiting Inlier and Outlier Specification for Improved Out-of-Distribution Detection
Jul 12, 2022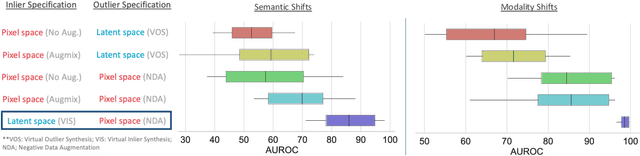
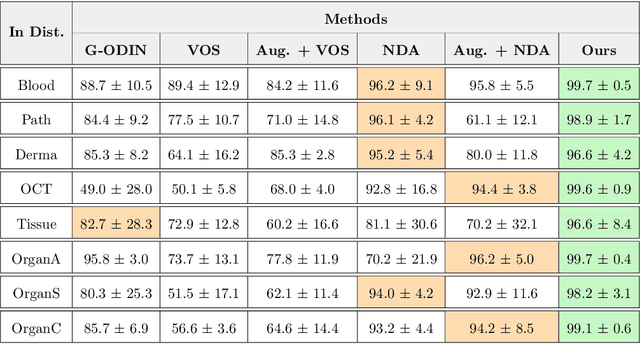
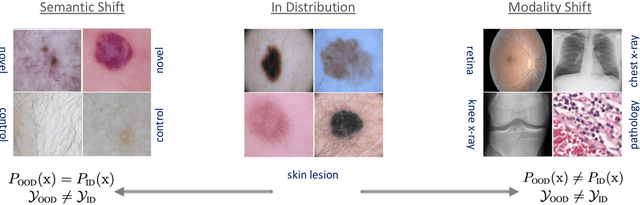
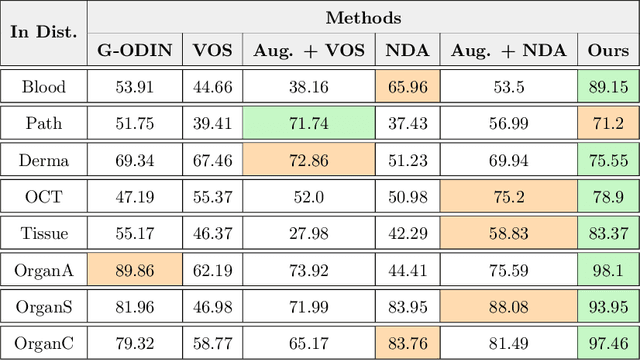
Accurately detecting out-of-distribution (OOD) data with varying levels of semantic and covariate shifts with respect to the in-distribution (ID) data is critical for deployment of safe and reliable models. This is particularly the case when dealing with highly consequential applications (e.g. medical imaging, self-driving cars, etc). The goal is to design a detector that can accept meaningful variations of the ID data, while also rejecting examples from OOD regimes. In practice, this dual objective can be realized by enforcing consistency using an appropriate scoring function (e.g., energy) and calibrating the detector to reject a curated set of OOD data (referred to as outlier exposure or shortly OE). While OE methods are widely adopted, assembling representative OOD datasets is both costly and challenging due to the unpredictability of real-world scenarios, hence the recent trend of designing OE-free detectors. In this paper, we make a surprising finding that controlled generalization to ID variations and exposure to diverse (synthetic) outlier examples are essential to simultaneously improving semantic and modality shift detection. In contrast to existing methods, our approach samples inliers in the latent space, and constructs outlier examples via negative data augmentation. Through a rigorous empirical study on medical imaging benchmarks (MedMNIST, ISIC2019 and NCT), we demonstrate significant performance gains ($15\% - 35\%$ in AUROC) over existing OE-free, OOD detection approaches under both semantic and modality shifts.
Adaptive Subsampling for ROI-based Visual Tracking: Algorithms and FPGA Implementation
Jan 17, 2022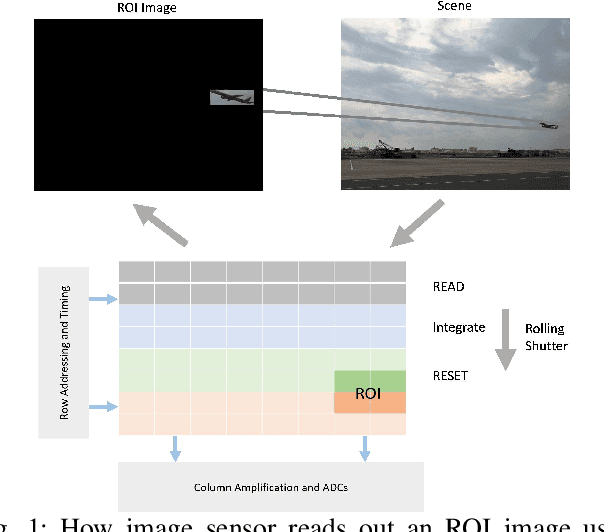

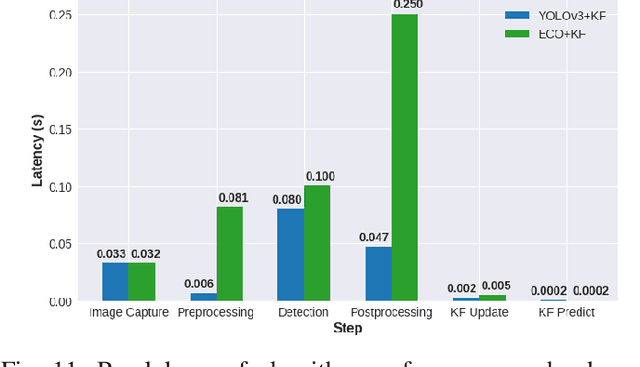

There is tremendous scope for improving the energy efficiency of embedded vision systems by incorporating programmable region-of-interest (ROI) readout in the image sensor design. In this work, we study how ROI programmability can be leveraged for tracking applications by anticipating where the ROI will be located in future frames and switching pixels off outside of this region. We refer to this process of ROI prediction and corresponding sensor configuration as adaptive subsampling. Our adaptive subsampling algorithms comprise an object detector and an ROI predictor (Kalman filter) which operate in conjunction to optimize the energy efficiency of the vision pipeline with the end task being object tracking. To further facilitate the implementation of our adaptive algorithms in real life, we select a candidate algorithm and map it onto an FPGA. Leveraging Xilinx Vitis AI tools, we designed and accelerated a YOLO object detector-based adaptive subsampling algorithm. In order to further improve the algorithm post-deployment, we evaluated several competing baselines on the OTB100 and LaSOT datasets. We found that coupling the ECO tracker with the Kalman filter has a competitive AUC score of 0.4568 and 0.3471 on the OTB100 and LaSOT datasets respectively. Further, the power efficiency of this algorithm is on par with, and in a couple of instances superior to, the other baselines. The ECO-based algorithm incurs a power consumption of approximately 4 W averaged across both datasets while the YOLO-based approach requires power consumption of approximately 6 W (as per our power consumption model). In terms of accuracy-latency tradeoff, the ECO-based algorithm provides near-real-time performance (19.23 FPS) while managing to attain competitive tracking precision.