 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Chronological Causal Bandits
Dec 03, 2021
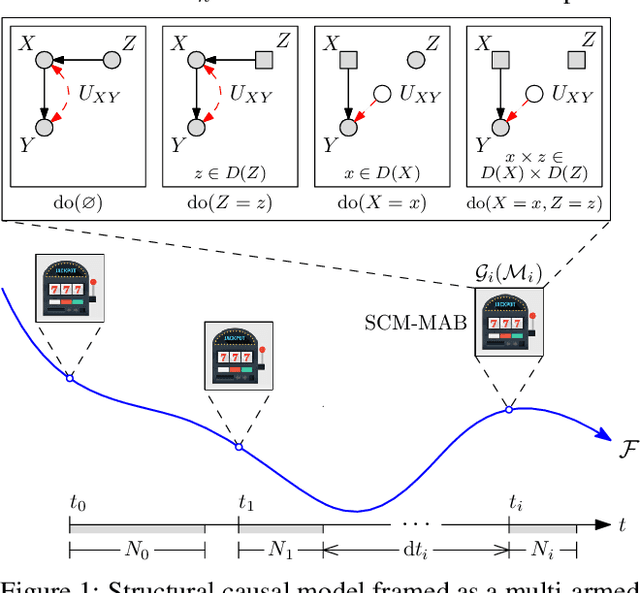
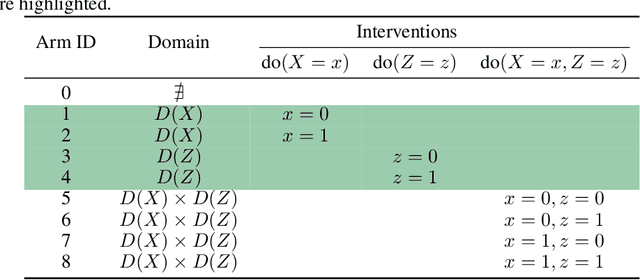
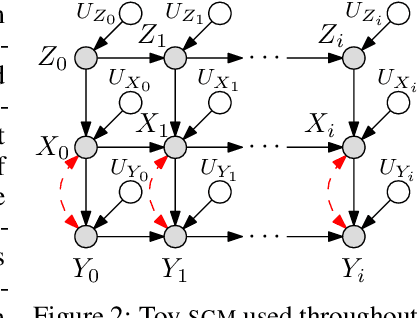

This paper studies an instance of the multi-armed bandit (MAB) problem, specifically where several causal MABs operate chronologically in the same dynamical system. Practically the reward distribution of each bandit is governed by the same non-trivial dependence structure, which is a dynamic causal model. Dynamic because we allow for each causal MAB to depend on the preceding MAB and in doing so are able to transfer information between agents. Our contribution, the Chronological Causal Bandit (CCB), is useful in discrete decision-making settings where the causal effects are changing across time and can be informed by earlier interventions in the same system. In this paper, we present some early findings of the CCB as demonstrated on a toy problem.
Usability and Aesthetics: Better Together for Automated Repair of Web Pages
Jan 01, 2022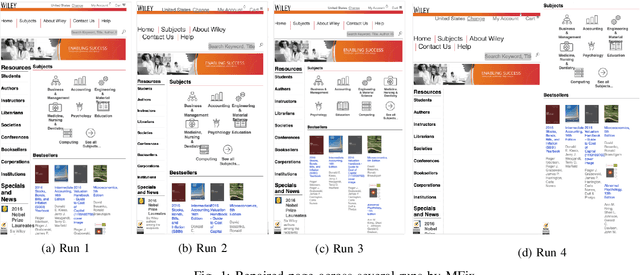
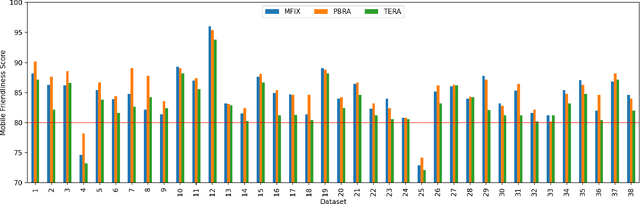
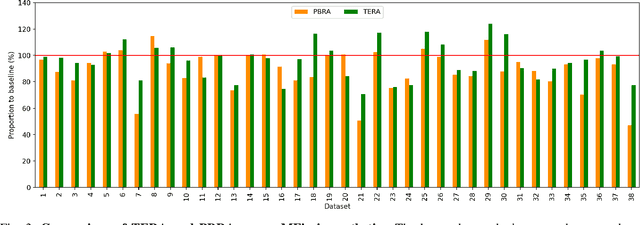
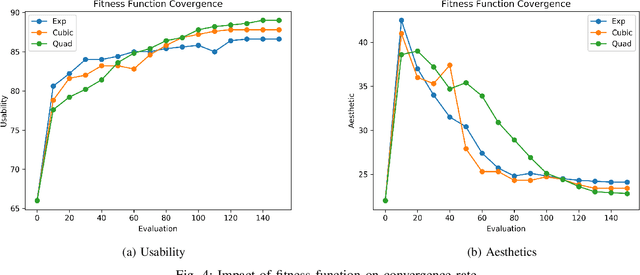
With the recent explosive growth of mobile devices such as smartphones or tablets, guaranteeing consistent web appearance across all environments has become a significant problem. This happens simply because it is hard to keep track of the web appearance on different sizes and types of devices that render the web pages. Therefore, fixing the inconsistent appearance of web pages can be difficult, and the cost incurred can be huge, e.g., poor user experience and financial loss due to it. Recently, automated web repair techniques have been proposed to automatically resolve inconsistent web page appearance, focusing on improving usability. However, generated patches tend to disrupt the webpage's layout, rendering the repaired webpage aesthetically unpleasing, e.g., distorted images or misalignment of components. In this paper, we propose an automated repair approach for web pages based on meta-heuristic algorithms that can assure both usability and aesthetics. The key novelty that empowers our approach is a novel fitness function that allows us to optimistically evolve buggy web pages to find the best solution that optimizes both usability and aesthetics at the same time. Empirical evaluations show that our approach is able to successfully resolve mobile-friendly problems in 94% of the evaluation subjects, significantly outperforming state-of-the-art baseline techniques in terms of both usability and aesthetics.
* Accepted to ISSRE 2021, Research Track
Contextual-Bandit Based Personalized Recommendation with Time-Varying User Interests
Feb 29, 2020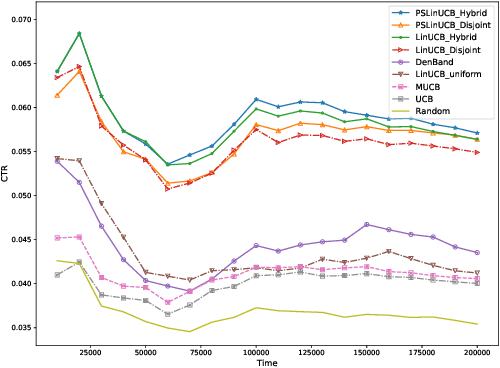
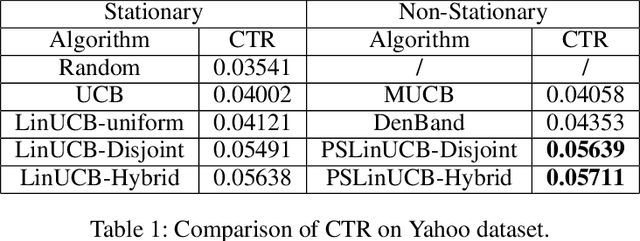
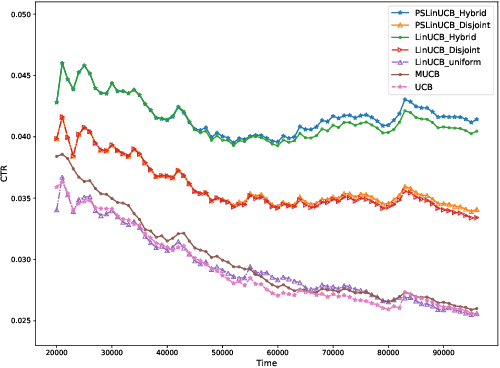
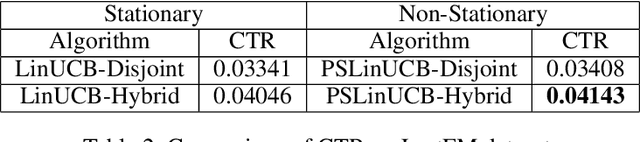
A contextual bandit problem is studied in a highly non-stationary environment, which is ubiquitous in various recommender systems due to the time-varying interests of users. Two models with disjoint and hybrid payoffs are considered to characterize the phenomenon that users' preferences towards different items vary differently over time. In the disjoint payoff model, the reward of playing an arm is determined by an arm-specific preference vector, which is piecewise-stationary with asynchronous and distinct changes across different arms. An efficient learning algorithm that is adaptive to abrupt reward changes is proposed and theoretical regret analysis is provided to show that a sublinear scaling of regret in the time length $T$ is achieved. The algorithm is further extended to a more general setting with hybrid payoffs where the reward of playing an arm is determined by both an arm-specific preference vector and a joint coefficient vector shared by all arms. Empirical experiments are conducted on real-world datasets to verify the advantages of the proposed learning algorithms against baseline ones in both settings.
A fast noise filtering algorithm for time series prediction using recurrent neural networks
Aug 12, 2020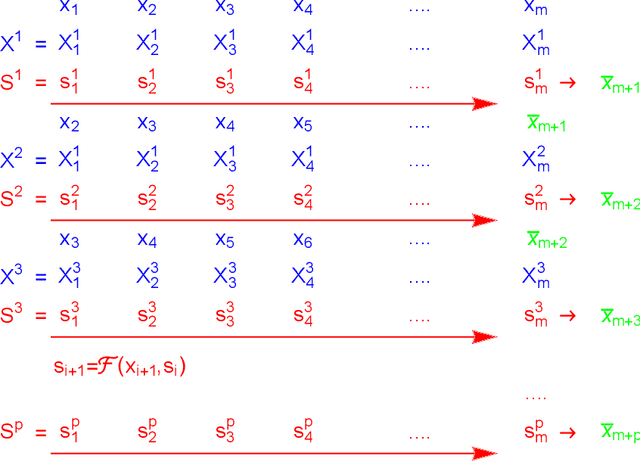

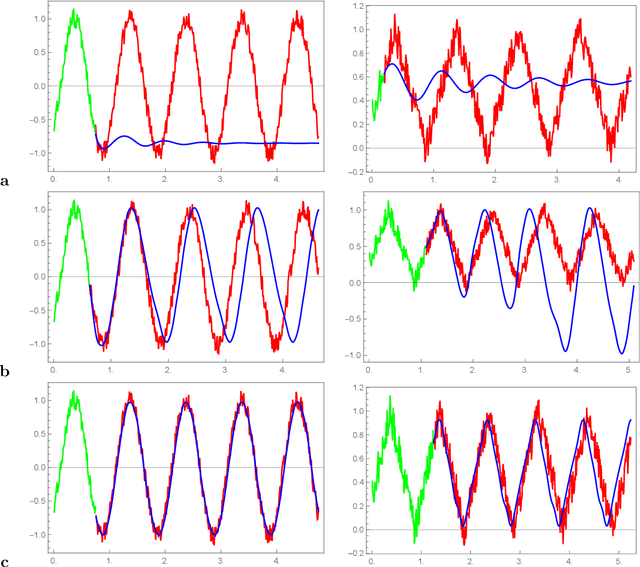
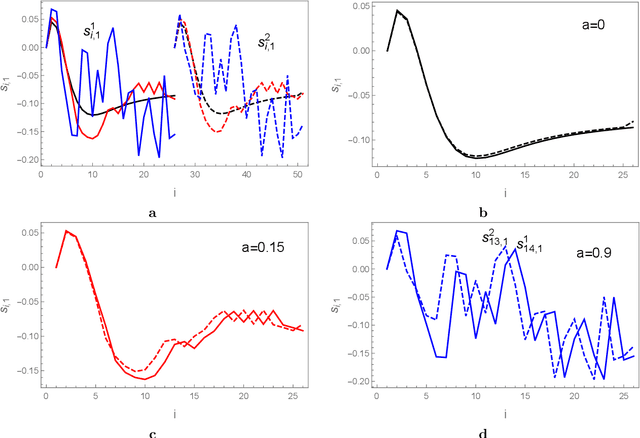
Recent research demonstrate that prediction of time series by recurrent neural networks (RNNs) based on the noisy input generates a smooth anticipated trajectory. We examine the internal dynamics of RNNs and establish a set of conditions required for such behavior. Based on this analysis we propose a new approximate algorithm and show that it significantly speeds up the predictive process without loss of accuracy.
Convergence and Complexity of Stochastic Block Majorization-Minimization
Jan 05, 2022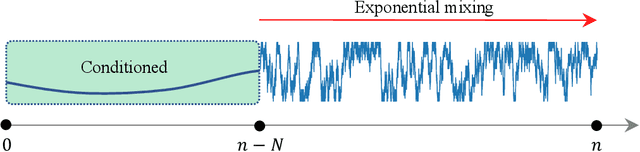
Stochastic majorization-minimization (SMM) is an online extension of the classical principle of majorization-minimization, which consists of sampling i.i.d. data points from a fixed data distribution and minimizing a recursively defined majorizing surrogate of an objective function. In this paper, we introduce stochastic block majorization-minimization, where the surrogates can now be only block multi-convex and a single block is optimized at a time within a diminishing radius. Relaxing the standard strong convexity requirements for surrogates in SMM, our framework gives wider applicability including online CANDECOMP/PARAFAC (CP) dictionary learning and yields greater computational efficiency especially when the problem dimension is large. We provide an extensive convergence analysis on the proposed algorithm, which we derive under possibly dependent data streams, relaxing the standard i.i.d. assumption on data samples. We show that the proposed algorithm converges almost surely to the set of stationary points of a nonconvex objective under constraints at a rate $O((\log n)^{1+\eps}/n^{1/2})$ for the empirical loss function and $O((\log n)^{1+\eps}/n^{1/4})$ for the expected loss function, where $n$ denotes the number of data samples processed. Under some additional assumption, the latter convergence rate can be improved to $O((\log n)^{1+\eps}/n^{1/2})$. Our results provide first convergence rate bounds for various online matrix and tensor decomposition algorithms under a general Markovian data setting.
Scalable Geometric Deep Learning on Molecular Graphs
Dec 06, 2021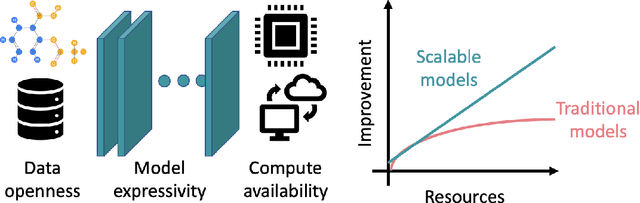

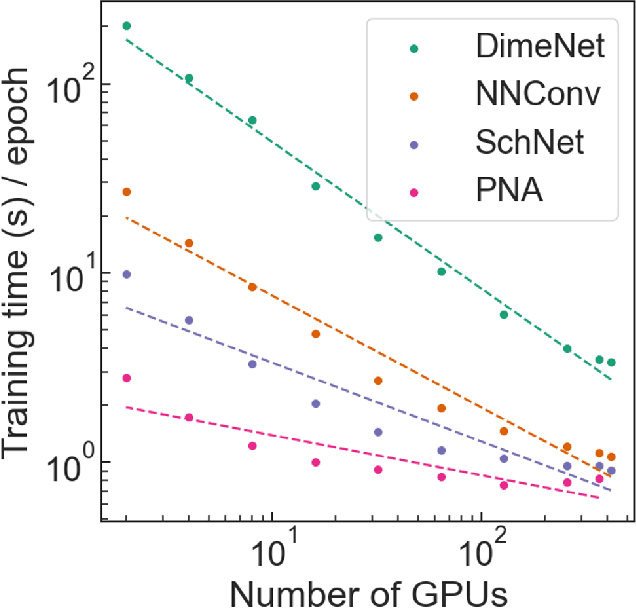
Deep learning in molecular and materials sciences is limited by the lack of integration between applied science, artificial intelligence, and high-performance computing. Bottlenecks with respect to the amount of training data, the size and complexity of model architectures, and the scale of the compute infrastructure are all key factors limiting the scaling of deep learning for molecules and materials. Here, we present $\textit{LitMatter}$, a lightweight framework for scaling molecular deep learning methods. We train four graph neural network architectures on over 400 GPUs and investigate the scaling behavior of these methods. Depending on the model architecture, training time speedups up to $60\times$ are seen. Empirical neural scaling relations quantify the model-dependent scaling and enable optimal compute resource allocation and the identification of scalable molecular geometric deep learning model implementations.
Finite-Time Analysis of Decentralized Stochastic Approximation with Applications in Multi-Agent and Multi-Task Learning
Oct 28, 2020

Stochastic approximation, a data-driven approach for finding the fixed point of an unknown operator, provides a unified framework for treating many problems in stochastic optimization and reinforcement learning. Motivated by a growing interest in multi-agent and multi-task learning, we consider in this paper a decentralized variant of stochastic approximation. A network of agents, each with their own unknown operator and data observations, cooperatively find the fixed point of the aggregate operator. The agents work by running a local stochastic approximation algorithm using noisy samples from their operators while averaging their iterates with their neighbors' on a decentralized communication graph. Our main contribution provides a finite-time analysis of this decentralized stochastic approximation algorithm and characterizes the impacts of the underlying communication topology between agents. Our model for the data observed at each agent is that it is sampled from a Markov processes; this lack of independence makes the iterates biased and (potentially) unbounded. Under mild assumptions on the Markov processes, we show that the convergence rate of the proposed methods is essentially the same as if the samples were independent, differing only by a log factor that represents the mixing time of the Markov process. We also present applications of the proposed method on a number of interesting learning problems in multi-agent systems, including a decentralized variant of Q-learning for solving multi-task reinforcement learning.
Analytical Shaping Method for Low-Thrust Rendezvous Trajectory Using Cubic Spline Functions
Jan 01, 2022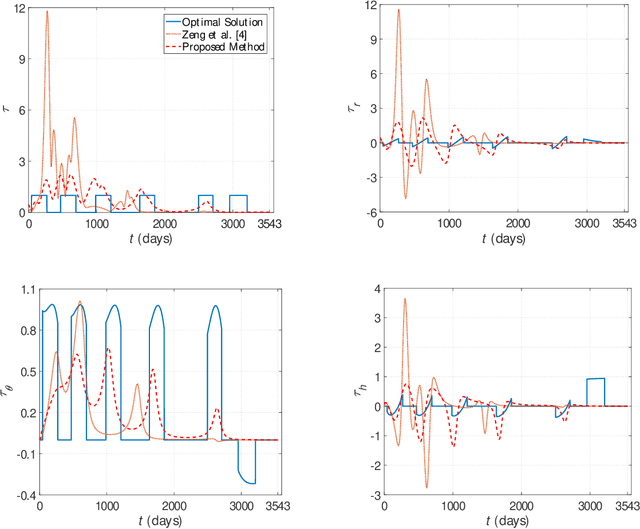
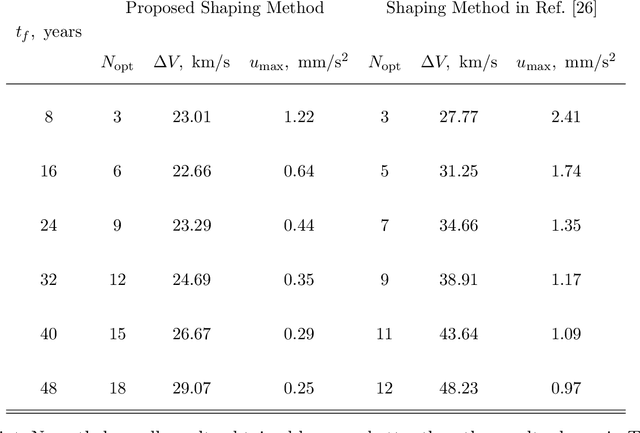
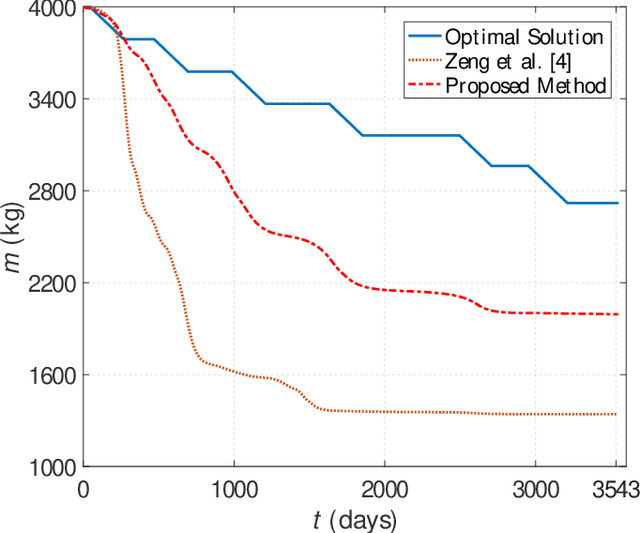
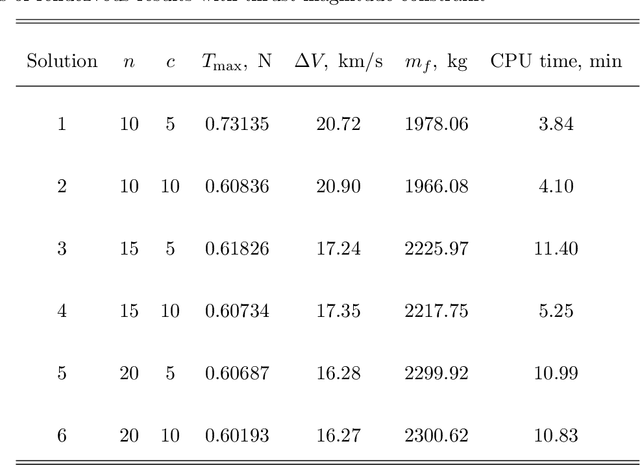
Preliminary mission design requires an efficient and accurate approximation to the low-thrust rendezvous trajectories, which might be generally three-dimensional and involve multiple revolutions. In this paper, a new shaping method using cubic spline functions is developed for the analytical approximation, which shows advantages in the optimality and computational efficiency. The rendezvous constraints on the boundary states and transfer time are all satisfied analytically, under the assumption that the boundary conditions and segment numbers of cubic spline functions are designated in advance. Two specific shapes are then formulated according to whether they have free optimization parameters. The shape without free parameters provides an efficient and robust estimation, while the other one allows a subsequent optimization for the satisfaction of additional constraints such as the constraint on the thrust magnitude. Applications of the proposed method in combination with the particle swarm optimization algorithm are discussed through two typical interplanetary rendezvous missions, that is, an inclined multi-revolution trajectory from the Earth to asteroid Dionysus and a multi-rendezvous trajectory of sample return. Simulation examples show that the proposed method is superior to existing methods in terms of providing good estimation for the global search and generating suitable initial guess for the subsequent trajectory optimization.
Learning to Minimize Cost-to-Serve for Multi-Node Multi-Product Order Fulfilment in Electronic Commerce
Dec 16, 2021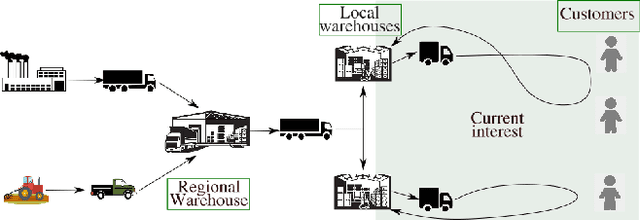
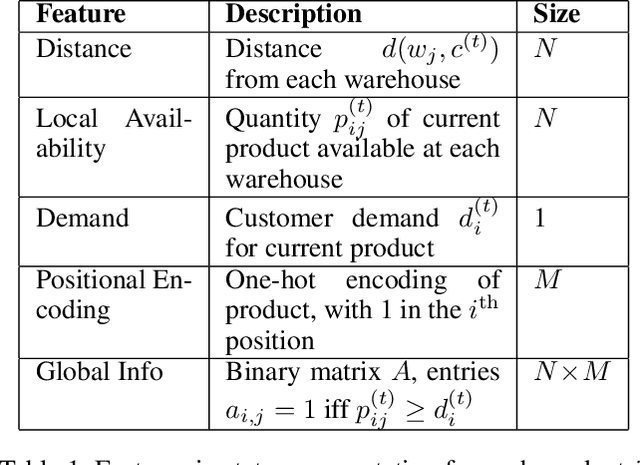
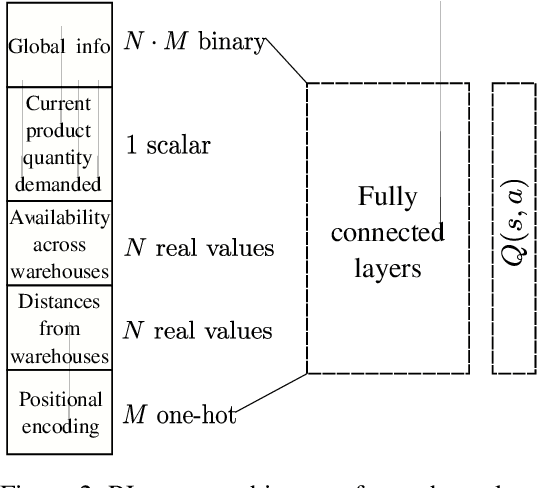
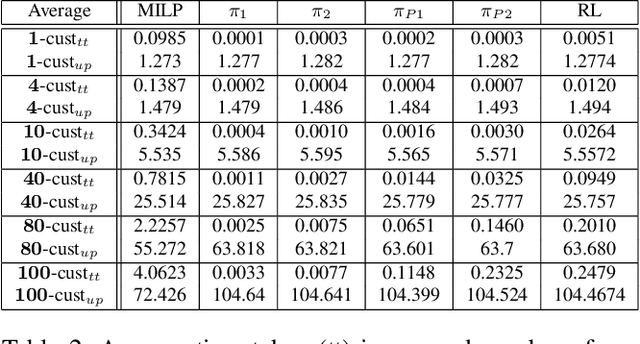
We describe a novel decision-making problem developed in response to the demands of retail electronic commerce (e-commerce). While working with logistics and retail industry business collaborators, we found that the cost of delivery of products from the most opportune node in the supply chain (a quantity called the cost-to-serve or CTS) is a key challenge. The large scale, high stochasticity, and large geographical spread of e-commerce supply chains make this setting ideal for a carefully designed data-driven decision-making algorithm. In this preliminary work, we focus on the specific subproblem of delivering multiple products in arbitrary quantities from any warehouse to multiple customers in each time period. We compare the relative performance and computational efficiency of several baselines, including heuristics and mixed-integer linear programming. We show that a reinforcement learning based algorithm is competitive with these policies, with the potential of efficient scale-up in the real world.
Performance optimizations on deep noise suppression models
Oct 08, 2021
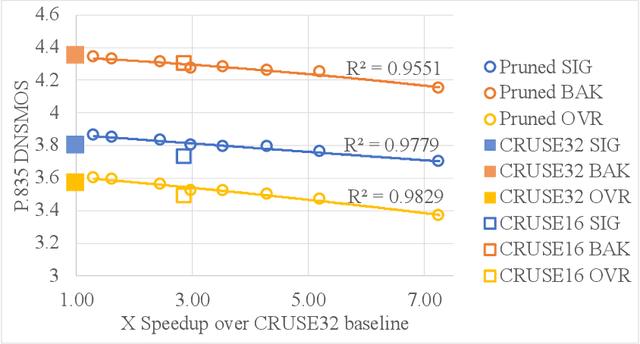
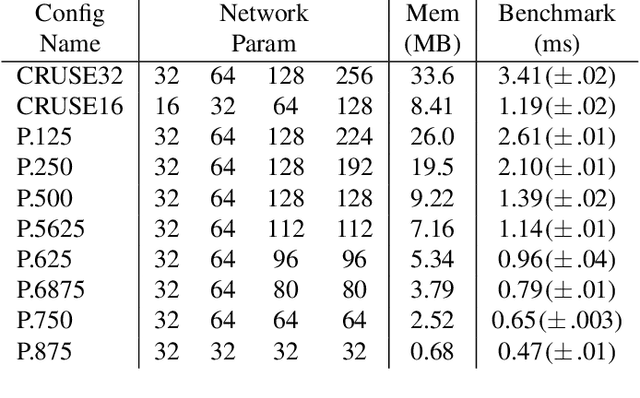
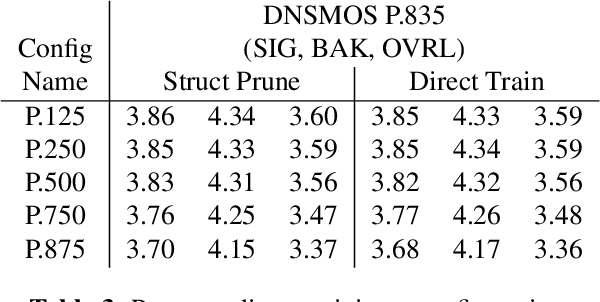
We study the role of magnitude structured pruning as an architecture search to speed up the inference time of a deep noise suppression (DNS) model. While deep learning approaches have been remarkably successful in enhancing audio quality, their increased complexity inhibits their deployment in real-time applications. We achieve up to a 7.25X inference speedup over the baseline, with a smooth model performance degradation. Ablation studies indicate that our proposed network re-parameterization (i.e., size per layer) is the major driver of the speedup, and that magnitude structured pruning does comparably to directly training a model in the smaller size. We report inference speed because a parameter reduction does not necessitate speedup, and we measure model quality using an accurate non-intrusive objective speech quality metric.