 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Data-Driven Column Generation Algorithm For Bin Packing Problem in Manufacturing Industry
Feb 25, 2022
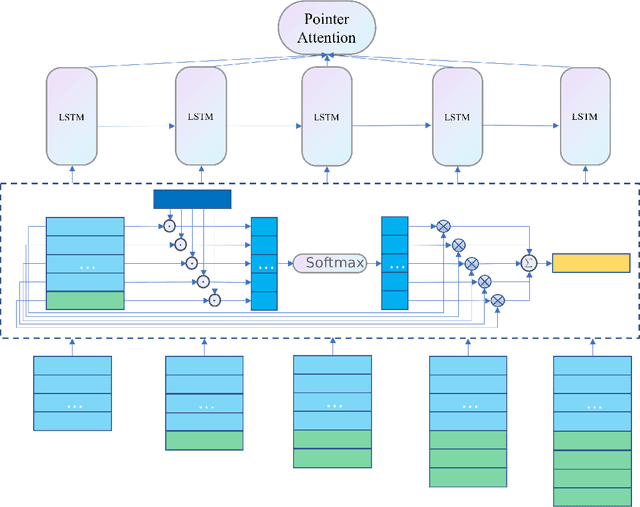

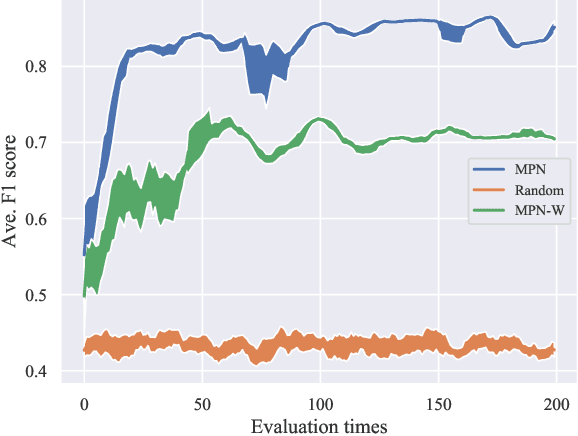

The bin packing problem exists widely in real logistic scenarios (e.g., packing pipeline, express delivery), with its goal to improve the packing efficiency and reduce the transportation cost. In this NP-hard combinatorial optimization problem, the position and quantity of each item in the box are strictly restricted by complex constraints and special customer requirements. Existing approaches are hard to obtain the optimal solution since rigorous constraints cannot be handled within a reasonable computation load. In this paper, for handling this difficulty, the packing knowledge is extracted from historical data collected from the packing pipeline of Huawei. First, by fully exploiting the relationship between historical packing records and input orders(orders to be packed) , the problem is reformulated as a set cover problem. Then, two novel strategies, the constraint handling and process acceleration strategies are applied to the classic column generation approach to solve this set cover problem. The cost of solving pricing problem for generating new columns is high due to the complex constraints and customer requirements. The proposed constraints handling strategy exploits the historical packing records with the most negative value of the reduced cost. Those constraints have been implicitly satisfied in these historical packing records so that there is no need to conduct further evaluation on constraints, thus the computational load is saved. To further eliminate the iteration process of column generation algorithm and accelerate the optimization process, a Learning to Price approach called Modified Pointer Network is proposed, by which we can determine which historical packing records should be selected directly. Through experiments on realworld datasets, we show our proposed method can improve the packing success rate and decrease the computation time simultaneously.
Dictionary Learning with Uniform Sparse Representations for Anomaly Detection
Jan 11, 2022

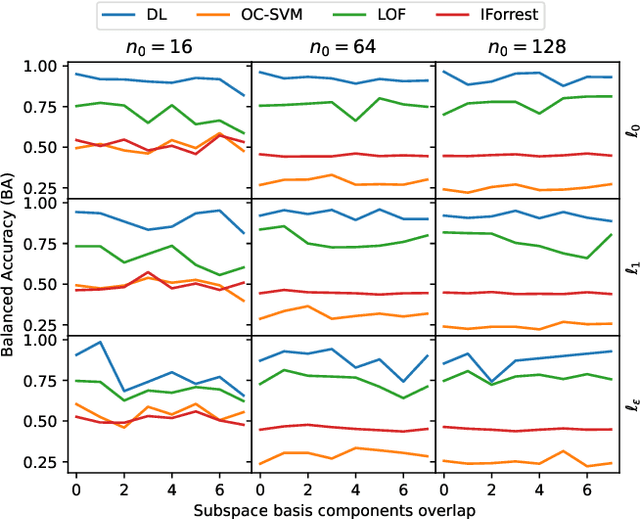
Many applications like audio and image processing show that sparse representations are a powerful and efficient signal modeling technique. Finding an optimal dictionary that generates at the same time the sparsest representations of data and the smallest approximation error is a hard problem approached by dictionary learning (DL). We study how DL performs in detecting abnormal samples in a dataset of signals. In this paper we use a particular DL formulation that seeks uniform sparse representations model to detect the underlying subspace of the majority of samples in a dataset, using a K-SVD-type algorithm. Numerical simulations show that one can efficiently use this resulted subspace to discriminate the anomalies over the regular data points.
An unsupervised extractive summarization method based on multi-round computation
Dec 06, 2021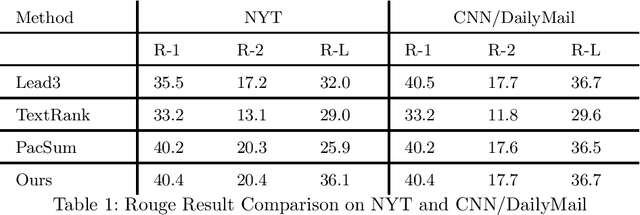
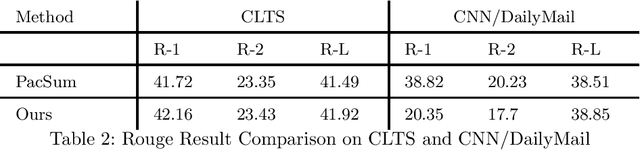
Text summarization methods have attracted much attention all the time. In recent years, deep learning has been applied to text summarization, and it turned out to be pretty effective. However, most of the current text summarization methods based on deep learning need large-scale datasets, which is difficult to achieve in practical applications. In this paper, an unsupervised extractive text summarization method based on multi-round calculation is proposed. Based on the directed graph algorithm, we change the traditional method of calculating the sentence ranking at one time to multi-round calculation, and the summary sentences are dynamically optimized after each round of calculation to better match the characteristics of the text. In this paper, experiments are carried out on four data sets, each separately containing Chinese, English, long and short texts. The experiment results show that our method has better performance than both baseline methods and other unsupervised methods and is robust on different datasets.
Social Neuro AI: Social Interaction as the "dark matter" of AI
Jan 03, 2022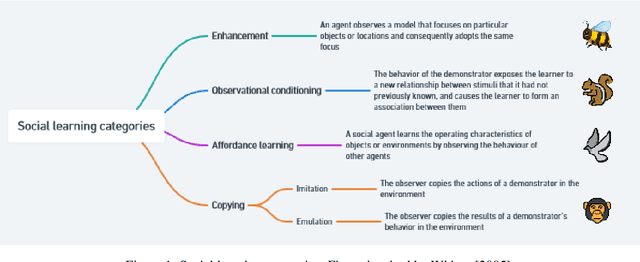
We are making the case that empirical results from social psychology and social neuroscience along with the framework of dynamics can be of inspiration to the development of more intelligent artificial agents. We specifically argue that the complex human cognitive architecture owes a large portion of its expressive power to its ability to engage in social and cultural learning. In the first section, we aim at demonstrating that social learning plays a key role in the development of intelligence. We do so by discussing social and cultural learning theories and investigating the abilities that various animals have at learning from others; we also explore findings from social neuroscience that examine human brains during social interaction and learning. Then, we discuss three proposed lines of research that fall under the umbrella of Social NeuroAI and can contribute to developing socially intelligent embodied agents in complex environments. First, neuroscientific theories of cognitive architecture, such as the global workspace theory and the attention schema theory, can enhance biological plausibility and help us understand how we could bridge individual and social theories of intelligence. Second, intelligence occurs in time as opposed to over time, and this is naturally incorporated by the powerful framework offered by dynamics. Third, social embodiment has been demonstrated to provide social interactions between virtual agents and humans with a more sophisticated array of communicative signals. To conclude, we provide a new perspective on the field of multiagent robot systems, exploring how it can advance by following the aforementioned three axes.
Vau da muntanialas: Energy-efficient multi-die scalable acceleration of RNN inference
Feb 14, 2022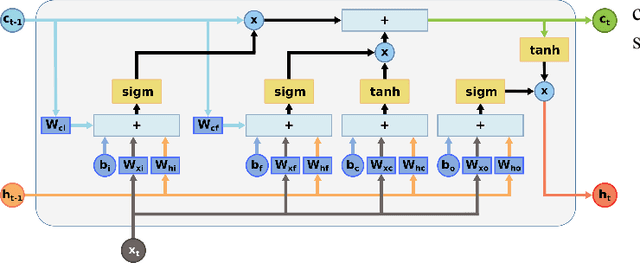

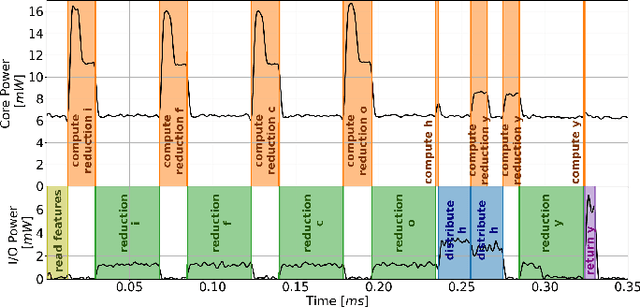
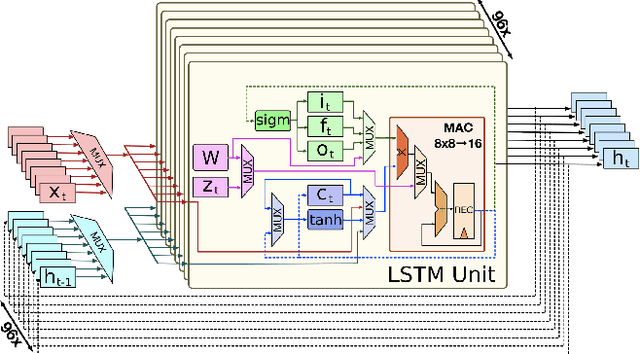
Recurrent neural networks such as Long Short-Term Memories (LSTMs) learn temporal dependencies by keeping an internal state, making them ideal for time-series problems such as speech recognition. However, the output-to-input feedback creates distinctive memory bandwidth and scalability challenges in designing accelerators for RNNs. We present Muntaniala, an RNN accelerator architecture for LSTM inference with a silicon-measured energy-efficiency of 3.25$TOP/s/W$ and performance of 30.53$GOP/s$ in UMC 65 $nm$ technology. The scalable design of Muntaniala allows running large RNN models by combining multiple tiles in a systolic array. We keep all parameters stationary on every die in the array, drastically reducing the I/O communication to only loading new features and sharing partial results with other dies. For quantifying the overall system power, including I/O power, we built Vau da Muntanialas, to the best of our knowledge, the first demonstration of a systolic multi-chip-on-PCB array of RNN accelerator. Our multi-die prototype performs LSTM inference with 192 hidden states in 330$\mu s$ with a total system power of 9.0$mW$ at 10$MHz$ consuming 2.95$\mu J$. Targeting the 8/16-bit quantization implemented in Muntaniala, we show a phoneme error rate (PER) drop of approximately 3% with respect to floating-point (FP) on a 3L-384NH-123NI LSTM network on the TIMIT dataset.
On Submodular Contextual Bandits
Dec 03, 2021We consider the problem of contextual bandits where actions are subsets of a ground set and mean rewards are modeled by an unknown monotone submodular function that belongs to a class $\mathcal{F}$. We allow time-varying matroid constraints to be placed on the feasible sets. Assuming access to an online regression oracle with regret $\mathsf{Reg}(\mathcal{F})$, our algorithm efficiently randomizes around local optima of estimated functions according to the Inverse Gap Weighting strategy. We show that cumulative regret of this procedure with time horizon $n$ scales as $O(\sqrt{n \mathsf{Reg}(\mathcal{F})})$ against a benchmark with a multiplicative factor $1/2$. On the other hand, using the techniques of (Filmus and Ward 2014), we show that an $\epsilon$-Greedy procedure with local randomization attains regret of $O(n^{2/3} \mathsf{Reg}(\mathcal{F})^{1/3})$ against a stronger $(1-e^{-1})$ benchmark.
LG-LSQ: Learned Gradient Linear Symmetric Quantization
Feb 18, 2022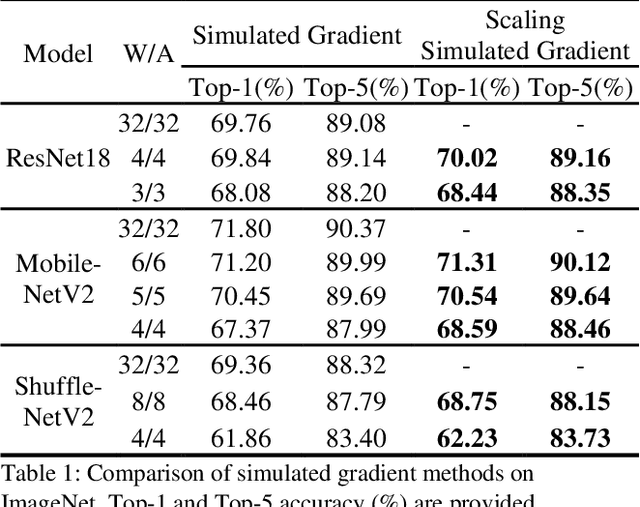
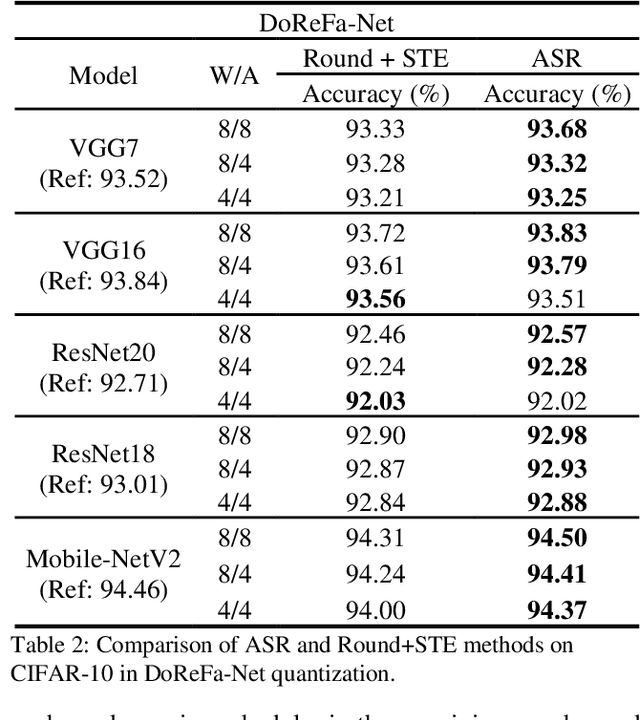
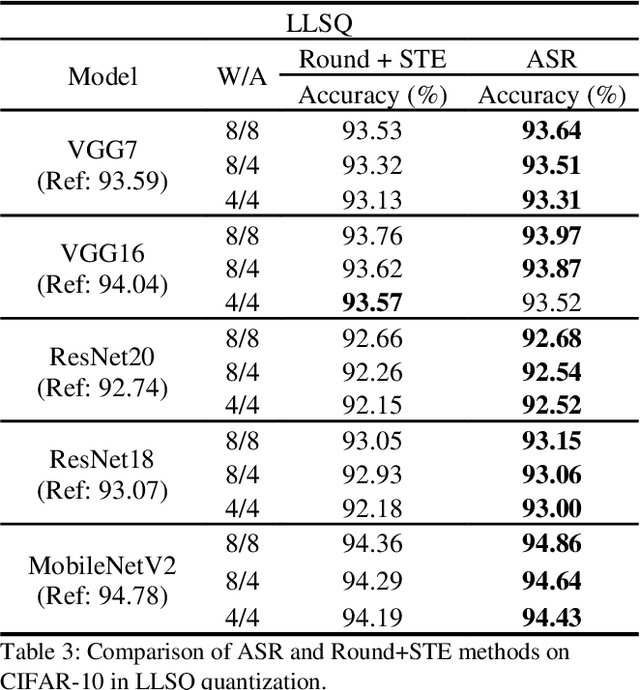
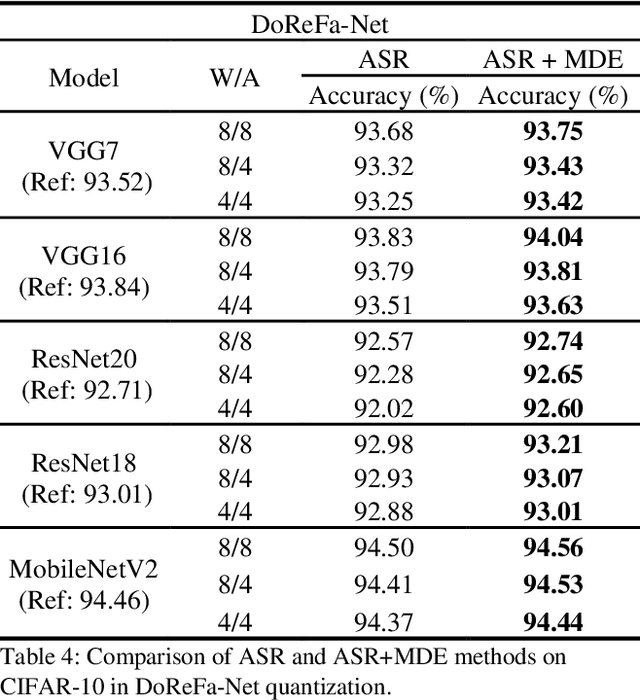
Deep neural networks with lower precision weights and operations at inference time have advantages in terms of the cost of memory space and accelerator power. The main challenge associated with the quantization algorithm is maintaining accuracy at low bit-widths. We propose learned gradient linear symmetric quantization (LG-LSQ) as a method for quantizing weights and activation functions to low bit-widths with high accuracy in integer neural network processors. First, we introduce the scaling simulated gradient (SSG) method for determining the appropriate gradient for the scaling factor of the linear quantizer during the training process. Second, we introduce the arctangent soft round (ASR) method, which differs from the straight-through estimator (STE) method in its ability to prevent the gradient from becoming zero, thereby solving the discrete problem caused by the rounding process. Finally, to bridge the gap between full-precision and low-bit quantization networks, we propose the minimize discretization error (MDE) method to determine an accurate gradient in backpropagation. The ASR+MDE method is a simple alternative to the STE method and is practical for use in different uniform quantization methods. In our evaluation, the proposed quantizer achieved full-precision baseline accuracy in various 3-bit networks, including ResNet18, ResNet34, and ResNet50, and an accuracy drop of less than 1% in the quantization of 4-bit weights and 4-bit activations in lightweight models such as MobileNetV2 and ShuffleNetV2.
Data Sensing and Offloading in Edge Computing Networks: TDMA or NOMA?
Nov 22, 2021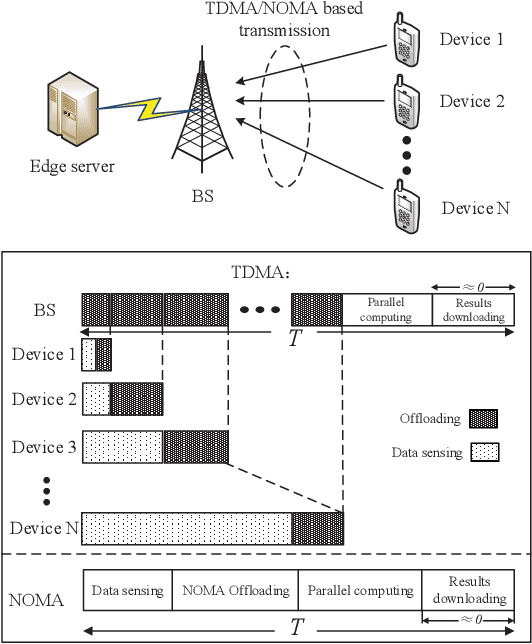
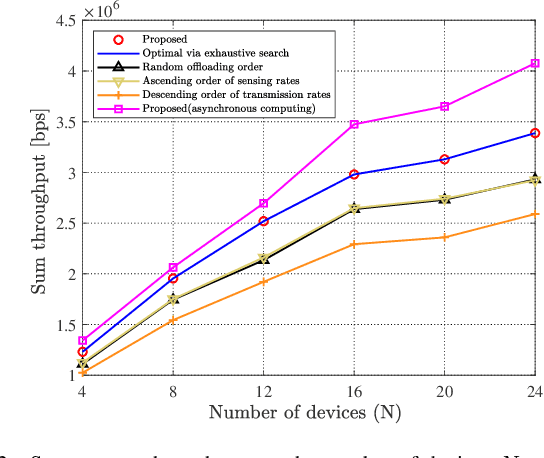
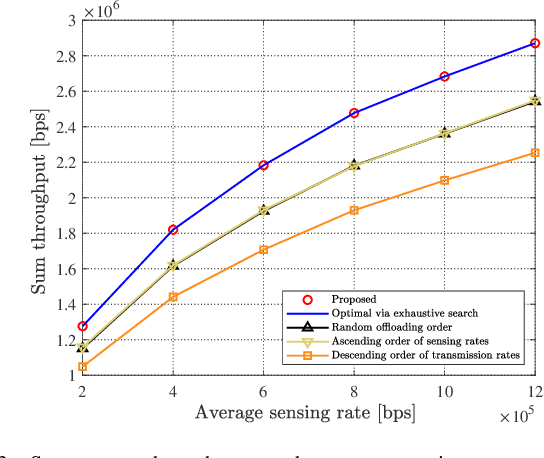
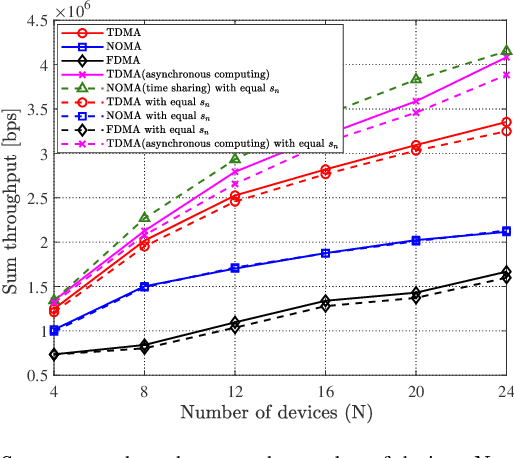
With the development of Internet-of-Things (IoT), we witness the explosive growth in the number of devices with sensing, computing, and communication capabilities, along with a large amount of raw data generated at the network edge. Mobile (multi-access) edge computing (MEC), acquiring and processing data at network edge (like base station (BS)) via wireless links, has emerged as a promising technique for real-time applications. In this paper, we consider the scenario that multiple devices sense then offload data to an edge server/BS, and the offloading throughput maximization problems are studied by joint radio-and-computation resource allocation, based on time-division multiple access (TDMA) and non-orthogonal multiple access (NOMA) multiuser computation offloading. Particularly, we take the sequence of TDMA-based multiuser transmission/offloading into account. The studied problems are NP-hard and non-convex. A set of low-complexity algorithms are designed based on decomposition approach and exploration of valuable insights of problems. They are either optimal or can achieve close-to-optimal performance as shown by simulation. The comprehensive simulation results show that the sequence optimized TDMA scheme achieves better throughput performance than the NOMA scheme, while the NOMA scheme is better under the assumptions of time-sharing strategy and the identical sensing capability of the devices.
ICA-UNet: ICA Inspired Statistical UNet for Real-time 3D Cardiac Cine MRI Segmentation
Jul 18, 2020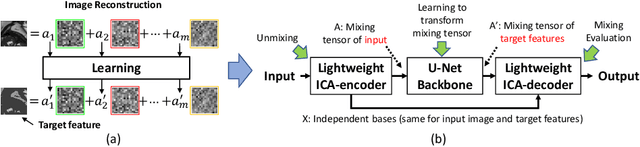
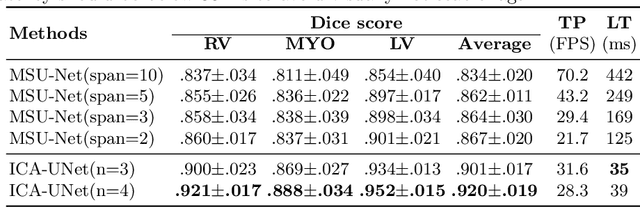
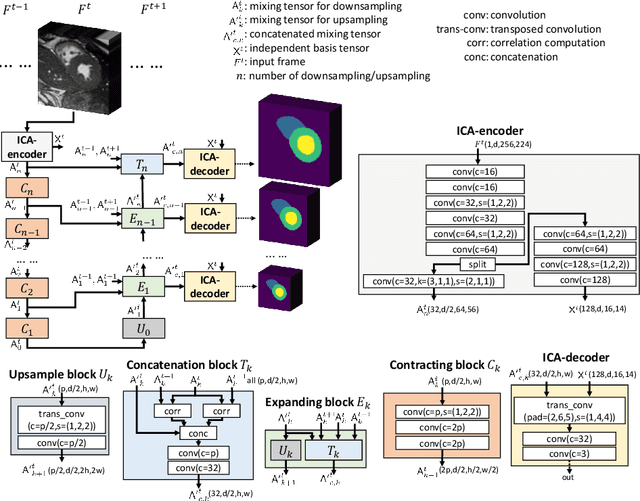
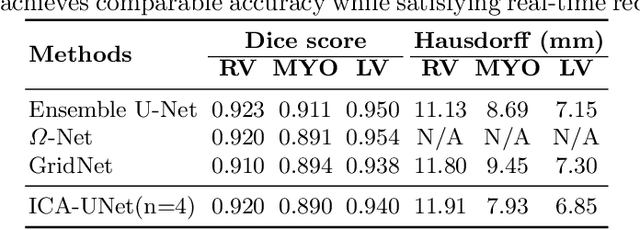
Real-time cine magnetic resonance imaging (MRI) plays an increasingly important role in various cardiac interventions. In order to enable fast and accurate visual assistance, the temporal frames need to be segmented on-the-fly. However, state-of-the-art MRI segmentation methods are used either offline because of their high computation complexity, or in real-time but with significant accuracy loss and latency increase (causing visually noticeable lag). As such, they can hardly be adopted to assist visual guidance. In this work, inspired by a new interpretation of Independent Component Analysis (ICA) for learning, we propose a novel ICA-UNet for real-time 3D cardiac cine MRI segmentation. Experiments using the MICCAI ACDC 2017 dataset show that, compared with the state-of-the-arts, ICA-UNet not only achieves higher Dice scores, but also meets the real-time requirements for both throughput and latency (up to 12.6X reduction), enabling real-time guidance for cardiac interventions without visual lag.
Real-time Pupil Tracking from Monocular Video for Digital Puppetry
Jun 19, 2020
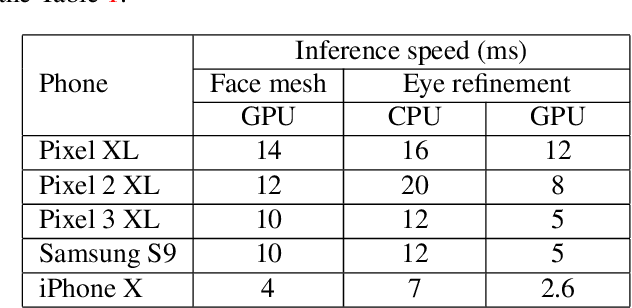
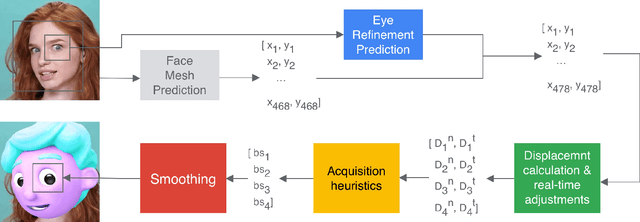
We present a simple, real-time approach for pupil tracking from live video on mobile devices. Our method extends a state-of-the-art face mesh detector with two new components: a tiny neural network that predicts positions of the pupils in 2D, and a displacement-based estimation of the pupil blend shape coefficients. Our technique can be used to accurately control the pupil movements of a virtual puppet, and lends liveliness and energy to it. The proposed approach runs at over 50 FPS on modern phones, and enables its usage in any real-time puppeteering pipeline.