 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating User and Item Reviews in Deep Cooperative Neural Networks for Movie Ranking Prediction
May 19, 2022
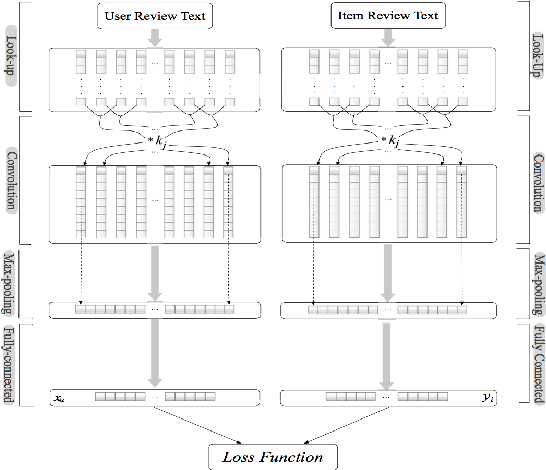
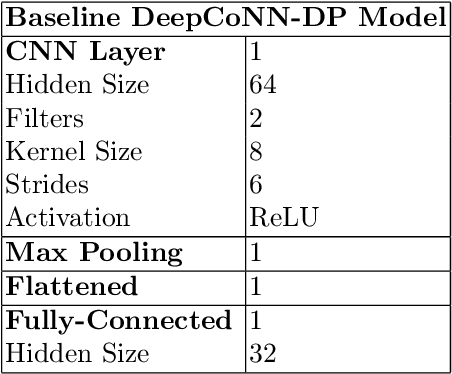
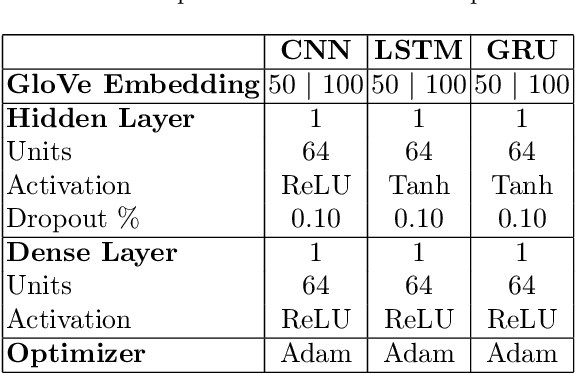
User evaluations include a significant quantity of information across online platforms. This information source has been neglected by the majority of existing recommendation systems, despite its potential to ease the sparsity issue and enhance the quality of suggestions. This work presents a deep model for concurrently learning item attributes and user behaviour from review text. Deep Cooperative Neural Network (DeepCoNN) is the suggested model consisting of two parallel neural networks connected in their final layers. One of the networks focuses on learning user behaviour from reviews submitted by the user, while the other network learns item attributes from user reviews. On top, a shared layer is added to connect these two networks. Similar to factorization machine approaches, the shared layer allows latent factors acquired for people and things to interact with each other. On a number of datasets, DeepCoNN surpasses all baseline recommendation systems, according to experimental findings.
Pattern Recognition and Event Detection on IoT Data-streams
Mar 02, 2022

Big data streams are possibly one of the most essential underlying notions. However, data streams are often challenging to handle owing to their rapid pace and limited information lifetime. It is difficult to collect and communicate stream samples while storing, transmitting and computing a function across the whole stream or even a large segment of it. In answer to this research issue, many streaming-specific solutions were developed. Stream techniques imply a limited capacity of one or more resources such as computing power and memory, as well as time or accuracy limits. Reservoir sampling algorithms choose and store results that are probabilistically significant. A weighted random sampling approach using a generalised sampling algorithmic framework to detect unique events is the key research goal of this work. Briefly, a gradually developed estimate of the joint stream distribution across all feasible components keeps k stream elements judged representative for the full stream. Once estimate confidence is high, k samples are chosen evenly. The complexity is O(min(k,n-k)), where n is the number of items inspected. Due to the fact that events are usually considered outliers, it is sufficient to extract element patterns and push them to an alternate version of k-means as proposed here. The suggested technique calculates the sum of squared errors (SSE) for each cluster, and this is utilised not only as a measure of convergence, but also as a quantification and an indirect assessment of the element distribution's approximation accuracy. This clustering enables for the detection of outliers in the stream based on their distance from the usual event centroids. The findings reveal that weighted sampling and res-means outperform typical approaches for stream event identification. Detected events are shown as knowledge graphs, along with typical clusters of events.