 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Annotating Load: Active Learning with Synthetic Images in Surgical Instrument Segmentation
Aug 07, 2021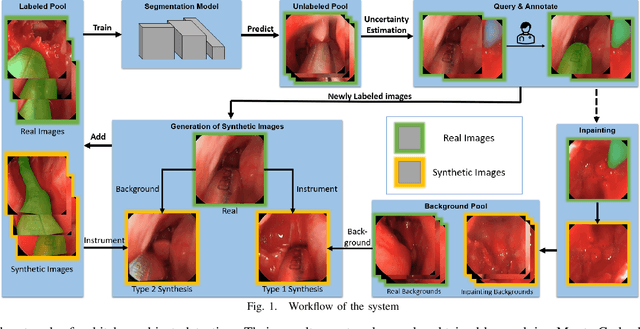
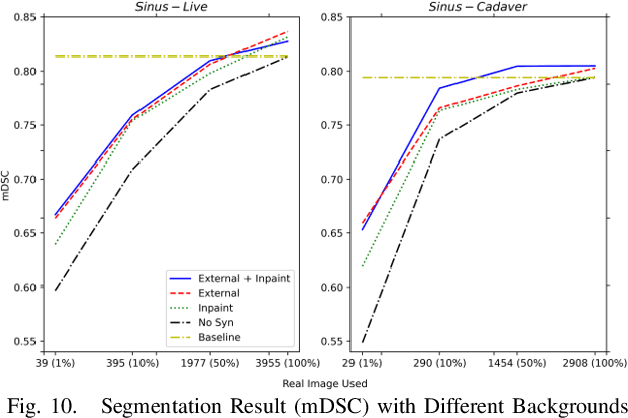
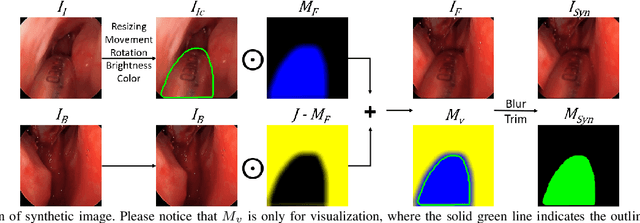
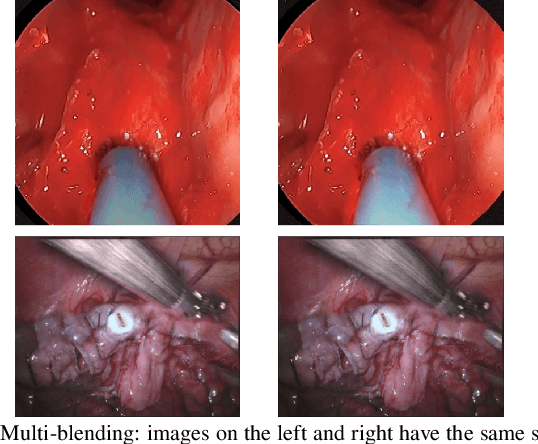
Accurate instrument segmentation in endoscopic vision of robot-assisted surgery is challenging due to reflection on the instruments and frequent contacts with tissue. Deep neural networks (DNN) show competitive performance and are in favor in recent years. However, the hunger of DNN for labeled data poses a huge workload of annotation. Motivated by alleviating this workload, we propose a general embeddable method to decrease the usage of labeled real images, using active generated synthetic images. In each active learning iteration, the most informative unlabeled images are first queried by active learning and then labeled. Next, synthetic images are generated based on these selected images. The instruments and backgrounds are cropped out and randomly combined with each other with blending and fusion near the boundary. The effectiveness of the proposed method is validated on 2 sinus surgery datasets and 1 intraabdominal surgery dataset. The results indicate a considerable improvement in performance, especially when the budget for annotation is small. The effectiveness of different types of synthetic images, blending methods, and external background are also studied. All the code is open-sourced at: https://github.com/HaonanPeng/active_syn_generator.
Multi-frame Feature Aggregation for Real-time Instrument Segmentation in Endoscopic Video
Nov 17, 2020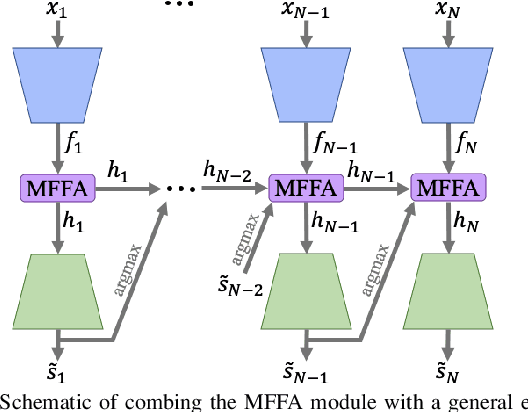
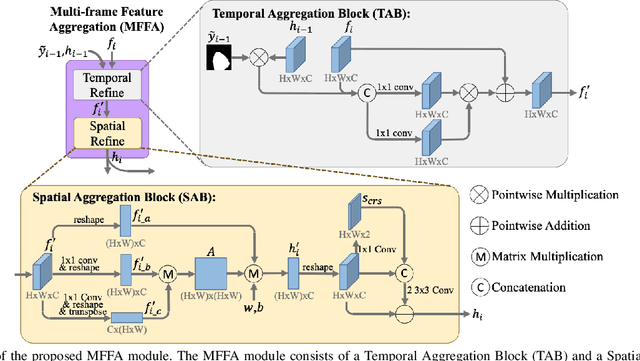
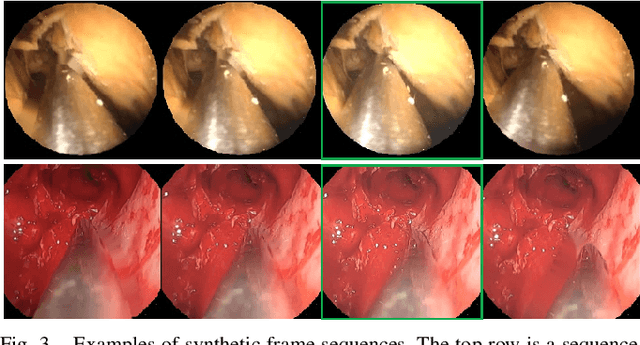
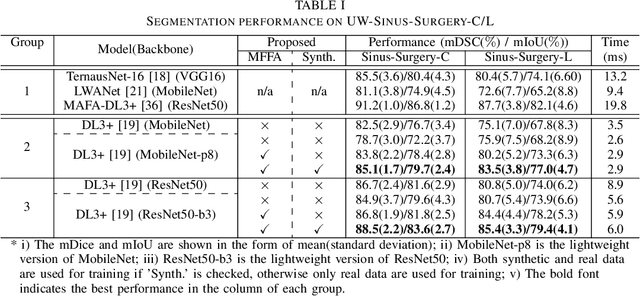
Deep learning-based methods have achieved promising results on surgical instrument segmentation. However, the high computation cost may limit the applications of deep models to time-sensitive tasks such as online surgical video analysis for robotic-assisted surgery. Also, current performance may still suffer from challenging conditions in surgical images such as various lighting conditions and the presence of blood. We propose a novel Multi-frame Feature Aggregation (MFFA) module that leverages information of neighboring frames for segmentation while reducing the influence of spatial misalignment between frames. The MFFA module also further aggregates features spatially based on the spatial self-attention mechanism. Neighboring frames usually have similar appearances, so we consider feature aggregation over a frame sequence as an iterative feature aggregation procedure. By distributing the computational workload of deep feature extraction over each frame in a sequence, we can use a lightweight encoder to reduce the computation costs. Moreover, public surgical videos usually are not labeled by frame, so we develop a method that can randomly synthesize a surgical frame sequence from a labeled frame to assist network training. We demonstrate that our approach achieves superior performance to corresponding deeper segmentation models on a public endoscopic sinus surgery dataset.
LC-GAN: Image-to-image Translation Based on Generative Adversarial Network for Endoscopic Images
Mar 10, 2020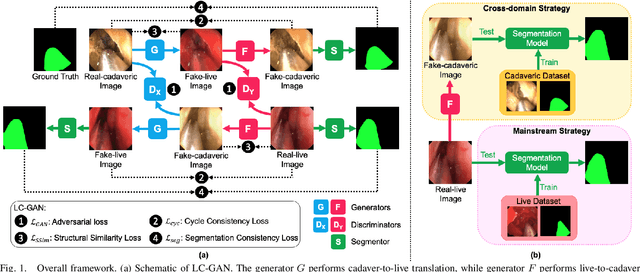
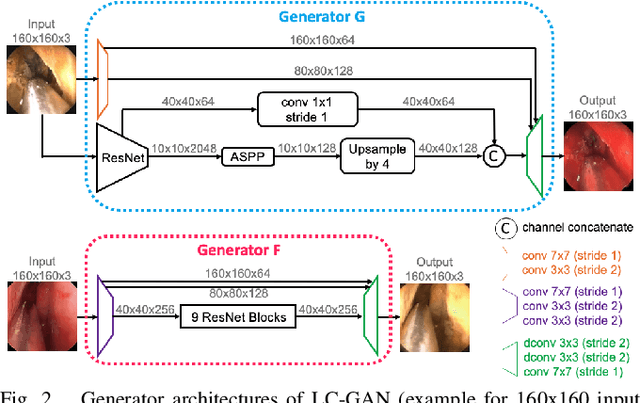

The intelligent perception of endoscopic vision is appealing in many computer-assisted and robotic surgeries. Achieving good vision-based analysis with deep learning techniques requires large labeled datasets, but manual data labeling is expensive and time-consuming in medical problems. When applying a trained model to a different but relevant dataset, a new labeled dataset may be required for training to avoid performance degradation. In this work, we investigate a novel cross-domain strategy to reduce the need for manual data labeling by proposing an image-to-image translation model called live-cadaver GAN (LC-GAN) based on generative adversarial networks (GANs). More specifically, we consider a situation when a labeled cadaveric surgery dataset is available while the task is instrument segmentation on a live surgery dataset. We train LC-GAN to learn the mappings between the cadaveric and live datasets. To achieve instrument segmentation on live images, we can first translate the live images to fake-cadaveric images with LC-GAN, and then perform segmentation on the fake-cadaveric images with models trained on the real cadaveric dataset. With this cross-domain strategy, we fully leverage the labeled cadaveric dataset for segmentation on live images without the need to label the live dataset again. Two generators with different architectures are designed for LC-GAN to make use of the deep feature representation learned from the cadaveric image based instrument segmentation task. Moreover, we propose structural similarity loss and segmentation consistency loss to improve the semantic consistency during translation. The results demonstrate that LC-GAN achieves better image-to-image translation results, and leads to improved segmentation performance in the proposed cross-domain segmentation task.
Towards Better Surgical Instrument Segmentation in Endoscopic Vision: Multi-Angle Feature Aggregation and Contour Supervision
Feb 25, 2020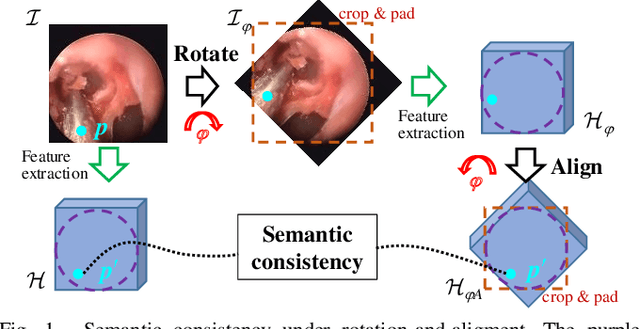
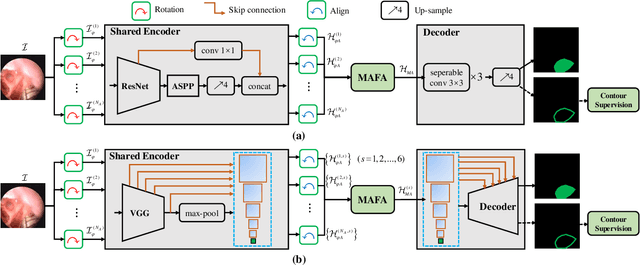
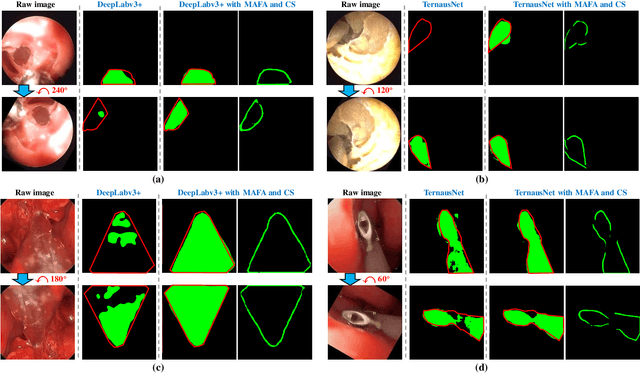
Accurate and real-time surgical instrument segmentation is important in the endoscopic vision of robot-assisted surgery, and significant challenges are posed by frequent instrument-tissue contacts and continuous change of observation perspective. For these challenging tasks more and more deep neural networks (DNN) models are designed in recent years. We are motivated to propose a general embeddable approach to improve these current DNN segmentation models without increasing the model parameter number. Firstly, observing the limited rotation-invariance performance of DNN, we proposed the Multi-Angle Feature Aggregation (MAFA) method, lever-aging active image rotation to gain richer visual cues and make the prediction more robust to instrument orientation changes. Secondly, in the end-to-end training stage, the auxiliary contour supervision is utilized to guide the model to learn the boundary awareness, so that the contour shape of segmentation mask is more precise. The effectiveness of the proposed methods is validated with ablation experiments con-ducted on novel Sinus-Surgery datasets.