 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Koopman Invariant Subspaces via Personalized PageRank
May 27, 2026Selecting a finite dictionary of observables whose span is Koopman-invariant is a central challenge in data-driven Koopman operator approximation. We address this problem by exploiting zero-block structure in Extended Dynamic Mode Decomposition (EDMD) matrices. We show that any sub-dictionary whose span is Koopman-invariant induces an exact zero block in the EDMD matrix, even for finite data. We then show that such blocks can be detected by applying PageRank to a row-normalized EDMD matrix constructed from a large initial dictionary. The theory extends to approximately invariant subspaces and yields stronger guarantees for personalized PageRank (PPR) when the seed observables lie inside the target block and reach all observables in that block. Combining EDMD concentration bounds with PageRank perturbation theory gives end-to-end detection guarantees with $O(1/\sqrt{M})$ finite-sample scaling and explicit constants. More generally, without assuming an invariant subspace exists, high PPR mass on a sub-dictionary controls discounted multi-step leakage from the seed observables. Numerical experiments on the Duffing oscillator, Van der Pol oscillator, Lorenz system, and a three-well Ramachandran potential suggest that the method identifies compact, interpretable dictionaries with accurate predictions.
Convergence and Complexity Guarantee for Inexact First-order Riemannian Optimization Algorithms
May 05, 2024



We analyze inexact Riemannian gradient descent (RGD) where Riemannian gradients and retractions are inexactly (and cheaply) computed. Our focus is on understanding when inexact RGD converges and what is the complexity in the general nonconvex and constrained setting. We answer these questions in a general framework of tangential Block Majorization-Minimization (tBMM). We establish that tBMM converges to an $\epsilon$-stationary point within $O(\epsilon^{-2})$ iterations. Under a mild assumption, the results still hold when the subproblem is solved inexactly in each iteration provided the total optimality gap is bounded. Our general analysis applies to a wide range of classical algorithms with Riemannian constraints including inexact RGD and proximal gradient method on Stiefel manifolds. We numerically validate that tBMM shows improved performance over existing methods when applied to various problems, including nonnegative tensor decomposition with Riemannian constraints, regularized nonnegative matrix factorization, and low-rank matrix recovery problems.
On the Complexity of First-Order Methods in Stochastic Bilevel Optimization
Feb 11, 2024We consider the problem of finding stationary points in Bilevel optimization when the lower-level problem is unconstrained and strongly convex. The problem has been extensively studied in recent years; the main technical challenge is to keep track of lower-level solutions $y^*(x)$ in response to the changes in the upper-level variables $x$. Subsequently, all existing approaches tie their analyses to a genie algorithm that knows lower-level solutions and, therefore, need not query any points far from them. We consider a dual question to such approaches: suppose we have an oracle, which we call $y^*$-aware, that returns an $O(\epsilon)$-estimate of the lower-level solution, in addition to first-order gradient estimators {\it locally unbiased} within the $\Theta(\epsilon)$-ball around $y^*(x)$. We study the complexity of finding stationary points with such an $y^*$-aware oracle: we propose a simple first-order method that converges to an $\epsilon$ stationary point using $O(\epsilon^{-6}), O(\epsilon^{-4})$ access to first-order $y^*$-aware oracles. Our upper bounds also apply to standard unbiased first-order oracles, improving the best-known complexity of first-order methods by $O(\epsilon)$ with minimal assumptions. We then provide the matching $\Omega(\epsilon^{-6})$, $\Omega(\epsilon^{-4})$ lower bounds without and with an additional smoothness assumption on $y^*$-aware oracles, respectively. Our results imply that any approach that simulates an algorithm with an $y^*$-aware oracle must suffer the same lower bounds.
Stochastic optimization with arbitrary recurrent data sampling
Jan 15, 2024



For obtaining optimal first-order convergence guarantee for stochastic optimization, it is necessary to use a recurrent data sampling algorithm that samples every data point with sufficient frequency. Most commonly used data sampling algorithms (e.g., i.i.d., MCMC, random reshuffling) are indeed recurrent under mild assumptions. In this work, we show that for a particular class of stochastic optimization algorithms, we do not need any other property (e.g., independence, exponential mixing, and reshuffling) than recurrence in data sampling algorithms to guarantee the optimal rate of first-order convergence. Namely, using regularized versions of Minimization by Incremental Surrogate Optimization (MISO), we show that for non-convex and possibly non-smooth objective functions, the expected optimality gap converges at an optimal rate $O(n^{-1/2})$ under general recurrent sampling schemes. Furthermore, the implied constant depends explicitly on the `speed of recurrence', measured by the expected amount of time to visit a given data point either averaged (`target time') or supremized (`hitting time') over the current location. We demonstrate theoretically and empirically that convergence can be accelerated by selecting sampling algorithms that cover the data set most effectively. We discuss applications of our general framework to decentralized optimization and distributed non-negative matrix factorization.
Convergence and complexity of block majorization-minimization for constrained block-Riemannian optimization
Dec 16, 2023



Block majorization-minimization (BMM) is a simple iterative algorithm for nonconvex optimization that sequentially minimizes a majorizing surrogate of the objective function in each block coordinate while the other block coordinates are held fixed. We consider a family of BMM algorithms for minimizing smooth nonconvex objectives, where each parameter block is constrained within a subset of a Riemannian manifold. We establish that this algorithm converges asymptotically to the set of stationary points, and attains an $\epsilon$-stationary point within $\widetilde{O}(\epsilon^{-2})$ iterations. In particular, the assumptions for our complexity results are completely Euclidean when the underlying manifold is a product of Euclidean or Stiefel manifolds, although our analysis makes explicit use of the Riemannian geometry. Our general analysis applies to a wide range of algorithms with Riemannian constraints: Riemannian MM, block projected gradient descent, optimistic likelihood estimation, geodesically constrained subspace tracking, robust PCA, and Riemannian CP-dictionary-learning. We experimentally validate that our algorithm converges faster than standard Euclidean algorithms applied to the Riemannian setting.
A latent linear model for nonlinear coupled oscillators on graphs
Nov 25, 2023



A system of coupled oscillators on an arbitrary graph is locally driven by the tendency to mutual synchronization between nearby oscillators, but can and often exhibit nonlinear behavior on the whole graph. Understanding such nonlinear behavior has been a key challenge in predicting whether all oscillators in such a system will eventually synchronize. In this paper, we demonstrate that, surprisingly, such nonlinear behavior of coupled oscillators can be effectively linearized in certain latent dynamic spaces. The key insight is that there is a small number of `latent dynamics filters', each with a specific association with synchronizing and non-synchronizing dynamics on subgraphs so that any observed dynamics on subgraphs can be approximated by a suitable linear combination of such elementary dynamic patterns. Taking an ensemble of subgraph-level predictions provides an interpretable predictor for whether the system on the whole graph reaches global synchronization. We propose algorithms based on supervised matrix factorization to learn such latent dynamics filters. We demonstrate that our method performs competitively in synchronization prediction tasks against baselines and black-box classification algorithms, despite its simple and interpretable architecture.
Exponentially Convergent Algorithms for Supervised Matrix Factorization
Nov 18, 2023


Supervised matrix factorization (SMF) is a classical machine learning method that simultaneously seeks feature extraction and classification tasks, which are not necessarily a priori aligned objectives. Our goal is to use SMF to learn low-rank latent factors that offer interpretable, data-reconstructive, and class-discriminative features, addressing challenges posed by high-dimensional data. Training SMF model involves solving a nonconvex and possibly constrained optimization with at least three blocks of parameters. Known algorithms are either heuristic or provide weak convergence guarantees for special cases. In this paper, we provide a novel framework that 'lifts' SMF as a low-rank matrix estimation problem in a combined factor space and propose an efficient algorithm that provably converges exponentially fast to a global minimizer of the objective with arbitrary initialization under mild assumptions. Our framework applies to a wide range of SMF-type problems for multi-class classification with auxiliary features. To showcase an application, we demonstrate that our algorithm successfully identified well-known cancer-associated gene groups for various cancers.
* 33 pages, 3 figures. arXiv admin note: substantial text overlap with arXiv:2206.06774
Supervised low-rank semi-nonnegative matrix factorization with frequency regularization for forecasting spatio-temporal data
Nov 15, 2023We propose a novel methodology for forecasting spatio-temporal data using supervised semi-nonnegative matrix factorization (SSNMF) with frequency regularization. Matrix factorization is employed to decompose spatio-temporal data into spatial and temporal components. To improve clarity in the temporal patterns, we introduce a nonnegativity constraint on the time domain along with regularization in the frequency domain. Specifically, regularization in the frequency domain involves selecting features in the frequency space, making an interpretation in the frequency domain more convenient. We propose two methods in the frequency domain: soft and hard regularizations, and provide convergence guarantees to first-order stationary points of the corresponding constrained optimization problem. While our primary motivation stems from geophysical data analysis based on GRACE (Gravity Recovery and Climate Experiment) data, our methodology has the potential for wider application. Consequently, when applying our methodology to GRACE data, we find that the results with the proposed methodology are comparable to previous research in the field of geophysical sciences but offer clearer interpretability.
Complexity of Block Coordinate Descent with Proximal Regularization and Applications to Wasserstein CP-dictionary Learning
Jun 04, 2023



We consider the block coordinate descent methods of Gauss-Seidel type with proximal regularization (BCD-PR), which is a classical method of minimizing general nonconvex objectives under constraints that has a wide range of practical applications. We theoretically establish the worst-case complexity bound for this algorithm. Namely, we show that for general nonconvex smooth objectives with block-wise constraints, the classical BCD-PR algorithm converges to an epsilon-stationary point within O(1/epsilon) iterations. Under a mild condition, this result still holds even if the algorithm is executed inexactly in each step. As an application, we propose a provable and efficient algorithm for `Wasserstein CP-dictionary learning', which seeks a set of elementary probability distributions that can well-approximate a given set of d-dimensional joint probability distributions. Our algorithm is a version of BCD-PR that operates in the dual space, where the primal problem is regularized both entropically and proximally.
Supervised Dictionary Learning with Auxiliary Covariates
Jun 14, 2022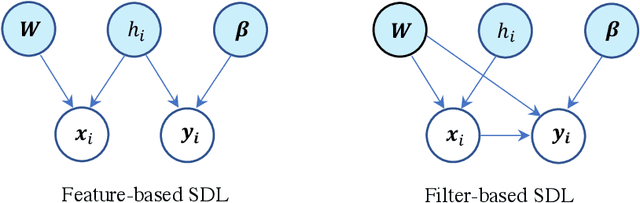

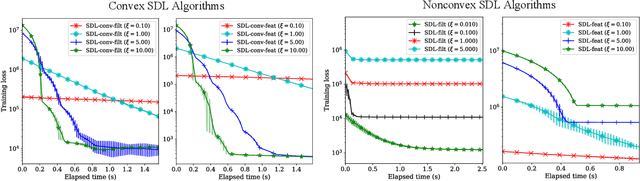
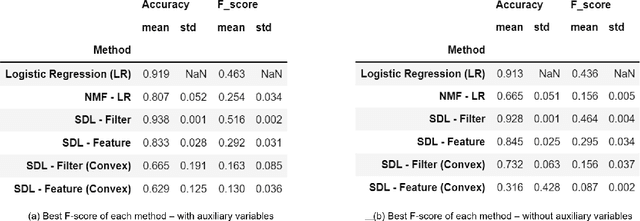
Supervised dictionary learning (SDL) is a classical machine learning method that simultaneously seeks feature extraction and classification tasks, which are not necessarily a priori aligned objectives. The goal of SDL is to learn a class-discriminative dictionary, which is a set of latent feature vectors that can well-explain both the features as well as labels of observed data. In this paper, we provide a systematic study of SDL, including the theory, algorithm, and applications of SDL. First, we provide a novel framework that `lifts' SDL as a convex problem in a combined factor space and propose a low-rank projected gradient descent algorithm that converges exponentially to the global minimizer of the objective. We also formulate generative models of SDL and provide global estimation guarantees of the true parameters depending on the hyperparameter regime. Second, viewed as a nonconvex constrained optimization problem, we provided an efficient block coordinate descent algorithm for SDL that is guaranteed to find an $\varepsilon$-stationary point of the objective in $O(\varepsilon^{-1}(\log \varepsilon^{-1})^{2})$ iterations. For the corresponding generative model, we establish a novel non-asymptotic local consistency result for constrained and regularized maximum likelihood estimation problems, which may be of independent interest. Third, we apply SDL for imbalanced document classification by supervised topic modeling and also for pneumonia detection from chest X-ray images. We also provide simulation studies to demonstrate that SDL becomes more effective when there is a discrepancy between the best reconstructive and the best discriminative dictionaries.