 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning with Multiple Data Set: A Weighted Goal Programming Approach
Dec 17, 2021
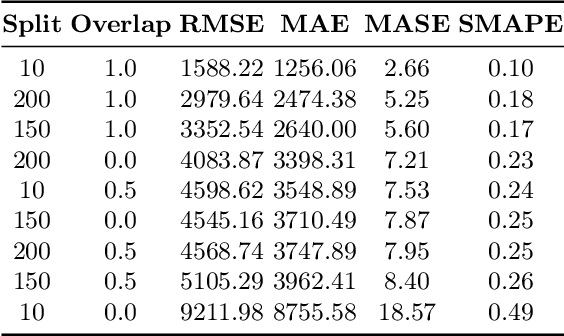
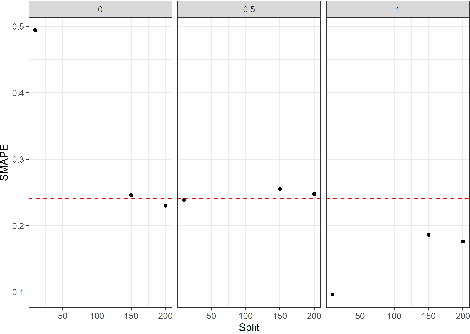
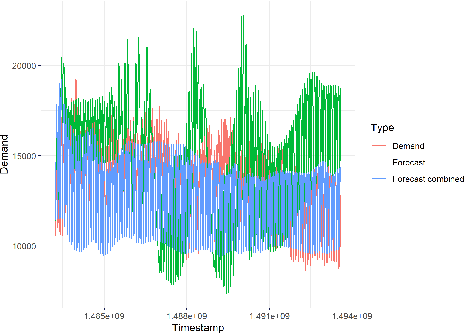
Large-scale data analysis is growing at an exponential rate as data proliferates in our societies. This abundance of data has the advantage of allowing the decision-maker to implement complex models in scenarios that were prohibitive before. At the same time, such an amount of data requires a distributed thinking approach. In fact, Deep Learning models require plenty of resources, and distributed training is needed. This paper presents a Multicriteria approach for distributed learning. Our approach uses the Weighted Goal Programming approach in its Chebyshev formulation to build an ensemble of decision rules that optimize aprioristically defined performance metrics. Such a formulation is beneficial because it is both model and metric agnostic and provides an interpretable output for the decision-maker. We test our approach by showing a practical application in electricity demand forecasting. Our results suggest that when we allow for dataset split overlapping, the performances of our methodology are consistently above the baseline model trained on the whole dataset.
An Approach for Combining Multimodal Fusion and Neural Architecture Search Applied to Knowledge Tracing
Nov 08, 2021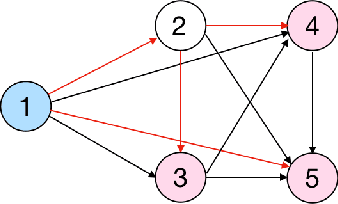
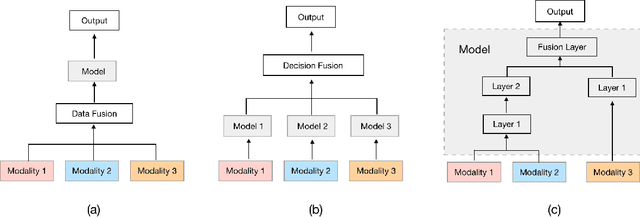
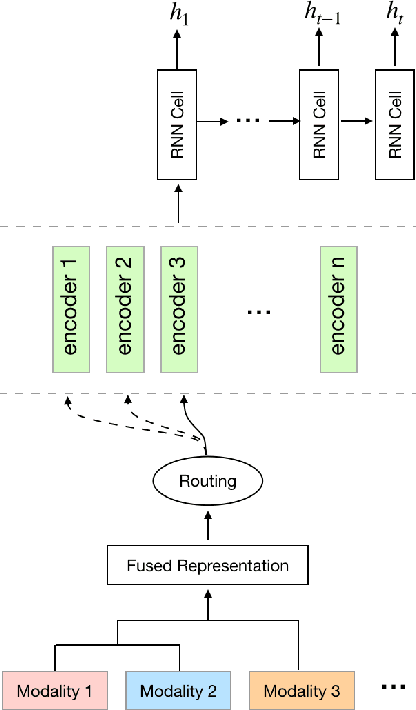
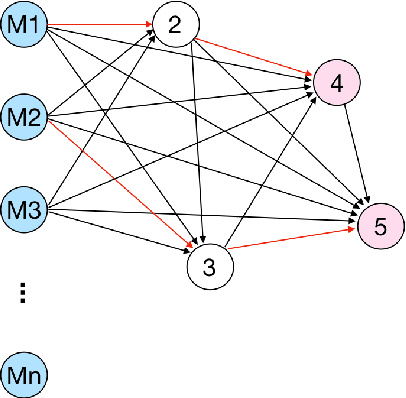
Knowledge Tracing is the process of tracking mastery level of different skills of students for a given learning domain. It is one of the key components for building adaptive learning systems and has been investigated for decades. In parallel with the success of deep neural networks in other fields, we have seen researchers take similar approaches in the learning science community. However, most existing deep learning based knowledge tracing models either: (1) only use the correct/incorrect response (ignoring useful information from other modalities) or (2) design their network architectures through domain expertise via trial and error. In this paper, we propose a sequential model based optimization approach that combines multimodal fusion and neural architecture search within one framework. The commonly used neural architecture search technique could be considered as a special case of our proposed approach when there is only one modality involved. We further propose to use a new metric called time-weighted Area Under the Curve (weighted AUC) to measure how a sequence model performs with time. We evaluate our methods on two public real datasets showing the discovered model is able to achieve superior performance. Unlike most existing works, we conduct McNemar's test on the model predictions and the results are statistically significant.
Dangerous Cloaking: Natural Trigger based Backdoor Attacks on Object Detectors in the Physical World
Jan 21, 2022
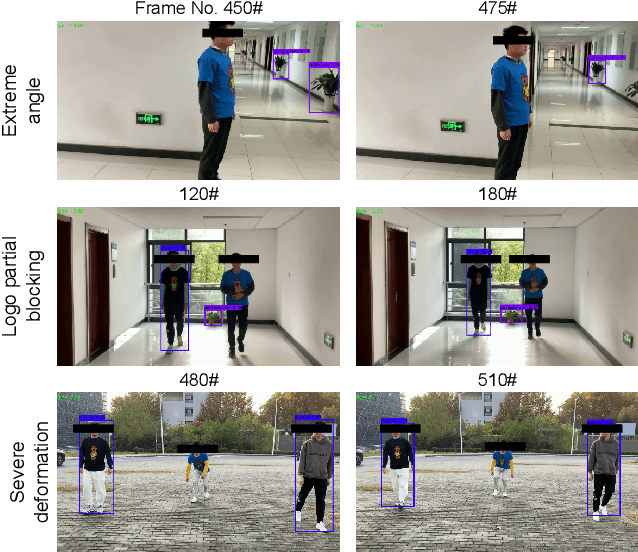
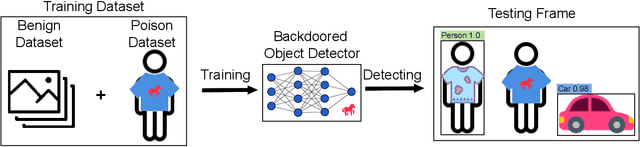

Deep learning models have been shown to be vulnerable to recent backdoor attacks. A backdoored model behaves normally for inputs containing no attacker-secretly-chosen trigger and maliciously for inputs with the trigger. To date, backdoor attacks and countermeasures mainly focus on image classification tasks. And most of them are implemented in the digital world with digital triggers. Besides the classification tasks, object detection systems are also considered as one of the basic foundations of computer vision tasks. However, there is no investigation and understanding of the backdoor vulnerability of the object detector, even in the digital world with digital triggers. For the first time, this work demonstrates that existing object detectors are inherently susceptible to physical backdoor attacks. We use a natural T-shirt bought from a market as a trigger to enable the cloaking effect--the person bounding-box disappears in front of the object detector. We show that such a backdoor can be implanted from two exploitable attack scenarios into the object detector, which is outsourced or fine-tuned through a pretrained model. We have extensively evaluated three popular object detection algorithms: anchor-based Yolo-V3, Yolo-V4, and anchor-free CenterNet. Building upon 19 videos shot in real-world scenes, we confirm that the backdoor attack is robust against various factors: movement, distance, angle, non-rigid deformation, and lighting. Specifically, the attack success rate (ASR) in most videos is 100% or close to it, while the clean data accuracy of the backdoored model is the same as its clean counterpart. The latter implies that it is infeasible to detect the backdoor behavior merely through a validation set. The averaged ASR still remains sufficiently high to be 78% in the transfer learning attack scenarios evaluated on CenterNet. See the demo video on https://youtu.be/Q3HOF4OobbY.
An Efficient Multi-Indicator and Many-Objective Optimization Algorithm based on Two-Archive
Jan 14, 2022
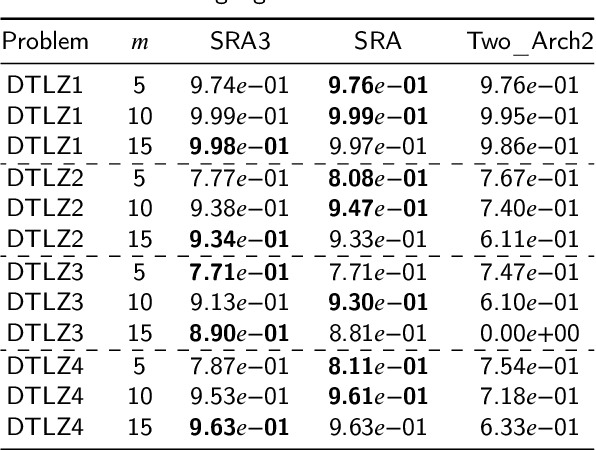
Indicator-based algorithms are gaining prominence as traditional multi-objective optimization algorithms based on domination and decomposition struggle to solve many-objective optimization problems. However, previous indicator-based multi-objective optimization algorithms suffer from the following flaws: 1) The environment selection process takes a long time; 2) Additional parameters are usually necessary. As a result, this paper proposed an multi-indicator and multi-objective optimization algorithm based on two-archive (SRA3) that can efficiently select good individuals in environment selection based on indicators performance and uses an adaptive parameter strategy for parental selection without setting additional parameters. Then we normalized the algorithm and compared its performance before and after normalization, finding that normalization improved the algorithm's performance significantly. We also analyzed how normalizing affected the indicator-based algorithm and observed that the normalized $I_{\epsilon+}$ indicator is better at finding extreme solutions and can reduce the influence of each objective's different extent of contribution to the indicator due to its different scope. However, it also has a preference for extreme solutions, which causes the solution set to converge to the extremes. As a result, we give some suggestions for normalization. Then, on the DTLZ and WFG problems, we conducted experiments on 39 problems with 5, 10, and 15 objectives, and the results show that SRA3 has good convergence and diversity while maintaining high efficiency. Finally, we conducted experiments on the DTLZ and WFG problems with 20 and 25 objectives and found that the algorithm proposed in this paper is more competitive than other algorithms as the number of objectives increases.
Visual Learning-based Planning for Continuous High-Dimensional POMDPs
Dec 17, 2021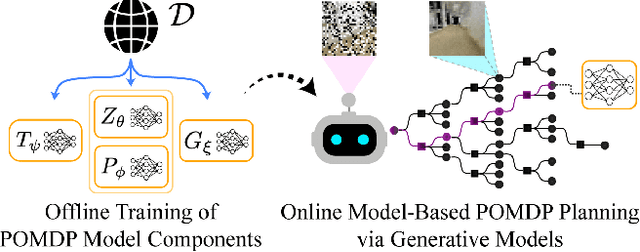
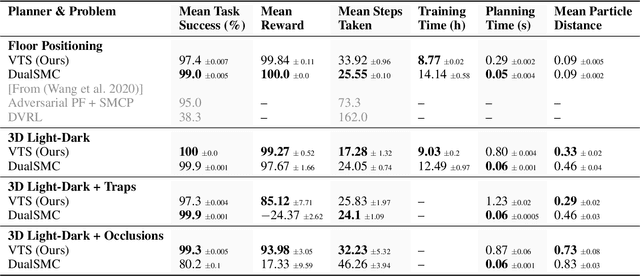
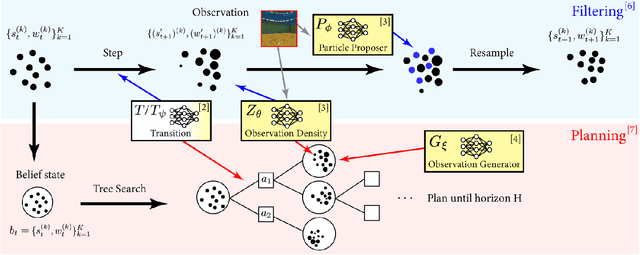
The Partially Observable Markov Decision Process (POMDP) is a powerful framework for capturing decision-making problems that involve state and transition uncertainty. However, most current POMDP planners cannot effectively handle very high-dimensional observations they often encounter in the real world (e.g. image observations in robotic domains). In this work, we propose Visual Tree Search (VTS), a learning and planning procedure that combines generative models learned offline with online model-based POMDP planning. VTS bridges offline model training and online planning by utilizing a set of deep generative observation models to predict and evaluate the likelihood of image observations in a Monte Carlo tree search planner. We show that VTS is robust to different observation noises and, since it utilizes online, model-based planning, can adapt to different reward structures without the need to re-train. This new approach outperforms a baseline state-of-the-art on-policy planning algorithm while using significantly less offline training time.
Active Learning Meets Optimized Item Selection
Nov 22, 2021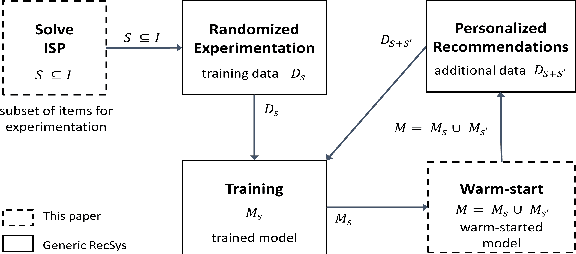
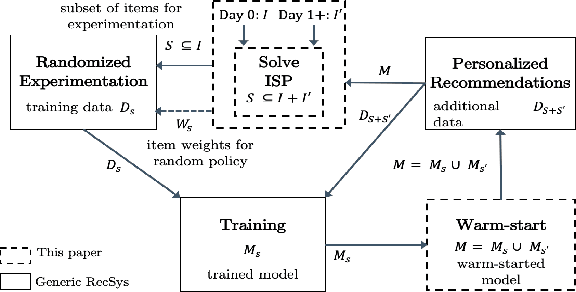
Designing recommendation systems with limited or no available training data remains a challenge. To that end, a new combinatorial optimization problem is formulated to generate optimized item selection for experimentation with the goal to shorten the time for collecting randomized training data. We first present an overview of the optimized item selection problem and a multi-level optimization framework to solve it. The approach integrates techniques from discrete optimization, unsupervised clustering, and latent text embeddings. We then discuss how to incorporate optimized item selection with active learning as part of randomized exploration in an ongoing fashion.
Testing for Causal Influence using a Partial Coherence Statistic
Dec 07, 2021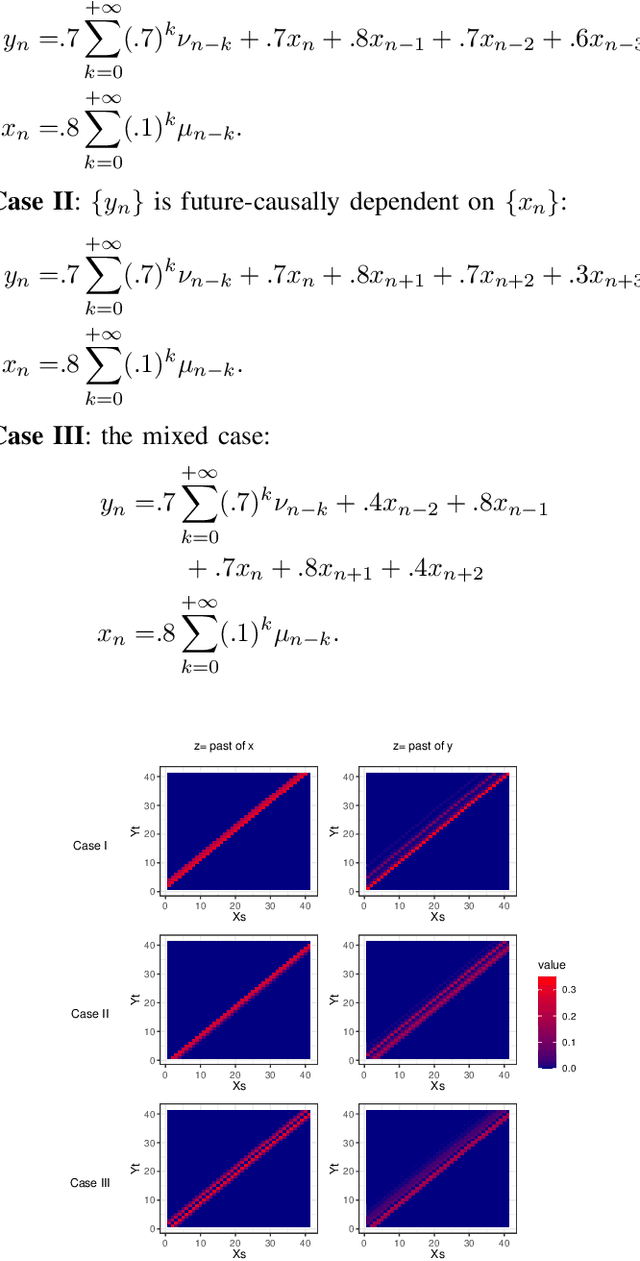
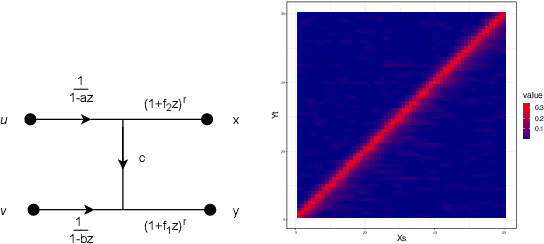
In this paper we explore partial coherence as a tool for evaluating causal influence of one signal sequence on another. In some cases the signal sequence is sampled from a time- or space-series. The key idea is to establish a connection between questions of causality and questions of partial coherence. Once this connection is established, then a scale-invariant partial coherence statistic is used to resolve the question of causality. This coherence statistic is shown to be a likelihood ratio, and its null distribution is shown to be a Wilks Lambda. It may be computed from a composite covariance matrix or from its inverse, the information matrix. Numerical experiments demonstrate the application of partial coherence to the resolution of causality. Importantly, the method is model-free, depending on no generative model for causality.
Globally convergent visual-feature range estimation with biased inertial measurements
Dec 23, 2021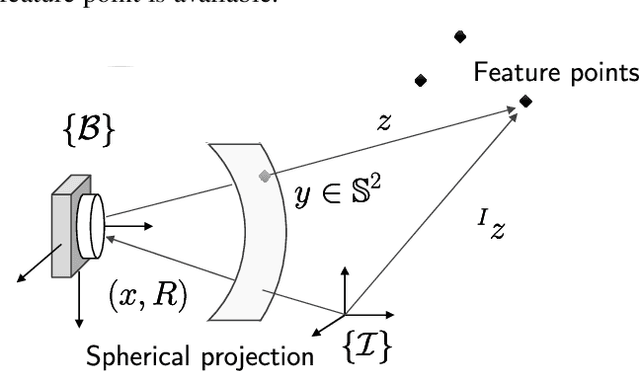
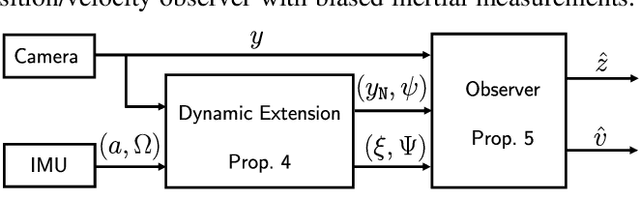
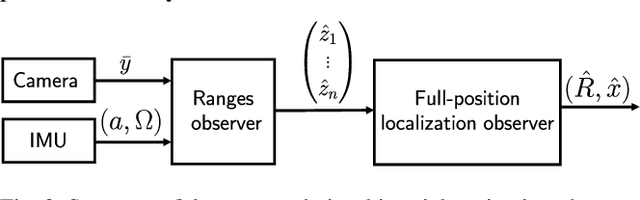
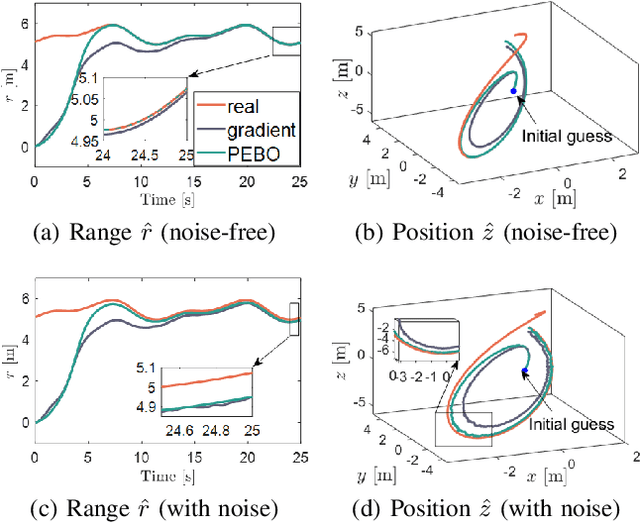
The design of a globally convergent position observer for feature points from visual information is a challenging problem, especially for the case with only inertial measurements and without assumptions of uniform observability, which remained open for a long time. We give a solution to the problem in this paper assuming that only the bearing of a feature point, and biased linear acceleration and rotational velocity of a robot -- all in the body-fixed frame -- are available. Further, in contrast to existing related results, we do not need the value of the gravitational constant either. The proposed approach builds upon the parameter estimation-based observer recently developed in (Ortega et al., Syst. Control. Lett., vol.85, 2015) and its extension to matrix Lie groups in our previous work. Conditions on the robot trajectory under which the observer converges are given, and these are strictly weaker than the standard persistency of excitation and uniform complete observability conditions. Finally, we apply the proposed design to the visual inertial navigation problem. Simulation results are also presented to illustrate our observer design.
Can uncertainty boost the reliability of AI-based diagnostic methods in digital pathology?
Dec 17, 2021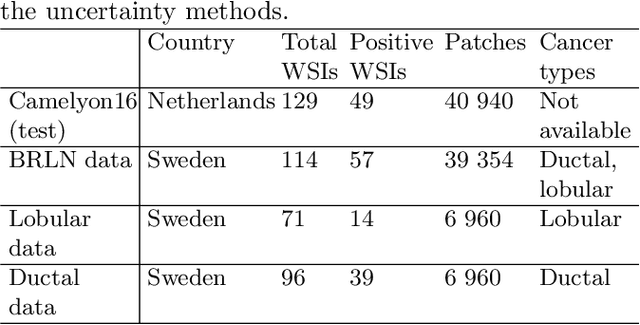
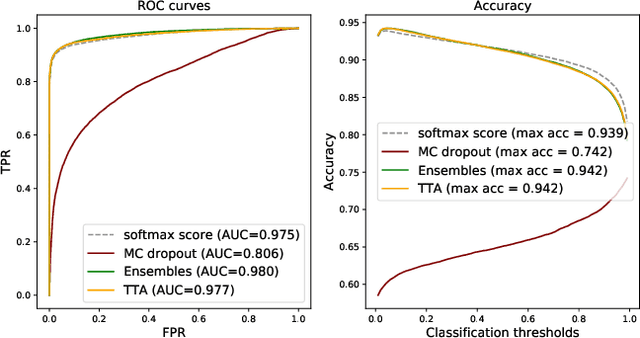

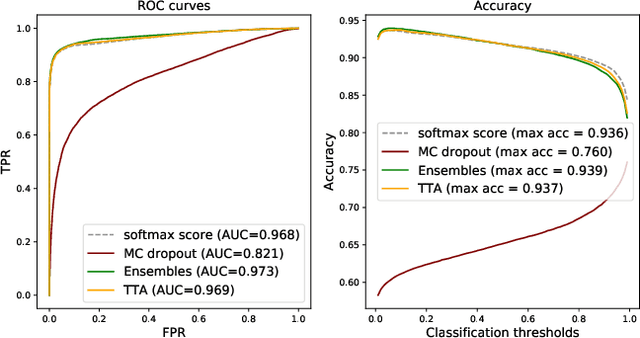
Deep learning (DL) has shown great potential in digital pathology applications. The robustness of a diagnostic DL-based solution is essential for safe clinical deployment. In this work we evaluate if adding uncertainty estimates for DL predictions in digital pathology could result in increased value for the clinical applications, by boosting the general predictive performance or by detecting mispredictions. We compare the effectiveness of model-integrated methods (MC dropout and Deep ensembles) with a model-agnostic approach (Test time augmentation, TTA). Moreover, four uncertainty metrics are compared. Our experiments focus on two domain shift scenarios: a shift to a different medical center and to an underrepresented subtype of cancer. Our results show that uncertainty estimates can add some reliability and reduce sensitivity to classification threshold selection. While advanced metrics and deep ensembles perform best in our comparison, the added value over simpler metrics and TTA is small. Importantly, the benefit of all evaluated uncertainty estimation methods is diminished by domain shift.
Multi-frame Feature Aggregation for Real-time Instrument Segmentation in Endoscopic Video
Nov 17, 2020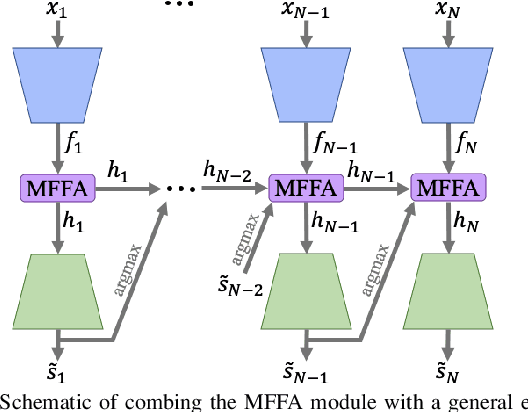
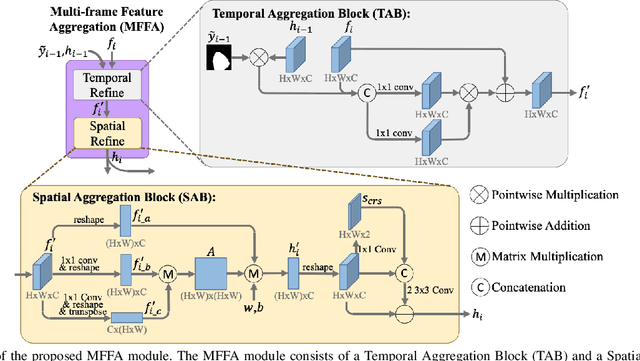
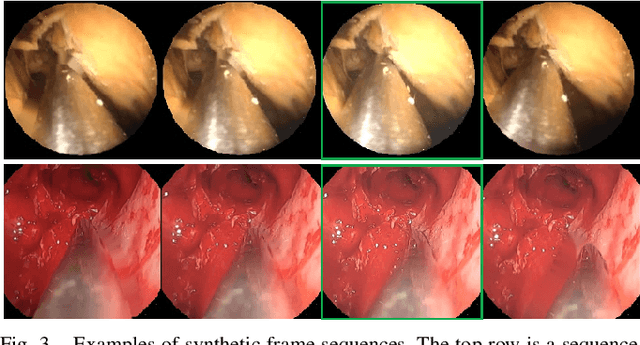
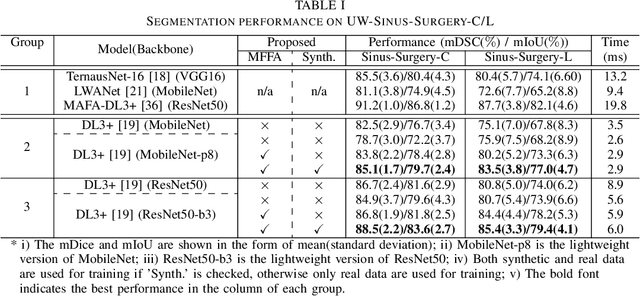
Deep learning-based methods have achieved promising results on surgical instrument segmentation. However, the high computation cost may limit the applications of deep models to time-sensitive tasks such as online surgical video analysis for robotic-assisted surgery. Also, current performance may still suffer from challenging conditions in surgical images such as various lighting conditions and the presence of blood. We propose a novel Multi-frame Feature Aggregation (MFFA) module that leverages information of neighboring frames for segmentation while reducing the influence of spatial misalignment between frames. The MFFA module also further aggregates features spatially based on the spatial self-attention mechanism. Neighboring frames usually have similar appearances, so we consider feature aggregation over a frame sequence as an iterative feature aggregation procedure. By distributing the computational workload of deep feature extraction over each frame in a sequence, we can use a lightweight encoder to reduce the computation costs. Moreover, public surgical videos usually are not labeled by frame, so we develop a method that can randomly synthesize a surgical frame sequence from a labeled frame to assist network training. We demonstrate that our approach achieves superior performance to corresponding deeper segmentation models on a public endoscopic sinus surgery dataset.