 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Image Reconstruction from Events. Why learn it?
Dec 12, 2021
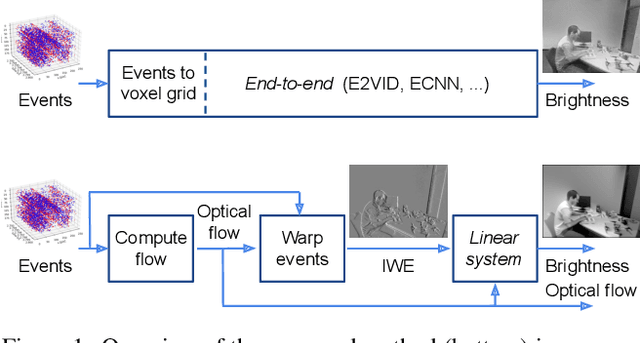
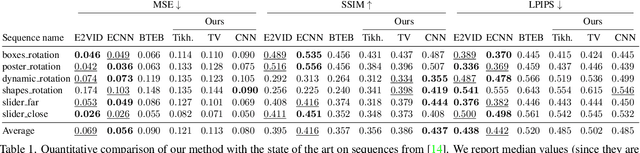

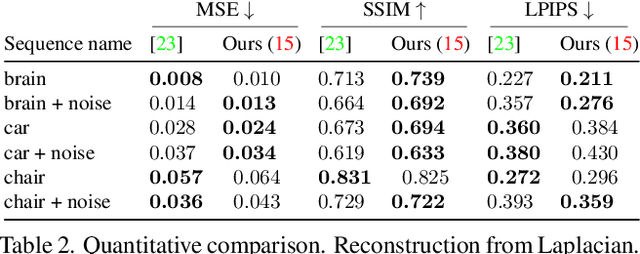
Traditional cameras measure image intensity. Event cameras, by contrast, measure per-pixel temporal intensity changes asynchronously. Recovering intensity from events is a popular research topic since the reconstructed images inherit the high dynamic range (HDR) and high-speed properties of events; hence they can be used in many robotic vision applications and to generate slow-motion HDR videos. However, state-of-the-art methods tackle this problem by training an event-to-image recurrent neural network (RNN), which lacks explainability and is difficult to tune. In this work we show, for the first time, how tackling the joint problem of motion and intensity estimation leads us to model event-based image reconstruction as a linear inverse problem that can be solved without training an image reconstruction RNN. Instead, classical and learning-based image priors can be used to solve the problem and remove artifacts from the reconstructed images. The experiments show that the proposed approach generates images with visual quality on par with state-of-the-art methods despite only using data from a short time interval (i.e., without recurrent connections). Our method can also be used to improve the quality of images reconstructed by approaches that first estimate the image Laplacian; here our method can be interpreted as Poisson reconstruction guided by image priors.
GTrans: Spatiotemporal Autoregressive Transformer with Graph Embeddings for Nowcasting Extreme Events
Jan 18, 2022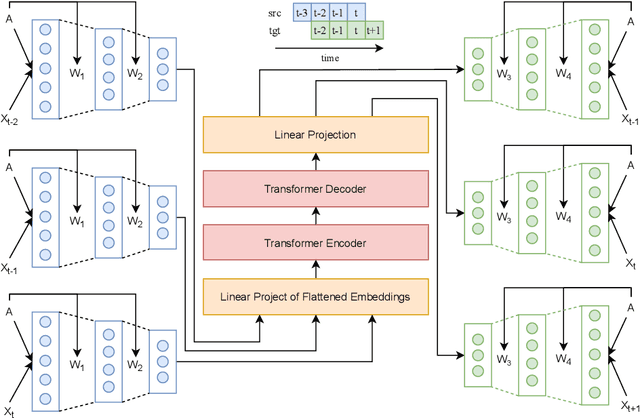

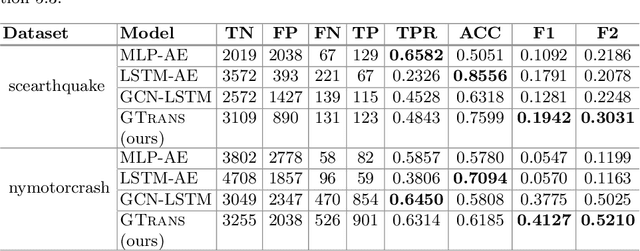
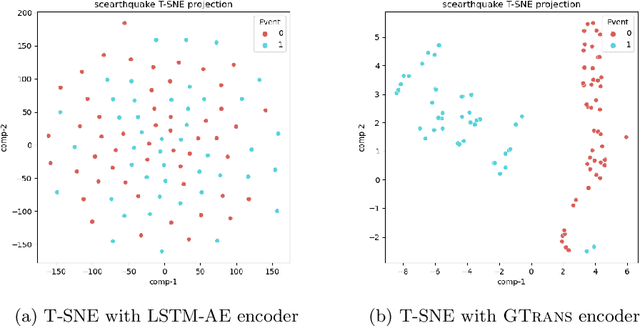
Spatiotemporal time series nowcasting should preserve temporal and spatial dynamics in the sense that generated new sequences from models respect the covariance relationship from history. Conventional feature extractors are built with deep convolutional neural networks (CNN). However, CNN models have limits to image-like applications where data can be formed with high-dimensional arrays. In contrast, applications in social networks, road traffic, physics, and chemical property prediction where data features can be organized with nodes and edges of graphs. Transformer architecture is an emerging method for predictive models, bringing high accuracy and efficiency due to attention mechanism design. This paper proposes a spatiotemporal model, namely GTrans, that transforms data features into graph embeddings and predicts temporal dynamics with a transformer model. According to our experiments, we demonstrate that GTrans can model spatial and temporal dynamics and nowcasts extreme events for datasets. Furthermore, in all the experiments, GTrans can achieve the highest F1 and F2 scores in binary-class prediction tests than the baseline models.
Interactron: Embodied Adaptive Object Detection
Feb 01, 2022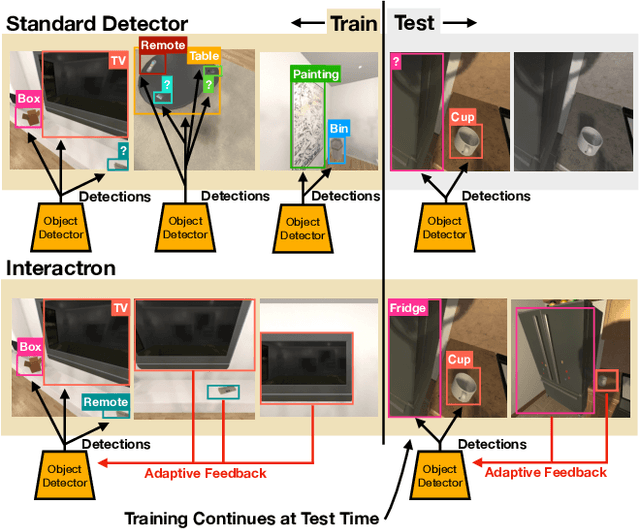

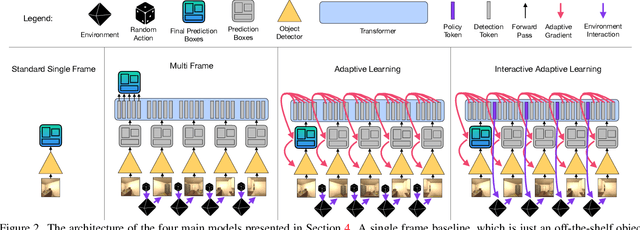
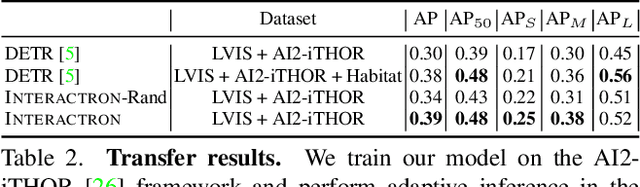
Over the years various methods have been proposed for the problem of object detection. Recently, we have witnessed great strides in this domain owing to the emergence of powerful deep neural networks. However, there are typically two main assumptions common among these approaches. First, the model is trained on a fixed training set and is evaluated on a pre-recorded test set. Second, the model is kept frozen after the training phase, so no further updates are performed after the training is finished. These two assumptions limit the applicability of these methods to real-world settings. In this paper, we propose Interactron, a method for adaptive object detection in an interactive setting, where the goal is to perform object detection in images observed by an embodied agent navigating in different environments. Our idea is to continue training during inference and adapt the model at test time without any explicit supervision via interacting with the environment. Our adaptive object detection model provides a 11.8 point improvement in AP (and 19.1 points in AP50) over DETR, a recent, high-performance object detector. Moreover, we show that our object detection model adapts to environments with completely different appearance characteristics, and its performance is on par with a model trained with full supervision for those environments.
Dynamic Time Warp Convolutional Networks
Nov 05, 2019
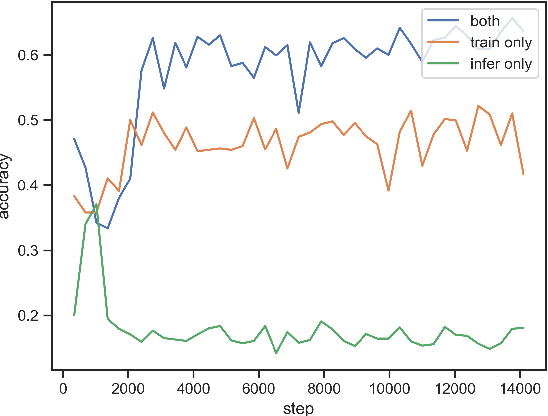
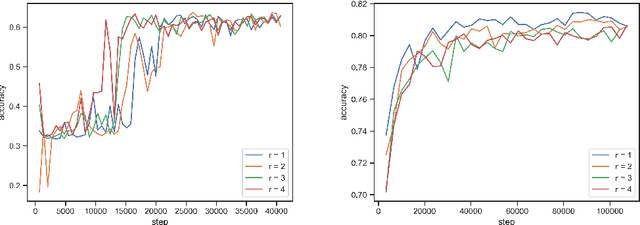
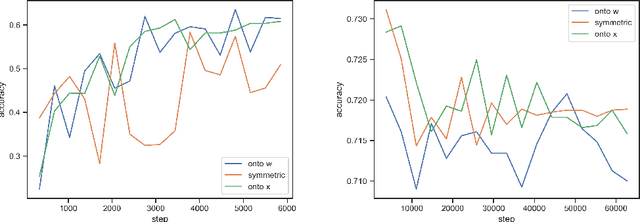
Where dealing with temporal sequences it is fair to assume that the same kind of deformations that motivated the development of the Dynamic Time Warp algorithm could be relevant also in the calculation of the dot product ("convolution") in a 1-D convolution layer. In this work a method is proposed for aligning the convolution filter and the input where they are locally out of phase utilising an algorithm similar to the Dynamic Time Warp. The proposed method enables embedding a non-parametric warping of temporal sequences for increasing similarity directly in deep networks and can expand on the generalisation capabilities and the capacity of standard 1-D convolution layer where local sequential deformations are present in the input. Experimental results demonstrate the proposed method exceeds or matches the standard 1-D convolution layer in terms of the maximum accuracy achieved on a number of time series classification tasks. In addition the impact of different hyperparameters settings is investigated given different datasets and the results support the conclusions of previous work done in relation to the choice of DTW parameter values. The proposed layer can be freely integrated with other typical layers to compose deep artificial neural networks of an arbitrary architecture that are trained using standard stochastic gradient descent.
Von Mises Tapering: A New Circular Windowing
Oct 30, 2021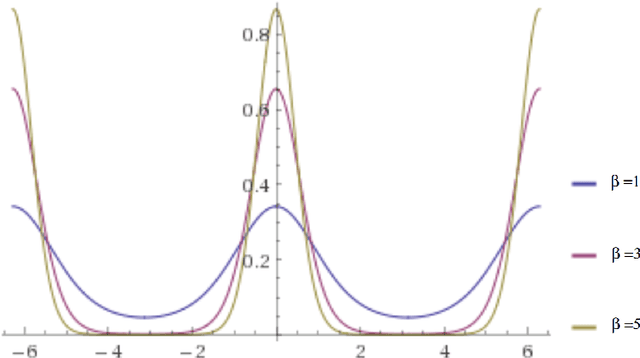
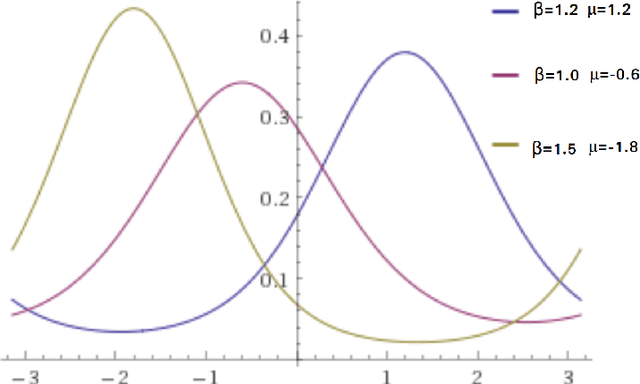
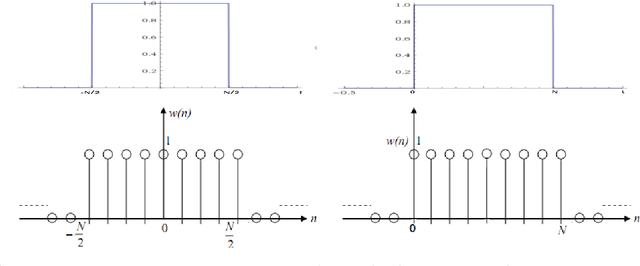
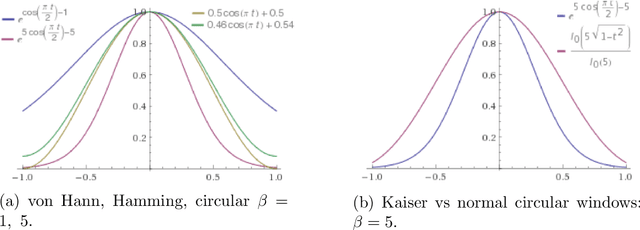
Discrete and continuous standard windowing are revisited and a a new taper is introduced, which is derived from the normal circular distribution by von Mises. Both the continuous-time and the discrete-time windows are considered, and their spectra obtained. A brief comparison with further classical window families is performed in terms of their properties in the spectral domain. These windows can be used in spectral analysis, and in particular, in the design of FIR (finite impulse response) filters as an alternative to the Kaiser window
Spatio-Temporal Failure Propagation in Cyber-Physical Power Systems
Feb 05, 2022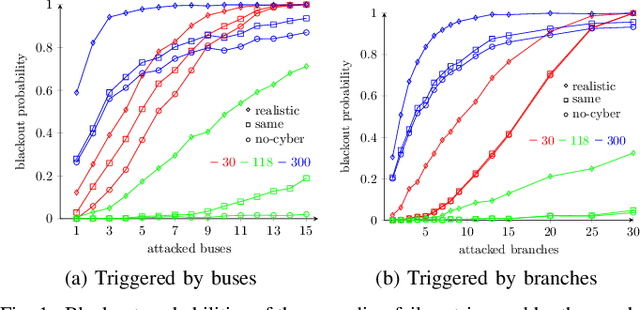
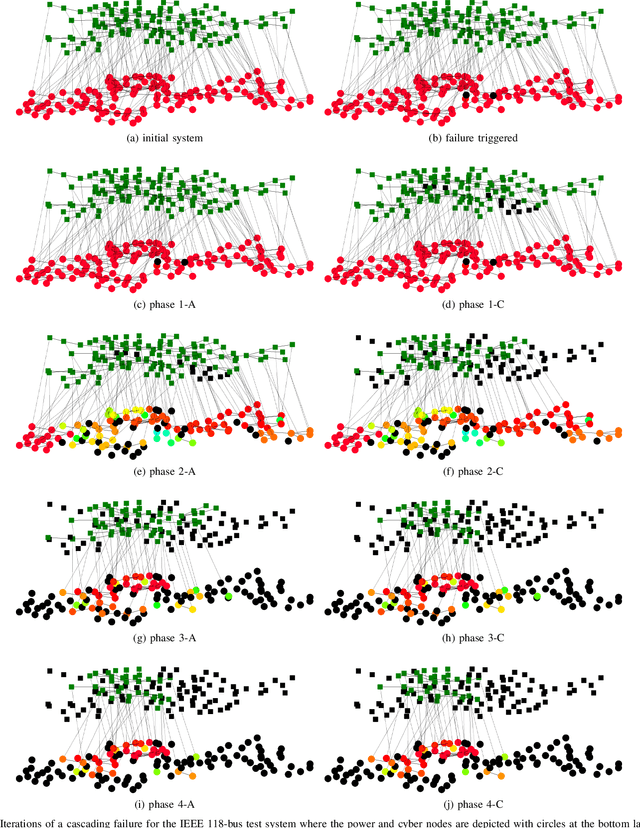
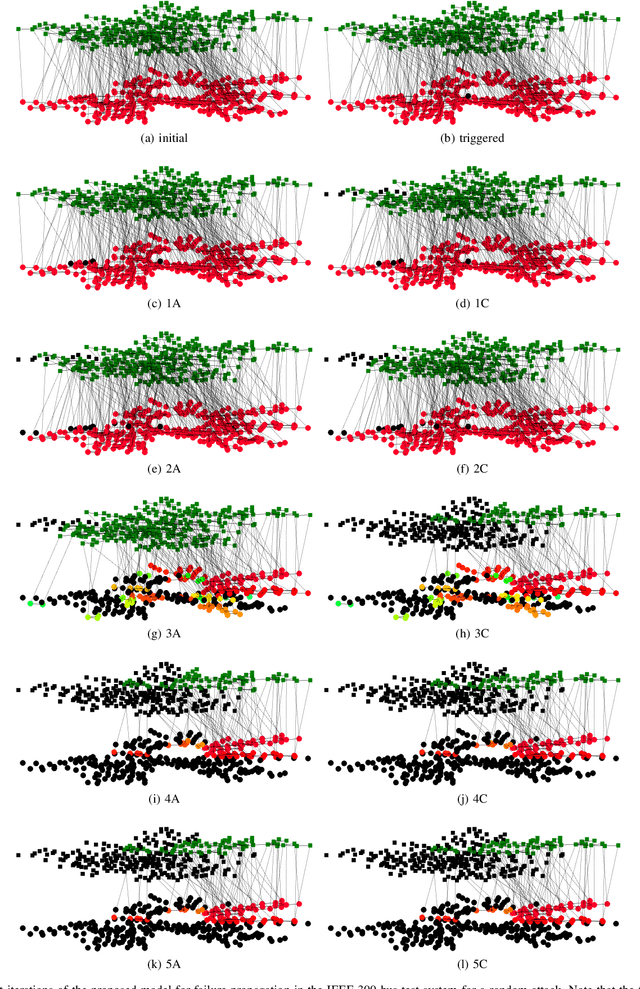
Cascading failure in power systems is triggered by a small perturbation that leads to a sequence of failures spread through the system. The interconnection between different components in a power system causes failures to easily propagate across the system. The situation gets worse by considering the interconnection between cyber and physical layers in power systems. A plethora of work has studied the cascading failure in power systems to calculate its impact on the system. Understanding how failures propagate into the system in time and space can help the system operator to take preventive actions and upgrade the system accordingly. Due to the nonlinearity of the power flow equation as well as the engineering constraints in the power system, it is essential to understand the spatio-temporal failure propagation in cyber-physical power systems (CPPS). This paper proposes an asynchronous algorithm for investigating failure propagation in CPPS. The physics of the power system is addressed by the full AC power flow equations. Various practical constraints including load shedding, load-generation balance, and island operation are considered to address practical constraints in power system operation. The propagation of various random initial attacks of different sizes is analyzed and visualized to elaborate on the applicability of the proposed approach. Our findings shed light on the cascading failure evolution in CPPS.
Modular representation and control of floppy networks
Jan 28, 2022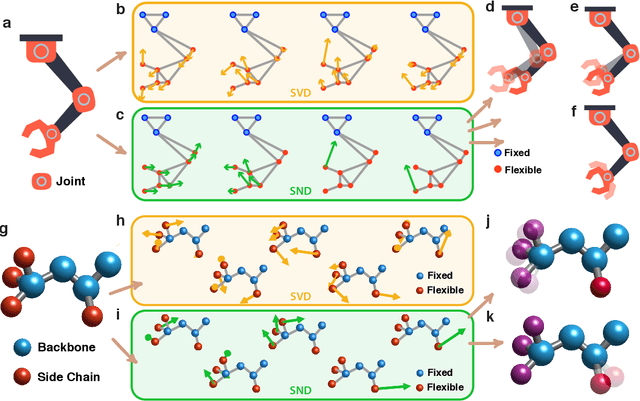
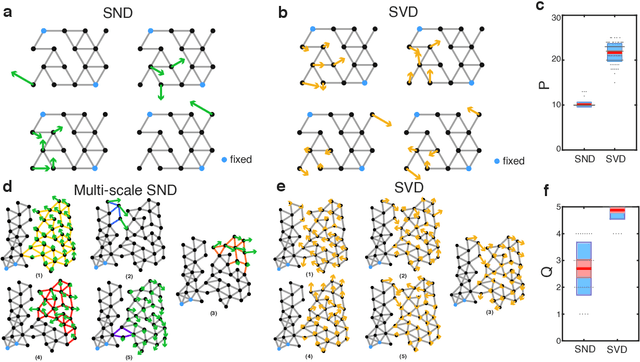
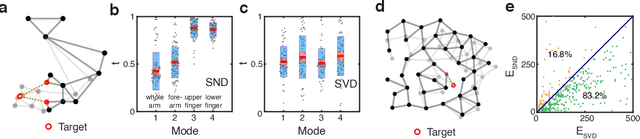
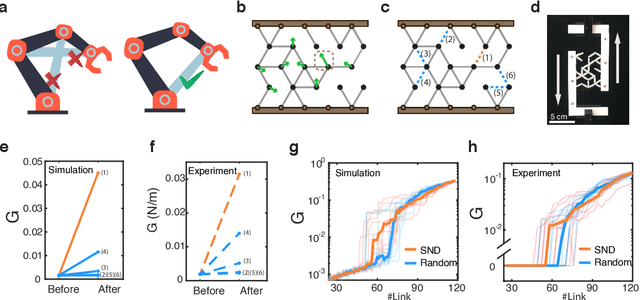
Geometric graph models of systems as diverse as proteins, robots, and mechanical structures from DNA assemblies to architected materials point towards a unified way to represent and control them in space and time. While much work has been done in the context of characterizing the behavior of these networks close to critical points associated with bond and rigidity percolation, isostaticity, etc., much less is known about floppy, under-constrained networks that are far more common in nature and technology. Here we combine geometric rigidity and algebraic sparsity to provide a framework for identifying the zero-energy floppy modes via a representation that illuminates the underlying hierarchy and modularity of the network, and thence the control of its nestedness and locality. Our framework allows us to demonstrate a range of applications of this approach that include robotic reaching tasks with motion primitives, and predicting the linear and nonlinear response of elastic networks based solely on infinitesimal rigidity and sparsity, which we test using physical experiments. Our approach is thus likely to be of use broadly in dissecting the geometrical properties of floppy networks using algebraic sparsity to optimize their function and performance.
Hardware/Software Co-Programmable Framework for Computational SSDs to Accelerate Deep Learning Service on Large-Scale Graphs
Jan 23, 2022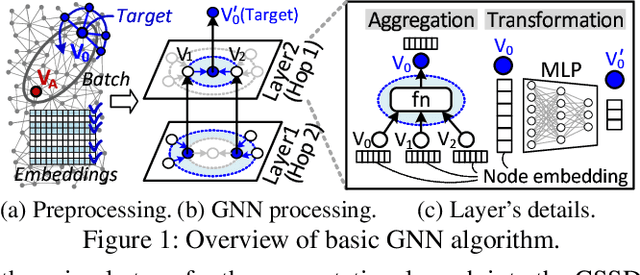

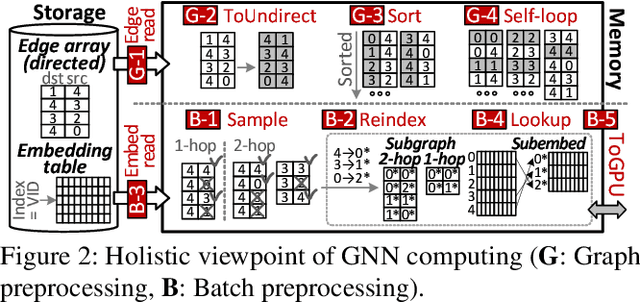

Graph neural networks (GNNs) process large-scale graphs consisting of a hundred billion edges. In contrast to traditional deep learning, unique behaviors of the emerging GNNs are engaged with a large set of graphs and embedding data on storage, which exhibits complex and irregular preprocessing. We propose a novel deep learning framework on large graphs, HolisticGNN, that provides an easy-to-use, near-storage inference infrastructure for fast, energy-efficient GNN processing. To achieve the best end-to-end latency and high energy efficiency, HolisticGNN allows users to implement various GNN algorithms and directly executes them where the actual data exist in a holistic manner. It also enables RPC over PCIe such that the users can simply program GNNs through a graph semantic library without any knowledge of the underlying hardware or storage configurations. We fabricate HolisticGNN's hardware RTL and implement its software on an FPGA-based computational SSD (CSSD). Our empirical evaluations show that the inference time of HolisticGNN outperforms GNN inference services using high-performance modern GPUs by 7.1x while reducing energy consumption by 33.2x, on average.
Uni-Retriever: Towards Learning The Unified Embedding Based Retriever in Bing Sponsored Search
Feb 13, 2022
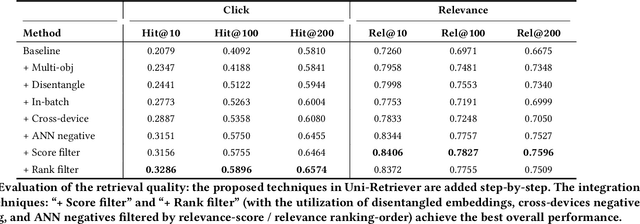
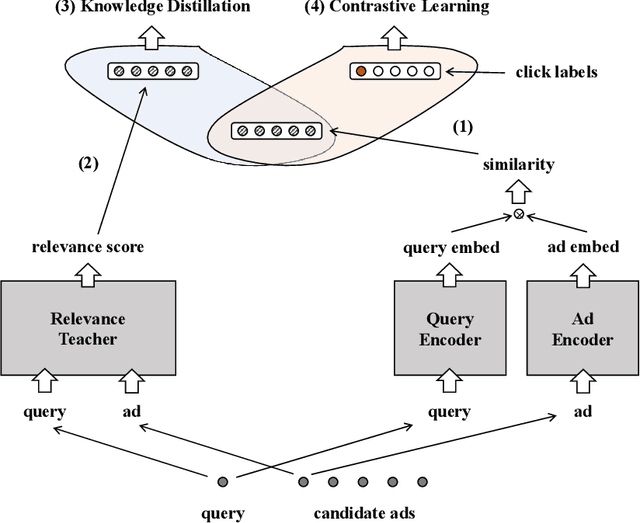
Embedding based retrieval (EBR) is a fundamental building block in many web applications. However, EBR in sponsored search is distinguished from other generic scenarios and technically challenging due to the need of serving multiple retrieval purposes: firstly, it has to retrieve high-relevance ads, which may exactly serve user's search intent; secondly, it needs to retrieve high-CTR ads so as to maximize the overall user clicks. In this paper, we present a novel representation learning framework Uni-Retriever developed for Bing Search, which unifies two different training modes knowledge distillation and contrastive learning to realize both required objectives. On one hand, the capability of making high-relevance retrieval is established by distilling knowledge from the ``relevance teacher model''. On the other hand, the capability of making high-CTR retrieval is optimized by learning to discriminate user's clicked ads from the entire corpus. The two training modes are jointly performed as a multi-objective learning process, such that the ads of high relevance and CTR can be favored by the generated embeddings. Besides the learning strategy, we also elaborate our solution for EBR serving pipeline built upon the substantially optimized DiskANN, where massive-scale EBR can be performed with competitive time and memory efficiency, and accomplished in high-quality. We make comprehensive offline and online experiments to evaluate the proposed techniques, whose findings may provide useful insights for the future development of EBR systems. Uni-Retriever has been mainstreamed as the major retrieval path in Bing's production thanks to the notable improvements on the representation and EBR serving quality.
Toward Development of Machine Learned Techniques for Production of Compact Kinetic Models
Feb 16, 2022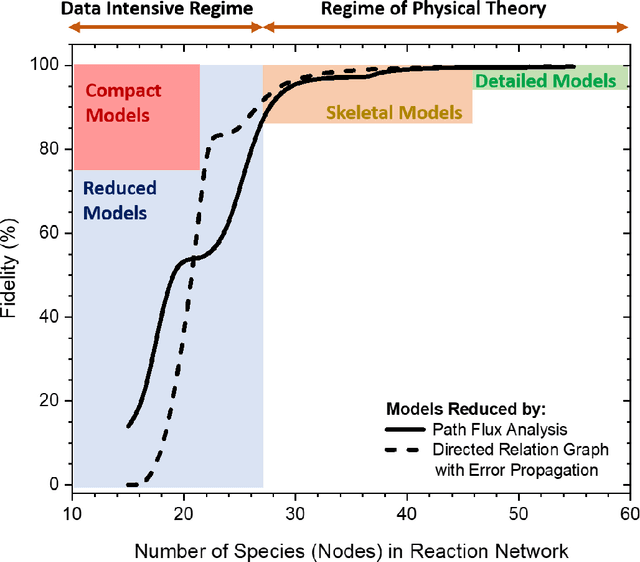
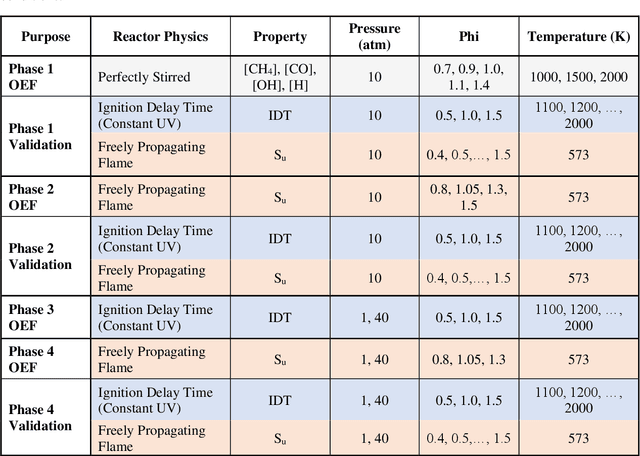
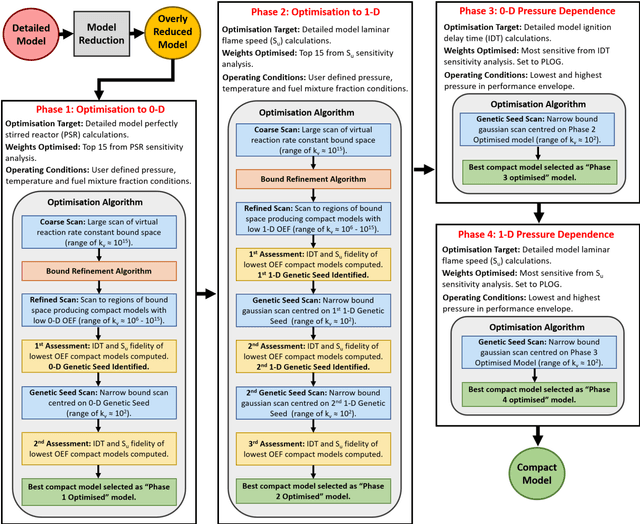
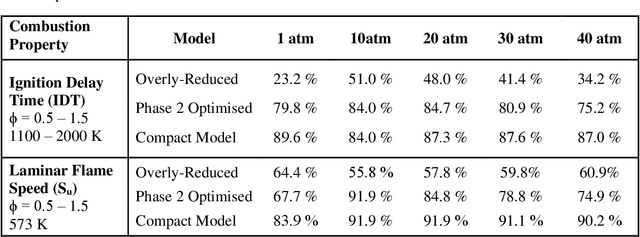
Chemical kinetic models are an essential component in the development and optimisation of combustion devices through their coupling to multi-dimensional simulations such as computational fluid dynamics (CFD). Low-dimensional kinetic models which retain good fidelity to the reality are needed, the production of which requires considerable human-time cost and expert knowledge. Here, we present a novel automated compute intensification methodology to produce overly-reduced and optimised (compact) chemical kinetic models. This algorithm, termed Machine Learned Optimisation of Chemical Kinetics (MLOCK), systematically perturbs each of the four sub-models of a chemical kinetic model to discover what combinations of terms results in a good model. A virtual reaction network comprised of n species is first obtained using conventional mechanism reduction. To counteract the imposed decrease in model performance, the weights (virtual reaction rate constants) of important connections (virtual reactions) between each node (species) of the virtual reaction network are numerically optimised to replicate selected calculations across four sequential phases. The first version of MLOCK, (MLOCK1.0) simultaneously perturbs all three virtual Arrhenius reaction rate constant parameters for important connections and assesses the suitability of the new parameters through objective error functions, which quantify the error in each compact model candidate's calculation of the optimisation targets, which may be comprised of detailed model calculations and/or experimental data. MLOCK1.0 is demonstrated by creating compact models for the archetypal case of methane air combustion. It is shown that the NUGMECH1.0 detailed model comprised of 2,789 species is reliably compacted to 15 species (nodes), whilst retaining an overall fidelity of ~87% to the detailed model calculations, outperforming the prior state-of-art.