 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSustainable Supercomputing for AI: GPU Power Capping at HPC Scale
Feb 25, 2024



As research and deployment of AI grows, the computational burden to support and sustain its progress inevitably does too. To train or fine-tune state-of-the-art models in NLP, computer vision, etc., some form of AI hardware acceleration is virtually a requirement. Recent large language models require considerable resources to train and deploy, resulting in significant energy usage, potential carbon emissions, and massive demand for GPUs and other hardware accelerators. However, this surge carries large implications for energy sustainability at the HPC/datacenter level. In this paper, we study the aggregate effect of power-capping GPUs on GPU temperature and power draw at a research supercomputing center. With the right amount of power-capping, we show significant decreases in both temperature and power draw, reducing power consumption and potentially improving hardware life-span with minimal impact on job performance. While power-capping reduces power draw by design, the aggregate system-wide effect on overall energy consumption is less clear; for instance, if users notice job performance degradation from GPU power-caps, they may request additional GPU-jobs to compensate, negating any energy savings or even worsening energy consumption. To our knowledge, our work is the first to conduct and make available a detailed analysis of the effects of GPU power-capping at the supercomputing scale. We hope our work will inspire HPCs/datacenters to further explore, evaluate, and communicate the impact of power-capping AI hardware accelerators for more sustainable AI.
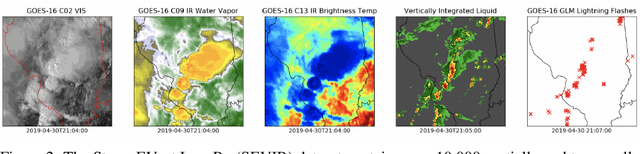
A Benchmark Dataset for Tornado Detection and Prediction using Full-Resolution Polarimetric Weather Radar Data
Jan 26, 2024Weather radar is the primary tool used by forecasters to detect and warn for tornadoes in near-real time. In order to assist forecasters in warning the public, several algorithms have been developed to automatically detect tornadic signatures in weather radar observations. Recently, Machine Learning (ML) algorithms, which learn directly from large amounts of labeled data, have been shown to be highly effective for this purpose. Since tornadoes are extremely rare events within the corpus of all available radar observations, the selection and design of training datasets for ML applications is critical for the performance, robustness, and ultimate acceptance of ML algorithms. This study introduces a new benchmark dataset, TorNet to support development of ML algorithms in tornado detection and prediction. TorNet contains full-resolution, polarimetric, Level-II WSR-88D data sampled from 10 years of reported storm events. A number of ML baselines for tornado detection are developed and compared, including a novel deep learning (DL) architecture capable of processing raw radar imagery without the need for manual feature extraction required for existing ML algorithms. Despite not benefiting from manual feature engineering or other preprocessing, the DL model shows increased detection performance compared to non-DL and operational baselines. The TorNet dataset, as well as source code and model weights of the DL baseline trained in this work, are made freely available.
Lincoln AI Computing Survey (LAICS) Update
Oct 13, 2023


This paper is an update of the survey of AI accelerators and processors from past four years, which is now called the Lincoln AI Computing Survey - LAICS (pronounced "lace"). As in past years, this paper collects and summarizes the current commercial accelerators that have been publicly announced with peak performance and peak power consumption numbers. The performance and power values are plotted on a scatter graph, and a number of dimensions and observations from the trends on this plot are again discussed and analyzed. Market segments are highlighted on the scatter plot, and zoomed plots of each segment are also included. Finally, a brief description of each of the new accelerators that have been added in the survey this year is included.
From Words to Watts: Benchmarking the Energy Costs of Large Language Model Inference
Oct 04, 2023



Large language models (LLMs) have exploded in popularity due to their new generative capabilities that go far beyond prior state-of-the-art. These technologies are increasingly being leveraged in various domains such as law, finance, and medicine. However, these models carry significant computational challenges, especially the compute and energy costs required for inference. Inference energy costs already receive less attention than the energy costs of training LLMs -- despite how often these large models are called on to conduct inference in reality (e.g., ChatGPT). As these state-of-the-art LLMs see increasing usage and deployment in various domains, a better understanding of their resource utilization is crucial for cost-savings, scaling performance, efficient hardware usage, and optimal inference strategies. In this paper, we describe experiments conducted to study the computational and energy utilization of inference with LLMs. We benchmark and conduct a preliminary analysis of the inference performance and inference energy costs of different sizes of LLaMA -- a recent state-of-the-art LLM -- developed by Meta AI on two generations of popular GPUs (NVIDIA V100 \& A100) and two datasets (Alpaca and GSM8K) to reflect the diverse set of tasks/benchmarks for LLMs in research and practice. We present the results of multi-node, multi-GPU inference using model sharding across up to 32 GPUs. To our knowledge, our work is the one of the first to study LLM inference performance from the perspective of computational and energy resources at this scale.
A Green(er) World for A.I
Jan 27, 2023



As research and practice in artificial intelligence (A.I.) grow in leaps and bounds, the resources necessary to sustain and support their operations also grow at an increasing pace. While innovations and applications from A.I. have brought significant advances, from applications to vision and natural language to improvements to fields like medical imaging and materials engineering, their costs should not be neglected. As we embrace a world with ever-increasing amounts of data as well as research and development of A.I. applications, we are sure to face an ever-mounting energy footprint to sustain these computational budgets, data storage needs, and more. But, is this sustainable and, more importantly, what kind of setting is best positioned to nurture such sustainable A.I. in both research and practice? In this paper, we outline our outlook for Green A.I. -- a more sustainable, energy-efficient and energy-aware ecosystem for developing A.I. across the research, computing, and practitioner communities alike -- and the steps required to arrive there. We present a bird's eye view of various areas for potential changes and improvements from the ground floor of AI's operational and hardware optimizations for datacenters/HPCs to the current incentive structures in the world of A.I. research and practice, and more. We hope these points will spur further discussion, and action, on some of these issues and their potential solutions.
* 8 pages, published in 2022 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW)
Building Heterogeneous Cloud System for Machine Learning Inference
Oct 15, 2022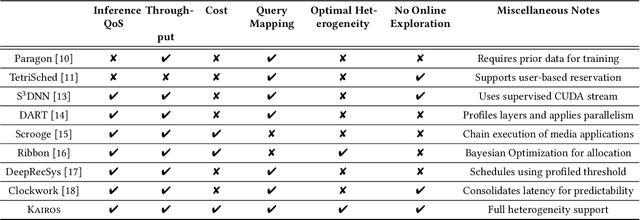
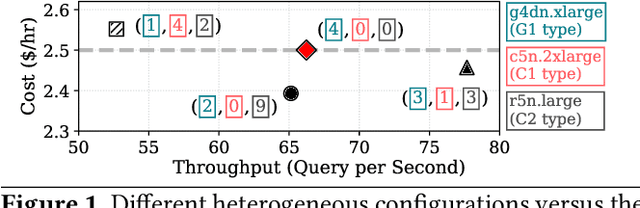
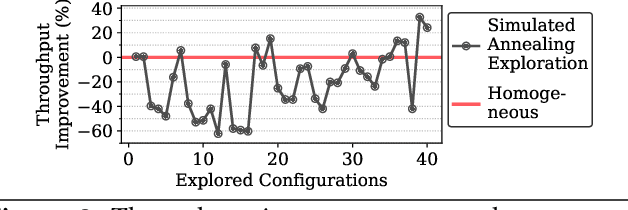

Online inference is becoming a key service product for many businesses, deployed in cloud platforms to meet customer demands. Despite their revenue-generation capability, these services need to operate under tight Quality-of-Service (QoS) and cost budget constraints. This paper introduces KAIROS, a novel runtime framework that maximizes the query throughput while meeting QoS target and a cost budget. KAIROS designs and implements novel techniques to build a pool of heterogeneous compute hardware without online exploration overhead, and distribute inference queries optimally at runtime. Our evaluation using industry-grade deep learning (DL) models shows that KAIROS yields up to 2X the throughput of an optimal homogeneous solution, and outperforms state-of-the-art schemes by up to 70%, despite advantageous implementations of the competing schemes to ignore their exploration overhead.
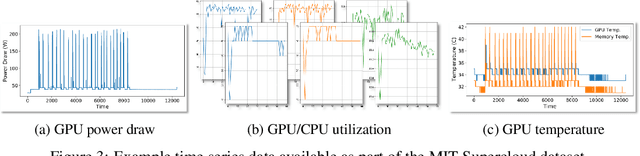
An Evaluation of Low Overhead Time Series Preprocessing Techniques for Downstream Machine Learning
Sep 12, 2022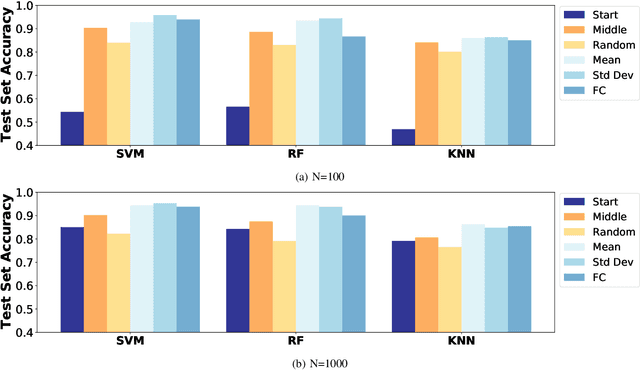
In this paper we address the application of pre-processing techniques to multi-channel time series data with varying lengths, which we refer to as the alignment problem, for downstream machine learning. The misalignment of multi-channel time series data may occur for a variety of reasons, such as missing data, varying sampling rates, or inconsistent collection times. We consider multi-channel time series data collected from the MIT SuperCloud High Performance Computing (HPC) center, where different job start times and varying run times of HPC jobs result in misaligned data. This misalignment makes it challenging to build AI/ML approaches for tasks such as compute workload classification. Building on previous supervised classification work with the MIT SuperCloud Dataset, we address the alignment problem via three broad, low overhead approaches: sampling a fixed subset from a full time series, performing summary statistics on a full time series, and sampling a subset of coefficients from time series mapped to the frequency domain. Our best performing models achieve a classification accuracy greater than 95%, outperforming previous approaches to multi-channel time series classification with the MIT SuperCloud Dataset by 5%. These results indicate our low overhead approaches to solving the alignment problem, in conjunction with standard machine learning techniques, are able to achieve high levels of classification accuracy, and serve as a baseline for future approaches to addressing the alignment problem, such as kernel methods.
Developing a Series of AI Challenges for the United States Department of the Air Force
Jul 14, 2022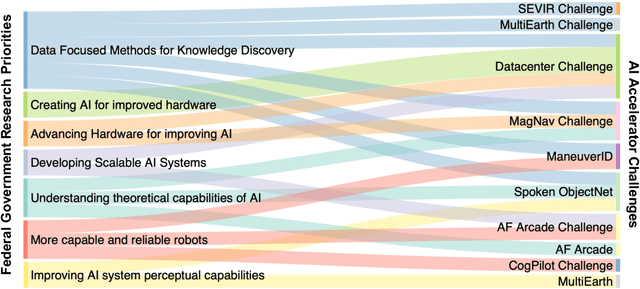

Through a series of federal initiatives and orders, the U.S. Government has been making a concerted effort to ensure American leadership in AI. These broad strategy documents have influenced organizations such as the United States Department of the Air Force (DAF). The DAF-MIT AI Accelerator is an initiative between the DAF and MIT to bridge the gap between AI researchers and DAF mission requirements. Several projects supported by the DAF-MIT AI Accelerator are developing public challenge problems that address numerous Federal AI research priorities. These challenges target priorities by making large, AI-ready datasets publicly available, incentivizing open-source solutions, and creating a demand signal for dual use technologies that can stimulate further research. In this article, we describe these public challenges being developed and how their application contributes to scientific advances.
Great Power, Great Responsibility: Recommendations for Reducing Energy for Training Language Models
May 19, 2022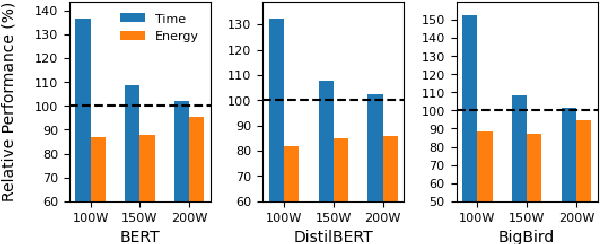

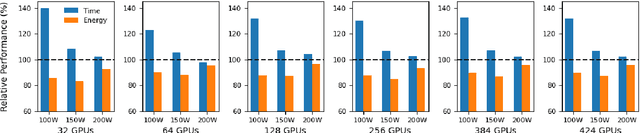
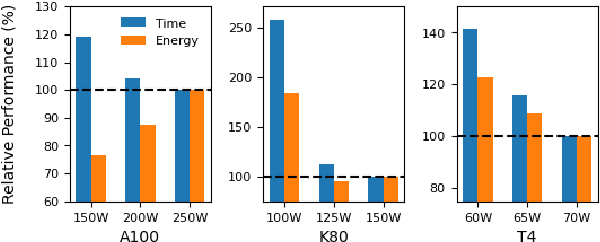
The energy requirements of current natural language processing models continue to grow at a rapid, unsustainable pace. Recent works highlighting this problem conclude there is an urgent need for methods that reduce the energy needs of NLP and machine learning more broadly. In this article, we investigate techniques that can be used to reduce the energy consumption of common NLP applications. In particular, we focus on techniques to measure energy usage and different hardware and datacenter-oriented settings that can be tuned to reduce energy consumption for training and inference for language models. We characterize the impact of these settings on metrics such as computational performance and energy consumption through experiments conducted on a high performance computing system as well as popular cloud computing platforms. These techniques can lead to significant reduction in energy consumption when training language models or their use for inference. For example, power-capping, which limits the maximum power a GPU can consume, can enable a 15\% decrease in energy usage with marginal increase in overall computation time when training a transformer-based language model.
The MIT Supercloud Workload Classification Challenge
Apr 13, 2022

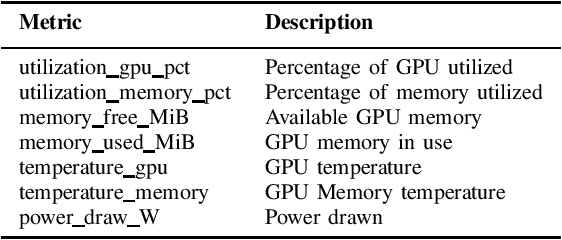
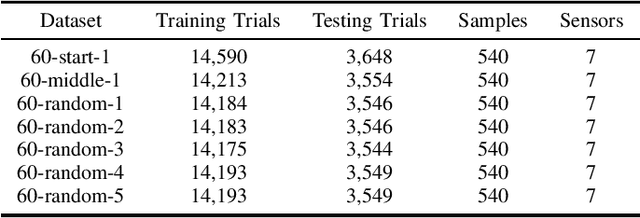
High-Performance Computing (HPC) centers and cloud providers support an increasingly diverse set of applications on heterogenous hardware. As Artificial Intelligence (AI) and Machine Learning (ML) workloads have become an increasingly larger share of the compute workloads, new approaches to optimized resource usage, allocation, and deployment of new AI frameworks are needed. By identifying compute workloads and their utilization characteristics, HPC systems may be able to better match available resources with the application demand. By leveraging datacenter instrumentation, it may be possible to develop AI-based approaches that can identify workloads and provide feedback to researchers and datacenter operators for improving operational efficiency. To enable this research, we released the MIT Supercloud Dataset, which provides detailed monitoring logs from the MIT Supercloud cluster. This dataset includes CPU and GPU usage by jobs, memory usage, and file system logs. In this paper, we present a workload classification challenge based on this dataset. We introduce a labelled dataset that can be used to develop new approaches to workload classification and present initial results based on existing approaches. The goal of this challenge is to foster algorithmic innovations in the analysis of compute workloads that can achieve higher accuracy than existing methods. Data and code will be made publicly available via the Datacenter Challenge website : https://dcc.mit.edu.