 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Application of Convolutional Neural Networks for Tomographic Reconstruction of Hyperspectral Images
Aug 30, 2021

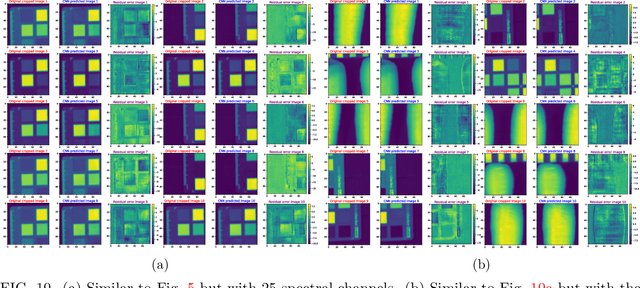
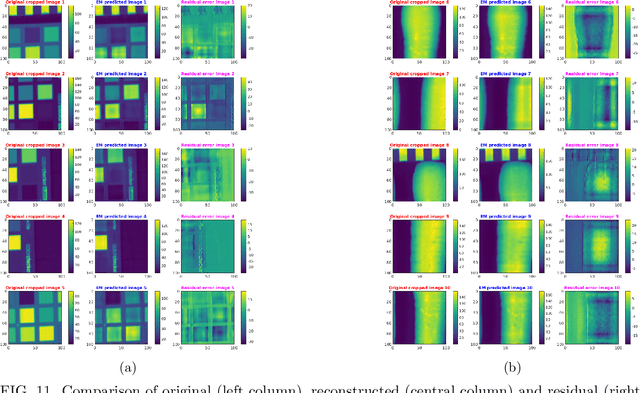
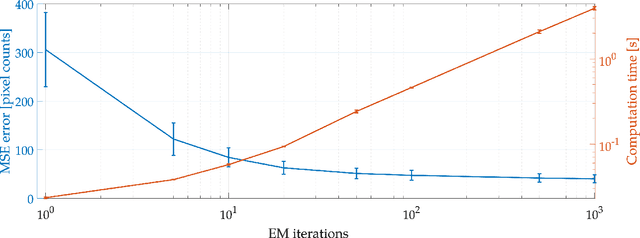
A novel method, utilizing convolutional neural networks (CNNs), is proposed to reconstruct hyperspectral cubes from computed tomography imaging spectrometer (CTIS) images. Current reconstruction algorithms are usually subject to long reconstruction times and mediocre precision in cases of a large number of spectral channels. The constructed CNNs deliver higher precision and shorter reconstruction time than a standard expectation maximization algorithm. In addition, the network can handle two different types of real-world images at the same time -- specifically ColorChecker and carrot spectral images are considered. This work paves the way toward real-time reconstruction of hyperspectral cubes from CTIS images.
Continuous-time Gaussian Process Trajectory Generation for Multi-robot Formation via Probabilistic Inference
Oct 31, 2020
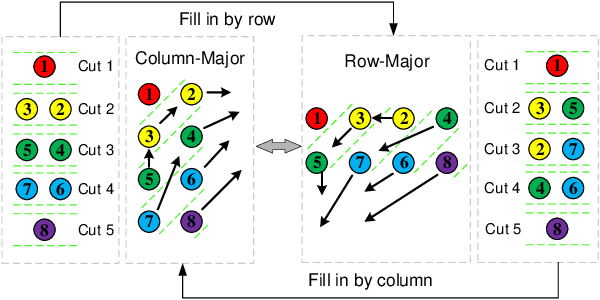
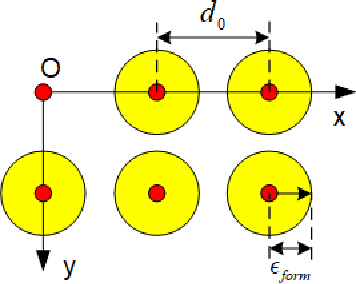
In this paper, we extend a famous motion planning approach GPMP2 to multi-robot cases, yielding a novel centralized trajectory generation method for the multi-robot formation. A sparse Gaussian Process model is employed to represent the continuous-time trajectories of all robots as a limited number of states, which improves computational efficiency due to the sparsity. We add constraints to guarantee collision avoidance between individuals as well as formation maintenance, then all constraints and kinematics are formulated on a factor graph. By introducing a global planner, our proposed method can generate trajectories efficiently for a team of robots which have to get through a width-varying area by adaptive formation change. Finally, we provide the implementation of an incremental replanning algorithm to demonstrate the online operation potential of our proposed framework. The experiments in simulation and real world illustrate the feasibility, efficiency and scalability of our approach.
Evaluating robustness of You Only Hear Once(YOHO) Algorithm on noisy audios in the VOICe Dataset
Nov 01, 2021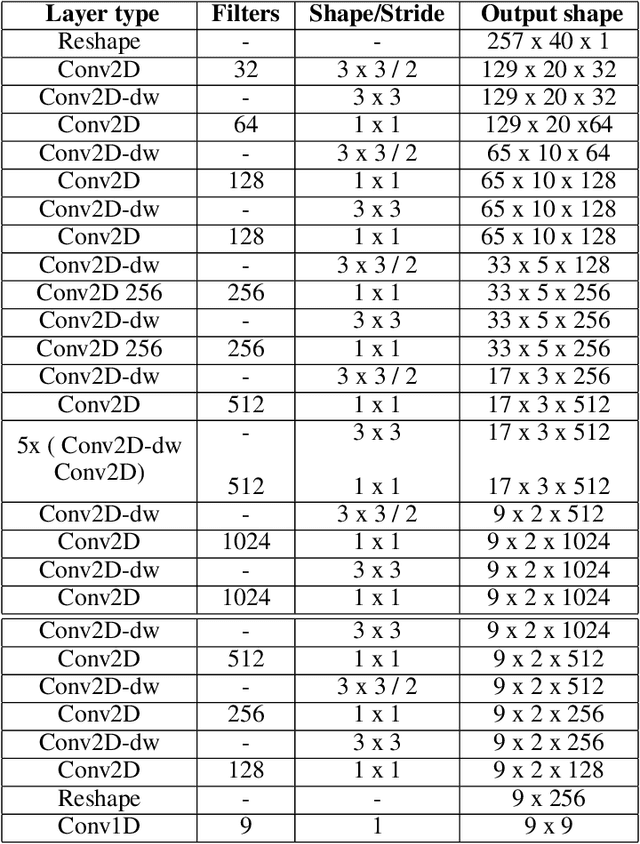
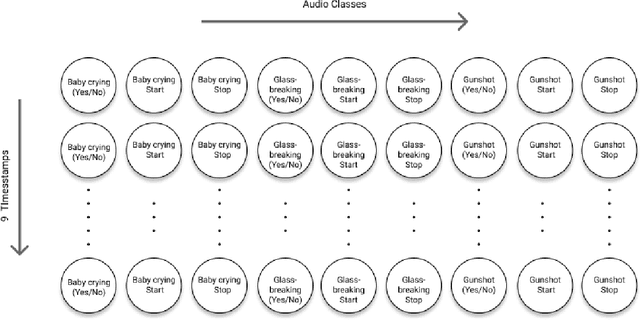
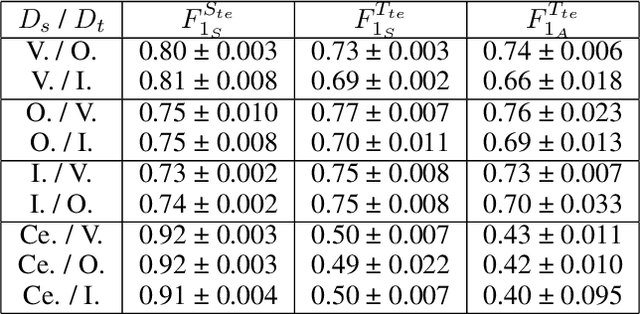
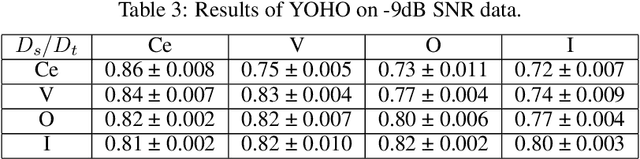
Sound event detection (SED) in machine listening entails identifying the different sounds in an audio file and identifying the start and end time of a particular sound event in the audio. SED finds use in various applications such as audio surveillance, speech recognition, and context-based indexing and retrieval of data in a multimedia database. However, in real-life scenarios, the audios from various sources are seldom devoid of any interfering noise or disturbance. In this paper, we test the performance of the You Only Hear Once (YOHO) algorithm on noisy audio data. Inspired by the You Only Look Once (YOLO) algorithm in computer vision, the YOHO algorithm can match the performance of the various state-of-the-art algorithms on datasets such as Music Speech Detection Dataset, TUT Sound Event, and Urban-SED datasets but at lower inference times. In this paper, we explore the performance of the YOHO algorithm on the VOICe dataset containing audio files with noise at different sound-to-noise ratios (SNR). YOHO could outperform or at least match the best performing SED algorithms reported in the VOICe dataset paper and make inferences in less time.
Improving the Thermal Infrared Monitoring of Volcanoes: A Deep Learning Approach for Intermittent Image Series
Sep 27, 2021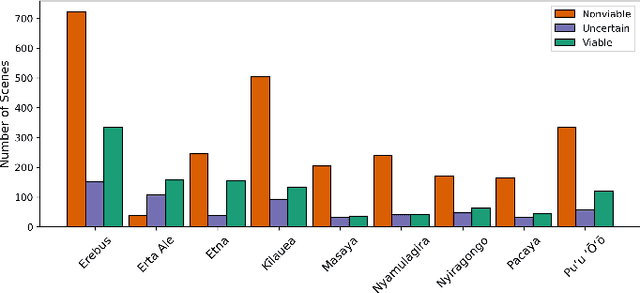
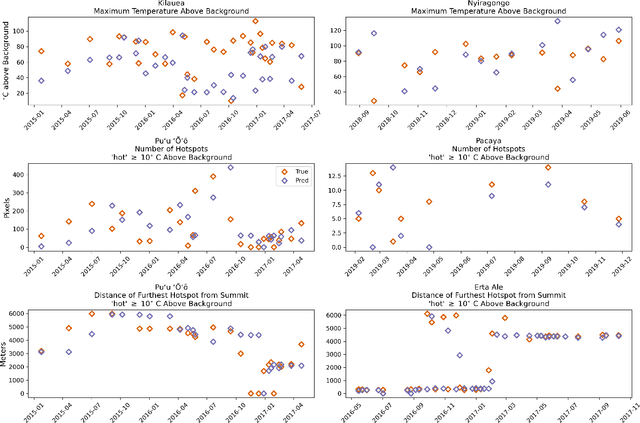
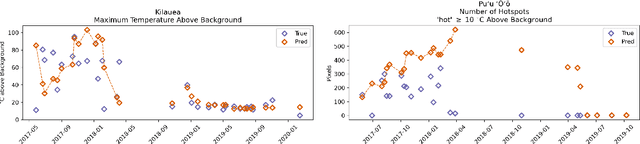

Active volcanoes are globally distributed and pose societal risks at multiple geographic scales, ranging from local hazards to regional/international disruptions. Many volcanoes do not have continuous ground monitoring networks; meaning that satellite observations provide the only record of volcanic behavior and unrest. Among these remote sensing observations, thermal imagery is inspected daily by volcanic observatories for examining the early signs, onset, and evolution of eruptive activity. However, thermal scenes are often obstructed by clouds, meaning that forecasts must be made off image sequences whose scenes are only usable intermittently through time. Here, we explore forecasting this thermal data stream from a deep learning perspective using existing architectures that model sequences with varying spatiotemporal considerations. Additionally, we propose and evaluate new architectures that explicitly model intermittent image sequences. Using ASTER Kinetic Surface Temperature data for $9$ volcanoes between $1999$ and $2020$, we found that a proposed architecture (ConvLSTM + Time-LSTM + U-Net) forecasts volcanic temperature imagery with the lowest RMSE ($4.164^{\circ}$C, other methods: $4.217-5.291^{\circ}$C). Additionally, we examined performance on multiple time series derived from the thermal imagery and the effect of training with data from singular volcanoes. Ultimately, we found that models with the lowest RMSE on forecasting imagery did not possess the lowest RMSE on recreating time series derived from that imagery and that training with individual volcanoes generally worsened performance relative to a multi-volcano data set. This work highlights the potential of data-driven deep learning models for volcanic unrest forecasting while revealing the need for carefully constructed optimization targets.
FREGAN : an application of generative adversarial networks in enhancing the frame rate of videos
Nov 01, 2021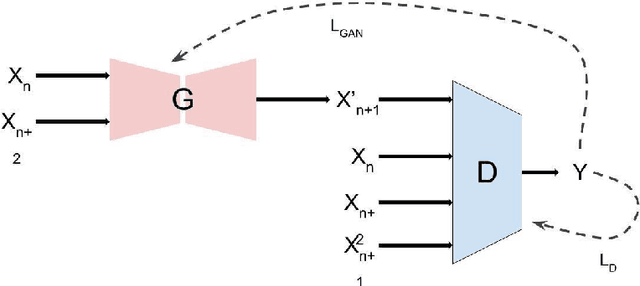

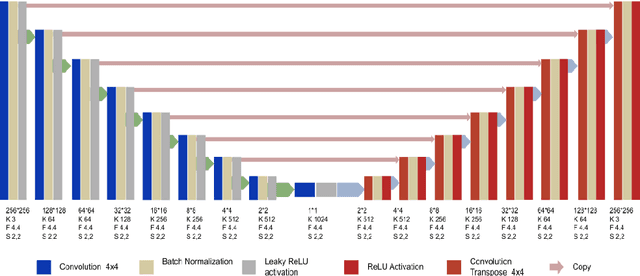
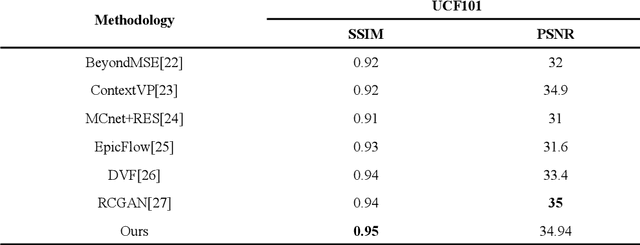
A digital video is a collection of individual frames, while streaming the video the scene utilized the time slice for each frame. High refresh rate and high frame rate is the demand of all high technology applications. The action tracking in videos becomes easier and motion becomes smoother in gaming applications due to the high refresh rate. It provides a faster response because of less time in between each frame that is displayed on the screen. FREGAN (Frame Rate Enhancement Generative Adversarial Network) model has been proposed, which predicts future frames of a video sequence based on a sequence of past frames. In this paper, we investigated the GAN model and proposed FREGAN for the enhancement of frame rate in videos. We have utilized Huber loss as a loss function in the proposed FREGAN. It provided excellent results in super-resolution and we have tried to reciprocate that performance in the application of frame rate enhancement. We have validated the effectiveness of the proposed model on the standard datasets (UCF101 and RFree500). The experimental outcomes illustrate that the proposed model has a Peak signal-to-noise ratio (PSNR) of 34.94 and a Structural Similarity Index (SSIM) of 0.95.
Hyperparameter-free Continuous Learning for Domain Classification in Natural Language Understanding
Jan 05, 2022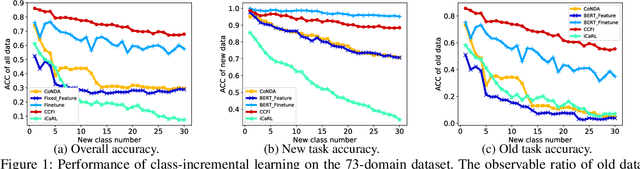

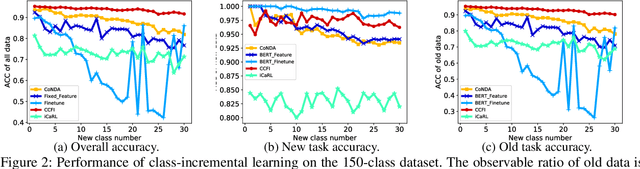

Domain classification is the fundamental task in natural language understanding (NLU), which often requires fast accommodation to new emerging domains. This constraint makes it impossible to retrain all previous domains, even if they are accessible to the new model. Most existing continual learning approaches suffer from low accuracy and performance fluctuation, especially when the distributions of old and new data are significantly different. In fact, the key real-world problem is not the absence of old data, but the inefficiency to retrain the model with the whole old dataset. Is it potential to utilize some old data to yield high accuracy and maintain stable performance, while at the same time, without introducing extra hyperparameters? In this paper, we proposed a hyperparameter-free continual learning model for text data that can stably produce high performance under various environments. Specifically, we utilize Fisher information to select exemplars that can "record" key information of the original model. Also, a novel scheme called dynamical weight consolidation is proposed to enable hyperparameter-free learning during the retrain process. Extensive experiments demonstrate that baselines suffer from fluctuated performance and therefore useless in practice. On the contrary, our proposed model CCFI significantly and consistently outperforms the best state-of-the-art method by up to 20% in average accuracy, and each component of CCFI contributes effectively to overall performance.
CIRCLE: Convolutional Implicit Reconstruction and Completion for Large-scale Indoor Scene
Nov 25, 2021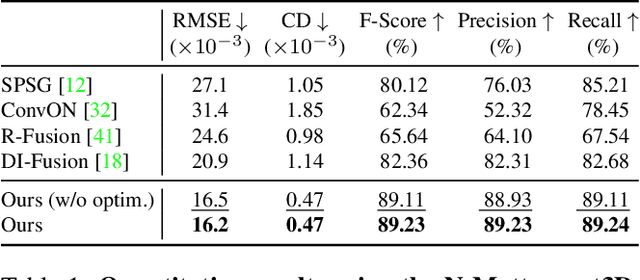
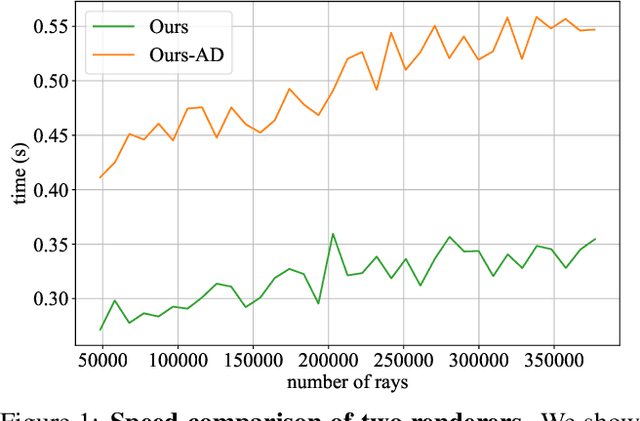
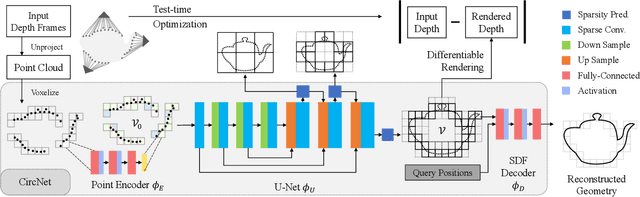
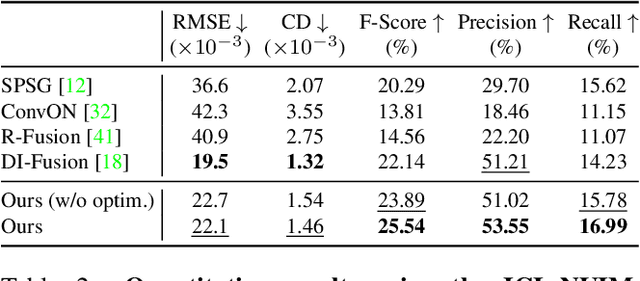
We present CIRCLE, a framework for large-scale scene completion and geometric refinement based on local implicit signed distance functions. It is based on an end-to-end sparse convolutional network, CircNet, that jointly models local geometric details and global scene structural contexts, allowing it to preserve fine-grained object detail while recovering missing regions commonly arising in traditional 3D scene data. A novel differentiable rendering module enables test-time refinement for better reconstruction quality. Extensive experiments on both real-world and synthetic datasets show that our concise framework is efficient and effective, achieving better reconstruction quality than the closest competitor while being 10-50x faster.
Real-time Surface Deformation Recovery from Stereo Videos
Jul 16, 2020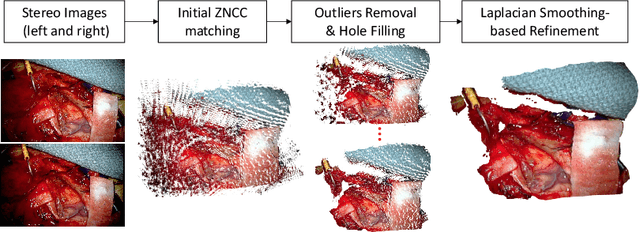

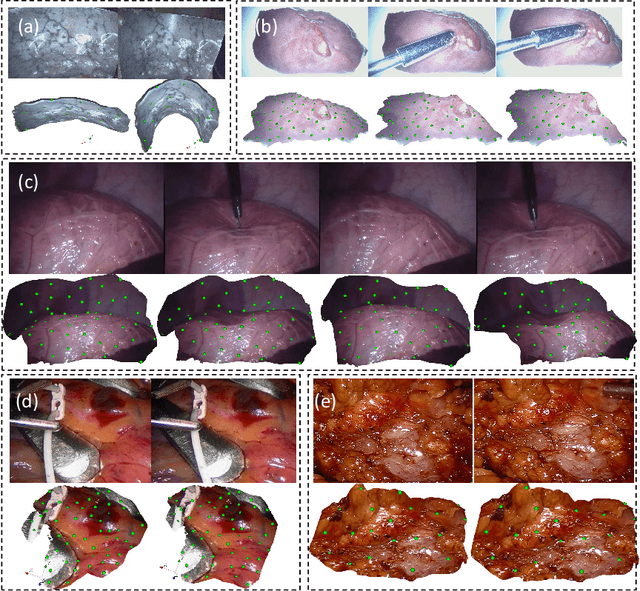
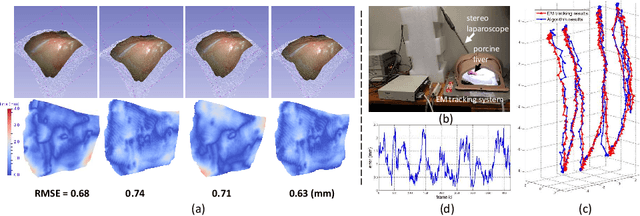
Tissue deformation during the surgery may significantly decrease the accuracy of surgical navigation systems. In this paper, we propose an approach to estimate the deformation of tissue surface from stereo videos in real-time, which is capable of handling occlusion, smooth surface and fast deformation. We first use a stereo matching method to extract depth information from stereo video frames and generate the tissue template, and then estimate the deformation of the obtained template by minimizing ICP, ORB feature matching and as-rigid-as-possible (ARAP) costs. The main novelties are twofold: (1) Due to non-rigid deformation, feature matching outliers are difficult to be removed by traditional RANSAC methods; therefore we propose a novel 1-point RANSAC and reweighting method to preselect matching inliers, which handles smooth surfaces and fast deformations. (2) We propose a novel ARAP cost function based on dense connections between the control points to achieve better smoothing performance with limited number of iterations. Algorithms are designed and implemented for GPU parallel computing. Experiments on ex- and in vivo data showed that this approach works at an update rate of 15Hz with an accuracy of less than 2.5 mm on a NVIDIA Titan X GPU.
Enhanced Language Representation with Label Knowledge for Span Extraction
Nov 01, 2021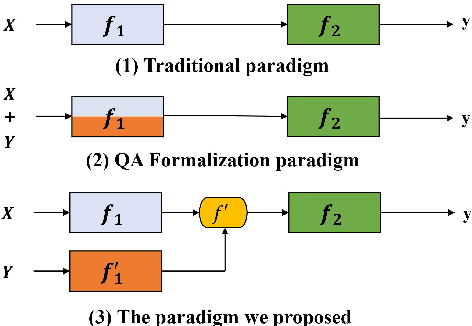


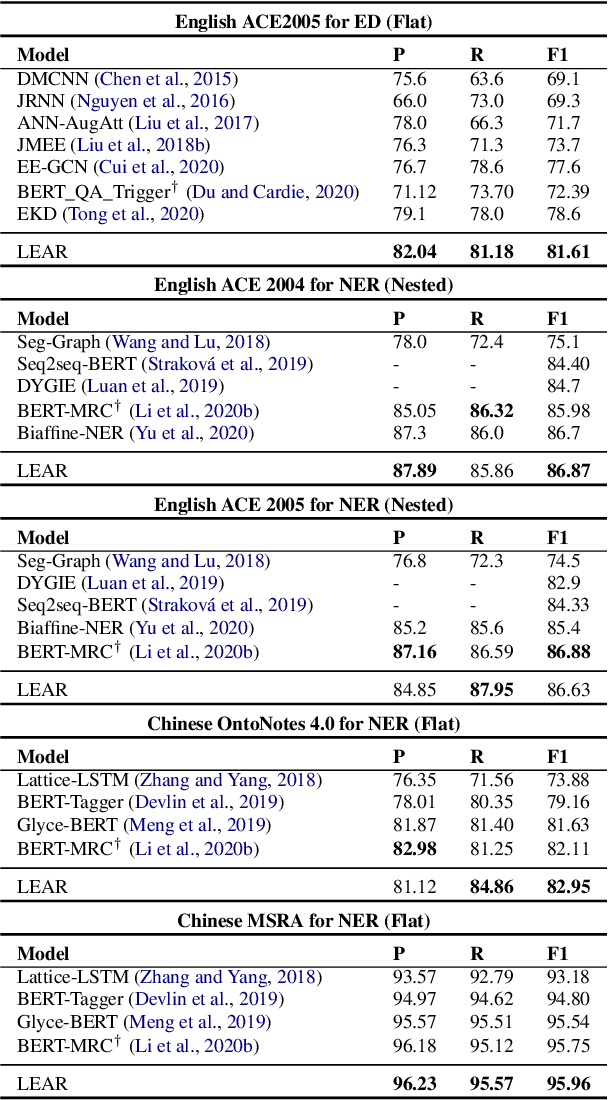
Span extraction, aiming to extract text spans (such as words or phrases) from plain texts, is a fundamental process in Information Extraction. Recent works introduce the label knowledge to enhance the text representation by formalizing the span extraction task into a question answering problem (QA Formalization), which achieves state-of-the-art performance. However, QA Formalization does not fully exploit the label knowledge and suffers from low efficiency in training/inference. To address those problems, we introduce a new paradigm to integrate label knowledge and further propose a novel model to explicitly and efficiently integrate label knowledge into text representations. Specifically, it encodes texts and label annotations independently and then integrates label knowledge into text representation with an elaborate-designed semantics fusion module. We conduct extensive experiments on three typical span extraction tasks: flat NER, nested NER, and event detection. The empirical results show that 1) our method achieves state-of-the-art performance on four benchmarks, and 2) reduces training time and inference time by 76% and 77% on average, respectively, compared with the QA Formalization paradigm. Our code and data are available at https://github.com/Akeepers/LEAR.
Multi-scale Interaction for Real-time LiDAR Data Segmentation on an Embedded Platform
Aug 20, 2020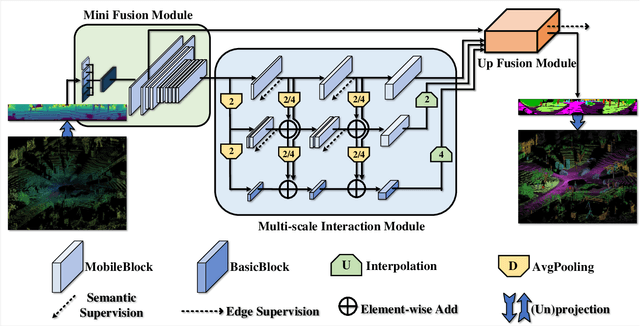
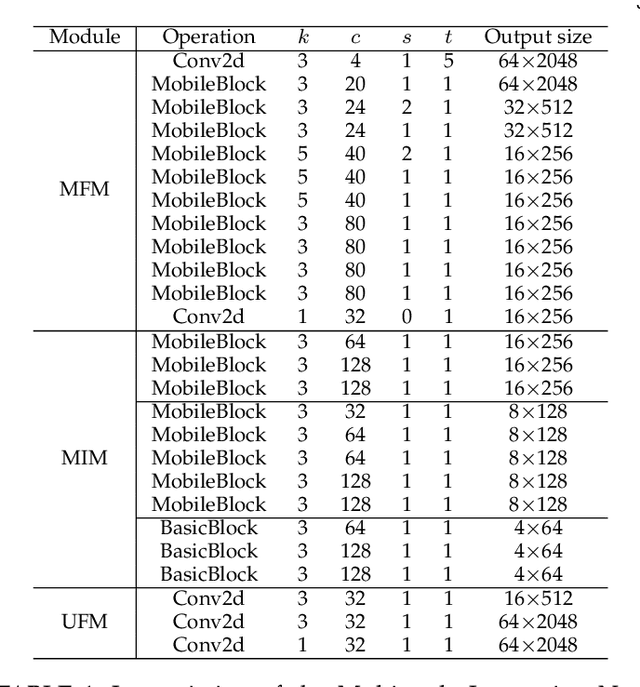
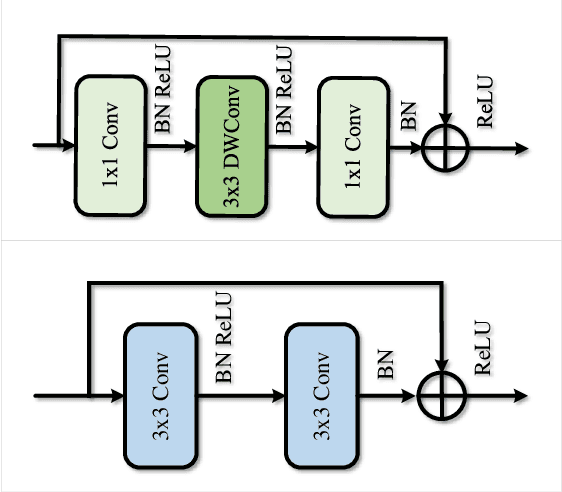

Real-time semantic segmentation of LiDAR data is crucial for autonomously driving vehicles, which are usually equipped with an embedded platform and have limited computational resources. Approaches that operate directly on the point cloud use complex spatial aggregation operations, which are very expensive and difficult to optimize for embedded platforms. They are therefore not suitable for real-time applications with embedded systems. As an alternative, projection-based methods are more efficient and can run on embedded platforms. However, the current state-of-the-art projection-based methods do not achieve the same accuracy as point-based methods and use millions of parameters. In this paper, we therefore propose a projection-based method, called Multi-scale Interaction Network (MINet), which is very efficient and accurate. The network uses multiple paths with different scales and balances the computational resources between the scales. Additional dense interactions between the scales avoid redundant computations and make the network highly efficient. The proposed network outperforms point-based, image-based, and projection-based methods in terms of accuracy, number of parameters, and runtime. Moreover, the network processes more than 24 scans per second on an embedded platform, which is higher than the framerates of LiDAR sensors. The network is therefore suitable for autonomous vehicles.