 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharting the Design Space of Neural Graph Representations for Subgraph Matching
Oct 27, 2025Subgraph matching is vital in knowledge graph (KG) question answering, molecule design, scene graph, code and circuit search, etc. Neural methods have shown promising results for subgraph matching. Our study of recent systems suggests refactoring them into a unified design space for graph matching networks. Existing methods occupy only a few isolated patches in this space, which remains largely uncharted. We undertake the first comprehensive exploration of this space, featuring such axes as attention-based vs. soft permutation-based interaction between query and corpus graphs, aligning nodes vs. edges, and the form of the final scoring network that integrates neural representations of the graphs. Our extensive experiments reveal that judicious and hitherto-unexplored combinations of choices in this space lead to large performance benefits. Beyond better performance, our study uncovers valuable insights and establishes general design principles for neural graph representation and interaction, which may be of wider interest.
Contextual Tokenization for Graph Inverted Indices
Oct 26, 2025Retrieving graphs from a large corpus, that contain a subgraph isomorphic to a given query graph, is a core operation in many real-world applications. While recent multi-vector graph representations and scores based on set alignment and containment can provide accurate subgraph isomorphism tests, their use in retrieval remains limited by their need to score corpus graphs exhaustively. We introduce CORGII (Contextual Representation of Graphs for Inverted Indexing), a graph indexing framework in which, starting with a contextual dense graph representation, a differentiable discretization module computes sparse binary codes over a learned latent vocabulary. This text document-like representation allows us to leverage classic, highly optimized inverted indices, while supporting soft (vector) set containment scores. Pushing this paradigm further, we replace the classical, fixed impact weight of a `token' on a graph (such as TFIDF or BM25) with a data-driven, trainable impact weight. Finally, we explore token expansion to support multi-probing the index for smoother accuracy-efficiency tradeoffs. To our knowledge, CORGII is the first indexer of dense graph representations using discrete tokens mapping to efficient inverted lists. Extensive experiments show that CORGII provides better trade-offs between accuracy and efficiency, compared to several baselines.
Iteratively Refined Early Interaction Alignment for Subgraph Matching based Graph Retrieval
Oct 26, 2025Graph retrieval based on subgraph isomorphism has several real-world applications such as scene graph retrieval, molecular fingerprint detection and circuit design. Roy et al. [35] proposed IsoNet, a late interaction model for subgraph matching, which first computes the node and edge embeddings of each graph independently of paired graph and then computes a trainable alignment map. Here, we present IsoNet++, an early interaction graph neural network (GNN), based on several technical innovations. First, we compute embeddings of all nodes by passing messages within and across the two input graphs, guided by an injective alignment between their nodes. Second, we update this alignment in a lazy fashion over multiple rounds. Within each round, we run a layerwise GNN from scratch, based on the current state of the alignment. After the completion of one round of GNN, we use the last-layer embeddings to update the alignments, and proceed to the next round. Third, IsoNet++ incorporates a novel notion of node-pair partner interaction. Traditional early interaction computes attention between a node and its potential partners in the other graph, the attention then controlling messages passed across graphs. In contrast, we consider node pairs (not single nodes) as potential partners. Existence of an edge between the nodes in one graph and non-existence in the other provide vital signals for refining the alignment. Our experiments on several datasets show that the alignments get progressively refined with successive rounds, resulting in significantly better retrieval performance than existing methods. We demonstrate that all three innovations contribute to the enhanced accuracy. Our code and datasets are publicly available at https://github.com/structlearning/isonetpp.
Differentiable Adversarial Attacks for Marked Temporal Point Processes
Jan 17, 2025Marked temporal point processes (MTPPs) have been shown to be extremely effective in modeling continuous time event sequences (CTESs). In this work, we present adversarial attacks designed specifically for MTPP models. A key criterion for a good adversarial attack is its imperceptibility. For objects such as images or text, this is often achieved by bounding perturbation in some fixed $L_p$ norm-ball. However, similarly minimizing distance norms between two CTESs in the context of MTPPs is challenging due to their sequential nature and varying time-scales and lengths. We address this challenge by first permuting the events and then incorporating the additive noise to the arrival timestamps. However, the worst case optimization of such adversarial attacks is a hard combinatorial problem, requiring exploration across a permutation space that is factorially large in the length of the input sequence. As a result, we propose a novel differentiable scheme PERMTPP using which we can perform adversarial attacks by learning to minimize the likelihood, while minimizing the distance between two CTESs. Our experiments on four real-world datasets demonstrate the offensive and defensive capabilities, and lower inference times of PERMTPP.
Graph Edit Distance with General Costs Using Neural Set Divergence
Sep 26, 2024



Graph Edit Distance (GED) measures the (dis-)similarity between two given graphs, in terms of the minimum-cost edit sequence that transforms one graph to the other. However, the exact computation of GED is NP-Hard, which has recently motivated the design of neural methods for GED estimation. However, they do not explicitly account for edit operations with different costs. In response, we propose GRAPHEDX, a neural GED estimator that can work with general costs specified for the four edit operations, viz., edge deletion, edge addition, node deletion and node addition. We first present GED as a quadratic assignment problem (QAP) that incorporates these four costs. Then, we represent each graph as a set of node and edge embeddings and use them to design a family of neural set divergence surrogates. We replace the QAP terms corresponding to each operation with their surrogates. Computing such neural set divergence require aligning nodes and edges of the two graphs. We learn these alignments using a Gumbel-Sinkhorn permutation generator, additionally ensuring that the node and edge alignments are consistent with each other. Moreover, these alignments are cognizant of both the presence and absence of edges between node-pairs. Experiments on several datasets, under a variety of edit cost settings, show that GRAPHEDX consistently outperforms state-of-the-art methods and heuristics in terms of prediction error.
* Published at NeurIPS 2024
Continuous Treatment Effect Estimation Using Gradient Interpolation and Kernel Smoothing
Jan 27, 2024



We address the Individualized continuous treatment effect (ICTE) estimation problem where we predict the effect of any continuous-valued treatment on an individual using observational data. The main challenge in this estimation task is the potential confounding of treatment assignment with an individual's covariates in the training data, whereas during inference ICTE requires prediction on independently sampled treatments. In contrast to prior work that relied on regularizers or unstable GAN training, we advocate the direct approach of augmenting training individuals with independently sampled treatments and inferred counterfactual outcomes. We infer counterfactual outcomes using a two-pronged strategy: a Gradient Interpolation for close-to-observed treatments, and a Gaussian Process based Kernel Smoothing which allows us to downweigh high variance inferences. We evaluate our method on five benchmarks and show that our method outperforms six state-of-the-art methods on the counterfactual estimation error. We analyze the superior performance of our method by showing that (1) our inferred counterfactual responses are more accurate, and (2) adding them to the training data reduces the distributional distance between the confounded training distribution and test distribution where treatment is independent of covariates. Our proposed method is model-agnostic and we show that it improves ICTE accuracy of several existing models.
Generator Assisted Mixture of Experts For Feature Acquisition in Batch
Dec 19, 2023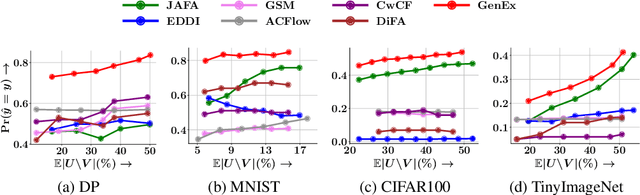
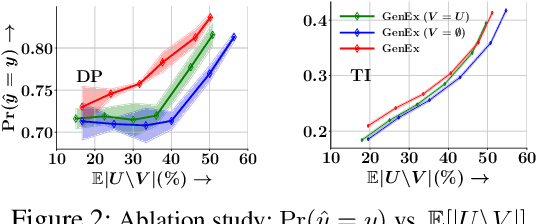
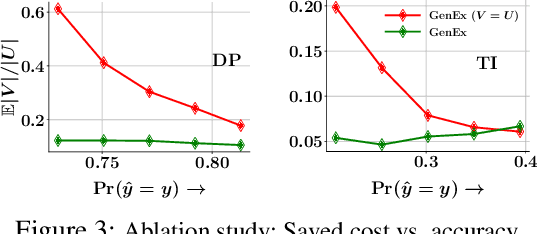
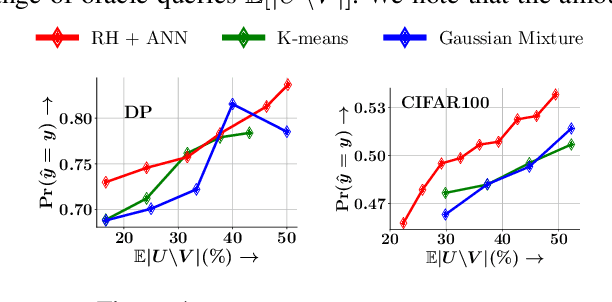
Given a set of observations, feature acquisition is about finding the subset of unobserved features which would enhance accuracy. Such problems have been explored in a sequential setting in prior work. Here, the model receives feedback from every new feature acquired and chooses to explore more features or to predict. However, sequential acquisition is not feasible in some settings where time is of the essence. We consider the problem of feature acquisition in batch, where the subset of features to be queried in batch is chosen based on the currently observed features, and then acquired as a batch, followed by prediction. We solve this problem using several technical innovations. First, we use a feature generator to draw a subset of the synthetic features for some examples, which reduces the cost of oracle queries. Second, to make the feature acquisition problem tractable for the large heterogeneous observed features, we partition the data into buckets, by borrowing tools from locality sensitive hashing and then train a mixture of experts model. Third, we design a tractable lower bound of the original objective. We use a greedy algorithm combined with model training to solve the underlying problem. Experiments with four datasets show that our approach outperforms these methods in terms of trade-off between accuracy and feature acquisition cost.
Retrieving Continuous Time Event Sequences using Neural Temporal Point Processes with Learnable Hashing
Jul 13, 2023Temporal sequences have become pervasive in various real-world applications. Consequently, the volume of data generated in the form of continuous time-event sequence(s) or CTES(s) has increased exponentially in the past few years. Thus, a significant fraction of the ongoing research on CTES datasets involves designing models to address downstream tasks such as next-event prediction, long-term forecasting, sequence classification etc. The recent developments in predictive modeling using marked temporal point processes (MTPP) have enabled an accurate characterization of several real-world applications involving the CTESs. However, due to the complex nature of these CTES datasets, the task of large-scale retrieval of temporal sequences has been overlooked by the past literature. In detail, by CTES retrieval we mean that for an input query sequence, a retrieval system must return a ranked list of relevant sequences from a large corpus. To tackle this, we propose NeuroSeqRet, a first-of-its-kind framework designed specifically for end-to-end CTES retrieval. Specifically, NeuroSeqRet introduces multiple enhancements over standard retrieval frameworks and first applies a trainable unwarping function on the query sequence which makes it comparable with corpus sequences, especially when a relevant query-corpus pair has individually different attributes. Next, it feeds the unwarped query sequence and the corpus sequence into MTPP-guided neural relevance models. We develop four variants of the relevance model for different kinds of applications based on the trade-off between accuracy and efficiency. We also propose an optimization framework to learn binary sequence embeddings from the relevance scores, suitable for the locality-sensitive hashing. Our experiments show the significant accuracy boost of NeuroSeqRet as well as the efficacy of our hashing mechanism.
Modeling Continuous Time Sequences with Intermittent Observations using Marked Temporal Point Processes
Jun 23, 2022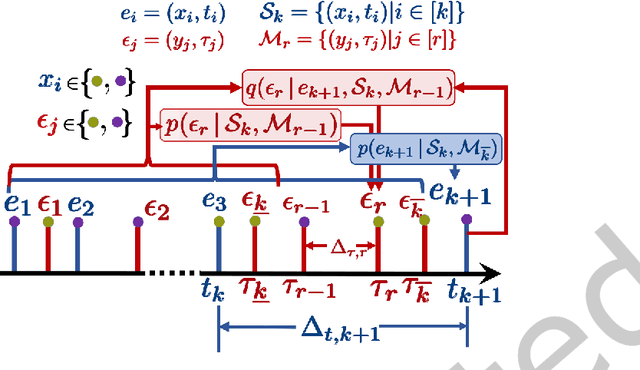

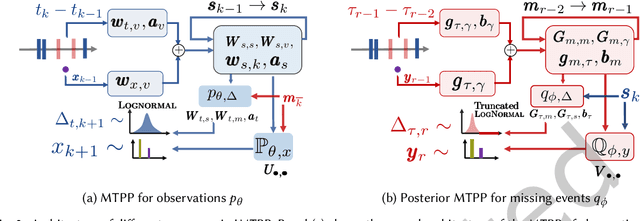
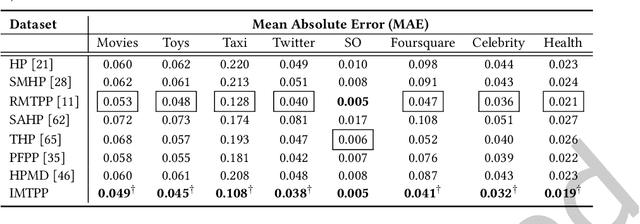
A large fraction of data generated via human activities such as online purchases, health records, spatial mobility etc. can be represented as a sequence of events over a continuous-time. Learning deep learning models over these continuous-time event sequences is a non-trivial task as it involves modeling the ever-increasing event timestamps, inter-event time gaps, event types, and the influences between different events within and across different sequences. In recent years neural enhancements to marked temporal point processes (MTPP) have emerged as a powerful framework to model the underlying generative mechanism of asynchronous events localized in continuous time. However, most existing models and inference methods in the MTPP framework consider only the complete observation scenario i.e. the event sequence being modeled is completely observed with no missing events -- an ideal setting that is rarely applicable in real-world applications. A recent line of work which considers missing events while training MTPP utilizes supervised learning techniques that require additional knowledge of missing or observed label for each event in a sequence, which further restricts its practicability as in several scenarios the details of missing events is not known apriori. In this work, we provide a novel unsupervised model and inference method for learning MTPP in presence of event sequences with missing events. Specifically, we first model the generative processes of observed events and missing events using two MTPP, where the missing events are represented as latent random variables. Then, we devise an unsupervised training method that jointly learns both the MTPP by means of variational inference. Such a formulation can effectively impute the missing data among the observed events and can identify the optimal position of missing events in a sequence.
Learning Temporal Point Processes for Efficient Retrieval of Continuous Time Event Sequences
Feb 17, 2022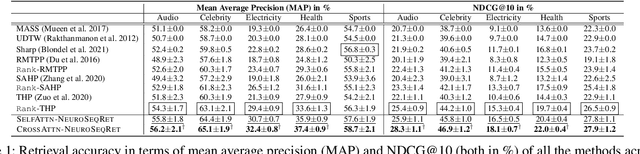

Recent developments in predictive modeling using marked temporal point processes (MTPP) have enabled an accurate characterization of several real-world applications involving continuous-time event sequences (CTESs). However, the retrieval problem of such sequences remains largely unaddressed in literature. To tackle this, we propose NEUROSEQRET which learns to retrieve and rank a relevant set of continuous-time event sequences for a given query sequence, from a large corpus of sequences. More specifically, NEUROSEQRET first applies a trainable unwarping function on the query sequence, which makes it comparable with corpus sequences, especially when a relevant query-corpus pair has individually different attributes. Next, it feeds the unwarped query sequence and the corpus sequence into MTPP guided neural relevance models. We develop two variants of the relevance model which offer a tradeoff between accuracy and efficiency. We also propose an optimization framework to learn binary sequence embeddings from the relevance scores, suitable for the locality-sensitive hashing leading to a significant speedup in returning top-K results for a given query sequence. Our experiments with several datasets show the significant accuracy boost of NEUROSEQRET beyond several baselines, as well as the efficacy of our hashing mechanism.