 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RIFE: Real-Time Intermediate Flow Estimation for Video Frame Interpolation
Nov 17, 2020
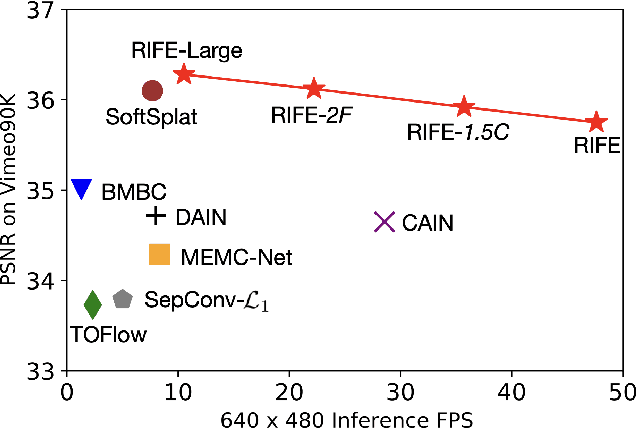

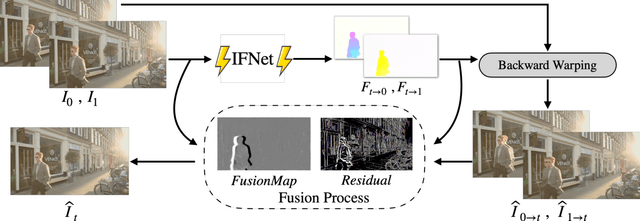
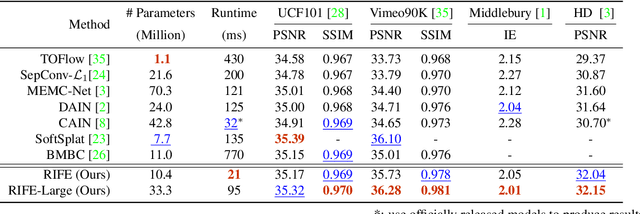
We propose RIFE, a Real-time Intermediate Flow Estimation algorithm for Video Frame Interpolation (VFI). Most existing methods first estimate the bi-directional optical flows and then linearly combine them to approximate intermediate flows, leading to artifacts on motion boundaries. RIFE uses a neural network named IFNet that can directly estimate the intermediate flows from images. With the more precise flows and our simplified fusion process, RIFE can improve interpolation quality and have much better speed. Based on our proposed leakage distillation loss, RIFE can be trained in an end-to-end fashion. Experiments demonstrate that our method is significantly faster than existing VFI methods and can achieve state-of-the-art performance on public benchmarks. The code is available at https://github.com/hzwer/arXiv2020-RIFE.
Unifying Pairwise Interactions in Complex Dynamics
Jan 28, 2022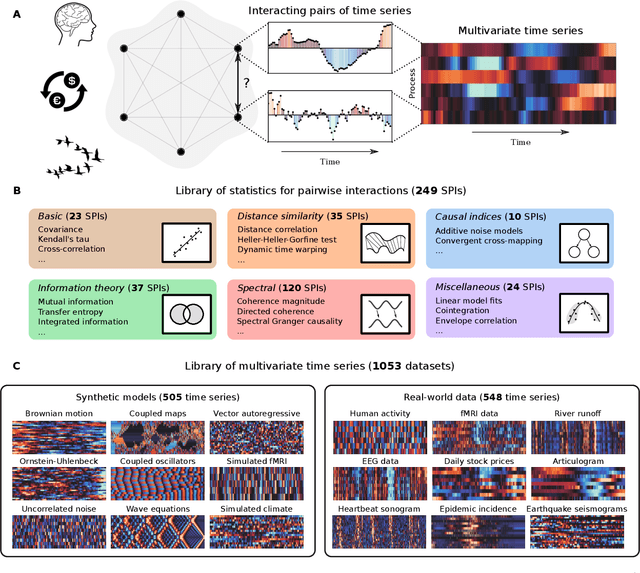
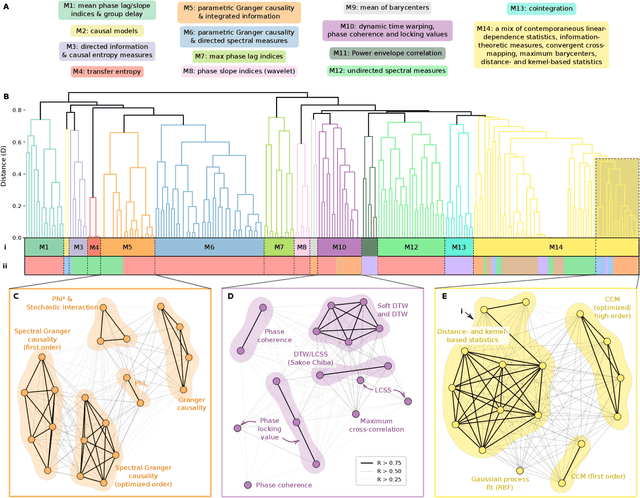
Scientists have developed hundreds of techniques to measure the interactions between pairs of processes in complex systems. But these computational methods -- from correlation coefficients to causal inference -- rely on distinct quantitative theories that remain largely disconnected. Here we introduce a library of 249 statistics for pairwise interactions and assess their behavior on 1053 multivariate time series from a wide range of real-world and model-generated systems. Our analysis highlights new commonalities between different mathematical formulations, providing a unified picture of a rich, interdisciplinary literature. We then show that leveraging many methods from across science can uncover those most suitable for addressing a given problem, yielding high accuracy and interpretable understanding. Our framework is provided in extendable open software, enabling comprehensive data-driven analysis by integrating decades of methodological advances.
Proofs and additional experiments on Second order techniques for learning time-series with structural breaks
Dec 15, 2020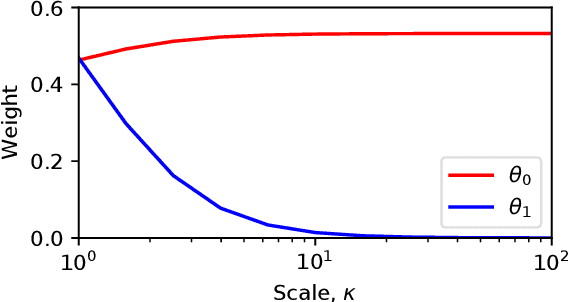
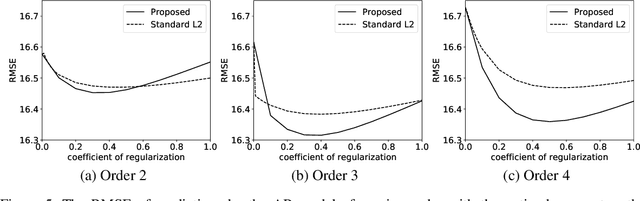
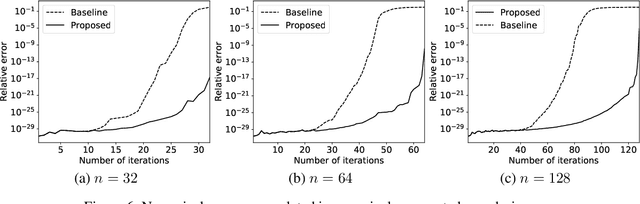
We provide complete proofs of the lemmas about the properties of the regularized loss function that is used in the second order techniques for learning time-series with structural breaks in Osogami (2021). In addition, we show experimental results that support the validity of the techniques.
FamilySeer: Towards Optimized Tensor Codes by Exploiting Computation Subgraph Similarity
Jan 01, 2022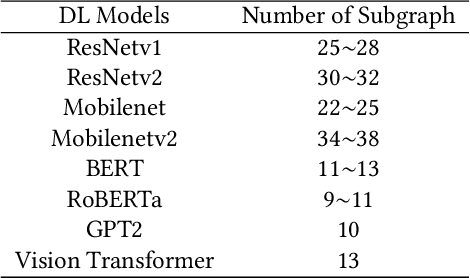
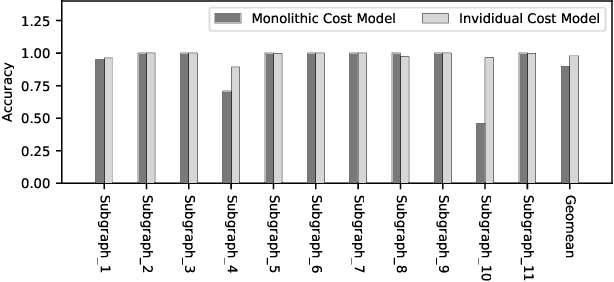

Deploying various deep learning (DL) models efficiently has boosted the research on DL compilers. The difficulty of generating optimized tensor codes drives DL compiler to ask for the auto-tuning approaches, and the increasing demands require increasing auto-tuning efficiency and quality. Currently, the DL compilers partition the input DL models into several subgraphs and leverage the auto-tuning to find the optimal tensor codes of these subgraphs. However, existing auto-tuning approaches usually regard subgraphs as individual ones and overlook the similarities across them, and thus fail to exploit better tensor codes under limited time budgets. We propose FamilySeer, an auto-tuning framework for DL compilers that can generate better tensor codes even with limited time budgets. FamilySeer exploits the similarities and differences among subgraphs can organize them into subgraph families, where the tuning of one subgraph can also improve other subgraphs within the same family. The cost model of each family gets more purified training samples generated by the family and becomes more accurate so that the costly measurements on real hardware can be replaced with the lightweight estimation through cost model. Our experiments show that FamilySeer can generate model codes with the same code performance more efficiently than state-of-the-art auto-tuning frameworks.
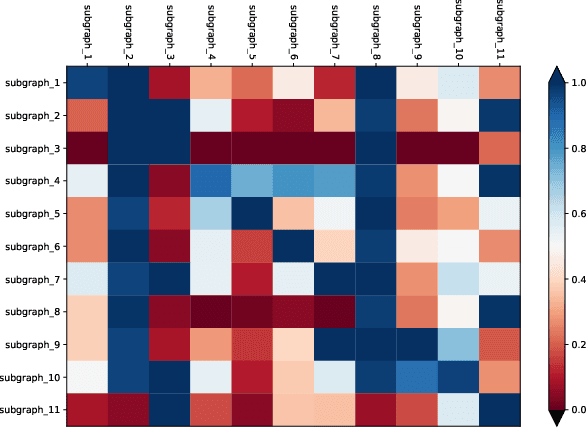
Sparse-Push: Communication- & Energy-Efficient Decentralized Distributed Learning over Directed & Time-Varying Graphs with non-IID Datasets
Feb 10, 2021
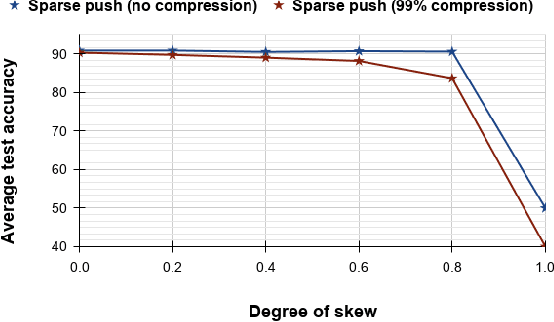
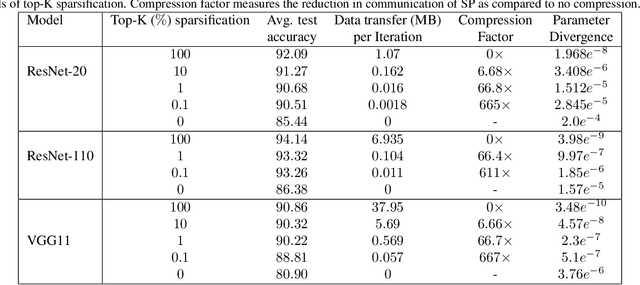
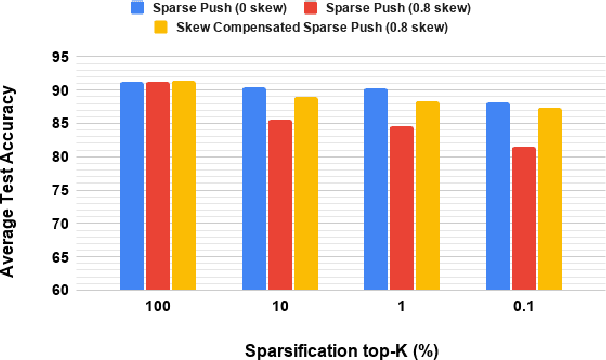
Current deep learning (DL) systems rely on a centralized computing paradigm which limits the amount of available training data, increases system latency, and adds privacy and security constraints. On-device learning, enabled by decentralized and distributed training of DL models over peer-to-peer wirelessly connected edge devices, not only alleviate the above limitations but also enable next-gen applications that need DL models to continuously interact and learn from their environment. However, this necessitates the development of novel training algorithms that train DL models over time-varying and directed peer-to-peer graph structures while minimizing the amount of communication between the devices and also being resilient to non-IID data distributions. In this work we propose, Sparse-Push, a communication efficient decentralized distributed training algorithm that supports training over peer-to-peer, directed, and time-varying graph topologies. The proposed algorithm enables 466x reduction in communication with only 1% degradation in performance when training various DL models such as ResNet-20 and VGG11 over the CIFAR-10 dataset. Further, we demonstrate how communication compression can lead to significant performance degradation in-case of non-IID datasets, and propose Skew-Compensated Sparse Push algorithm that recovers this performance drop while maintaining similar levels of communication compression.
Coarse-To-Fine Incremental Few-Shot Learning
Nov 24, 2021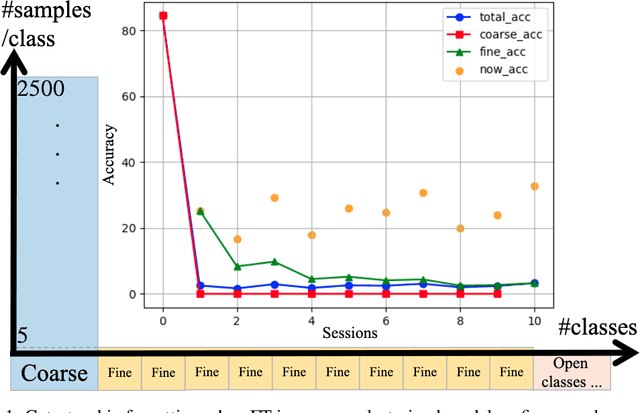

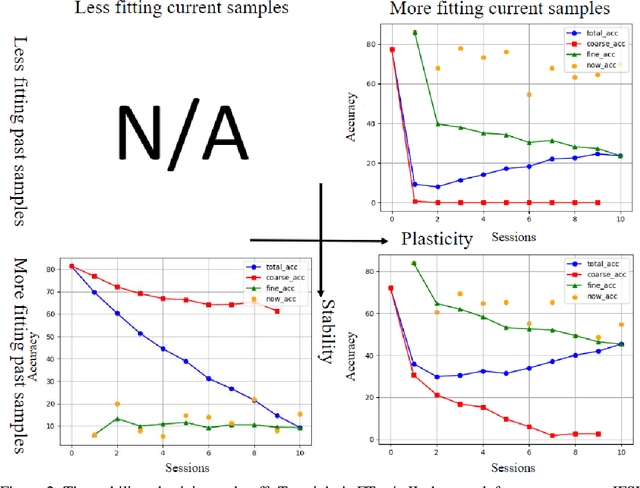
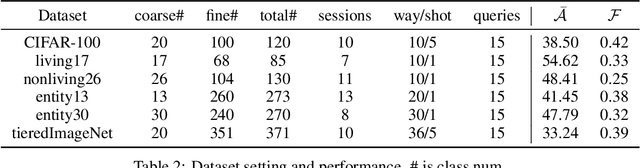
Different from fine-tuning models pre-trained on a large-scale dataset of preset classes, class-incremental learning (CIL) aims to recognize novel classes over time without forgetting pre-trained classes. However, a given model will be challenged by test images with finer-grained classes, e.g., a basenji is at most recognized as a dog. Such images form a new training set (i.e., support set) so that the incremental model is hoped to recognize a basenji (i.e., query) as a basenji next time. This paper formulates such a hybrid natural problem of coarse-to-fine few-shot (C2FS) recognition as a CIL problem named C2FSCIL, and proposes a simple, effective, and theoretically-sound strategy Knowe: to learn, normalize, and freeze a classifier's weights from fine labels, once learning an embedding space contrastively from coarse labels. Besides, as CIL aims at a stability-plasticity balance, new overall performance metrics are proposed. In that sense, on CIFAR-100, BREEDS, and tieredImageNet, Knowe outperforms all recent relevant CIL/FSCIL methods that are tailored to the new problem setting for the first time.
The Power of Communication in a Distributed Multi-Agent System
Dec 14, 2021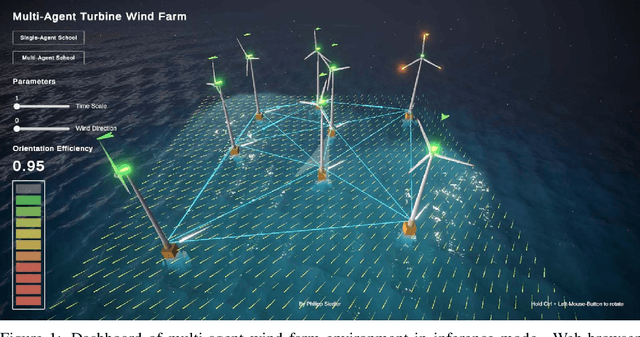
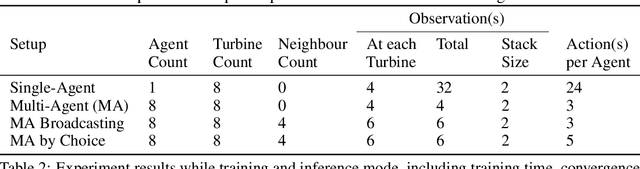


Single-Agent (SA) Reinforcement Learning systems have shown outstanding re-sults on non-stationary problems. However, Multi-Agent Reinforcement Learning(MARL) can surpass SA systems generally and when scaling. Furthermore, MAsystems can be super-powered by collaboration, which can happen through ob-serving others, or a communication system used to share information betweencollaborators. Here, we developed a distributed MA learning mechanism withthe ability to communicate based on decentralised partially observable Markovdecision processes (Dec-POMDPs) and Graph Neural Networks (GNNs). Minimis-ing the time and energy consumed by training Machine Learning models whileimproving performance can be achieved by collaborative MA mechanisms. Wedemonstrate this in a real-world scenario, an offshore wind farm, including a set ofdistributed wind turbines, where the objective is to maximise collective efficiency.Compared to a SA system, MA collaboration has shown significantly reducedtraining time and higher cumulative rewards in unseen and scaled scenarios.
Random-reshuffled SARAH does not need a full gradient computations
Nov 26, 2021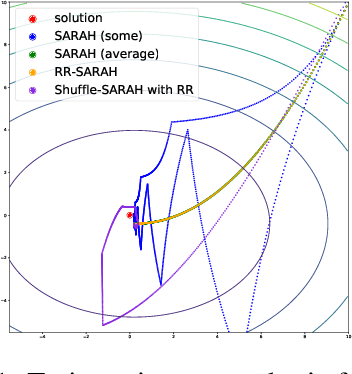
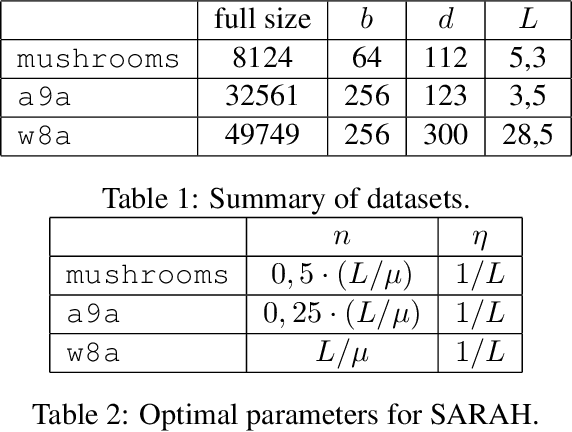
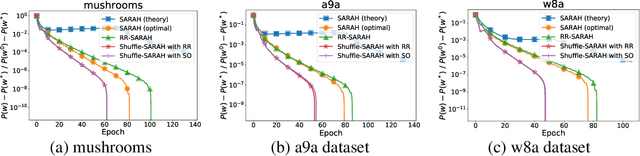
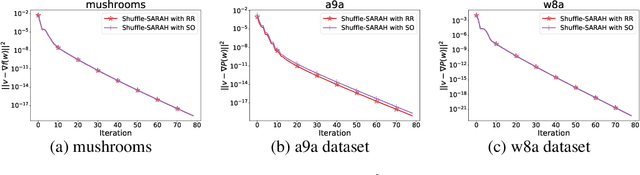
The StochAstic Recursive grAdient algoritHm (SARAH) algorithm is a variance reduced variant of the Stochastic Gradient Descent (SGD) algorithm that needs a gradient of the objective function from time to time. In this paper, we remove the necessity of a full gradient computation. This is achieved by using a randomized reshuffling strategy and aggregating stochastic gradients obtained in each epoch. The aggregated stochastic gradients serve as an estimate of a full gradient in the SARAH algorithm. We provide a theoretical analysis of the proposed approach and conclude the paper with numerical experiments that demonstrate the efficiency of this approach.
A Speech Intelligibility Enhancement Model based on Canonical Correlation and Deep Learning for Hearing-Assistive Technologies
Feb 15, 2022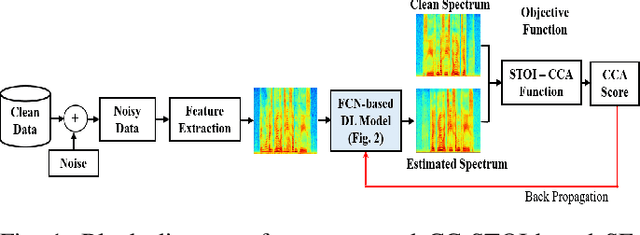
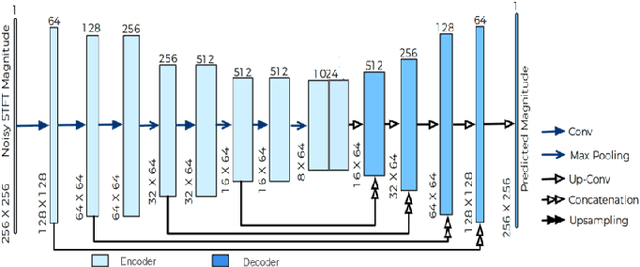
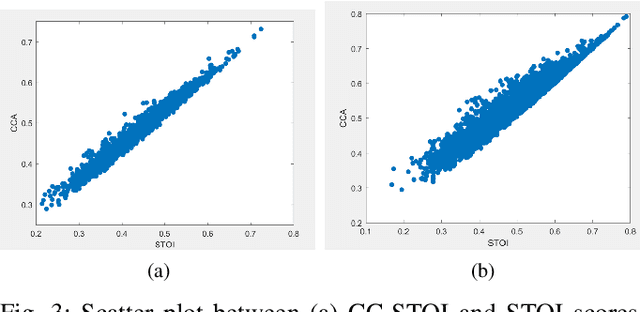
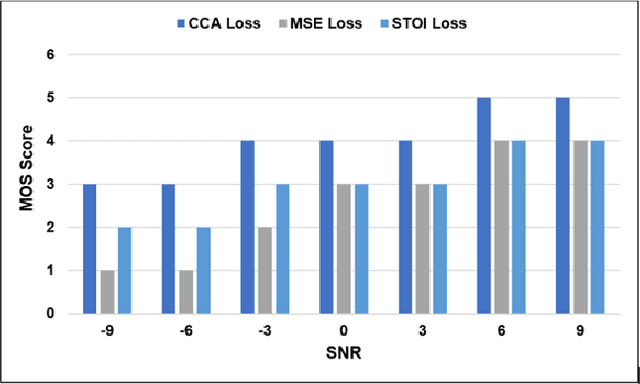
Current deep learning (DL) based approaches to speech intelligibility enhancement in noisy environments are generally trained to minimise the distance between clean and enhanced speech features. These often result in improved speech quality however they suffer from a lack of generalisation and may not deliver the required speech intelligibility in everyday noisy situations. In an attempt to address these challenges, researchers have explored intelligibility-oriented (I-O) loss functions to train DL approaches for robust speech enhancement (SE). In this paper, we formulate a novel canonical correlation-based I-O loss function to more effectively train DL algorithms. Specifically, we present a fully convolutional SE model that uses a modified canonical-correlation based short-time objective intelligibility (CC-STOI) metric as a training cost function. To the best of our knowledge, this is the first work that exploits the integration of canonical correlation in an I-O based loss function for SE. Comparative experimental results demonstrate that our proposed CC-STOI based SE framework outperforms DL models trained with conventional STOI and distance-based loss functions, in terms of both standard objective and subjective evaluation measures when dealing with unseen speakers and noises.
On Cyclic Solutions to the Min-Max Latency Multi-Robot Patrolling Problem
Mar 14, 2022

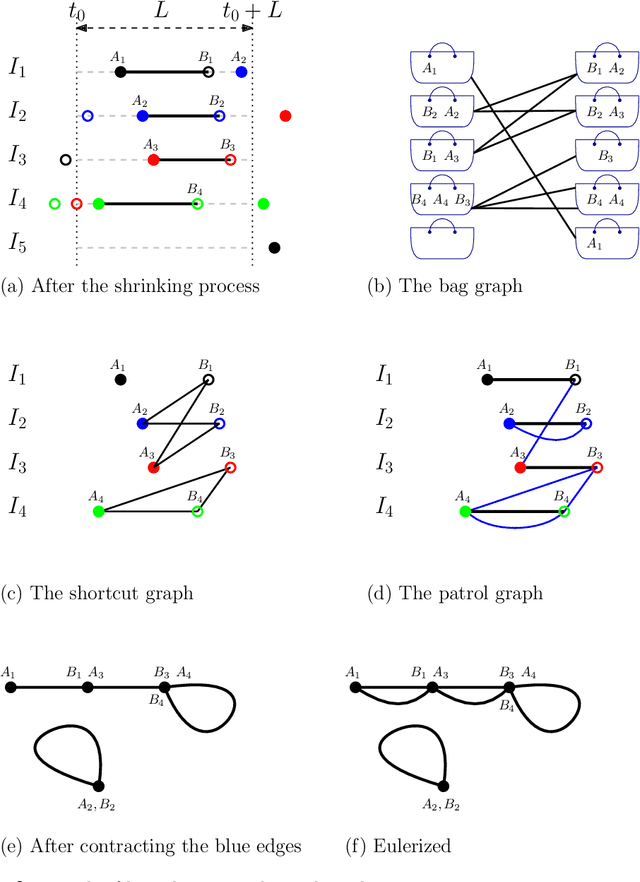
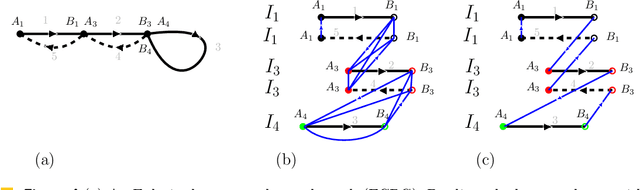
We consider the following surveillance problem: Given a set $P$ of $n$ sites in a metric space and a set of $k$ robots with the same maximum speed, compute a patrol schedule of minimum latency for the robots. Here a patrol schedule specifies for each robot an infinite sequence of sites to visit (in the given order) and the latency $L$ of a schedule is the maximum latency of any site, where the latency of a site $s$ is the supremum of the lengths of the time intervals between consecutive visits to $s$. When $k=1$ the problem is equivalent to the travelling salesman problem (TSP) and thus it is NP-hard. We have two main results. We consider cyclic solutions in which the set of sites must be partitioned into $\ell$ groups, for some~$\ell \leq k$, and each group is assigned a subset of the robots that move along the travelling salesman tour of the group at equal distance from each other. Our first main result is that approximating the optimal latency of the class of cyclic solutions can be reduced to approximating the optimal travelling salesman tour on some input, with only a $1+\varepsilon$ factor loss in the approximation factor and an $O\left(\left( k/\varepsilon \right)^k\right)$ factor loss in the runtime, for any $\varepsilon >0$. Our second main result shows that an optimal cyclic solution is a $2(1-1/k)$-approximation of the overall optimal solution. Note that for $k=2$ this implies that an optimal cyclic solution is optimal overall. The results have a number of consequences. For the Euclidean version of the problem, for instance, combining our results with known results on Euclidean TSP, yields a PTAS for approximating an optimal cyclic solution, and it yields a $(2(1-1/k)+\varepsilon)$-approximation of the optimal unrestricted solution. If the conjecture mentioned above is true, then our algorithm is actually a PTAS for the general problem in the Euclidean setting.