 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlockchain For Mobile Health Applications: Acceleration With GPU Computing
Jan 11, 2023Blockchain is a linearly linked, distributed, and very robust data structure. Originally proposed as part of the Bitcoin distributed stack, it found a number of applications in a number of fields, most notably in smart contracts, social media, secure IoT, and cryptocurrency mining. It ensures data integrity by distributing strongly encrypted data in widely redundant segments. Each new insertion requires verification and approval by the majority of the users of the blockchain. Both encryption and verification are computationally intensive tasks which cannot be solved with ordinary off-the-shelf CPUs. This has resulted in a renewed scientific interest in secure distributed communication and coordination protocols. Mobile health applications are growing progressively popular and have the enormous advantage of timely diagnosis of certain conditions. However, privacy concerns have been raised as mobile health application by default have access to highly sensitive personal data. This chapter presents concisely how blockchain can be applied to mobile health applications in order to enhance privacy.
Pattern Recognition and Event Detection on IoT Data-streams
Mar 02, 2022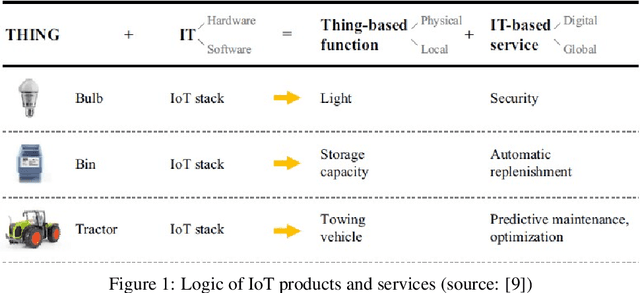
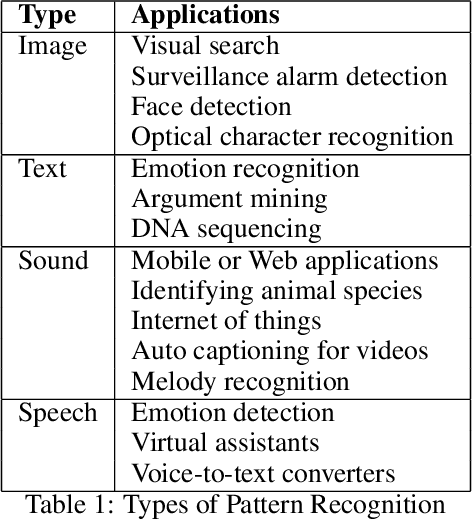

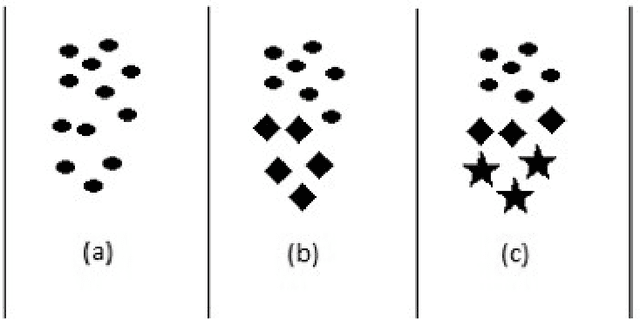
Big data streams are possibly one of the most essential underlying notions. However, data streams are often challenging to handle owing to their rapid pace and limited information lifetime. It is difficult to collect and communicate stream samples while storing, transmitting and computing a function across the whole stream or even a large segment of it. In answer to this research issue, many streaming-specific solutions were developed. Stream techniques imply a limited capacity of one or more resources such as computing power and memory, as well as time or accuracy limits. Reservoir sampling algorithms choose and store results that are probabilistically significant. A weighted random sampling approach using a generalised sampling algorithmic framework to detect unique events is the key research goal of this work. Briefly, a gradually developed estimate of the joint stream distribution across all feasible components keeps k stream elements judged representative for the full stream. Once estimate confidence is high, k samples are chosen evenly. The complexity is O(min(k,n-k)), where n is the number of items inspected. Due to the fact that events are usually considered outliers, it is sufficient to extract element patterns and push them to an alternate version of k-means as proposed here. The suggested technique calculates the sum of squared errors (SSE) for each cluster, and this is utilised not only as a measure of convergence, but also as a quantification and an indirect assessment of the element distribution's approximation accuracy. This clustering enables for the detection of outliers in the stream based on their distance from the usual event centroids. The findings reveal that weighted sampling and res-means outperform typical approaches for stream event identification. Detected events are shown as knowledge graphs, along with typical clusters of events.
Using Hadoop for Large Scale Analysis on Twitter: A Technical Report
Feb 03, 2016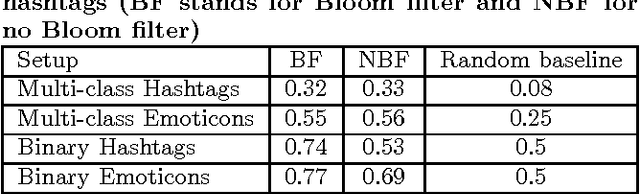

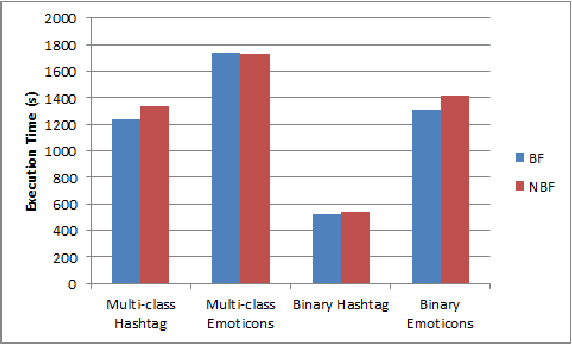
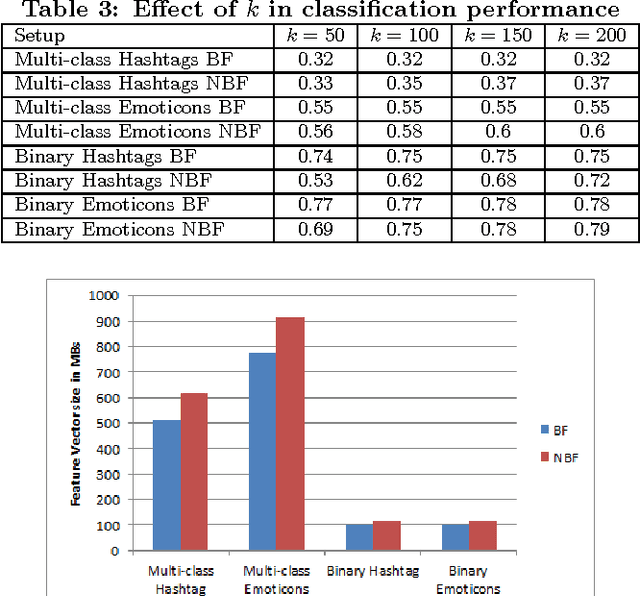
Sentiment analysis (or opinion mining) on Twitter data has attracted much attention recently. One of the system's key features, is the immediacy in communication with other users in an easy, user-friendly and fast way. Consequently, people tend to express their feelings freely, which makes Twitter an ideal source for accumulating a vast amount of opinions towards a wide diversity of topics. This amount of information offers huge potential and can be harnessed to receive the sentiment tendency towards these topics. However, since none can invest an infinite amount of time to read through these tweets, an automated decision making approach is necessary. Nevertheless, most existing solutions are limited in centralized environments only. Thus, they can only process at most a few thousand tweets. Such a sample, is not representative to define the sentiment polarity towards a topic due to the massive number of tweets published daily. In this paper, we go one step further and develop a novel method for sentiment learning in the MapReduce framework. Our algorithm exploits the hashtags and emoticons inside a tweet, as sentiment labels, and proceeds to a classification procedure of diverse sentiment types in a parallel and distributed manner. Moreover, we utilize Bloom filters to compact the storage size of intermediate data and boost the performance of our algorithm. Through an extensive experimental evaluation, we prove that our solution is efficient, robust and scalable and confirm the quality of our sentiment identification.