 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Lattice-Based Methods Surpass Sum-of-Squares in Clustering
Dec 07, 2021
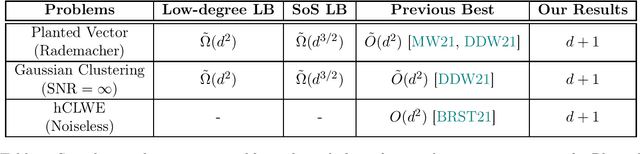
Clustering is a fundamental primitive in unsupervised learning which gives rise to a rich class of computationally-challenging inference tasks. In this work, we focus on the canonical task of clustering $d$-dimensional Gaussian mixtures with unknown (and possibly degenerate) covariance. Recent works (Ghosh et al.\ '20; Mao, Wein '21; Davis, Diaz, Wang '21) have established lower bounds against the class of low-degree polynomial methods and the sum-of-squares (SoS) hierarchy for recovering certain hidden structures planted in Gaussian clustering instances. Prior work on many similar inference tasks portends that such lower bounds strongly suggest the presence of an inherent statistical-to-computational gap for clustering, that is, a parameter regime where the clustering task is \textit{statistically} possible but no \textit{polynomial-time} algorithm succeeds. One special case of the clustering task we consider is equivalent to the problem of finding a planted hypercube vector in an otherwise random subspace. We show that, perhaps surprisingly, this particular clustering model \textit{does not exhibit} a statistical-to-computational gap, even though the aforementioned low-degree and SoS lower bounds continue to apply in this case. To achieve this, we give a polynomial-time algorithm based on the Lenstra--Lenstra--Lovasz lattice basis reduction method which achieves the statistically-optimal sample complexity of $d+1$ samples. This result extends the class of problems whose conjectured statistical-to-computational gaps can be "closed" by "brittle" polynomial-time algorithms, highlighting the crucial but subtle role of noise in the onset of statistical-to-computational gaps.
Visual attention analysis of pathologists examining whole slide images of Prostate cancer
Feb 17, 2022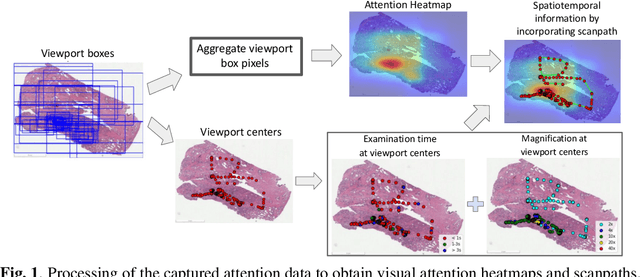
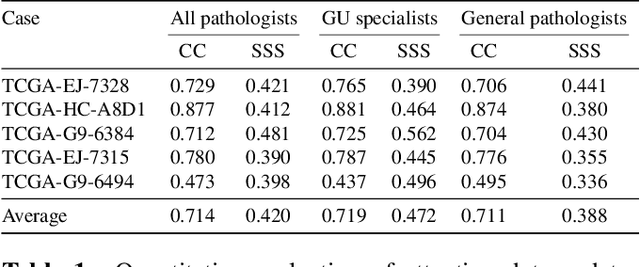
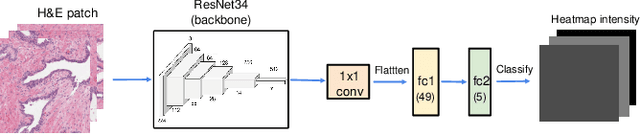
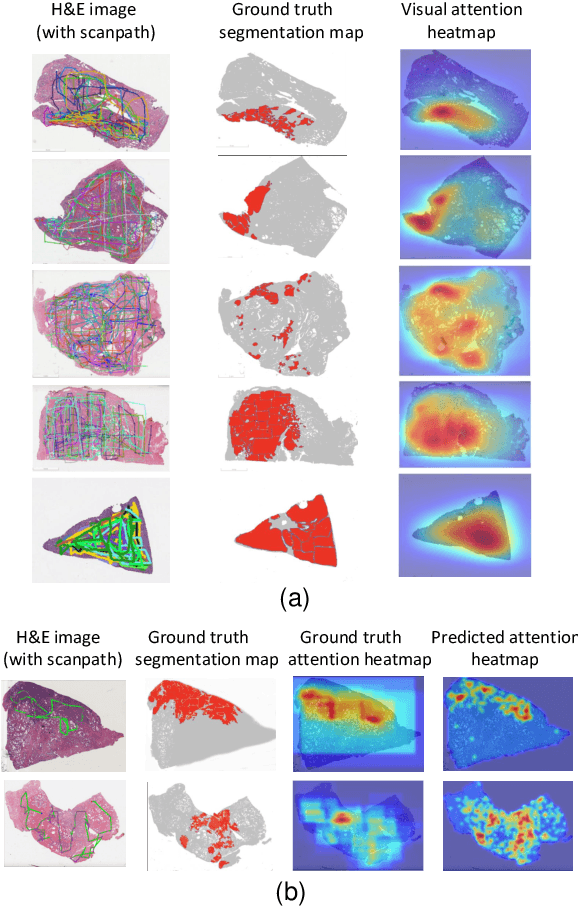
We study the attention of pathologists as they examine whole-slide images (WSIs) of prostate cancer tissue using a digital microscope. To the best of our knowledge, our study is the first to report in detail how pathologists navigate WSIs of prostate cancer as they accumulate information for their diagnoses. We collected slide navigation data (i.e., viewport location, magnification level, and time) from 13 pathologists in 2 groups (5 genitourinary (GU) specialists and 8 general pathologists) and generated visual attention heatmaps and scanpaths. Each pathologist examined five WSIs from the TCGA PRAD dataset, which were selected by a GU pathology specialist. We examined and analyzed the distributions of visual attention for each group of pathologists after each WSI was examined. To quantify the relationship between a pathologist's attention and evidence for cancer in the WSI, we obtained tumor annotations from a genitourinary specialist. We used these annotations to compute the overlap between the distribution of visual attention and annotated tumor region to identify strong correlations. Motivated by this analysis, we trained a deep learning model to predict visual attention on unseen WSIs. We find that the attention heatmaps predicted by our model correlate quite well with the ground truth attention heatmap and tumor annotations on a test set of 17 WSIs by using various spatial and temporal evaluation metrics.
CEM-GD: Cross-Entropy Method with Gradient Descent Planner for Model-Based Reinforcement Learning
Dec 14, 2021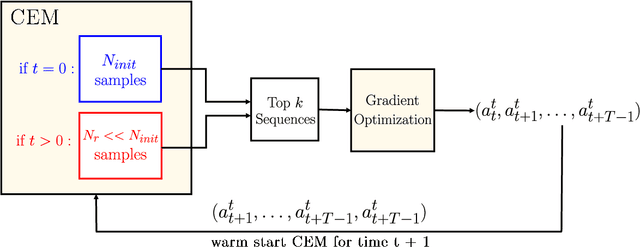
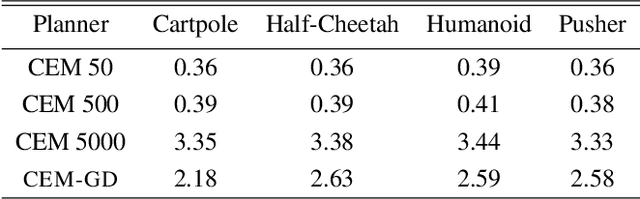
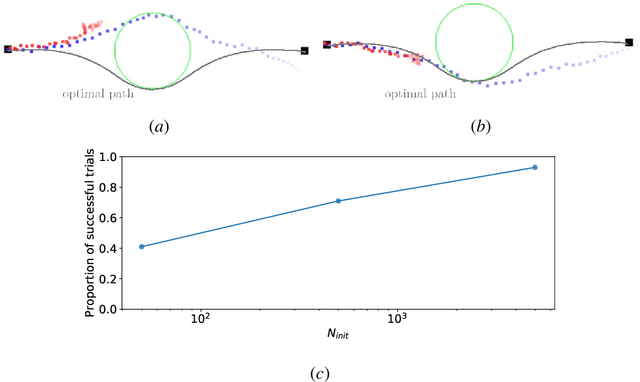
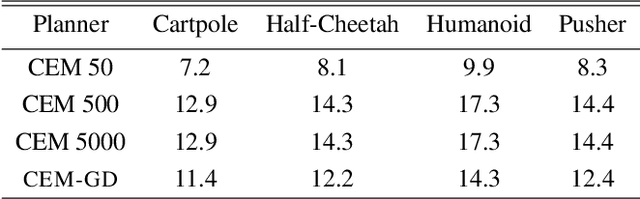
Current state-of-the-art model-based reinforcement learning algorithms use trajectory sampling methods, such as the Cross-Entropy Method (CEM), for planning in continuous control settings. These zeroth-order optimizers require sampling a large number of trajectory rollouts to select an optimal action, which scales poorly for large prediction horizons or high dimensional action spaces. First-order methods that use the gradients of the rewards with respect to the actions as an update can mitigate this issue, but suffer from local optima due to the non-convex optimization landscape. To overcome these issues and achieve the best of both worlds, we propose a novel planner, Cross-Entropy Method with Gradient Descent (CEM-GD), that combines first-order methods with CEM. At the beginning of execution, CEM-GD uses CEM to sample a significant amount of trajectory rollouts to explore the optimization landscape and avoid poor local minima. It then uses the top trajectories as initialization for gradient descent and applies gradient updates to each of these trajectories to find the optimal action sequence. At each subsequent time step, however, CEM-GD samples much fewer trajectories from CEM before applying gradient updates. We show that as the dimensionality of the planning problem increases, CEM-GD maintains desirable performance with a constant small number of samples by using the gradient information, while avoiding local optima using initially well-sampled trajectories. Furthermore, CEM-GD achieves better performance than CEM on a variety of continuous control benchmarks in MuJoCo with 100x fewer samples per time step, resulting in around 25% less computation time and 10% less memory usage. The implementation of CEM-GD is available at $\href{https://github.com/KevinHuang8/CEM-GD}{\text{https://github.com/KevinHuang8/CEM-GD}}$.
Cybertrust: From Explainable to Actionable and Interpretable AI (AI2)
Jan 26, 2022To benefit from AI advances, users and operators of AI systems must have reason to trust it. Trust arises from multiple interactions, where predictable and desirable behavior is reinforced over time. Providing the system's users with some understanding of AI operations can support predictability, but forcing AI to explain itself risks constraining AI capabilities to only those reconcilable with human cognition. We argue that AI systems should be designed with features that build trust by bringing decision-analytic perspectives and formal tools into AI. Instead of trying to achieve explainable AI, we should develop interpretable and actionable AI. Actionable and Interpretable AI (AI2) will incorporate explicit quantifications and visualizations of user confidence in AI recommendations. In doing so, it will allow examining and testing of AI system predictions to establish a basis for trust in the systems' decision making and ensure broad benefits from deploying and advancing its computational capabilities.
Pattern Recognition and Event Detection on IoT Data-streams
Mar 02, 2022
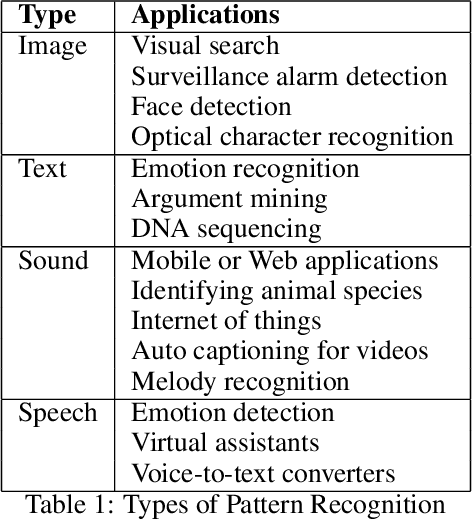

Big data streams are possibly one of the most essential underlying notions. However, data streams are often challenging to handle owing to their rapid pace and limited information lifetime. It is difficult to collect and communicate stream samples while storing, transmitting and computing a function across the whole stream or even a large segment of it. In answer to this research issue, many streaming-specific solutions were developed. Stream techniques imply a limited capacity of one or more resources such as computing power and memory, as well as time or accuracy limits. Reservoir sampling algorithms choose and store results that are probabilistically significant. A weighted random sampling approach using a generalised sampling algorithmic framework to detect unique events is the key research goal of this work. Briefly, a gradually developed estimate of the joint stream distribution across all feasible components keeps k stream elements judged representative for the full stream. Once estimate confidence is high, k samples are chosen evenly. The complexity is O(min(k,n-k)), where n is the number of items inspected. Due to the fact that events are usually considered outliers, it is sufficient to extract element patterns and push them to an alternate version of k-means as proposed here. The suggested technique calculates the sum of squared errors (SSE) for each cluster, and this is utilised not only as a measure of convergence, but also as a quantification and an indirect assessment of the element distribution's approximation accuracy. This clustering enables for the detection of outliers in the stream based on their distance from the usual event centroids. The findings reveal that weighted sampling and res-means outperform typical approaches for stream event identification. Detected events are shown as knowledge graphs, along with typical clusters of events.
Ranking by Momentum based on Pareto ordering of entities
Nov 25, 2021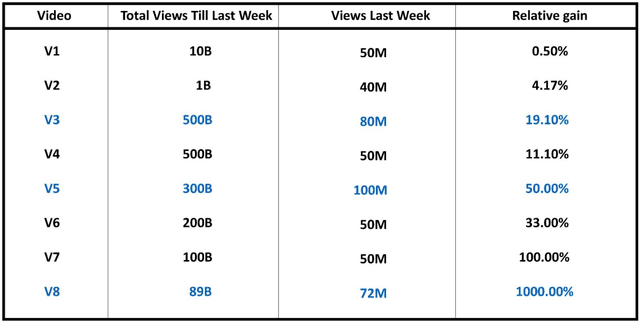
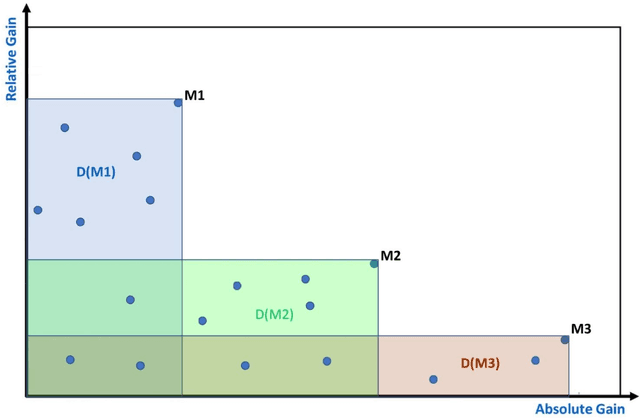
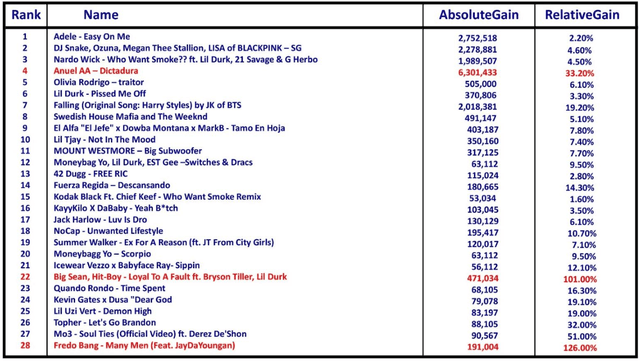
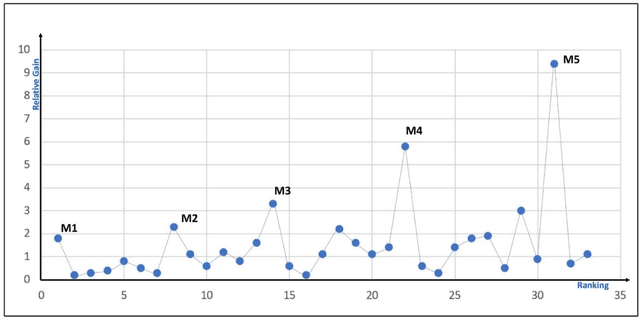
Given a set of changing entities, which ones are the most uptrending over some time T? Which entities are standing out as the biggest movers? To answer this question we define the concept of momentum. Two parameters - absolute gain and relative gain over time T play the key role in defining momentum. Neither alone is sufficient since they are each biased towards a subset of entities. Absolute gain favors large entities, while relative gain favors small ones. To accommodate both absolute and relative gain in an unbiased way, we define Pareto ordering between entities. For entity E to dominate another entity F in Pareto ordering, E's absolute and relative gains over time T must be higher than F's absolute and relative gains respectively. Momentum leaders are defined as maximal elements of this partial order - the Pareto frontier. We show how to compute momentum leaders and propose linear ordering among them to help rank entities with the most momentum on the top. Additionally, we show that when vectors follow power-law, the cardinality of the set of Momentum leaders (Pareto frontier) is of the order of square root of the logarithm of the number of entities, thus it is very small.
MIRA: Multihop Relation Prediction in Temporal Knowledge Graphs
Oct 27, 2021
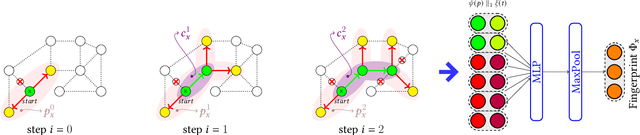
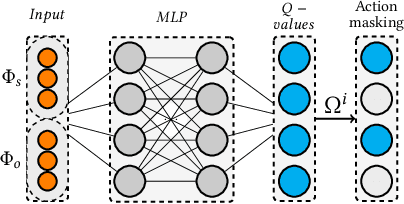
In knowledge graph reasoning, we observe a trend to analyze temporal data evolving over time. The additional temporal dimension is attached to facts in a knowledge base resulting in quadruples between entities such as (Nintendo, released, Super Mario, Sep-13-1985), where the relation between two entities is associated to a specific time interval or point in time. Multi-hop reasoning on inferred subgraphs connecting entities within a knowledge graph can be formulated as a reinforcement learning task where the agent sequentially performs inference upon the explored subgraph. The task in this work is to infer the predicate between a subject and an object entity, i.e., (subject, ?, object, time), being valid at a certain timestamp or time interval. Given query entities, our agent starts to gather temporal relevant information about the neighborhood of the subject and object. The encoding of information about the explored graph structures is referred to as fingerprints. Subsequently, we use the two fingerprints as input to a Q-Network. Our agent decides sequentially which relational type needs to be explored next expanding the local subgraphs of the query entities in order to find promising paths between them. The evaluation shows that the proposed method not only yields results being in line with state-of-the-art embedding algorithms for temporal Knowledge Graphs (tKG), but we also gain information about the relevant structures between subjects and objects.
Predictive Beamforming for Integrated Sensing and Communication in Vehicular Networks: A Deep Learning Approach
Feb 08, 2022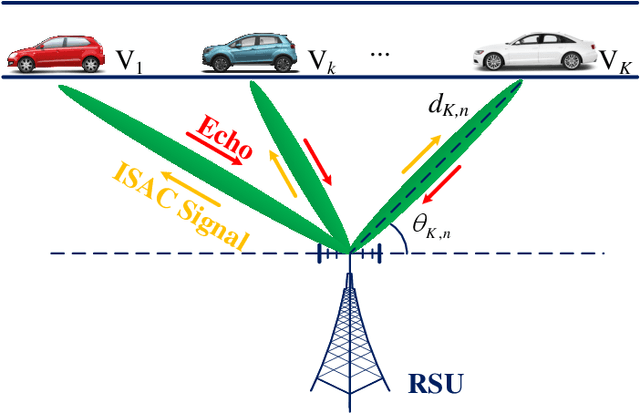
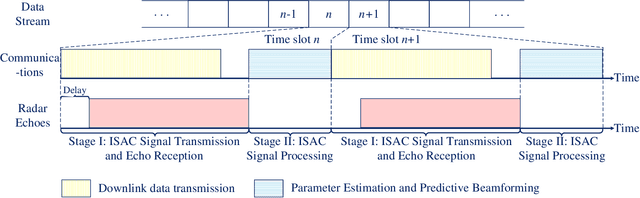
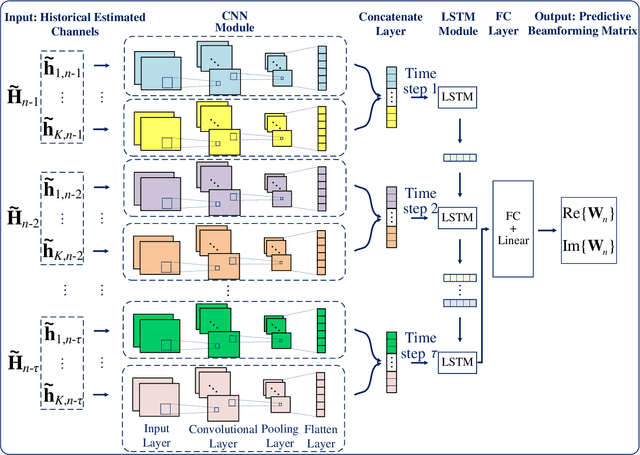
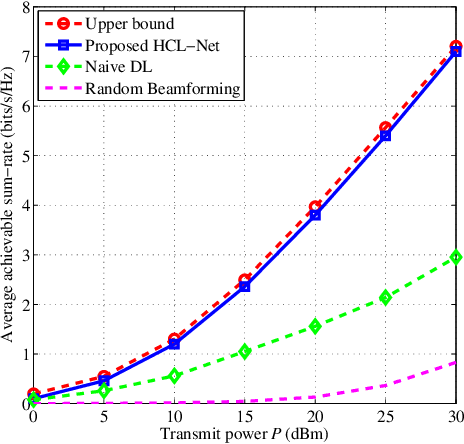
The implementation of integrated sensing and communication (ISAC) highly depends on the effective beamforming design exploiting accurate instantaneous channel state information (ICSI). However, channel tracking in ISAC requires large amount of training overhead and prohibitively large computational complexity. To address this problem, in this paper, we focus on ISAC-assisted vehicular networks and exploit a deep learning approach to implicitly learn the features of historical channels and directly predict the beamforming matrix for the next time slot to maximize the average achievable sum-rate of system, thus bypassing the need of explicit channel tracking for reducing the system signaling overhead. To this end, a general sum-rate maximization problem with Cramer-Rao lower bounds-based sensing constraints is first formulated for the considered ISAC system. Then, a historical channels-based convolutional long short-term memory network is designed for predictive beamforming that can exploit the spatial and temporal dependencies of communication channels to further improve the learning performance. Finally, simulation results show that the proposed method can satisfy the requirement of sensing performance, while its achievable sum-rate can approach the upper bound obtained by a genie-aided scheme with perfect ICSI available.
Fast Server Learning Rate Tuning for Coded Federated Dropout
Jan 26, 2022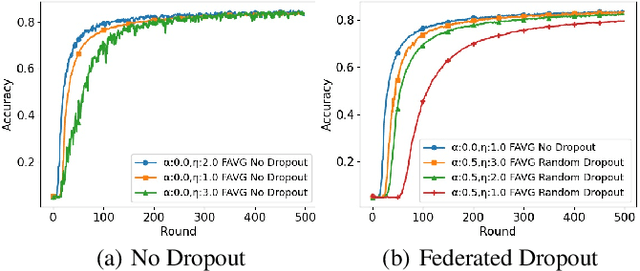
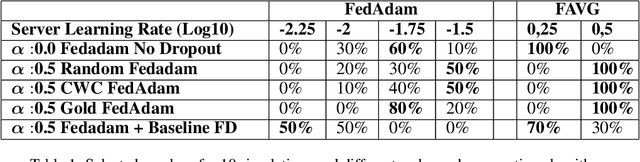
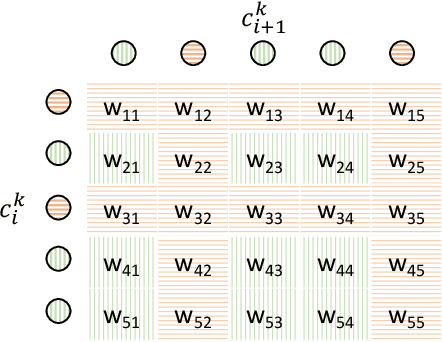
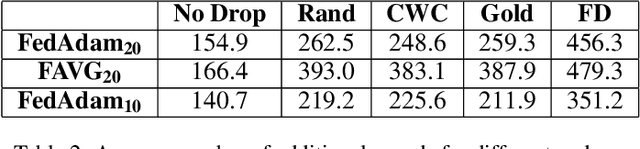
In cross-device Federated Learning (FL), clients with low computational power train a common machine model by exchanging parameters updates instead of potentially private data. Federated Dropout (FD) is a technique that improves the communication efficiency of a FL session by selecting a subset of model variables to be updated in each training round. However, FD produces considerably lower accuracy and higher convergence time compared to standard FL. In this paper, we leverage coding theory to enhance FD by allowing a different sub-model to be used at each client. We also show that by carefully tuning the server learning rate hyper-parameter, we can achieve higher training speed and up to the same final accuracy of the no dropout case. For the EMNIST dataset, our mechanism achieves 99.6 % of the final accuracy of the no dropout case while requiring 2.43x less bandwidth to achieve this accuracy level.
Computational Aspects of Conditional Minisum Approval Voting in Elections with Interdependent Issues
Feb 03, 2022

Approval voting provides a simple, practical framework for multi-issue elections, and the most representative example among such election rules is the classic Minisum approval voting rule. We consider a generalization of Minisum, introduced by the work of Barrot and Lang [2016], referred to as Conditional Minisum, where voters are also allowed to express dependencies between issues. The price we have to pay when we move to this higher level of expressiveness is that we end up with a computationally hard rule. Motivated by this, we focus on the computational aspects of Conditional Minisum, where progress has been rather scarce so far. We identify restrictions that concern the voters' dependencies and the value of an optimal solution, under which we provide the first multiplicative approximation algorithms for the problem. At the same time, by additionally requiring certain structural properties for the union of dependencies cast by the whole electorate, we obtain optimal efficient algorithms for well-motivated special cases. Overall, our work provides a better understanding on the complexity implications introduced by conditional voting.
* corrected version of the following IJCAI-20 publication: Evangelos Markakis and Georgios Papasotiropoulos. Computational aspects of conditional minisum approval voting in elections with interdependent issues. In Proceedings of the 22nd International Joint Conference on Artificial Intelligence (IJCAI-20), pages 304-310, 2020. (link: https://www.ijcai.org/Proceedings/2020/0043.pdf)