 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuropsychology of AI: Relationship Between Activation Proximity and Categorical Proximity Within Neural Categories of Synthetic Cognition
Oct 08, 2024



Neuropsychology of artificial intelligence focuses on synthetic neural cog nition as a new type of study object within cognitive psychology. With the goal of making artificial neural networks of language models more explainable, this approach involves transposing concepts from cognitive psychology to the interpretive construction of artificial neural cognition. The human cognitive concept involved here is categorization, serving as a heuristic for thinking about the process of segmentation and construction of reality carried out by the neural vectors of synthetic cognition.
Using meaning instead of words to track topics
Jan 02, 2023The ability to monitor the evolution of topics over time is extremely valuable for businesses. Currently, all existing topic tracking methods use lexical information by matching word usage. However, no studies has ever experimented with the use of semantic information for tracking topics. Hence, we explore a novel semantic-based method using word embeddings. Our results show that a semantic-based approach to topic tracking is on par with the lexical approach but makes different mistakes. This suggest that both methods may complement each other.
HTMOT : Hierarchical Topic Modelling Over Time
Nov 22, 2021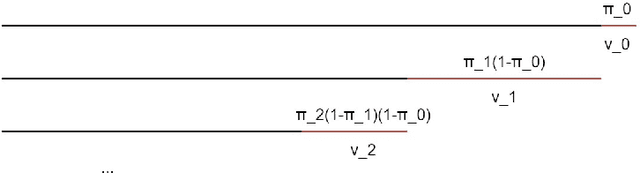
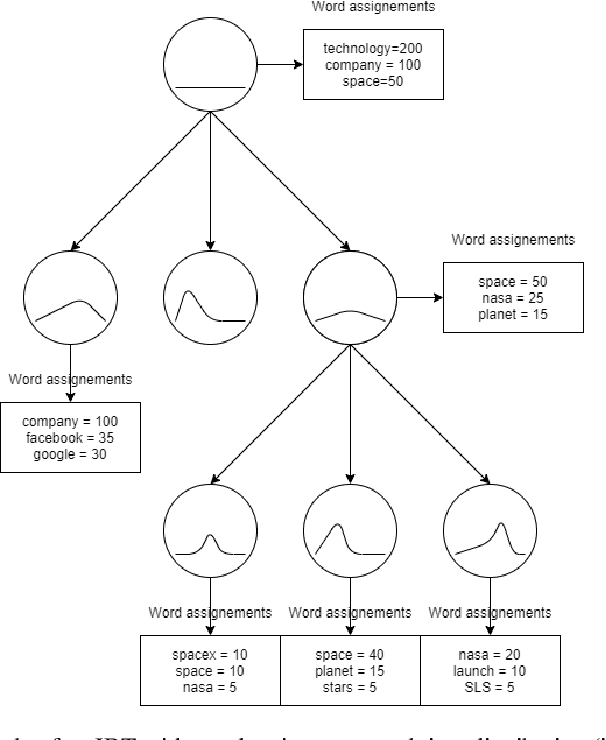
Over the years, topic models have provided an efficient way of extracting insights from text. However, while many models have been proposed, none are able to model topic temporality and hierarchy jointly. Modelling time provide more precise topics by separating lexically close but temporally distinct topics while modelling hierarchy provides a more detailed view of the content of a document corpus. In this study, we therefore propose a novel method, HTMOT, to perform Hierarchical Topic Modelling Over Time. We train HTMOT using a new implementation of Gibbs sampling, which is more efficient. Specifically, we show that only applying time modelling to deep sub-topics provides a way to extract specific stories or events while high level topics extract larger themes in the corpus. Our results show that our training procedure is fast and can extract accurate high-level topics and temporally precise sub-topics. We measured our model's performance using the Word Intrusion task and outlined some limitations of this evaluation method, especially for hierarchical models. As a case study, we focused on the various developments in the space industry in 2020.
A Comprehensive Comparison of Word Embeddings in Event & Entity Coreference Resolution
Oct 11, 2021
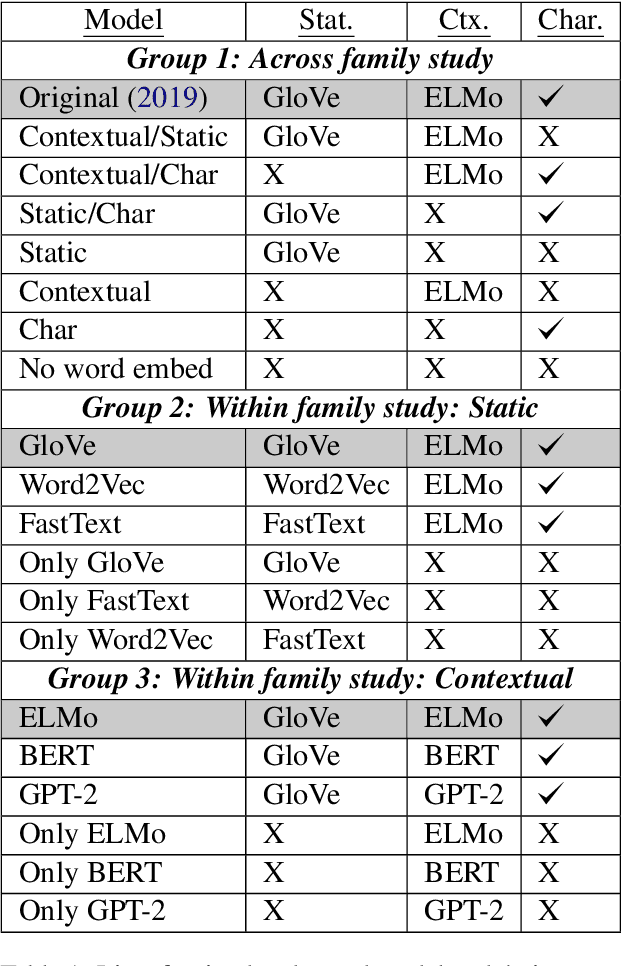
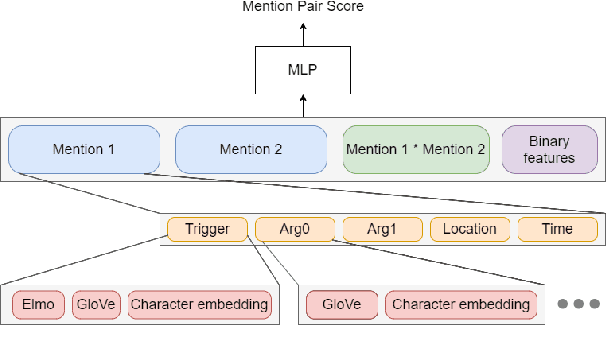
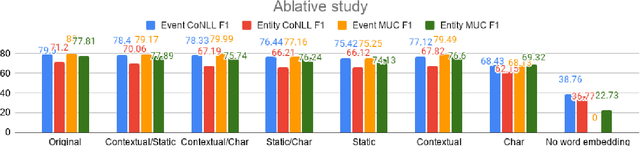
Coreference Resolution is an important NLP task and most state-of-the-art methods rely on word embeddings for word representation. However, one issue that has been largely overlooked in literature is that of comparing the performance of different embeddings across and within families in this task. Therefore, we frame our study in the context of Event and Entity Coreference Resolution (EvCR & EnCR), and address two questions : 1) Is there a trade-off between performance (predictive & run-time) and embedding size? 2) How do the embeddings' performance compare within and across families? Our experiments reveal several interesting findings. First, we observe diminishing returns in performance with respect to embedding size. E.g. a model using solely a character embedding achieves 86% of the performance of the largest model (Elmo, GloVe, Character) while being 1.2% of its size. Second, the larger model using multiple embeddings learns faster overall despite being slower per epoch. However, it is still slower at test time. Finally, Elmo performs best on both EvCR and EnCR, while GloVe and FastText perform best in EvCR and EnCR respectively.