 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseBalance: Load-Balanced Long Context Training with Dynamic Sparse Attention
Apr 15, 2026While sparse attention mitigates the computational bottleneck of long-context LLM training, its distributed training process exhibits extreme heterogeneity in both \textit{1)} sequence length and \textit{2)} sparsity sensitivity, leading to a severe imbalance problem and sub-optimal model accuracy. Existing algorithms and training frameworks typically focus on single issue, failing to systematically co-optimize these two problems. Therefore, we propose SparseBalance, a novel algorithm-system co-design framework, which exploits the sparsity and sequence heterogeneity to optimize model accuracy and system efficiency jointly. First, we propose workload-aware dynamic sparsity tuning, which employs a bidirectional sparsity adjustment to eliminate stragglers and exploit inherent bubbles for free accuracy. Second, we propose a sparsity-aware batching strategy to achieve coarse-grained balance, which complements dynamic sparsity tuning. Experimental results demonstrate that SparseBalance achieves up to a 1.33$\times$ end-to-end speedup while still improving the long-context capability by 0.46\% on the LongBench benchmark.
Skrull: Towards Efficient Long Context Fine-tuning through Dynamic Data Scheduling
May 26, 2025Long-context supervised fine-tuning (Long-SFT) plays a vital role in enhancing the performance of large language models (LLMs) on long-context tasks. To smoothly adapt LLMs to long-context scenarios, this process typically entails training on mixed datasets containing both long and short sequences. However, this heterogeneous sequence length distribution poses significant challenges for existing training systems, as they fail to simultaneously achieve high training efficiency for both long and short sequences, resulting in sub-optimal end-to-end system performance in Long-SFT. In this paper, we present a novel perspective on data scheduling to address the challenges posed by the heterogeneous data distributions in Long-SFT. We propose Skrull, a dynamic data scheduler specifically designed for efficient long-SFT. Through dynamic data scheduling, Skrull balances the computation requirements of long and short sequences, improving overall training efficiency. Furthermore, we formulate the scheduling process as a joint optimization problem and thoroughly analyze the trade-offs involved. Based on those analysis, Skrull employs a lightweight scheduling algorithm to achieve near-zero cost online scheduling in Long-SFT. Finally, we implement Skrull upon DeepSpeed, a state-of-the-art distributed training system for LLMs. Experimental results demonstrate that Skrull outperforms DeepSpeed by 3.76x on average (up to 7.54x) in real-world long-SFT scenarios.
Real-Time Human Action Recognition on Embedded Platforms
Sep 11, 2024



With advancements in computer vision and deep learning, video-based human action recognition (HAR) has become practical. However, due to the complexity of the computation pipeline, running HAR on live video streams incurs excessive delays on embedded platforms. This work tackles the real-time performance challenges of HAR with four contributions: 1) an experimental study identifying a standard Optical Flow (OF) extraction technique as the latency bottleneck in a state-of-the-art HAR pipeline, 2) an exploration of the latency-accuracy tradeoff between the standard and deep learning approaches to OF extraction, which highlights the need for a novel, efficient motion feature extractor, 3) the design of Integrated Motion Feature Extractor (IMFE), a novel single-shot neural network architecture for motion feature extraction with drastic improvement in latency, 4) the development of RT-HARE, a real-time HAR system tailored for embedded platforms. Experimental results on an Nvidia Jetson Xavier NX platform demonstrated that RT-HARE realizes real-time HAR at a video frame rate of 30 frames per second while delivering high levels of recognition accuracy.
Vicinal Feature Statistics Augmentation for Federated 3D Medical Volume Segmentation
Oct 23, 2023Federated learning (FL) enables multiple client medical institutes collaboratively train a deep learning (DL) model with privacy protection. However, the performance of FL can be constrained by the limited availability of labeled data in small institutes and the heterogeneous (i.e., non-i.i.d.) data distribution across institutes. Though data augmentation has been a proven technique to boost the generalization capabilities of conventional centralized DL as a "free lunch", its application in FL is largely underexplored. Notably, constrained by costly labeling, 3D medical segmentation generally relies on data augmentation. In this work, we aim to develop a vicinal feature-level data augmentation (VFDA) scheme to efficiently alleviate the local feature shift and facilitate collaborative training for privacy-aware FL segmentation. We take both the inner- and inter-institute divergence into consideration, without the need for cross-institute transfer of raw data or their mixup. Specifically, we exploit the batch-wise feature statistics (e.g., mean and standard deviation) in each institute to abstractly represent the discrepancy of data, and model each feature statistic probabilistically via a Gaussian prototype, with the mean corresponding to the original statistic and the variance quantifying the augmentation scope. From the vicinal risk minimization perspective, novel feature statistics can be drawn from the Gaussian distribution to fulfill augmentation. The variance is explicitly derived by the data bias in each individual institute and the underlying feature statistics characterized by all participating institutes. The added-on VFDA consistently yielded marked improvements over six advanced FL methods on both 3D brain tumor and cardiac segmentation.
* 28th biennial international conference on Information Processing in Medical Imaging (IPMI 2023): Oral Paper
FamilySeer: Towards Optimized Tensor Codes by Exploiting Computation Subgraph Similarity
Jan 01, 2022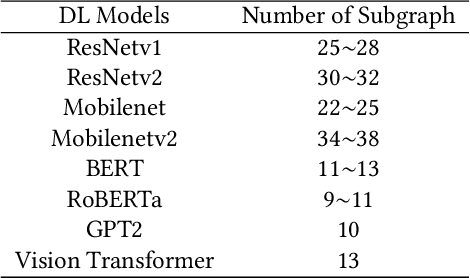
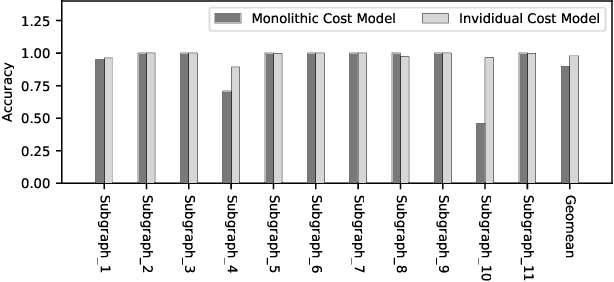
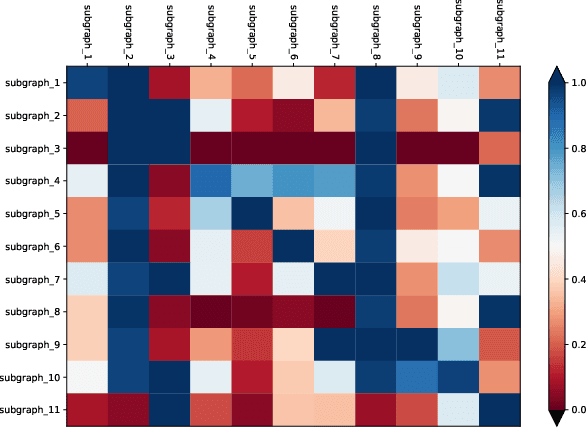

Deploying various deep learning (DL) models efficiently has boosted the research on DL compilers. The difficulty of generating optimized tensor codes drives DL compiler to ask for the auto-tuning approaches, and the increasing demands require increasing auto-tuning efficiency and quality. Currently, the DL compilers partition the input DL models into several subgraphs and leverage the auto-tuning to find the optimal tensor codes of these subgraphs. However, existing auto-tuning approaches usually regard subgraphs as individual ones and overlook the similarities across them, and thus fail to exploit better tensor codes under limited time budgets. We propose FamilySeer, an auto-tuning framework for DL compilers that can generate better tensor codes even with limited time budgets. FamilySeer exploits the similarities and differences among subgraphs can organize them into subgraph families, where the tuning of one subgraph can also improve other subgraphs within the same family. The cost model of each family gets more purified training samples generated by the family and becomes more accurate so that the costly measurements on real hardware can be replaced with the lightweight estimation through cost model. Our experiments show that FamilySeer can generate model codes with the same code performance more efficiently than state-of-the-art auto-tuning frameworks.
The Deep Learning Compiler: A Comprehensive Survey
Feb 27, 2020
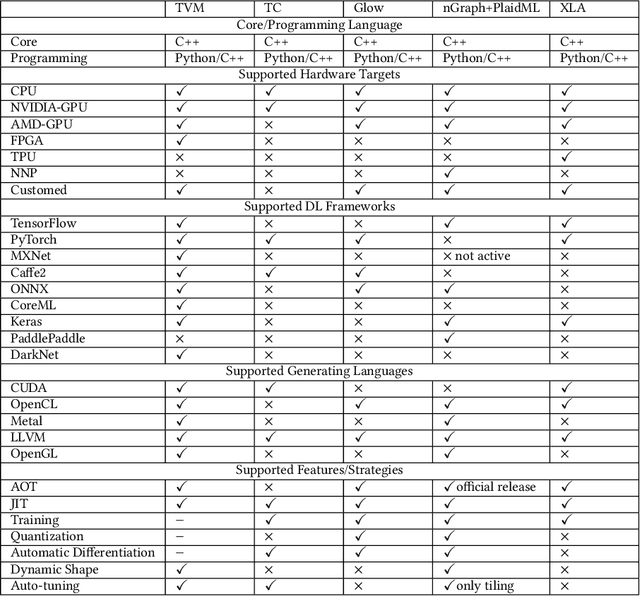
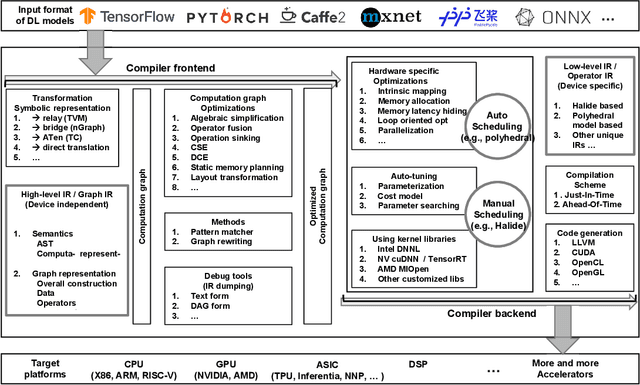
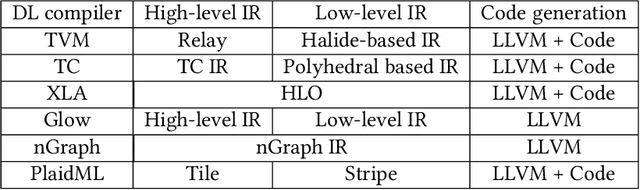
The difficulty of deploying various deep learning (DL) models on diverse DL hardware has boosted the research and development of DL compilers in the community. Several DL compilers have been proposed from both industry and academia such as Tensorflow XLA and TVM. Similarly, the DL compilers take the DL models described in different DL frameworks as input, and then generate optimized codes for diverse DL hardware as output. However, none of the existing survey has analyzed the unique design of the DL compilers comprehensively. In this paper, we perform a comprehensive survey of existing DL compilers by dissecting the commonly adopted design in details, with emphasis on the DL oriented multi-level IRs, and frontend/backend optimizations. Specifically, we provide a comprehensive comparison among existing DL compilers from various aspects. In addition, we present detailed analysis of the multi-level IR design and compiler optimization techniques. Finally, several insights are highlighted as the potential research directions of DL compiler. This is the first survey paper focusing on the unique design of DL compiler, which we hope can pave the road for future research towards the DL compiler.