 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online programming system for robotic fillet welding in Industry 4.0
Dec 21, 2021
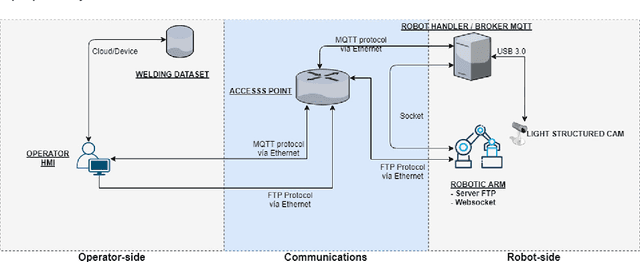
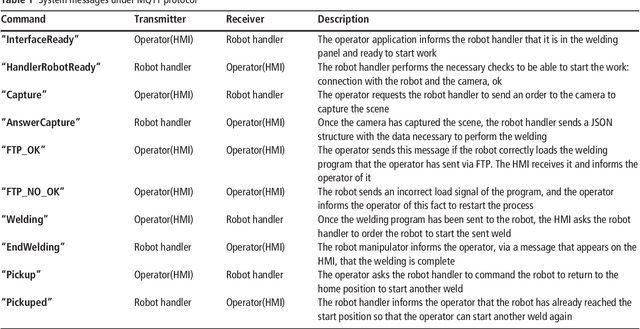


Fillet welding is one of the most widespread types of welding in the industry, which is still carried out manually or automated by contact. This paper aims to describe an online programming system for noncontact fillet welding robots with U and L shaped structures, which responds to the needs of the Fourth Industrial Revolution. In this paper, the authors propose an online robot programming methodology that eliminates unnecessary steps traditionally performed in robotic welding, so that the operator only performs three steps to complete the welding task. First, choose the piece to weld. Then, enter the welding parameters. Finally, it sends the automatically generated program to the robot. The system finally managed to perform the fillet welding task with the proposed method in a more efficient preparation time than the compared methods. For this, a reduced number of components was used compared to other systems, such as, a structured light 3D camera, two computers and a concentrator, in addition to the six axis industrial robotic arm. The operating complexity of the system has been reduced as much as possible. To the best of the authors knowledge, there is no scientific or commercial evidence of an online robot programming system capable of performing a fillet welding process, simplifying the process so that it is completely transparent for the operator and framed in the Industry 4.0 paradigm. Its commercial potential lies mainly in its simple and low cost implementation in a flexible system capable of adapting to any industrial fillet welding job and to any support that can accommodate it.
Multi Agent Reinforcement Learning Trajectory Design and Two-Stage Resource Management in CoMP UAV VLC Networks
Dec 03, 2021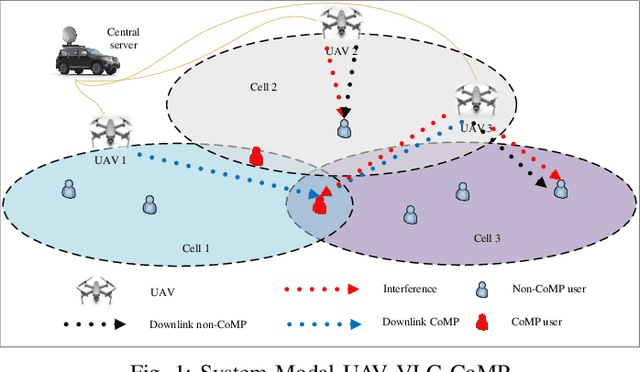
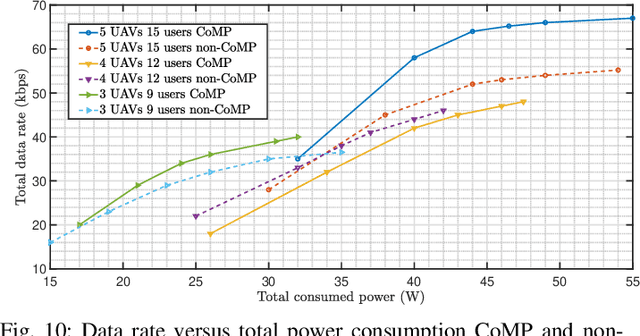
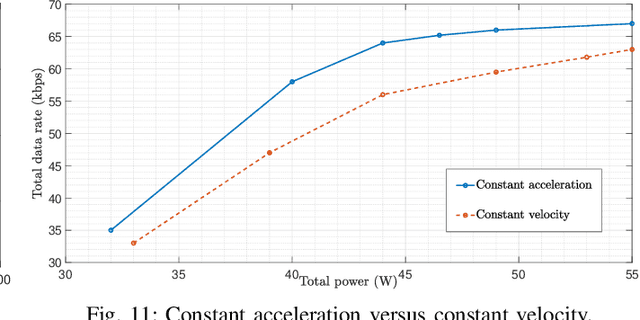
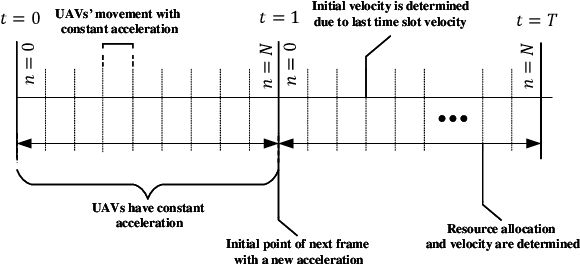
In this paper, we consider unmanned aerial vehicles (UAVs) equipped with a visible light communication (VLC) access point and coordinated multipoint (CoMP) capability that allows users to connect to more than one UAV. UAVs can move in 3-dimensional (3D) at a constant acceleration, where a central server is responsible for synchronization and cooperation among UAVs. The effect of accelerated motion in UAV is necessary to be considered. Unlike most existing works, we examine the effects of variable speed on kinetics and radio resource allocations. For the proposed system model, we define two different time frames. In the frame, the acceleration of each UAV is specified, and in each slot, radio resources are allocated. Our goal is to formulate a multiobjective optimization problem where the total data rate is maximized, and the total communication power consumption is minimized simultaneously. To handle this multiobjective optimization, we first apply the scalarization method and then apply multi-agent deep deterministic policy gradient (MADDPG). We improve this solution method by adding two critic networks together with two-stage resources allocation. Simulation results indicate that the constant acceleration motion of UAVs shows about 8\% better results than conventional motion systems in terms of performance.
An empirical study of neural networks for trend detection in time series
Dec 09, 2019

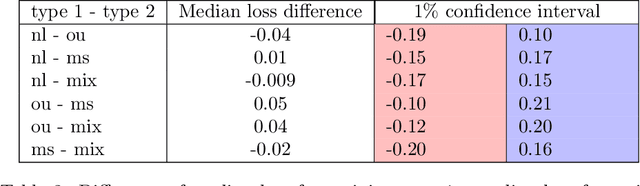
Detecting structure in noisy time series is a difficult task. One intuitive feature is the notion of trend. From theoretical hints and using simulated time series, we empirically investigate the efficiency of standard recurrent neural networks (RNNs) to detect trends. We show the overall superiority and versatility of certain standard RNNs structures over various other estimators. These RNNs could be used as basic blocks to build more complex time series trend estimators.
GM-Livox: An Integrated Framework for Large-Scale Map Construction with Multiple Non-repetitive Scanning LiDARs
Oct 11, 2021

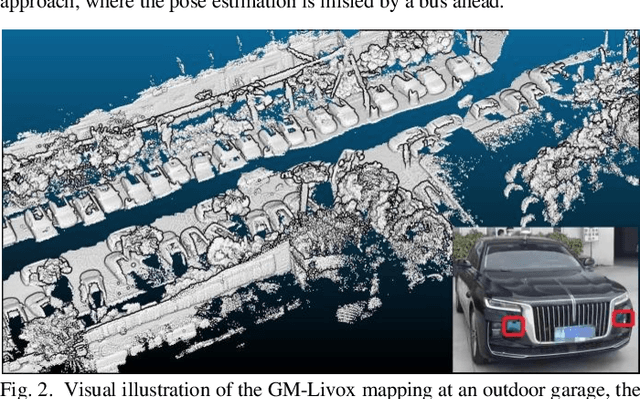
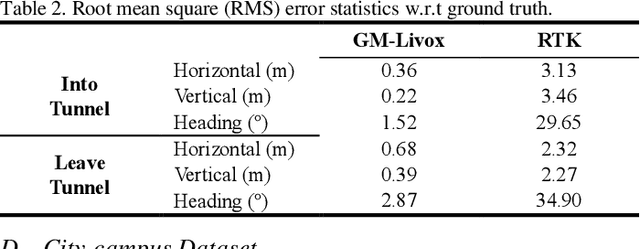
With the ability of providing direct and accurate enough range measurements, light detection and ranging (LiDAR) is playing an essential role in localization and detection for autonomous vehicles. Since single LiDAR suffers from hardware failure and performance degradation intermittently, we present a multi-LiDAR integration scheme in this article. Our framework tightly couples multiple non-repetitive scanning LiDARs with inertial, encoder, and global navigation satellite system (GNSS) into pose estimation and simultaneous global map generation. Primarily, we formulate a precise synchronization strategy to integrate isolated sensors, and the extracted feature points from separate LiDARs are merged into a single sweep. The fused scans are introduced to compute the scan-matching correspondences, which can be further refined by additional real-time kinematic (RTK) measurements. Based thereupon, we construct a factor graph along with the inertial preintegration result, estimated ground constraints, and RTK data. For the purpose of maintaining a restricted number of poses for estimation, we deploy a keyframe based sliding-window optimization strategy in our system. The real-time performance is guaranteed with multi-threaded computation, and extensive experiments are conducted in challenging scenarios. Experimental results show that the utilization of multiple LiDARs boosts the system performance in both robustness and accuracy.
Learnable Faster Kernel-PCA for Nonlinear Fault Detection: Deep Autoencoder-Based Realization
Dec 08, 2021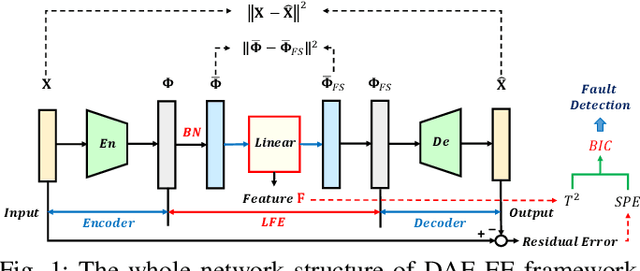
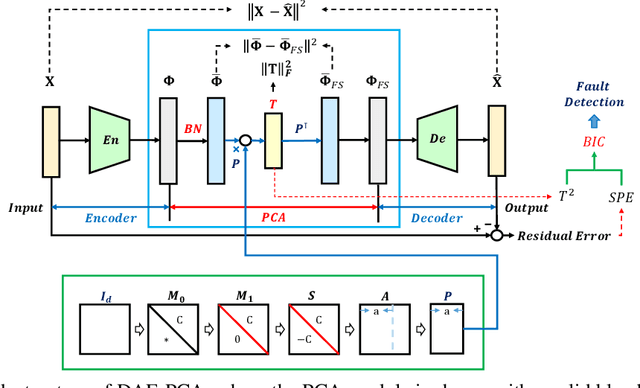
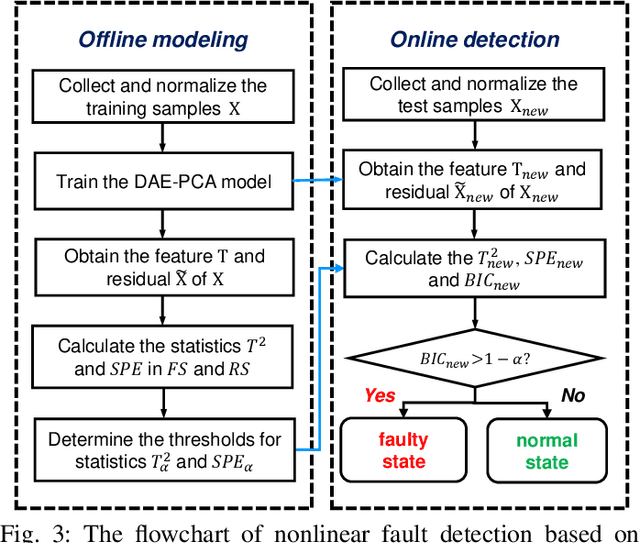
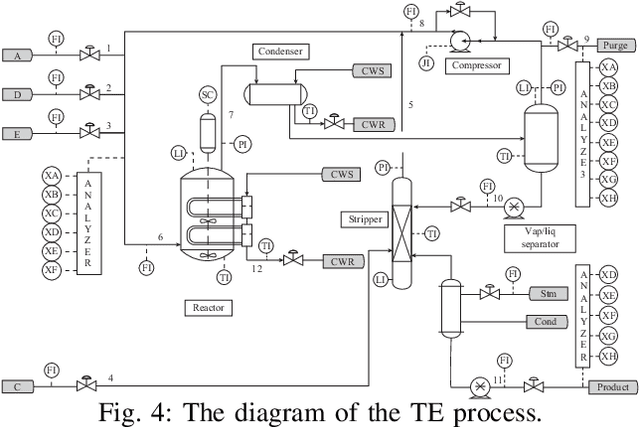
Kernel principal component analysis (KPCA) is a well-recognized nonlinear dimensionality reduction method that has been widely used in nonlinear fault detection tasks. As a kernel trick-based method, KPCA inherits two major problems. First, the form and the parameters of the kernel function are usually selected blindly, depending seriously on trial-and-error. As a result, there may be serious performance degradation in case of inappropriate selections. Second, at the online monitoring stage, KPCA has much computational burden and poor real-time performance, because the kernel method requires to leverage all the offline training data. In this work, to deal with the two drawbacks, a learnable faster realization of the conventional KPCA is proposed. The core idea is to parameterize all feasible kernel functions using the novel nonlinear DAE-FE (deep autoencoder based feature extraction) framework and propose DAE-PCA (deep autoencoder based principal component analysis) approach in detail. The proposed DAE-PCA method is proved to be equivalent to KPCA but has more advantage in terms of automatic searching of the most suitable nonlinear high-dimensional space according to the inputs. Furthermore, the online computational efficiency improves by approximately 100 times compared with the conventional KPCA. With the Tennessee Eastman (TE) process benchmark, the effectiveness and superiority of the proposed method is illustrated.
The similarity index of scientific publications with equations and formulas, identification of self-plagiarism, and testing of the iThenticate system
Dec 21, 2021The problems of estimating the similarity index of mathematical and other scientific publications containing equations and formulas are discussed for the first time. It is shown that the presence of equations and formulas (as well as figures, drawings, and tables) is a complicating factor that significantly complicates the study of such texts. It is shown that the method for determining the similarity index of publications, based on taking into account individual mathematical symbols and parts of equations and formulas, is ineffective and can lead to erroneous and even completely absurd conclusions. The possibilities of the most popular software system iThenticate, currently used in scientific journals, are investigated for detecting plagiarism and self-plagiarism. The results of processing by the iThenticate system of specific examples and special test problems containing equations (PDEs and ODEs), exact solutions, and some formulas are presented. It has been established that this software system when analyzing inhomogeneous texts, is often unable to distinguish self-plagiarism from pseudo-self-plagiarism (false self-plagiarism). A model complex situation is considered, in which the identification of self-plagiarism requires the involvement of highly qualified specialists of a narrow profile. Various ways to improve the work of software systems for comparing inhomogeneous texts are proposed. This article will be useful to researchers and university teachers in mathematics, physics, and engineering sciences, programmers dealing with problems in image recognition and research topics of digital image processing, as well as a wide range of readers who are interested in issues of plagiarism and self-plagiarism.
* 23 pages, 3 figures, 2 photos
Fast Data-Driven Adaptation of Radar Detection via Meta-Learning
Dec 03, 2021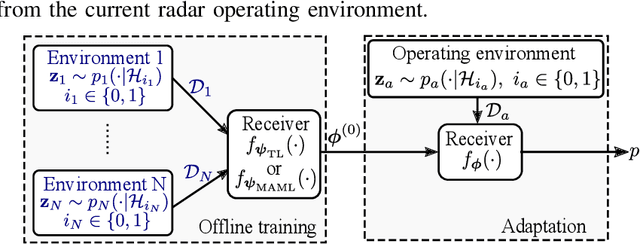
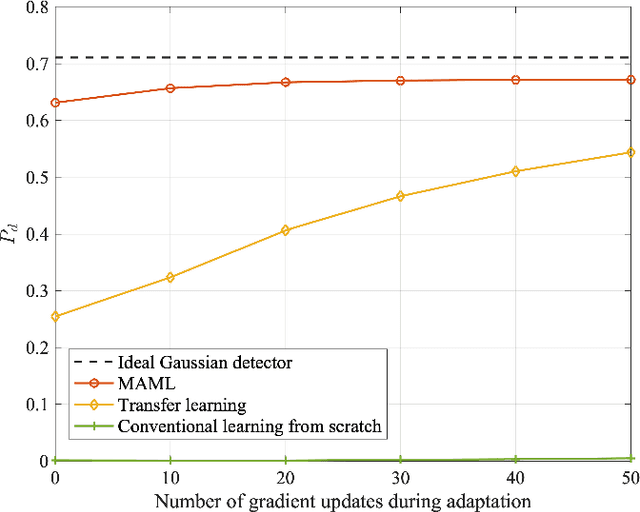
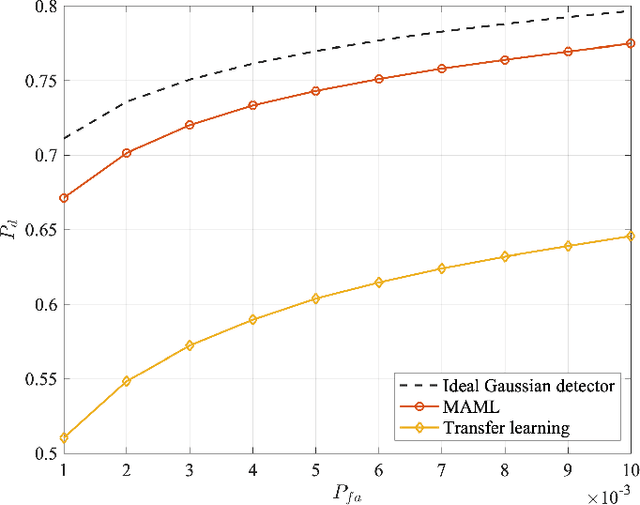
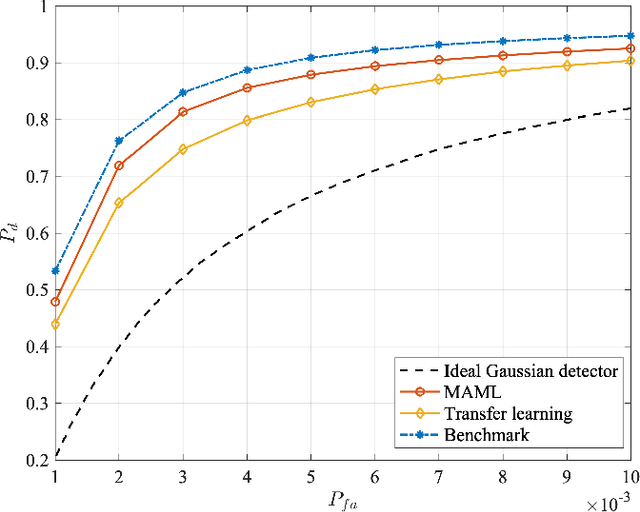
This paper addresses the problem of fast learning of radar detectors with a limited amount of training data. In current data-driven approaches for radar detection, re-training is generally required when the operating environment changes, incurring large overhead in terms of data collection and training time. In contrast, this paper proposes two novel deep learning-based approaches that enable fast adaptation of detectors based on few data samples from a new environment. The proposed methods integrate prior knowledge regarding previously encountered radar operating environments in two different ways. One approach is based on transfer learning: it first pre-trains a detector such that it works well on data collected in previously observed environments, and then it adapts the pre-trained detector to the specific current environment. The other approach targets explicitly few-shot training via meta-learning: based on data from previous environments, it finds a common initialization that enables fast adaptation to a new environment. Numerical results validate the benefits of the proposed two approaches compared with the conventional method based on training with no prior knowledge. Furthermore, the meta-learning-based detector outperforms the transfer learning-based detector when the clutter is Gaussian.
Learning Emergent Random Access Protocol for LEO Satellite Networks
Dec 03, 2021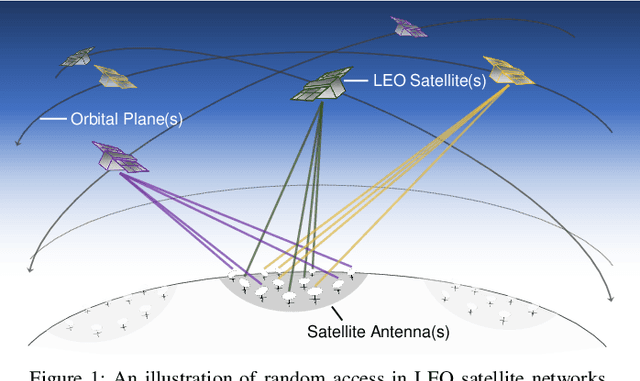
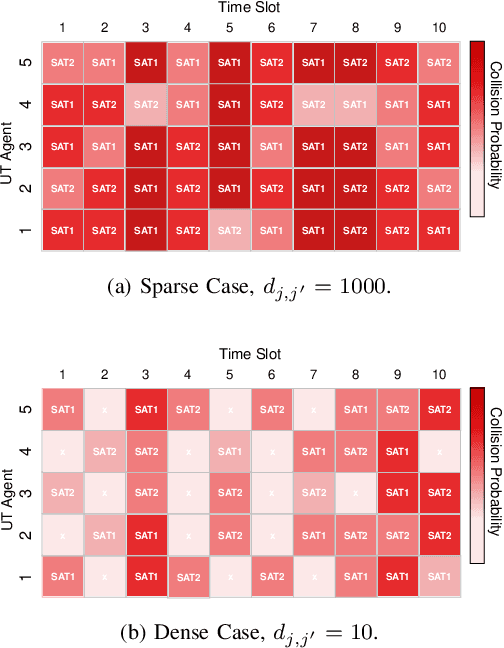
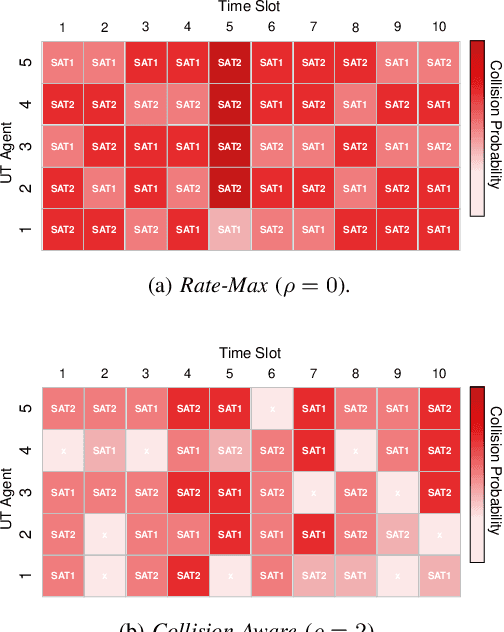
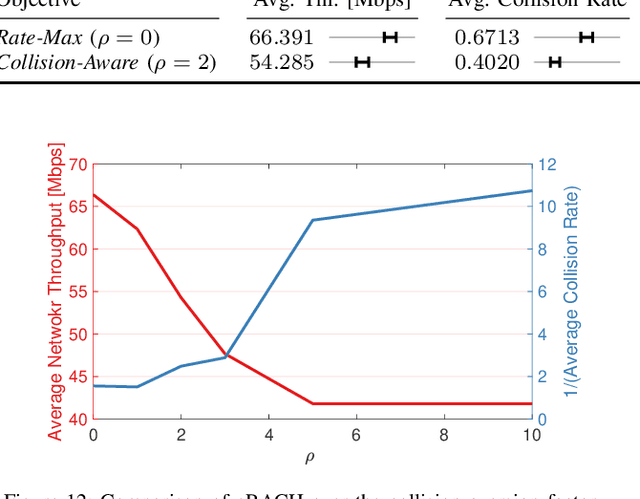
A mega-constellation of low-altitude earth orbit (LEO) satellites (SATs) are envisaged to provide a global coverage SAT network in beyond fifth-generation (5G) cellular systems. LEO SAT networks exhibit extremely long link distances of many users under time-varying SAT network topology. This makes existing multiple access protocols, such as random access channel (RACH) based cellular protocol designed for fixed terrestrial network topology, ill-suited. To overcome this issue, in this paper, we propose a novel grant-free random access solution for LEO SAT networks, dubbed emergent random access channel protocol (eRACH). In stark contrast to existing model-based and standardized protocols, eRACH is a model-free approach that emerges through interaction with the non-stationary network environment, using multi-agent deep reinforcement learning (MADRL). Furthermore, by exploiting known SAT orbiting patterns, eRACH does not require central coordination or additional communication across users, while training convergence is stabilized through the regular orbiting patterns. Compared to RACH, we show from various simulations that our proposed eRACH yields 54.6% higher average network throughput with around two times lower average access delay while achieving 0.989 Jain's fairness index.
Speed Maps: An Application to Guide Robots in Human Environments
Nov 04, 2021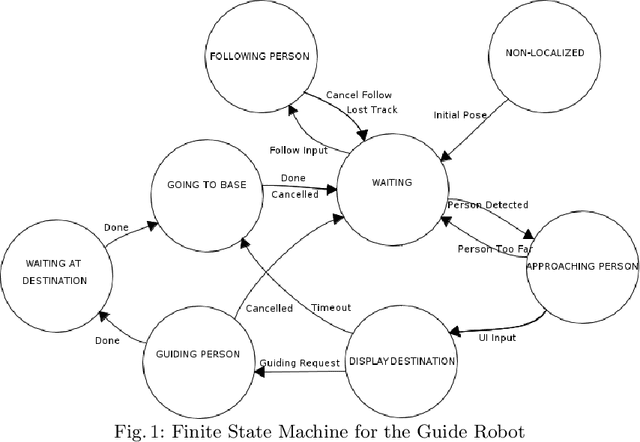
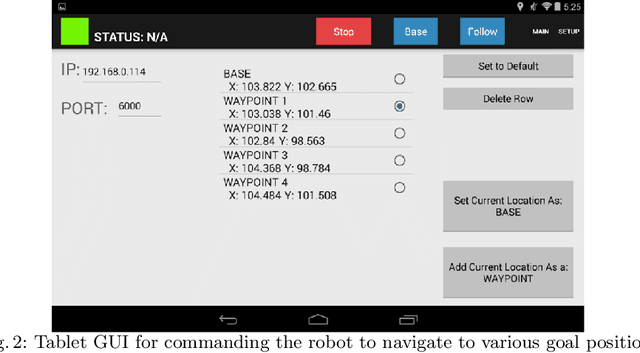


We present the concept of speed maps: speed limits for mobile robots in human environments. Static speed maps allow for faster navigation on corridors while limiting the speed around corners and in rooms. Dynamic speed maps put limits on speed around humans. We demonstrate the concept for a mobile robot that guides people to annotated landmarks on the map. The robot keeps a metric map for navigation and a semantic map to hold planar surfaces for tasking. The system supports automatic initialization upon the detection of a specially designed QR code. We show that speed maps not only can reduce the impact of a potential collision but can also reduce navigation time.
ST2Vec: Spatio-Temporal Trajectory Similarity Learning in Road Networks
Dec 17, 2021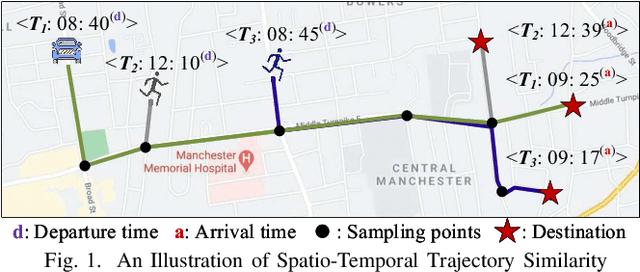

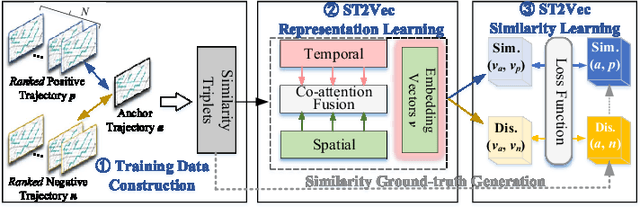
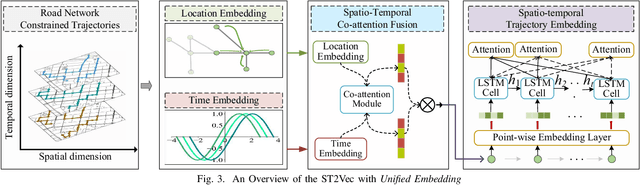
People and vehicle trajectories embody important information of transportation infrastructures, and trajectory similarity computation is functionality in many real-world applications involving trajectory data analysis. Recently, deep-learning based trajectory similarity techniques hold the potential to offer improved efficiency and adaptability over traditional similarity techniques. Nevertheless, the existing trajectory similarity learning proposals emphasize spatial similarity over temporal similarity, making them suboptimal for time-aware analyses. To this end, we propose ST2Vec, a trajectory-representation-learning based architecture that considers fine-grained spatial and temporal correlations between pairs of trajectories for spatio-temporal similarity learning in road networks. To the best of our knowledge, this is the first deep-learning proposal for spatio-temporal trajectory similarity analytics. Specifically, ST2Vec encompasses three phases: (i) training data preparation that selects representative training samples; (ii) spatial and temporal modeling that encode spatial and temporal characteristics of trajectories, where a generic temporal modeling module (TMM) is designed; and (iii) spatio-temporal co-attention fusion (STCF), where a unified fusion (UF) approach is developed to help generating unified spatio-temporal trajectory embeddings that capture the spatio-temporal similarity relations between trajectories. Further, inspired by curriculum concept, ST2Vec employs the curriculum learning for model optimization to improve both convergence and effectiveness. An experimental study offers evidence that ST2Vec outperforms all state-of-the-art competitors substantially in terms of effectiveness, efficiency, and scalability, while showing low parameter sensitivity and good model robustness.