 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A integrating critic-waspas group decision making method under interval-valued q-rung orthogonal fuzzy enviroment
Jan 04, 2022
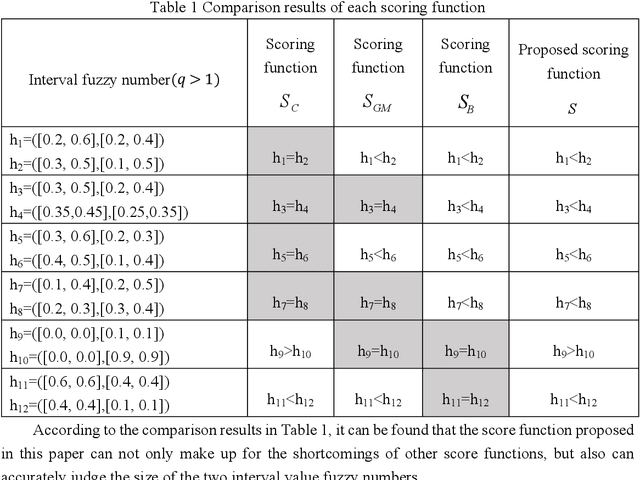
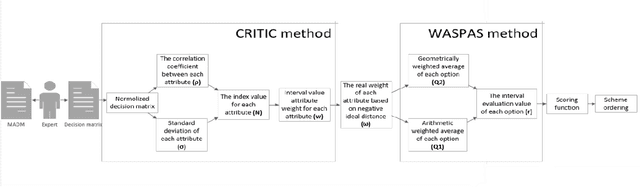
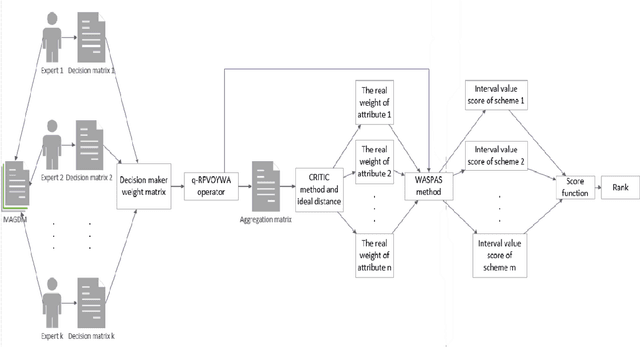
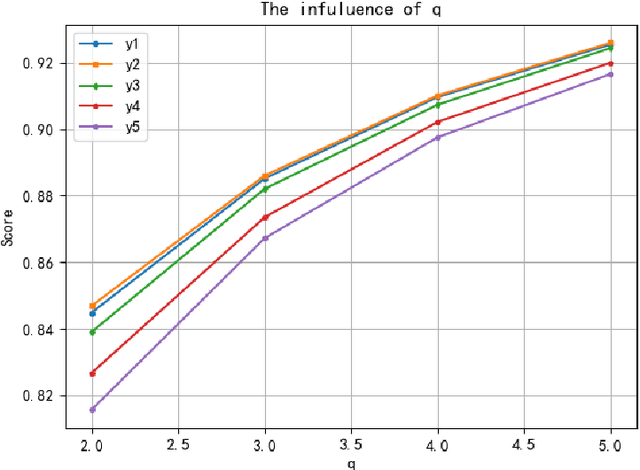
This paper provides a new tool for multi-attribute multi-objective group decision-making with unknown weights and attributes' weights. An interval-valued generalized orthogonal fuzzy group decision-making method is proposed based on the Yager operator and CRITIC-WASPAS method with unknown weights. The method integrates Yager operator, CRITIC, WASPAS, and interval value generalized orthogonal fuzzy group. Its merits lie in allowing decision-makers greater freedom, avoiding bias due to decision-makers' weight, and yielding accurate evaluation. The research includes: expanding the interval value generalized distance measurement method for comparison and application of similarity measurement and decision-making methods; developing a new scoring function for comparing the size of interval value generalized orthogonal fuzzy numbers,and further existing researches. The proposed interval-valued Yager weighted average operator (IVq-ROFYWA) and Yager weighted geometric average operator (IVq-ROFYWG) are used for information aggregation. The CRITIC-WASPAS combines the advantages of CRITIC and WASPAS, which not only work in the single decision but also serve as the basis of the group decision. The in-depth study of the decision-maker's weight matrix overcomes the shortcomings of taking the decision as a whole, and weighs the decision-maker's information aggregation. Finally, the group decision algorithm is used for hypertension risk management. The results are consistent with decision-makers' opinions. Practice and case analysis have proved the effectiveness of the method proposed in this paper. At the same time, it is compared with other operators and decision-making methods, which proves the method effective and feasible.
Global Convergence Using Policy Gradient Methods for Model-free Markovian Jump Linear Quadratic Control
Nov 30, 2021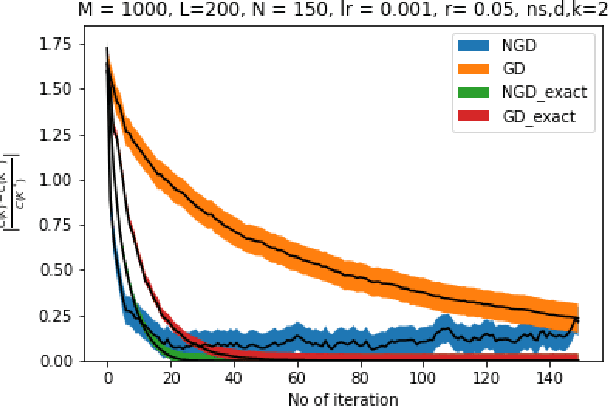
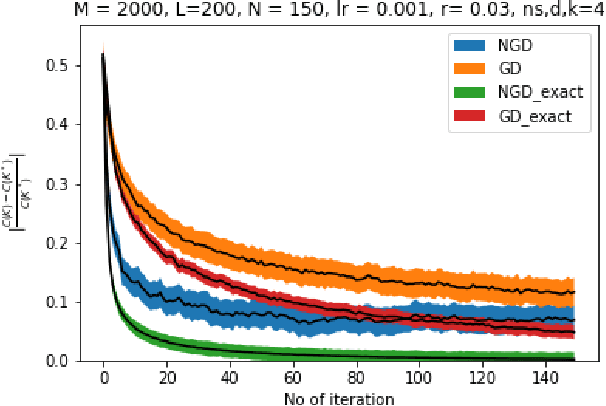
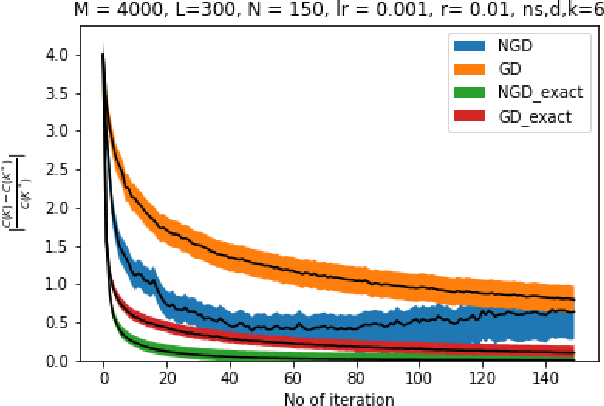
Owing to the growth of interest in Reinforcement Learning in the last few years, gradient based policy control methods have been gaining popularity for Control problems as well. And rightly so, since gradient policy methods have the advantage of optimizing a metric of interest in an end-to-end manner, along with being relatively easy to implement without complete knowledge of the underlying system. In this paper, we study the global convergence of gradient-based policy optimization methods for quadratic control of discrete-time and model-free Markovian jump linear systems (MJLS). We surmount myriad challenges that arise because of more than one states coupled with lack of knowledge of the system dynamics and show global convergence of the policy using gradient descent and natural policy gradient methods. We also provide simulation studies to corroborate our claims.
Clustering Market Regimes using the Wasserstein Distance
Oct 22, 2021The problem of rapid and automated detection of distinct market regimes is a topic of great interest to financial mathematicians and practitioners alike. In this paper, we outline an unsupervised learning algorithm for clustering financial time-series into a suitable number of temporal segments (market regimes). As a special case of the above, we develop a robust algorithm that automates the process of classifying market regimes. The method is robust in the sense that it does not depend on modelling assumptions of the underlying time series as our experiments with real datasets show. This method -- dubbed the Wasserstein $k$-means algorithm -- frames such a problem as one on the space of probability measures with finite $p^\text{th}$ moment, in terms of the $p$-Wasserstein distance between (empirical) distributions. We compare our WK-means approach with a more traditional clustering algorithms by studying the so-called maximum mean discrepancy scores between, and within clusters. In both cases it is shown that the WK-means algorithm vastly outperforms all considered competitor approaches. We demonstrate the performance of all approaches both in a controlled environment on synthetic data, and on real data.
Predicting Path Failure In Time-Evolving Graphs
May 21, 2019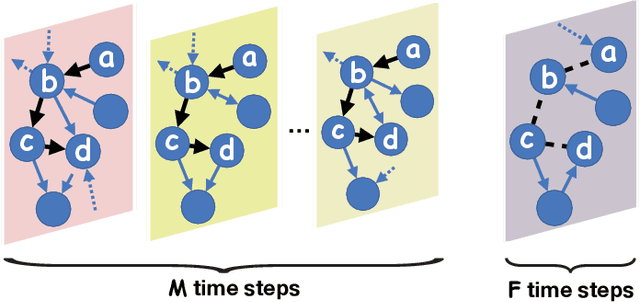
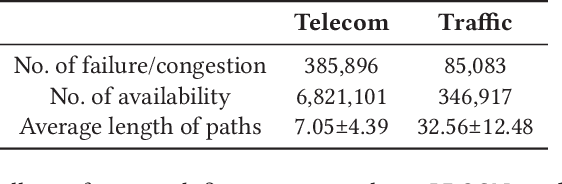
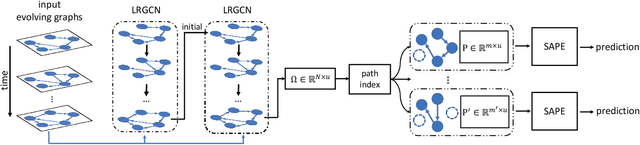
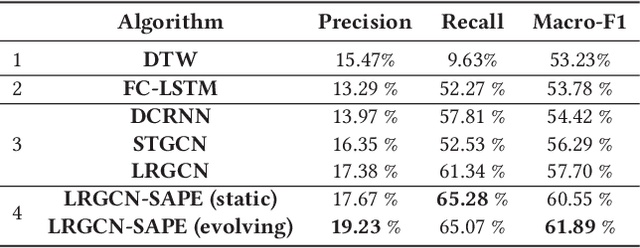
In this paper we use a time-evolving graph which consists of a sequence of graph snapshots over time to model many real-world networks. We study the path classification problem in a time-evolving graph, which has many applications in real-world scenarios, for example, predicting path failure in a telecommunication network and predicting path congestion in a traffic network in the near future. In order to capture the temporal dependency and graph structure dynamics, we design a novel deep neural network named Long Short-Term Memory R-GCN (LRGCN). LRGCN considers temporal dependency between time-adjacent graph snapshots as a special relation with memory, and uses relational GCN to jointly process both intra-time and inter-time relations. We also propose a new path representation method named self-attentive path embedding (SAPE), to embed paths of arbitrary length into fixed-length vectors. Through experiments on a real-world telecommunication network and a traffic network in California, we demonstrate the superiority of LRGCN to other competing methods in path failure prediction, and prove the effectiveness of SAPE on path representation.
Adaptive Beam Search to Enhance On-device Abstractive Summarization
Dec 22, 2021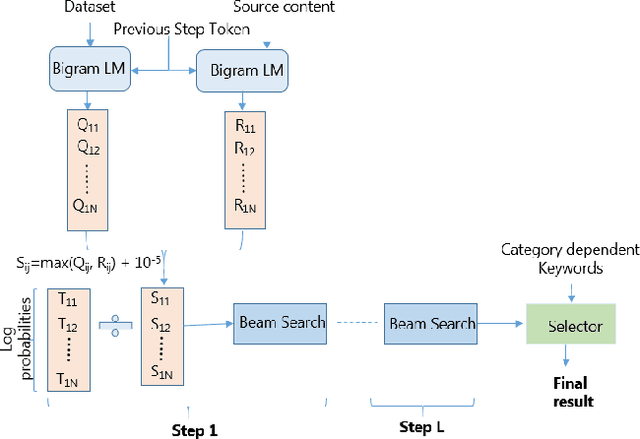
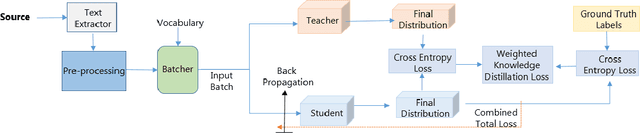
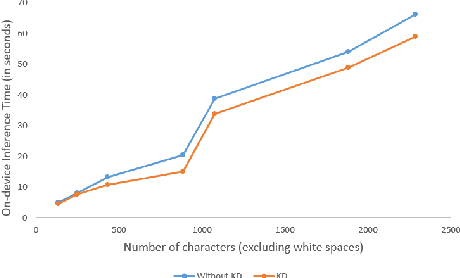
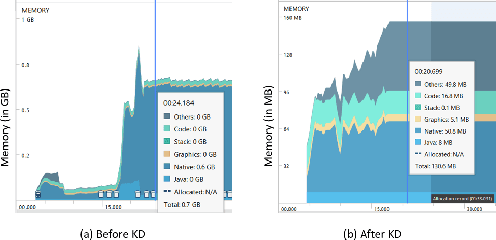
We receive several essential updates on our smartphones in the form of SMS, documents, voice messages, etc. that get buried beneath the clutter of content. We often do not realize the key information without going through the full content. SMS notifications sometimes help by giving an idea of what the message is about, however, they merely offer a preview of the beginning content. One way to solve this is to have a single efficient model that can adapt and summarize data from varied sources. In this paper, we tackle this issue and for the first time, propose a novel Adaptive Beam Search to improve the quality of on-device abstractive summarization that can be applied to SMS, voice messages and can be extended to documents. To the best of our knowledge, this is the first on-device abstractive summarization pipeline to be proposed that can adapt to multiple data sources addressing privacy concerns of users as compared to the majority of existing summarization systems that send data to a server. We reduce the model size by 30.9% using knowledge distillation and show that this model with a 97.6% lesser memory footprint extracts the same or more key information as compared to BERT.
Deep Spatio-temporal Sparse Decomposition for Trend Prediction and Anomaly Detection in Cardiac Electrical Conduction
Sep 20, 2021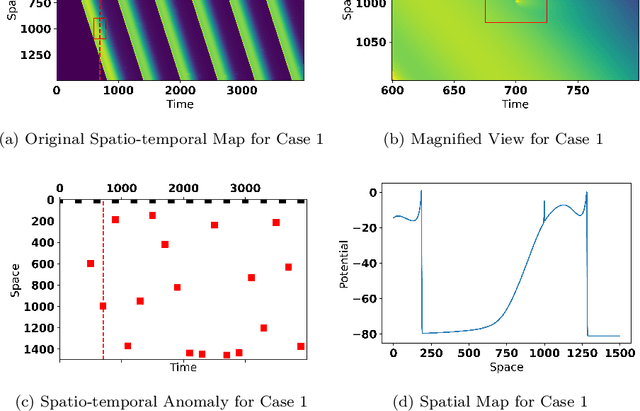

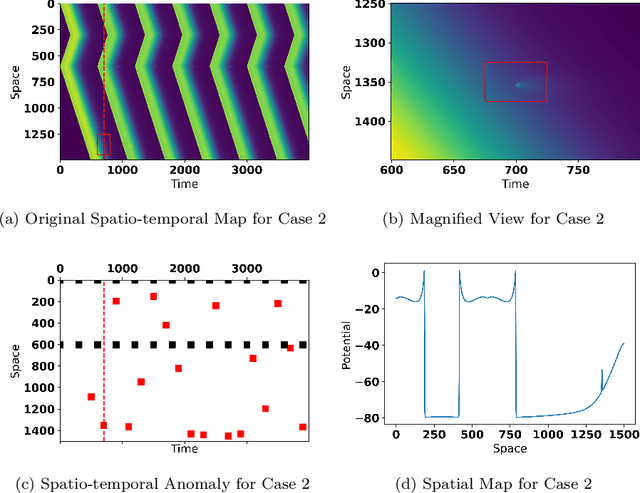

Electrical conduction among cardiac tissue is commonly modeled with partial differential equations, i.e., reaction-diffusion equation, where the reaction term describes cellular stimulation and diffusion term describes electrical propagation. Detecting and identifying of cardiac cells that produce abnormal electrical impulses in such nonlinear dynamic systems are important for efficient treatment and planning. To model the nonlinear dynamics, simulation has been widely used in both cardiac research and clinical study to investigate cardiac disease mechanisms and develop new treatment designs. However, existing cardiac models have a great level of complexity, and the simulation is often time-consuming. We propose a deep spatio-temporal sparse decomposition (DSTSD) approach to bypass the time-consuming cardiac partial differential equations with the deep spatio-temporal model and detect the time and location of the anomaly (i.e., malfunctioning cardiac cells). This approach is validated from the data set generated from the Courtemanche-Ramirez-Nattel (CRN) model, which is widely used to model the propagation of the transmembrane potential across the cross neuron membrane. The proposed DSTSD achieved the best accuracy in terms of spatio-temporal mean trend prediction and anomaly detection.
Incremental Learning in Semantic Segmentation from Image Labels
Dec 03, 2021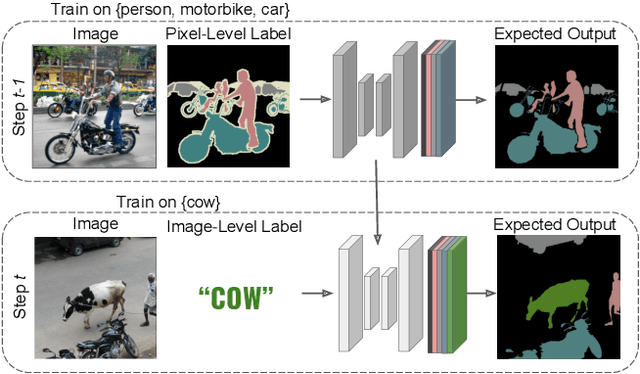
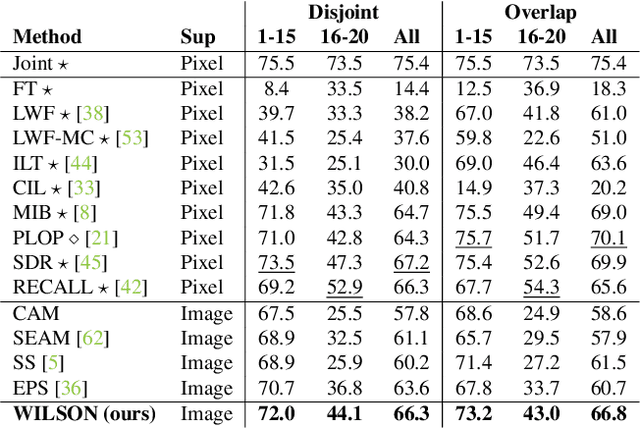
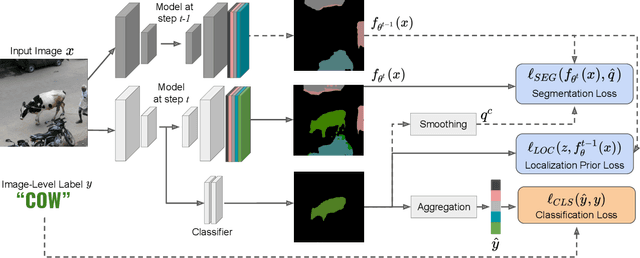
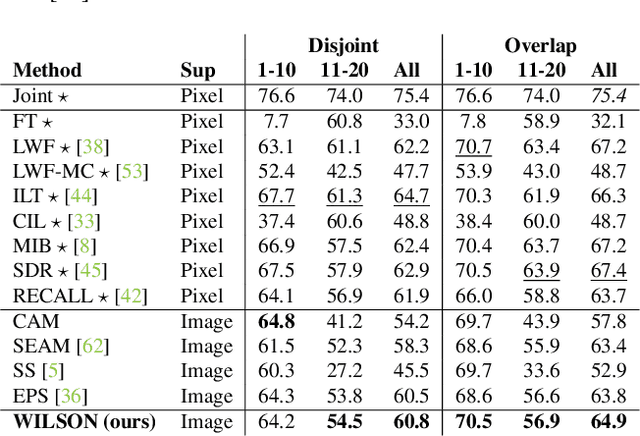
Although existing semantic segmentation approaches achieve impressive results, they still struggle to update their models incrementally as new categories are uncovered. Furthermore, pixel-by-pixel annotations are expensive and time-consuming. This paper proposes a novel framework for Weakly Incremental Learning for Semantic Segmentation, that aims at learning to segment new classes from cheap and largely available image-level labels. As opposed to existing approaches, that need to generate pseudo-labels offline, we use an auxiliary classifier, trained with image-level labels and regularized by the segmentation model, to obtain pseudo-supervision online and update the model incrementally. We cope with the inherent noise in the process by using soft-labels generated by the auxiliary classifier. We demonstrate the effectiveness of our approach on the Pascal VOC and COCO datasets, outperforming offline weakly-supervised methods and obtaining results comparable with incremental learning methods with full supervision.
An AGI with Time-Inconsistent Preferences
Jun 23, 2019This paper reveals a trap for artificial general intelligence (AGI) theorists who use economists' standard method of discounting. This trap is implicitly and falsely assuming that a rational AGI would have time-consistent preferences. An agent with time-inconsistent preferences knows that its future self will disagree with its current self concerning intertemporal decision making. Such an agent cannot automatically trust its future self to carry out plans that its current self considers optimal.
Molecular Attributes Transfer from Non-Parallel Data
Nov 30, 2021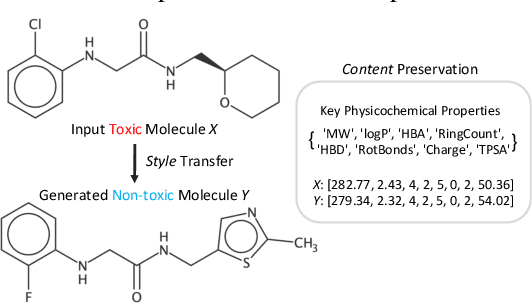
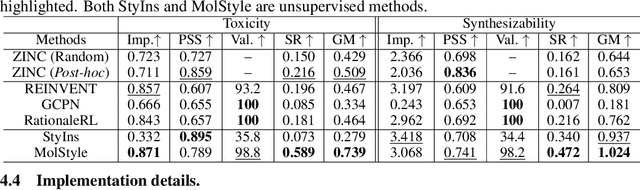
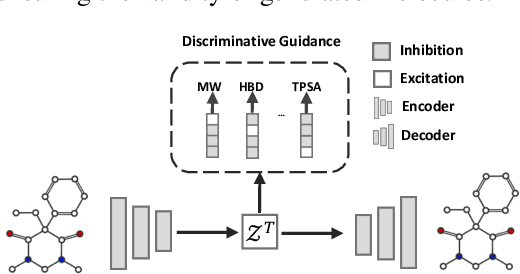
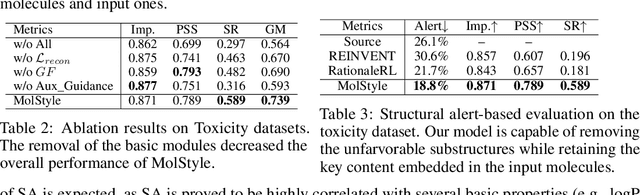
Optimizing chemical molecules for desired properties lies at the core of drug development. Despite initial successes made by deep generative models and reinforcement learning methods, these methods were mostly limited by the requirement of predefined attribute functions or parallel data with manually pre-compiled pairs of original and optimized molecules. In this paper, for the first time, we formulate molecular optimization as a style transfer problem and present a novel generative model that could automatically learn internal differences between two groups of non-parallel data through adversarial training strategies. Our model further enables both preservation of molecular contents and optimization of molecular properties through combining auxiliary guided-variational autoencoders and generative flow techniques. Experiments on two molecular optimization tasks, toxicity modification and synthesizability improvement, demonstrate that our model significantly outperforms several state-of-the-art methods.
Fast and scalable neuroevolution deep learning architecture search for multivariate anomaly detection
Jan 07, 2022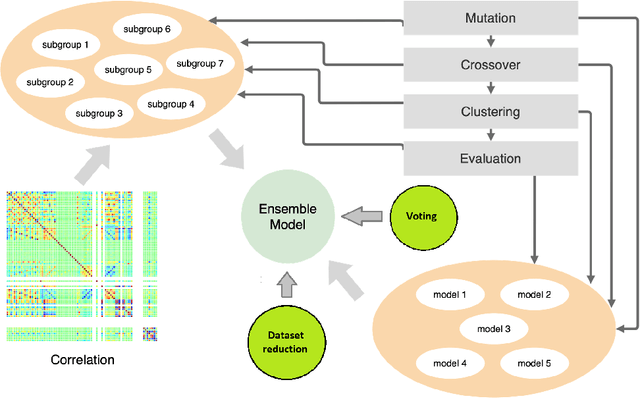
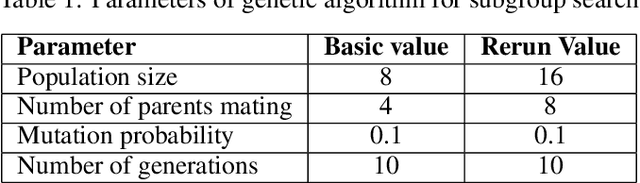
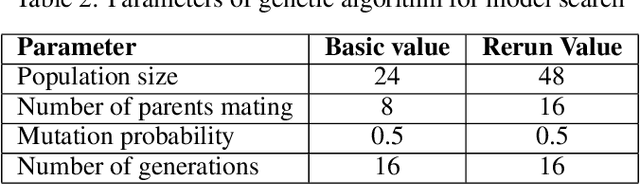
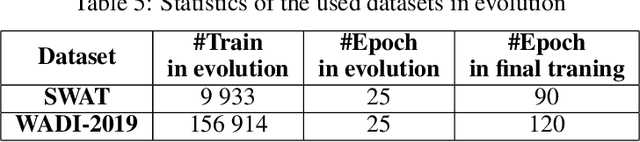
Neuroevolution is one of the methodologies that can be used for learning optimal architecture during training. It uses evolutionary algorithms to generate the topology of artificial neural networks and its parameters. The main benefits are that it is scalable and can be fully or partially non gradient method. In this work, a modified neuroevolution technique is presented which incorporates multi-level optimisation. The presented approach adapts evolution strategies for evolving an ensemble model based on the bagging technique, using genetic operators for optimising single anomaly detection models, reducing the training dataset to speedup the search process and perform non-gradient fine tuning. Multivariate anomaly detection as an unsupervised learning task is the case study upon which the presented approach is tested. Single model optimisation is based on mutation and crossover operators and is focused on finding optimal window sizes, the number of layers, layer depths, hyperparameters etc. to boost the anomaly detection scores of new and already known models. The proposed framework and its protocol shows that it is possible to find architecture within a reasonable time frame which can boost all well known multivariate anomaly detection deep learning architectures. The work concentrates on improvements to the multi-level neuroevolution approach for anomaly detection. The main modifications are in the methods of mixing groups and single model evolution, non-gradient fine tuning and a voting mechanism. The presented framework can be used as an efficient learning network architecture method for any different unsupervised task where autoencoder architectures can be used. The tests were run on SWAT and WADI datasets and the presented approach evolved the architectures that achieved the best scores among other deep learning models.