 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Resource-aware Distributed Gaussian Process Regression for Real-time Machine Learning
May 13, 2021
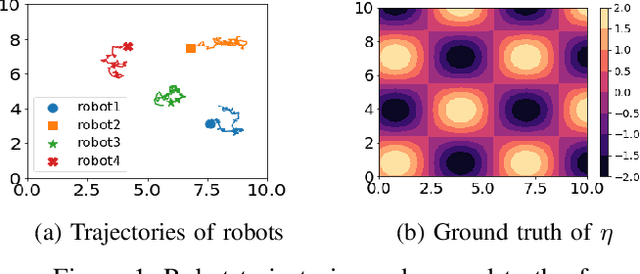
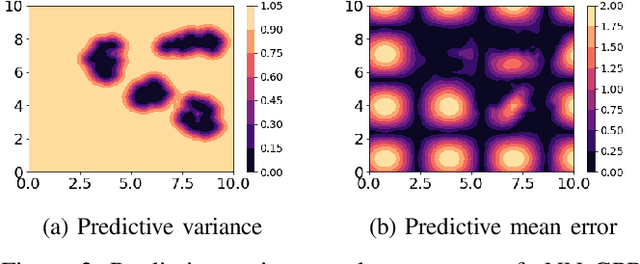
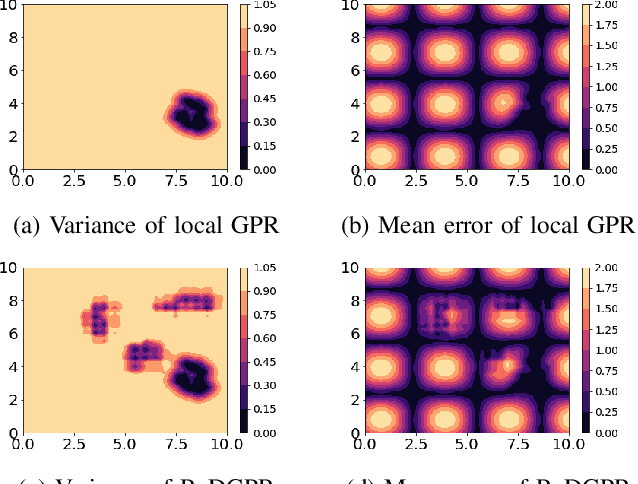
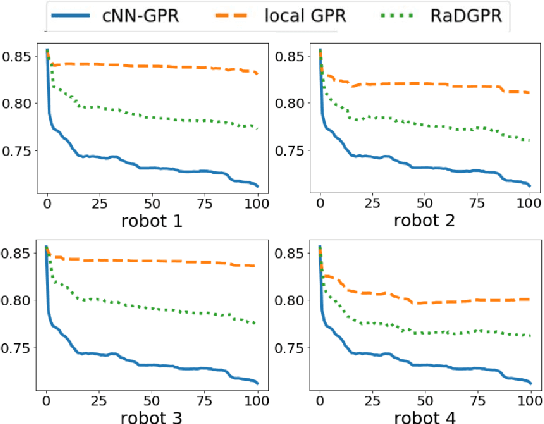
We study the problem where a group of agents aim to collaboratively learn a common latent function through streaming data. We propose a Resource-aware Gaussian process regression algorithm that is cognizant of agents' limited capabilities in communication, computation and memory. We quantify the improvement that limited inter-agent communication brings to the transient and steady-state performance in predictive variance and predictive mean. A set of simulations is conducted to evaluate the developed algorithm.
Fast and Furious: Real Time End-to-End 3D Detection, Tracking and Motion Forecasting with a Single Convolutional Net
Dec 22, 2020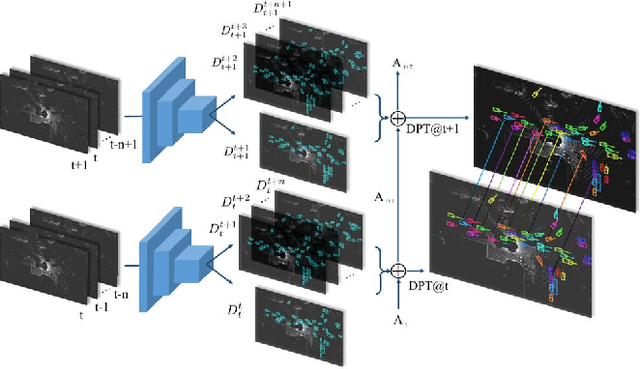
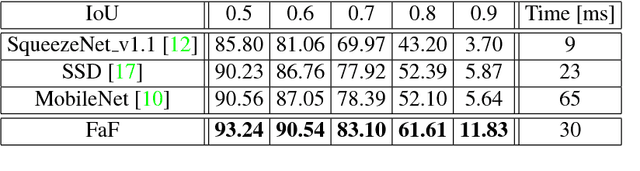


In this paper we propose a novel deep neural network that is able to jointly reason about 3D detection, tracking and motion forecasting given data captured by a 3D sensor. By jointly reasoning about these tasks, our holistic approach is more robust to occlusion as well as sparse data at range. Our approach performs 3D convolutions across space and time over a bird's eye view representation of the 3D world, which is very efficient in terms of both memory and computation. Our experiments on a new very large scale dataset captured in several north american cities, show that we can outperform the state-of-the-art by a large margin. Importantly, by sharing computation we can perform all tasks in as little as 30 ms.
Efficient and Local Parallel Random Walks
Dec 01, 2021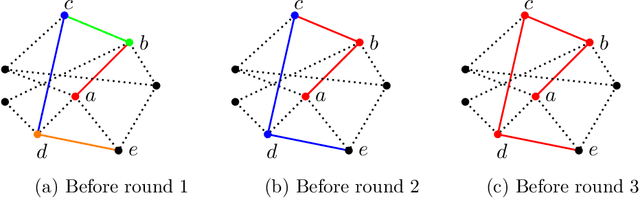
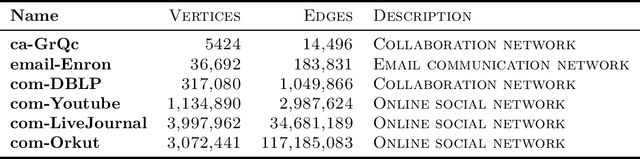
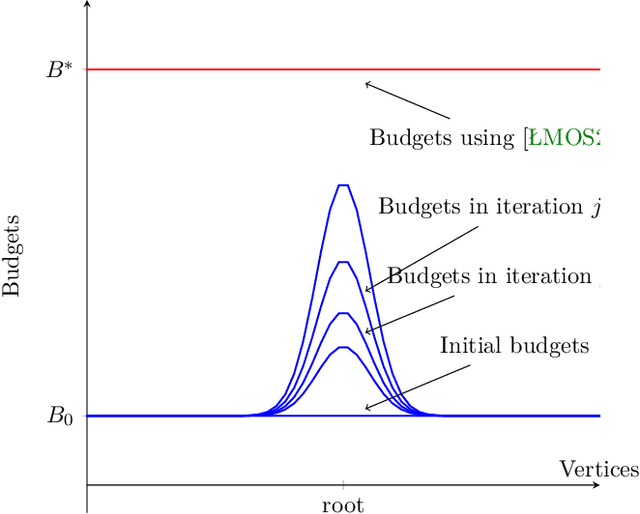

Random walks are a fundamental primitive used in many machine learning algorithms with several applications in clustering and semi-supervised learning. Despite their relevance, the first efficient parallel algorithm to compute random walks has been introduced very recently (Lacki et al.). Unfortunately their method has a fundamental shortcoming: their algorithm is non-local in that it heavily relies on computing random walks out of all nodes in the input graph, even though in many practical applications one is interested in computing random walks only from a small subset of nodes in the graph. In this paper, we present a new algorithm that overcomes this limitation by building random walk efficiently and locally at the same time. We show that our technique is both memory and round efficient, and in particular yields an efficient parallel local clustering algorithm. Finally, we complement our theoretical analysis with experimental results showing that our algorithm is significantly more scalable than previous approaches.
Delivery Issues Identification from Customer Feedback Data
Dec 26, 2021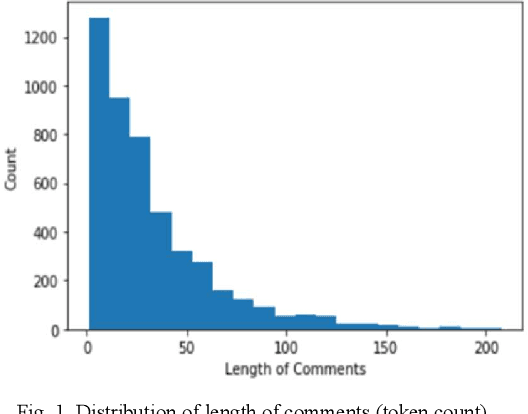

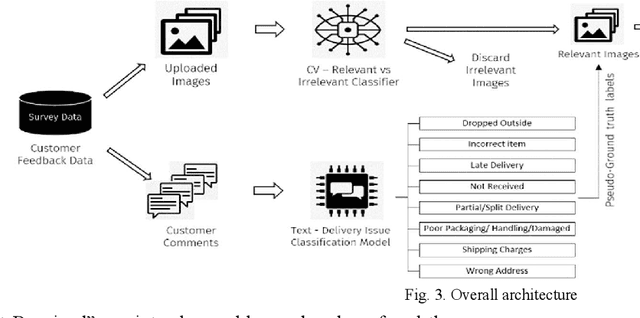

Millions of packages are delivered successfully by online and local retail stores across the world every day. The proper delivery of packages is needed to ensure high customer satisfaction and repeat purchases. These deliveries suffer various problems despite the best efforts from the stores. These issues happen not only due to the large volume and high demand for low turnaround time but also due to mechanical operations and natural factors. These issues range from receiving wrong items in the package to delayed shipment to damaged packages because of mishandling during transportation. Finding solutions to various delivery issues faced by both sending and receiving parties plays a vital role in increasing the efficiency of the entire process. This paper shows how to find these issues using customer feedback from the text comments and uploaded images. We used transfer learning for both Text and Image models to minimize the demand for thousands of labeled examples. The results show that the model can find different issues. Furthermore, it can also be used for tasks like bottleneck identification, process improvement, automating refunds, etc. Compared with the existing process, the ensemble of text and image models proposed in this paper ensures the identification of several types of delivery issues, which is more suitable for the real-life scenarios of delivery of items in retail businesses. This method can supply a new idea of issue detection for the delivery of packages in similar industries.
DeepEdgeBench: Benchmarking Deep Neural Networks on Edge Devices
Aug 21, 2021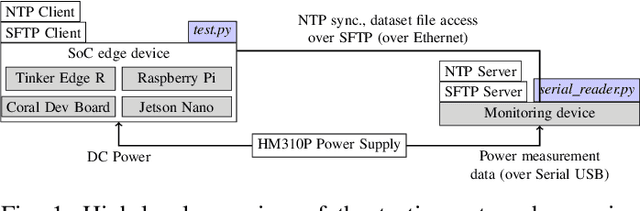
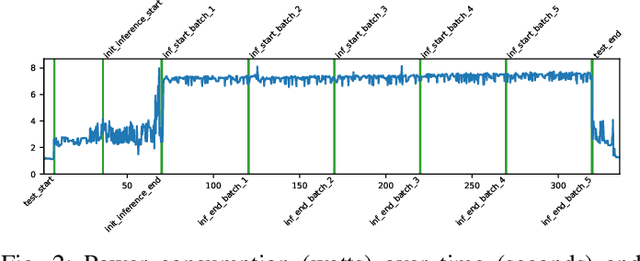

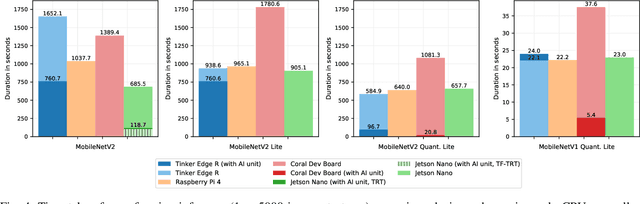
EdgeAI (Edge computing based Artificial Intelligence) has been most actively researched for the last few years to handle variety of massively distributed AI applications to meet up the strict latency requirements. Meanwhile, many companies have released edge devices with smaller form factors (low power consumption and limited resources) like the popular Raspberry Pi and Nvidia's Jetson Nano for acting as compute nodes at the edge computing environments. Although the edge devices are limited in terms of computing power and hardware resources, they are powered by accelerators to enhance their performance behavior. Therefore, it is interesting to see how AI-based Deep Neural Networks perform on such devices with limited resources. In this work, we present and compare the performance in terms of inference time and power consumption of the four Systems on a Chip (SoCs): Asus Tinker Edge R, Raspberry Pi 4, Google Coral Dev Board, Nvidia Jetson Nano, and one microcontroller: Arduino Nano 33 BLE, on different deep learning models and frameworks. We also provide a method for measuring power consumption, inference time and accuracy for the devices, which can be easily extended to other devices. Our results showcase that, for Tensorflow based quantized model, the Google Coral Dev Board delivers the best performance, both for inference time and power consumption. For a low fraction of inference computation time, i.e. less than 29.3% of the time for MobileNetV2, the Jetson Nano performs faster than the other devices.
A Comprehensive Comparison of Word Embeddings in Event & Entity Coreference Resolution
Oct 11, 2021
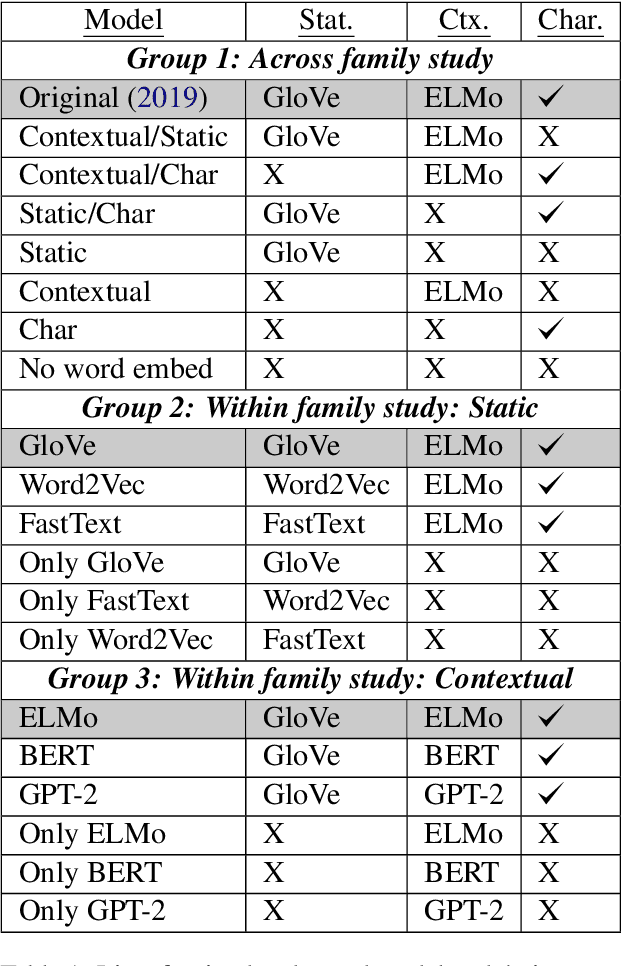
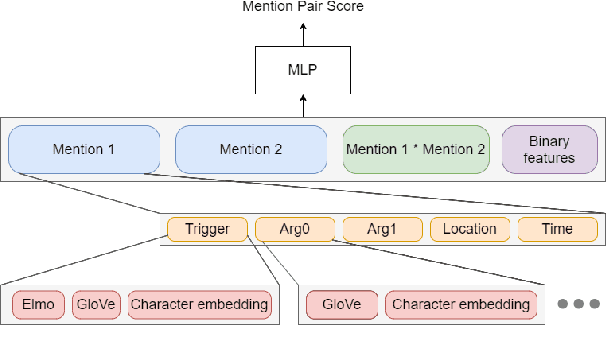
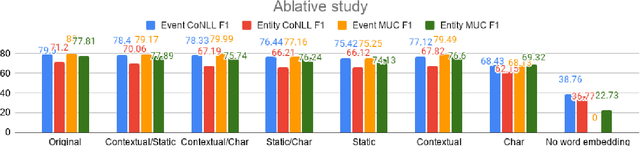
Coreference Resolution is an important NLP task and most state-of-the-art methods rely on word embeddings for word representation. However, one issue that has been largely overlooked in literature is that of comparing the performance of different embeddings across and within families in this task. Therefore, we frame our study in the context of Event and Entity Coreference Resolution (EvCR & EnCR), and address two questions : 1) Is there a trade-off between performance (predictive & run-time) and embedding size? 2) How do the embeddings' performance compare within and across families? Our experiments reveal several interesting findings. First, we observe diminishing returns in performance with respect to embedding size. E.g. a model using solely a character embedding achieves 86% of the performance of the largest model (Elmo, GloVe, Character) while being 1.2% of its size. Second, the larger model using multiple embeddings learns faster overall despite being slower per epoch. However, it is still slower at test time. Finally, Elmo performs best on both EvCR and EnCR, while GloVe and FastText perform best in EvCR and EnCR respectively.
Deep MAGSAC++
Nov 28, 2021
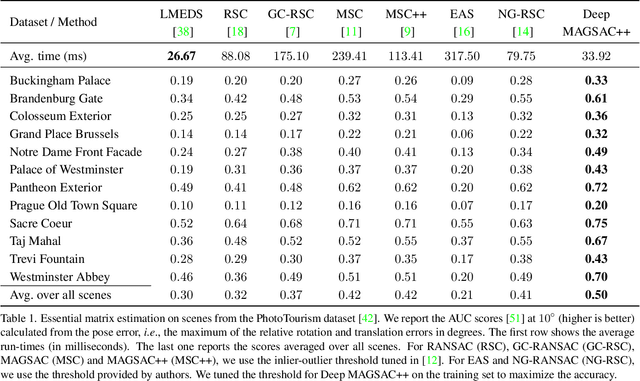
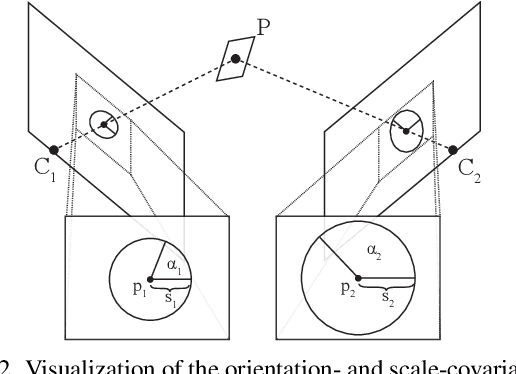
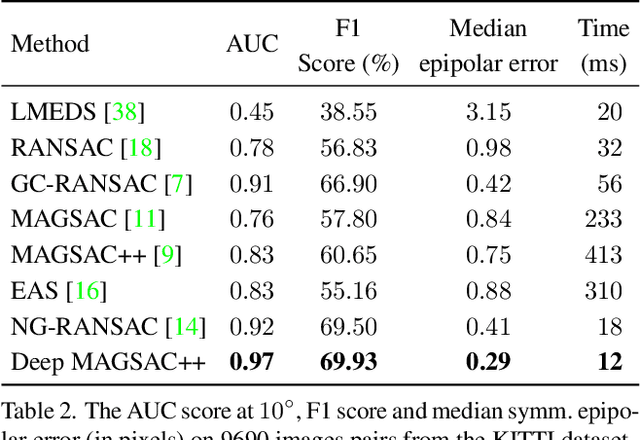
We propose Deep MAGSAC++ combining the advantages of traditional and deep robust estimators. We introduce a novel loss function that exploits the orientation and scale from partially affine covariant features, e.g., SIFT, in a geometrically justifiable manner. The new loss helps in learning higher-order information about the underlying scene geometry. Moreover, we propose a new sampler for RANSAC that always selects the sample with the highest probability of consisting only of inliers. After every unsuccessful iteration, the probabilities are updated in a principled way via a Bayesian approach. The prediction of the deep network is exploited as prior inside the sampler. Benefiting from the new loss, the proposed sampler, and a number of technical advancements, Deep MAGSAC++ is superior to the state-of-the-art both in terms of accuracy and run-time on thousands of image pairs from publicly available datasets for essential and fundamental matrix estimation.
A Primal Approach to Constrained Policy Optimization: Global Optimality and Finite-Time Analysis
Nov 17, 2020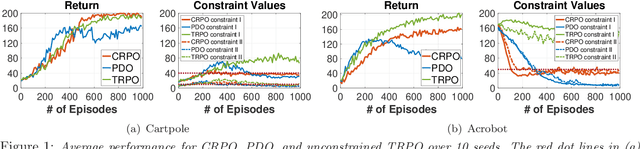
Safe reinforcement learning (SRL) problems are typically modeled as constrained Markov Decision Process (CMDP), in which an agent explores the environment to maximize the expected total reward and meanwhile avoids violating certain constraints on a number of expected total costs. In general, such SRL problems have nonconvex objective functions subject to multiple nonconvex constraints, and hence are very challenging to solve, particularly to provide a globally optimal policy. Many popular SRL algorithms adopt a primal-dual structure which utilizes the updating of dual variables for satisfying the constraints. In contrast, we propose a primal approach, called constraint-rectified policy optimization (CRPO), which updates the policy alternatingly between objective improvement and constraint satisfaction. CRPO provides a primal-type algorithmic framework to solve SRL problems, where each policy update can take any variant of policy optimization step. To demonstrate the theoretical performance of CRPO, we adopt natural policy gradient (NPG) for each policy update step and show that CRPO achieves an $\mathcal{O}(1/\sqrt{T})$ convergence rate to the global optimal policy in the constrained policy set and an $\mathcal{O}(1/\sqrt{T})$ error bound on constraint satisfaction. This is the first finite-time analysis of SRL algorithms with global optimality guarantee. Our empirical results demonstrate that CRPO can outperform the existing primal-dual baseline algorithms significantly.
Source Mixing and Separation Robust Audio Steganography
Oct 11, 2021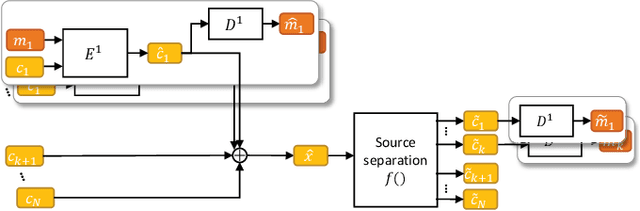

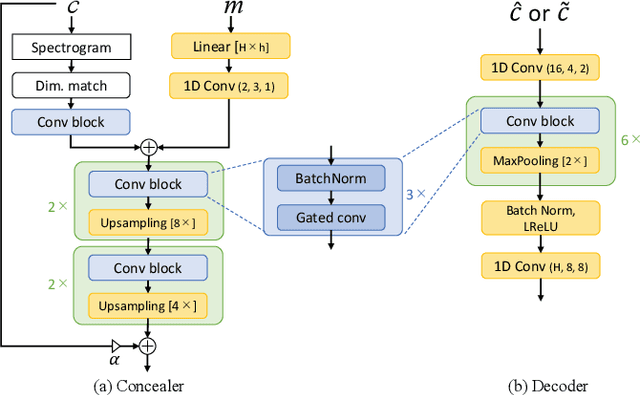
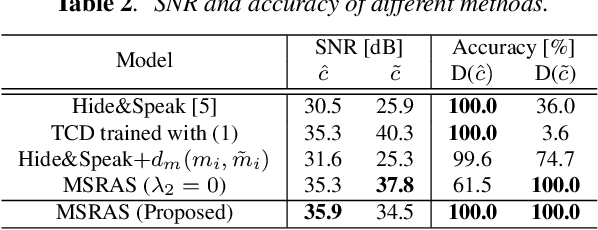
Audio steganography aims at concealing secret information in carrier audio with imperceptible modification on the carrier. Although previous works addressed the robustness of concealed message recovery against distortions introduced during transmission, they do not address the robustness against aggressive editing such as mixing of other audio sources and source separation. In this work, we propose for the first time a steganography method that can embed information into individual sound sources in a mixture such as instrumental tracks in music. To this end, we propose a time-domain model and curriculum learning essential to learn to decode the concealed message from the separated sources. Experimental results show that the proposed method successfully conceals the information in an imperceptible perturbation and that the information can be correctly recovered even after mixing of other sources and separation by a source separation algorithm. Furthermore, we show that the proposed method can be applied to multiple sources simultaneously without interfering with the decoder for other sources even after the sources are mixed and separated.
Dynamic Compressed Sensing of Unsteady Flows with a Mobile Robot
Oct 16, 2021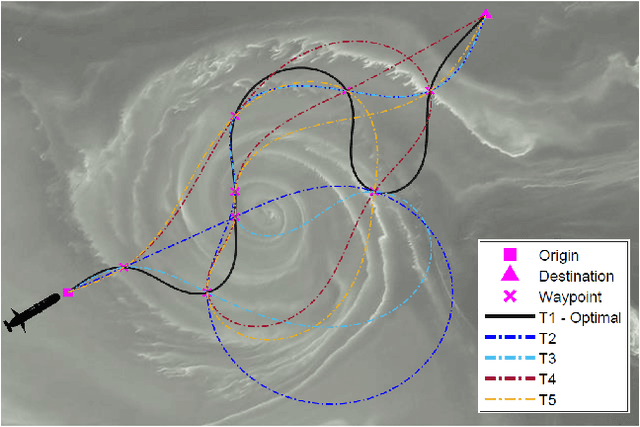
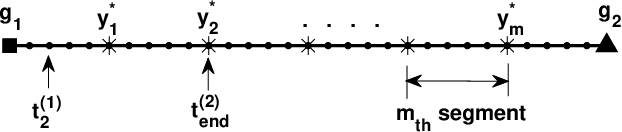
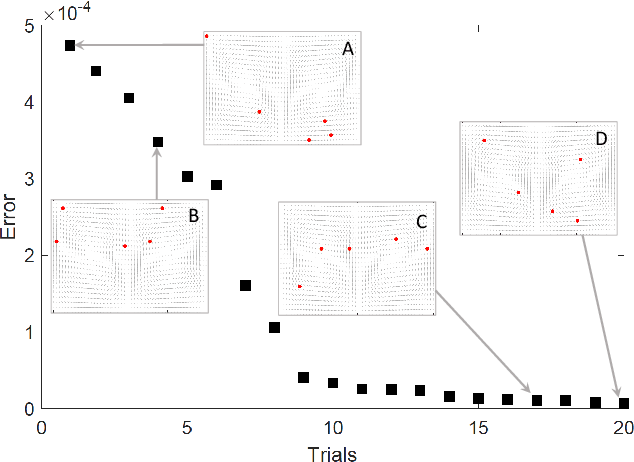
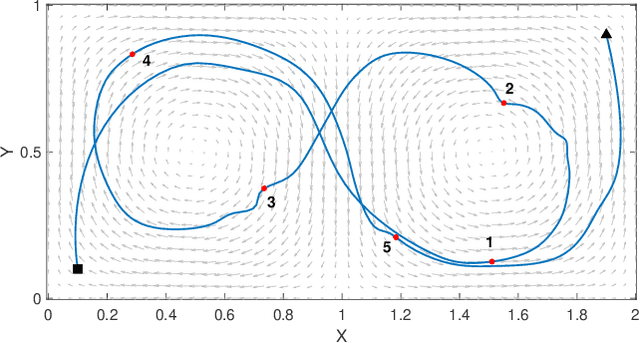
Large-scale environmental sensing with a finite number of mobile sensor is a challenging task that requires a lot of resources and time. This is especially true when features in the environment are spatiotemporally changing with unknown or partially known dynamics. However, these dynamic features often evolve in a low-dimensional space, making it possible to capture their dynamics sufficiently well with only one or several properly planned mobile sensors. This paper investigates the problem of dynamic compressed sensing (DCS) of an unsteady flow field, which takes advantage of the inherently low dimensionality of the underlying flow dynamics to reduce number of waypoints for a mobile sensing robot. The optimal sensing waypoints are identified by an iterative compressed sensing algorithm that optimizes the flow reconstruction based on the proper orthogonal decomposition (POD) modes. An optimized robot trajectory is then found to traverse these waypoints while minimizing the energy consumption, time, and flow reconstruction error. Simulation results in an unsteady double-gyre flow field is presented to demonstrate the efficacy of the proposed algorithms. Experimental results with an indoor quadcopter are presented to show the feasibility of the resulting trajectory.