 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Local Polynomial Regression with Similarity Kernels
Jan 18, 2025



Local Polynomial Regression (LPR) is a widely used nonparametric method for modeling complex relationships due to its flexibility and simplicity. It estimates a regression function by fitting low-degree polynomials to localized subsets of the data, weighted by proximity. However, traditional LPR is sensitive to outliers and high-leverage points, which can significantly affect estimation accuracy. This paper revisits the kernel function used to compute regression weights and proposes a novel framework that incorporates both predictor and response variables in the weighting mechanism. By introducing two positive definite kernels, the proposed method robustly estimates weights, mitigating the influence of outliers through localized density estimation. The method is implemented in Python and is publicly available at https://github.com/yaniv-shulman/rsklpr, demonstrating competitive performance in synthetic benchmark experiments. Compared to standard LPR, the proposed approach consistently improves robustness and accuracy, especially in heteroscedastic and noisy environments, without requiring multiple iterations. This advancement provides a promising extension to traditional LPR, opening new possibilities for robust regression applications.
Exact Backpropagation in Binary Weighted Networks with Group Weight Transformations
Jul 16, 2021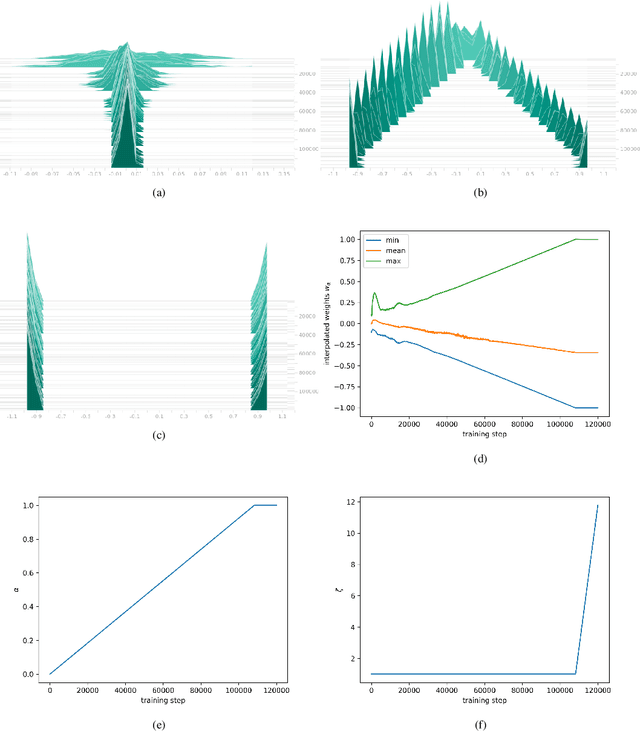

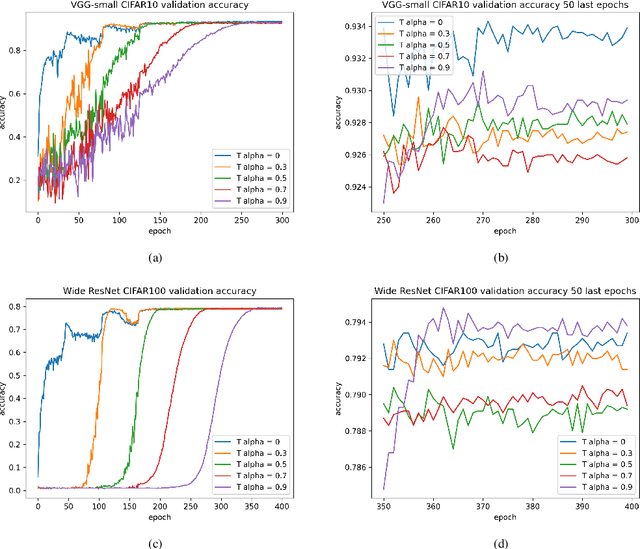
Quantization based model compression serves as high performing and fast approach for inference that yields models which are highly compressed when compared to their full-precision floating point counterparts. The most extreme quantization is a 1-bit representation of parameters such that they have only two possible values, typically -1(0) or +1, enabling efficient implementation of the ubiquitous dot product using only additions. The main contribution of this work is the introduction of a method to smooth the combinatorial problem of determining a binary vector of weights to minimize the expected loss for a given objective by means of empirical risk minimization with backpropagation. This is achieved by approximating a multivariate binary state over the weights utilizing a deterministic and differentiable transformation of real-valued, continuous parameters. The proposed method adds little overhead in training, can be readily applied without any substantial modifications to the original architecture, does not introduce additional saturating nonlinearities or auxiliary losses, and does not prohibit applying other methods for binarizing the activations. Contrary to common assertions made in the literature, it is demonstrated that binary weighted networks can train well with the same standard optimization techniques and similar hyperparameter settings as their full-precision counterparts, specifically momentum SGD with large learning rates and $L_2$ regularization. To conclude experiments demonstrate the method performs remarkably well across a number of inductive image classification tasks with various architectures compared to their full-precision counterparts. The source code is publicly available at https://bitbucket.org/YanivShu/binary_weighted_networks_public.
DiffPrune: Neural Network Pruning with Deterministic Approximate Binary Gates and $L_0$ Regularization
Dec 07, 2020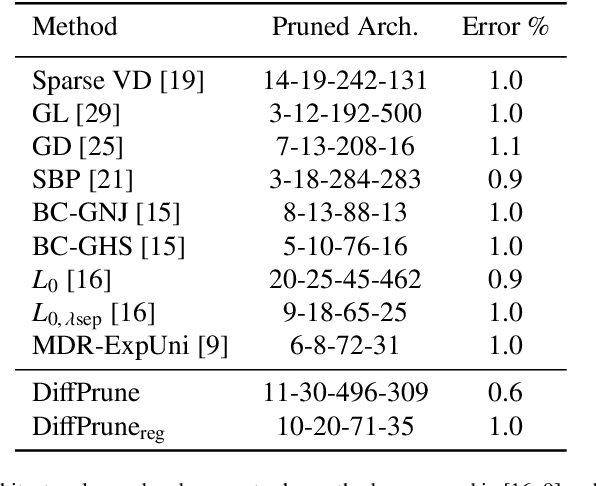
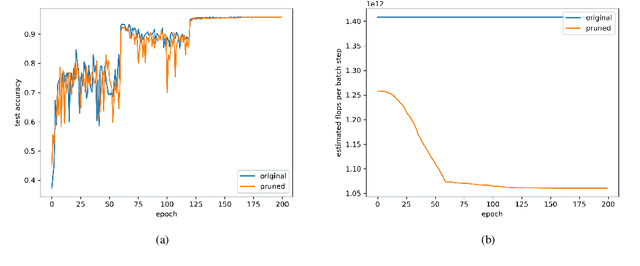
Modern neural network architectures typically have many millions of parameters and can be pruned significantly without substantial loss in effectiveness which demonstrates they are over-parameterized. The contribution of this work is two-fold. The first is a method for approximating a multivariate Bernoulli random variable by means of a deterministic and differentiable transformation of any real-valued multivariate random variable. The second is a method for model selection by element-wise multiplication of parameters with approximate binary gates that may be computed deterministically or stochastically and take on exact zero values. Sparsity is encouraged by the inclusion of a surrogate regularization to the $L_0$ loss. Since the method is differentiable it enables straightforward and efficient learning of model architectures by an empirical risk minimization procedure with stochastic gradient descent and theoretically enables conditional computation during training. The method also supports any arbitrary group sparsity over parameters or activations and therefore offers a framework for unstructured or flexible structured model pruning. To conclude experiments are performed to demonstrate the effectiveness of the proposed approach.
SimPool: Towards Topology Based Graph Pooling with Structural Similarity Features
Jun 03, 2020
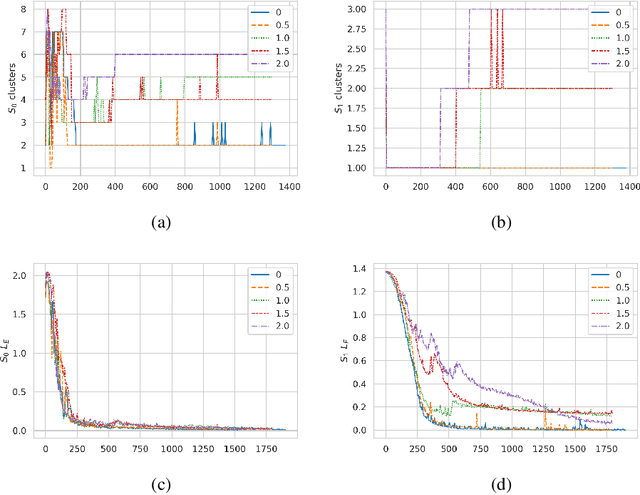
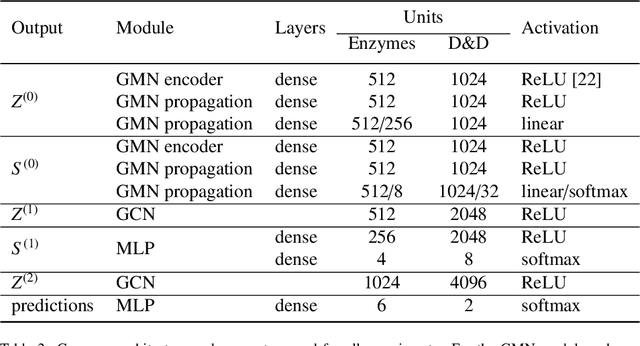
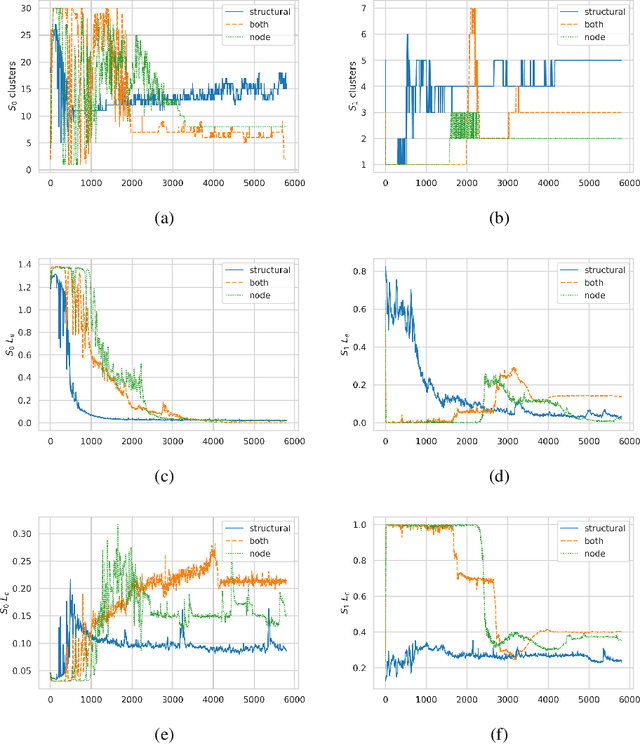
Deep learning methods for graphs have seen rapid progress in recent years with much focus awarded to generalising Convolutional Neural Networks (CNN) to graph data. CNNs are typically realised by alternating convolutional and pooling layers where the pooling layers subsample the grid and exchange spatial or temporal resolution for increased feature dimensionality. Whereas the generalised convolution operator for graphs has been studied extensively and proven useful, hierarchical coarsening of graphs is still challenging since nodes in graphs have no spatial locality and no natural order. This paper proposes two main contributions, the first is a differential module calculating structural similarity features based on the adjacency matrix. These structural similarity features may be used with various algorithms however in this paper the focus and the second main contribution is on integrating these features with a revisited pooling layer DiffPool arXiv:1806.08804 to propose a pooling layer referred to as SimPool. This is achieved by linking the concept of network reduction by means of structural similarity in graphs with the concept of hierarchical localised pooling. Experimental results demonstrate that as part of an end-to-end Graph Neural Network architecture SimPool calculates node cluster assignments that functionally resemble more to the locality preserving pooling operations used by CNNs that operate on local receptive fields in the standard grid. Furthermore the experimental results demonstrate that these features are useful in inductive graph classification tasks with no increase to the number of parameters.
Dynamic Time Warp Convolutional Networks
Nov 05, 2019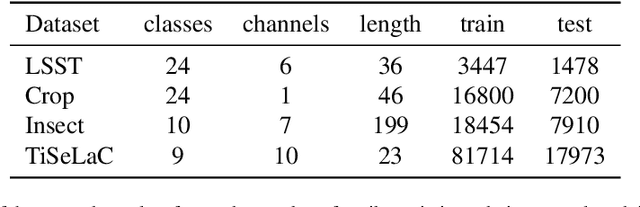
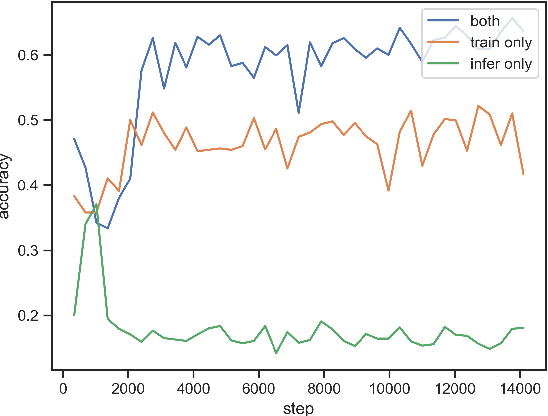
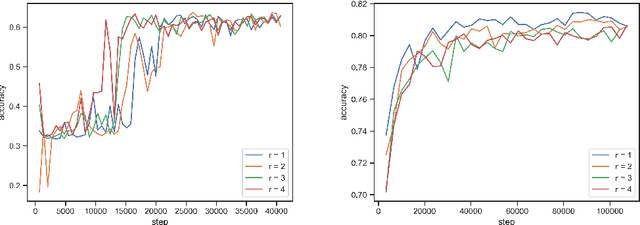
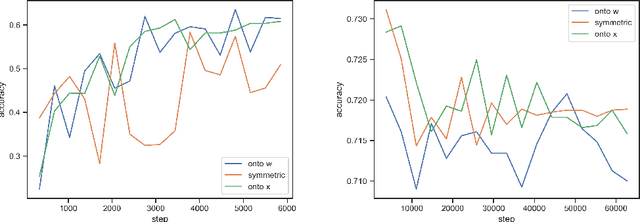
Where dealing with temporal sequences it is fair to assume that the same kind of deformations that motivated the development of the Dynamic Time Warp algorithm could be relevant also in the calculation of the dot product ("convolution") in a 1-D convolution layer. In this work a method is proposed for aligning the convolution filter and the input where they are locally out of phase utilising an algorithm similar to the Dynamic Time Warp. The proposed method enables embedding a non-parametric warping of temporal sequences for increasing similarity directly in deep networks and can expand on the generalisation capabilities and the capacity of standard 1-D convolution layer where local sequential deformations are present in the input. Experimental results demonstrate the proposed method exceeds or matches the standard 1-D convolution layer in terms of the maximum accuracy achieved on a number of time series classification tasks. In addition the impact of different hyperparameters settings is investigated given different datasets and the results support the conclusions of previous work done in relation to the choice of DTW parameter values. The proposed layer can be freely integrated with other typical layers to compose deep artificial neural networks of an arbitrary architecture that are trained using standard stochastic gradient descent.
Unsupervised Contextual Anomaly Detection using Joint Deep Variational Generative Models
Apr 01, 2019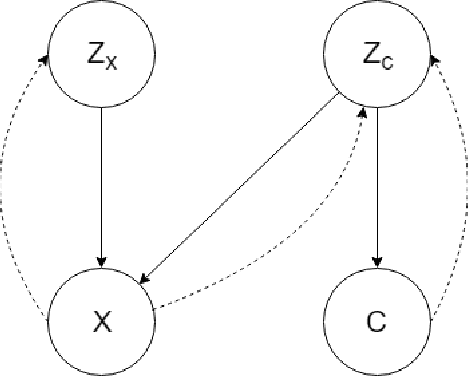
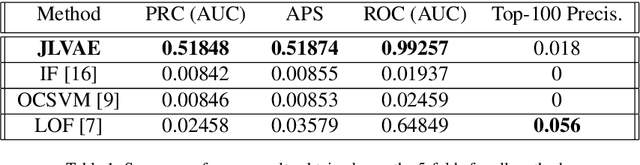
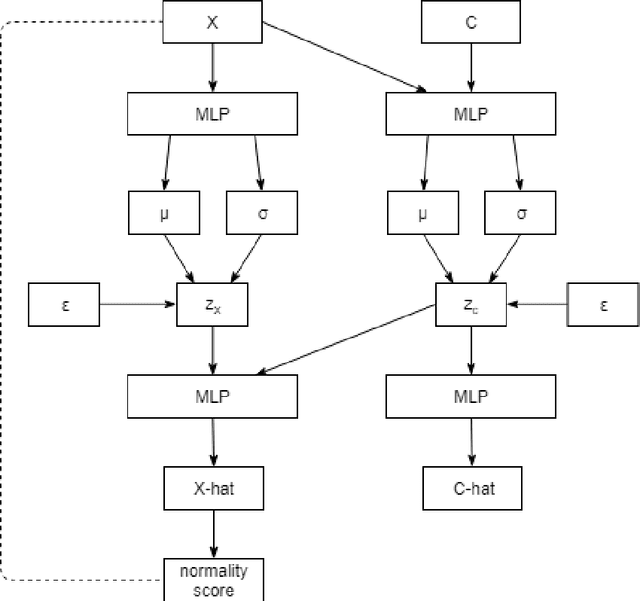
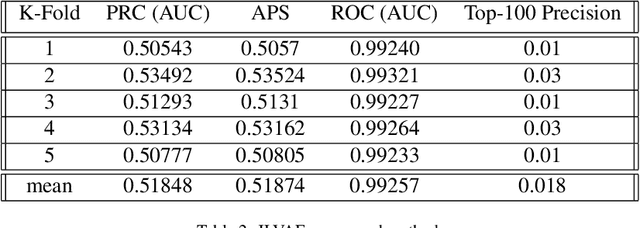
A method for unsupervised contextual anomaly detection is proposed using a cross-linked pair of Variational Auto-Encoders for assigning a normality score to an observation. The method enables a distinct separation of contextual from behavioral attributes and is robust to the presence of anomalous or novel contextual attributes. The method can be trained with data sets that contain anomalies without any special pre-processing.