 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-Level AirComp for Wireless Federated Learning under Data Scarcity and Heterogeneity
Jun 06, 2025



The conventional FL methods face critical challenges in realistic wireless edge networks, where training data is both limited and heterogeneous, often leading to unstable training and poor generalization. To address these challenges in a principled manner, we propose a novel wireless FL framework grounded in Bayesian inference. By virtue of the Bayesian approach, our framework captures model uncertainty by maintaining distributions over local weights and performs distribution-level aggregation of local distributions into a global distribution. This mitigates local overfitting and client drift, thereby enabling more reliable inference. Nevertheless, adopting Bayesian FL increases communication overhead due to the need to transmit richer model information and fundamentally alters the aggregation process beyond simple averaging. As a result, conventional Over-the-Air Computation (AirComp), widely used to improve communication efficiency in standard FL, is no longer directly applicable. To overcome this limitation, we design a dedicated AirComp scheme tailored to Bayesian FL, which efficiently aggregates local posterior distributions at the distribution level by exploiting the superposition property of wireless channels. In addition, we derive an optimal transmit power control strategy, grounded in rigorous convergence analysis, to accelerate training under power constraints. Our analysis explicitly accounts for practical wireless impairments such as fading and noise, and provides theoretical guarantees for convergence. Extensive simulations validate the proposed framework, demonstrating significant improvements in test accuracy and calibration performance over conventional FL methods, particularly in data-scarce and heterogeneous environments.
Federated Learning Meets Fluid Antenna: Towards Robust and Scalable Edge Intelligence
Mar 04, 2025



Federated learning (FL) is an emerging machine learning paradigm with immense potential to support advanced services and applications in future industries. However, when deployed over wireless communication systems, FL suffers from significant communication overhead, which can be alleviated by integrating over-the-air computation (AirComp). Despite its advantages, AirComp introduces learning inaccuracies due to the inherent randomness of wireless channels, which can degrade overall learning performance. To address this issue, this paper explores the integration of fluid antenna systems (FAS) into AirComp-based FL to enhance system robustness and efficiency. Fluid antennas offer dynamic spatial diversity by adaptively selecting antenna ports, thereby mitigating channel variations and improving signal aggregation. Specifically, we propose an antenna selection rule for fluid-antenna-equipped devices that optimally enhances learning robustness or training performance. Building on this, we develop a learning algorithm and provide a theoretical convergence analysis. The simulation results validate the effectiveness of fluid antennas in improving FL performance, demonstrating their potential as a key enabler for wireless AI applications.
Privacy-Enhanced Over-the-Air Federated Learning via Client-Driven Power Balancing
Oct 08, 2024



This paper introduces a novel privacy-enhanced over-the-air Federated Learning (OTA-FL) framework using client-driven power balancing (CDPB) to address privacy concerns in OTA-FL systems. In recent studies, a server determines the power balancing based on the continuous transmission of channel state information (CSI) from each client. Furthermore, they concentrate on fulfilling privacy requirements in every global iteration, which can heighten the risk of privacy exposure as the learning process extends. To mitigate these risks, we propose two CDPB strategies -- CDPB-n (noisy) and CDPB-i (idle) -- allowing clients to adjust transmission power independently, without sharing CSI. CDPB-n transmits noise during poor conditions, while CDPB-i pauses transmission until conditions improve. To further enhance privacy and learning efficiency, we show a mixed strategy, CDPB-mixed, which combines CDPB-n and CDPB-i. Our experimental results show that CDPB outperforms traditional approaches in terms of model accuracy and privacy guarantees, providing a practical solution for enhancing OTA-FL in resource-constrained environments.
Semantic Communication and Control Co-Design for Multi-Objective Correlated Dynamics
Oct 03, 2024



This letter introduces a machine-learning approach to learning the semantic dynamics of correlated systems with different control rules and dynamics. By leveraging the Koopman operator in an autoencoder (AE) framework, the system's state evolution is linearized in the latent space using a dynamic semantic Koopman (DSK) model, capturing the baseline semantic dynamics. Signal temporal logic (STL) is incorporated through a logical semantic Koopman (LSK) model to encode system-specific control rules. These models form the proposed logical Koopman AE framework that reduces communication costs while improving state prediction accuracy and control performance, showing a 91.65% reduction in communication samples and significant performance gains in simulation.
Terahertz Communication Multi-UAV-Assisted Mobile Edge Computing System
Jul 01, 2024



Mobile edge computing (MEC) and terahertz (THz)enabled unmanned aerial vehicle (UAV) communication systems are gaining significant attention for improving user service delays in future mobile networks. This article introduces a novel multi-UAV-aided MEC system operating at THz frequencies to minimize expected user service delays, including communication and computation latency. We address this challenge by jointly optimizing UAV relay selection, power control, positioning, and user-resource association for task offloading and resource allocation. To tackle the problem's complexities, we decompose it into four subproblems, each solved optimally with our proposed algorithm. An iterative penalty dual decomposition (PDD) algorithm approximates the original problem's solution. Numerical results demonstrate that our PDD-based approach outperforms baseline algorithms in terms of expected user service delay.
Universal Joint Source-Channel Coding for Modulation-Agnostic Semantic Communication
May 17, 2024



From the perspective of joint source-channel coding (JSCC), there has been significant research on utilizing semantic communication, which inherently possesses analog characteristics, within digital device environments. However, a single-model approach that operates modulation-agnostically across various digital modulation orders has not yet been established. This article presents the first attempt at such an approach by proposing a universal joint source-channel coding (uJSCC) system that utilizes a single-model encoder-decoder pair and trained vector quantization (VQ) codebooks. To support various modulation orders within a single model, the operation of every neural network (NN)-based module in the uJSCC system requires the selection of modulation orders according to signal-to-noise ratio (SNR) boundaries. To address the challenge of unequal output statistics from shared parameters across NN layers, we integrate multiple batch normalization (BN) layers, selected based on modulation order, after each NN layer. This integration occurs with minimal impact on the overall model size. Through a comprehensive series of experiments, we validate that this modulation-agnostic semantic communication framework demonstrates superiority over existing digital semantic communication approaches in terms of model complexity, communication efficiency, and task effectiveness.
Pilot Signal and Channel Estimator Co-Design for Hybrid-Field XL-MIMO
Mar 28, 2024



This paper addresses the intricate task of hybrid-field channel estimation in extremely large-scale MIMO (XL-MIMO) systems, critical for the progression of 6G communications. Within these systems, comprising a line-of-sight (LoS) channel component alongside far-field and near-field scattering channel components, our objective is to tackle the channel estimation challenge. We encounter two central hurdles for ensuring dependable sparse channel recovery: the design of pilot signals and channel estimators tailored for hybrid-field communications. To overcome the first challenge, we propose a method to derive optimal pilot signals, aimed at minimizing the mutual coherence of the sensing matrix within the context of compressive sensing (CS) problems. These optimal signals are derived using the alternating direction method of multipliers (ADMM), ensuring robust performance in sparse channel recovery. Additionally, leveraging the acquired optimal pilot signal, we introduce a two-stage channel estimation approach that sequentially estimates the LoS channel component and the hybrid-field scattering channel components. Simulation results attest to the superiority of our co-designed approach for pilot signal and channel estimation over conventional CS-based methods, providing more reliable sparse channel recovery in practical scenarios.
Bayesian Inverse Contextual Reasoning for Heterogeneous Semantics-Native Communication
Jun 10, 2023



This work deals with the heterogeneous semantic-native communication (SNC) problem. When agents do not share the same communication context, the effectiveness of contextual reasoning (CR) is compromised calling for agents to infer other agents' context. This article proposes a novel framework for solving the inverse problem of CR in SNC using two Bayesian inference methods, namely: Bayesian inverse CR (iCR) and Bayesian inverse linearized CR (iLCR). The first proposed Bayesian iCR method utilizes Markov Chain Monte Carlo (MCMC) sampling to infer the agent's context while being computationally expensive. To address this issue, a Bayesian iLCR method is leveraged which obtains a linearized CR (LCR) model by training a linear neural network. Experimental results show that the Bayesian iLCR method requires less computation and achieves higher inference accuracy compared to Bayesian iCR. Additionally, heterogeneous SNC based on the context obtained through the Bayesian iLCR method shows better communication effectiveness than that of Bayesian iCR. Overall, this work provides valuable insights and methods to improve the effectiveness of SNC in situations where agents have different contexts.
Attention Based Communication and Control for Multi-UAV Path Planning
Dec 20, 2021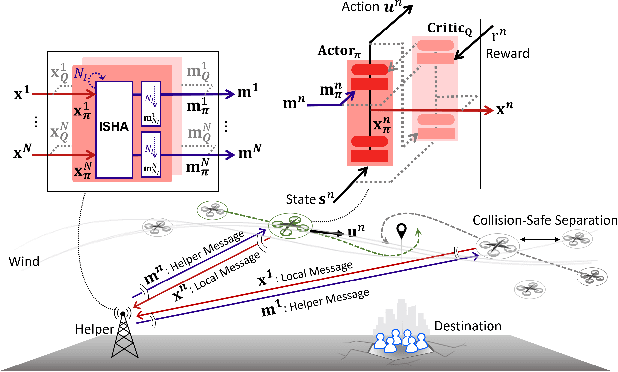
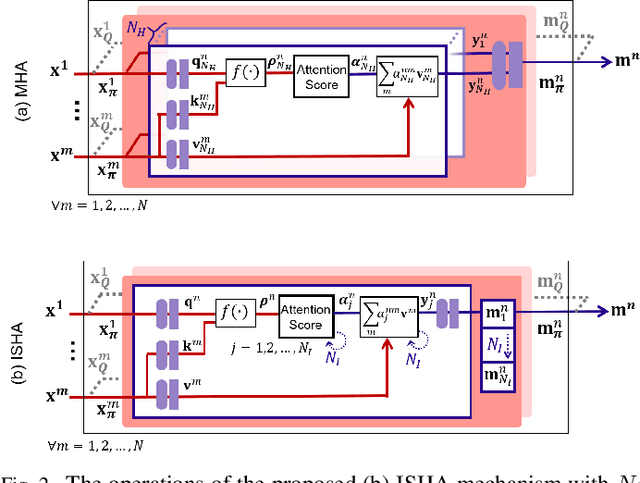
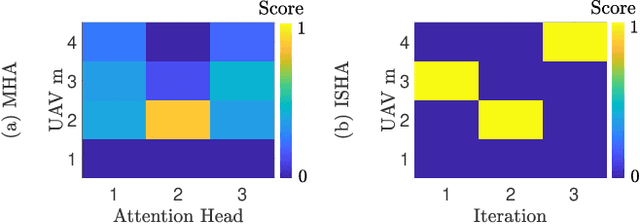
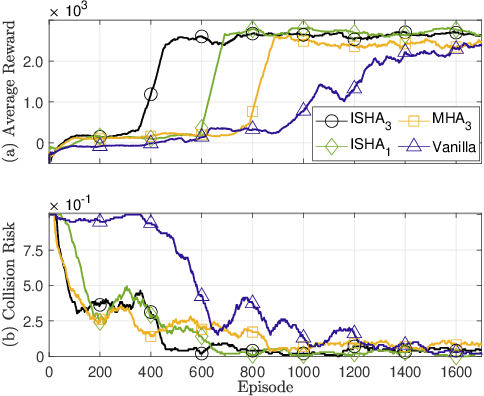
Inspired by the multi-head attention (MHA) mechanism in natural language processing, this letter proposes an iterative single-head attention (ISHA) mechanism for multi-UAV path planning. The ISHA mechanism is run by a communication helper collecting the state embeddings of UAVs and distributing an attention score vector to each UAV. The attention scores computed by ISHA identify how many interactions with other UAVs should be considered in each UAV's control decision-making. Simulation results corroborate that the ISHA-based communication and control framework achieves faster travel with lower inter-UAV collision risks than an MHA-aided baseline, particularly under limited communication resources.
Learning Emergent Random Access Protocol for LEO Satellite Networks
Dec 03, 2021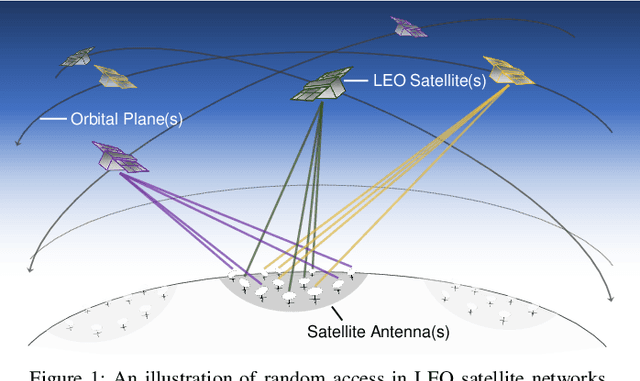
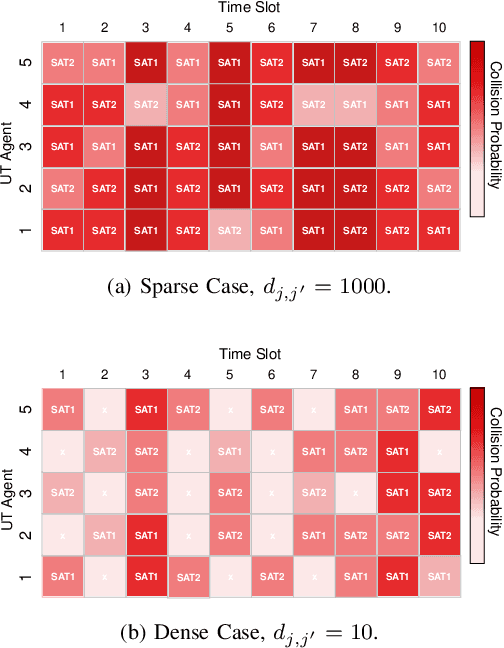
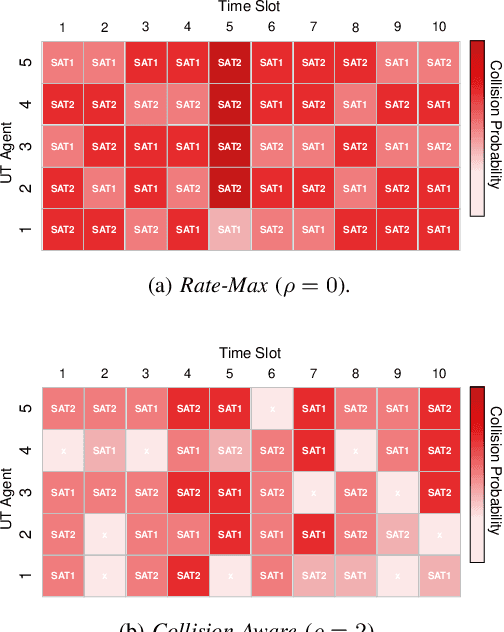
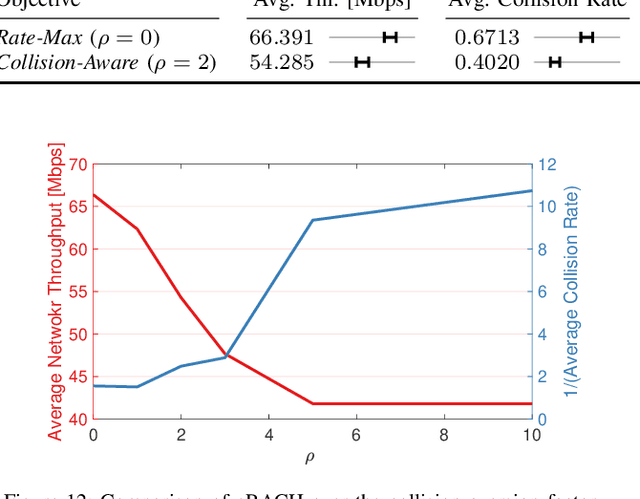
A mega-constellation of low-altitude earth orbit (LEO) satellites (SATs) are envisaged to provide a global coverage SAT network in beyond fifth-generation (5G) cellular systems. LEO SAT networks exhibit extremely long link distances of many users under time-varying SAT network topology. This makes existing multiple access protocols, such as random access channel (RACH) based cellular protocol designed for fixed terrestrial network topology, ill-suited. To overcome this issue, in this paper, we propose a novel grant-free random access solution for LEO SAT networks, dubbed emergent random access channel protocol (eRACH). In stark contrast to existing model-based and standardized protocols, eRACH is a model-free approach that emerges through interaction with the non-stationary network environment, using multi-agent deep reinforcement learning (MADRL). Furthermore, by exploiting known SAT orbiting patterns, eRACH does not require central coordination or additional communication across users, while training convergence is stabilized through the regular orbiting patterns. Compared to RACH, we show from various simulations that our proposed eRACH yields 54.6% higher average network throughput with around two times lower average access delay while achieving 0.989 Jain's fairness index.