 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Fusion of Lead-lag Graphs:Application to Cryptocurrencies
Jan 05, 2022
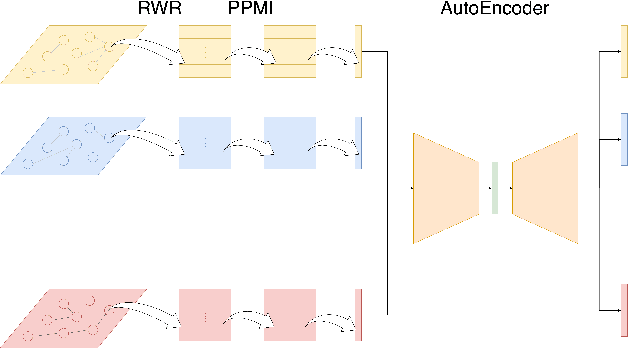

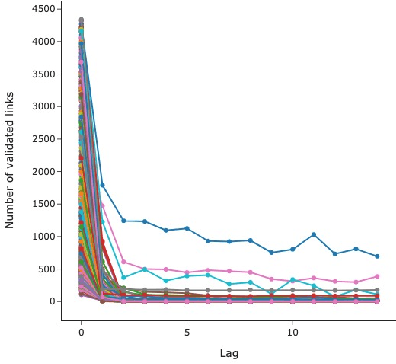
The study of time series has motivated many researchers, particularly on the area of multivariate-analysis. The study of co-movements and dependency between random variables leads us to develop metrics to describe existing connection between assets. The most commonly used are correlation and causality. Despite the growing literature, some connections remained still undetected. The objective of this paper is to propose a new representation learning algorithm capable to integrate synchronous and asynchronous relationships.
A 5.3 GHz Al0.76Sc0.24N Two-Dimensional Resonant Rods Resonator with a Record kt2 of 23.9%
Feb 23, 2022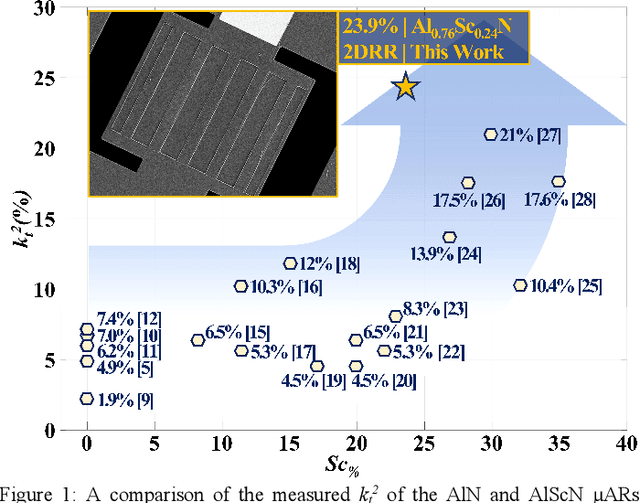
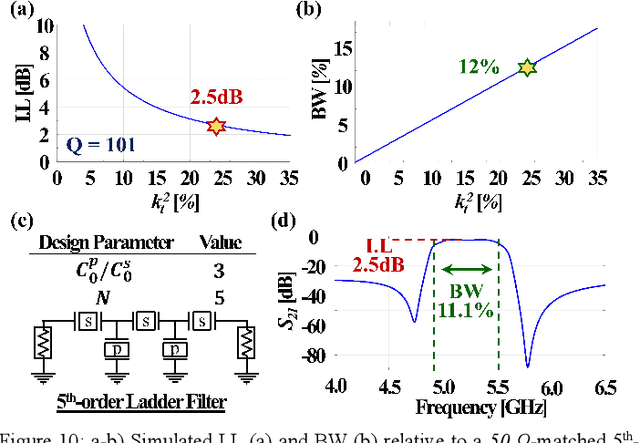
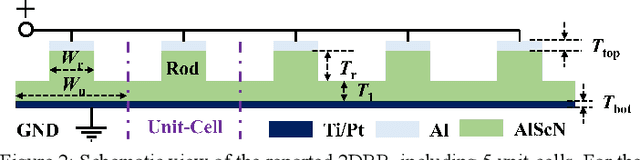
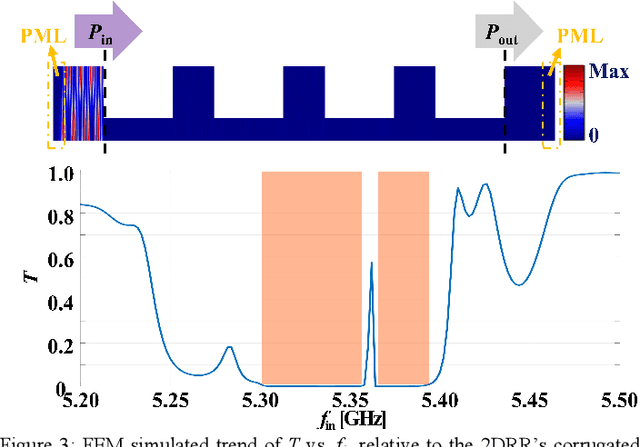
This work reports on the measured performance of an Aluminum Scandium Nitride (AlScN) Two-Dimensional Resonant Rods resonator (2DRR), fabricated by using a Sc-doping concentration of 24%, characterized by an ultra-low impedance (~25 Ohm) and exhibiting an all-time record electromechanical coupling coefficient (kt2) of 23.9%. In order to achieve such unprecedented performance, we identified and relied on optimized deposition and etching processes for highly-doped AlScN films, aiming at achieving high crystalline quality, low density of abnormal grains in the 2DRR's active region and sharp lateral sidewalls. Also, the 2DRR's unit cell has been acoustically engineered to maximize the piezo-generated mechanical energy within each rod and to ensure a low transduction of spurious modes around resonance. Due to its unprecedented kt2, the reported 2DRR opens exciting scenarios towards the development of next-generation monolithic integrated radio-frequency (RF) filtering components. In fact, we show that 5th-order 2DRR-based ladder filters with fractional bandwidths (BW) of ~11%, insertion-loss (I.L) values of ~2.5 dB and with larger than 30 dB out-of-band rejections can now be envisioned, paving an unprecedented path towards the development of ultra-wide band (UWB) filters for next-generation Super-High-Frequency (SHF) radio front-ends.
Joint CNN and Transformer Network via weakly supervised Learning for efficient crowd counting
Mar 12, 2022

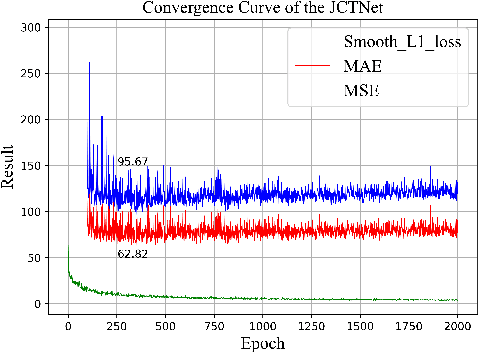
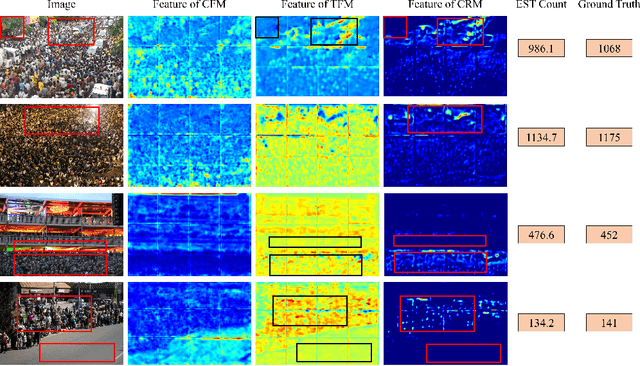
Currently, for crowd counting, the fully supervised methods via density map estimation are the mainstream research directions. However, such methods need location-level annotation of persons in an image, which is time-consuming and laborious. Therefore, the weakly supervised method just relying upon the count-level annotation is urgently needed. Since CNN is not suitable for modeling the global context and the interactions between image patches, crowd counting with weakly supervised learning via CNN generally can not show good performance. The weakly supervised model via Transformer was sequentially proposed to model the global context and learn contrast features. However, the transformer directly partitions the crowd images into a series of tokens, which may not be a good choice due to each pedestrian being an independent individual, and the parameter number of the network is very large. Hence, we propose a Joint CNN and Transformer Network (JCTNet) via weakly supervised learning for crowd counting in this paper. JCTNet consists of three parts: CNN feature extraction module (CFM), Transformer feature extraction module (TFM), and counting regression module (CRM). In particular, the CFM extracts crowd semantic information features, then sends their patch partitions to TRM for modeling global context, and CRM is used to predict the number of people. Extensive experiments and visualizations demonstrate that JCTNet can effectively focus on the crowd regions and obtain superior weakly supervised counting performance on five mainstream datasets. The number of parameters of the model can be reduced by about 67%~73% compared with the pure Transformer works. We also tried to explain the phenomenon that a model constrained only by count-level annotations can still focus on the crowd regions. We believe our work can promote further research in this field.
Crowd-powered Face Manipulation Detection: Fusing Human Examiner Decisions
Jan 31, 2022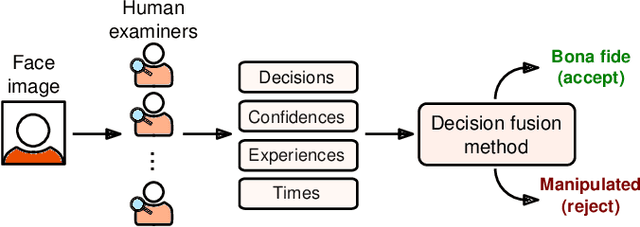
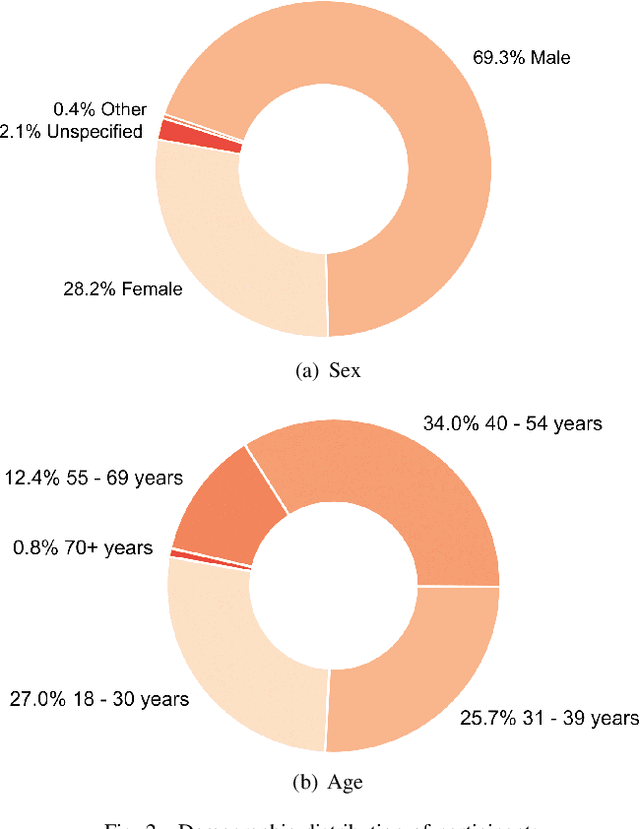

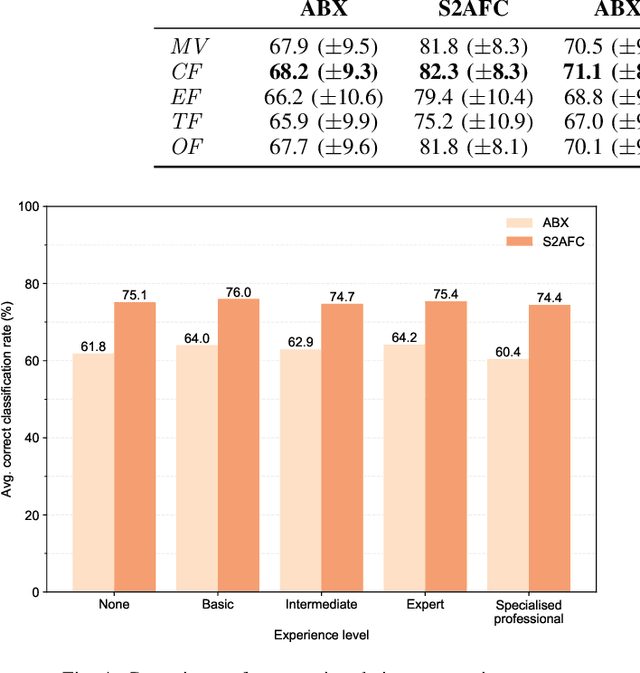
We investigate the potential of fusing human examiner decisions for the task of digital face manipulation detection. To this end, various decision fusion methods are proposed incorporating the examiners' decision confidence, experience level, and their time to take a decision. Conducted experiments are based on a psychophysical evaluation of digital face image manipulation detection capabilities of humans in which different manipulation techniques were applied, i.e. face morphing, face swapping and retouching. The decisions of 223 participants were fused to simulate crowds of up to seven human examiners. Experimental results reveal that (1) despite the moderate detection performance achieved by single human examiners, a high accuracy can be obtained through decision fusion and (2) a weighted fusion which takes the examiners' decision confidence into account yields the most competitive detection performance.
MSCFNet: A Lightweight Network With Multi-Scale Context Fusion for Real-Time Semantic Segmentation
Mar 24, 2021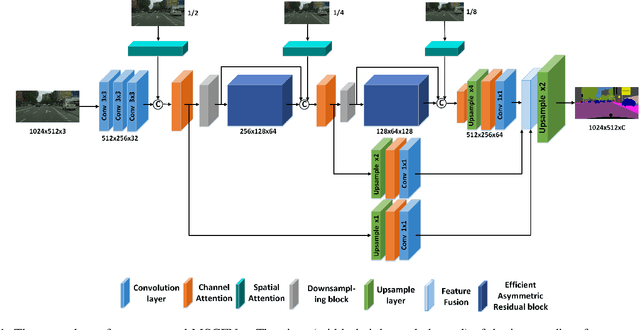
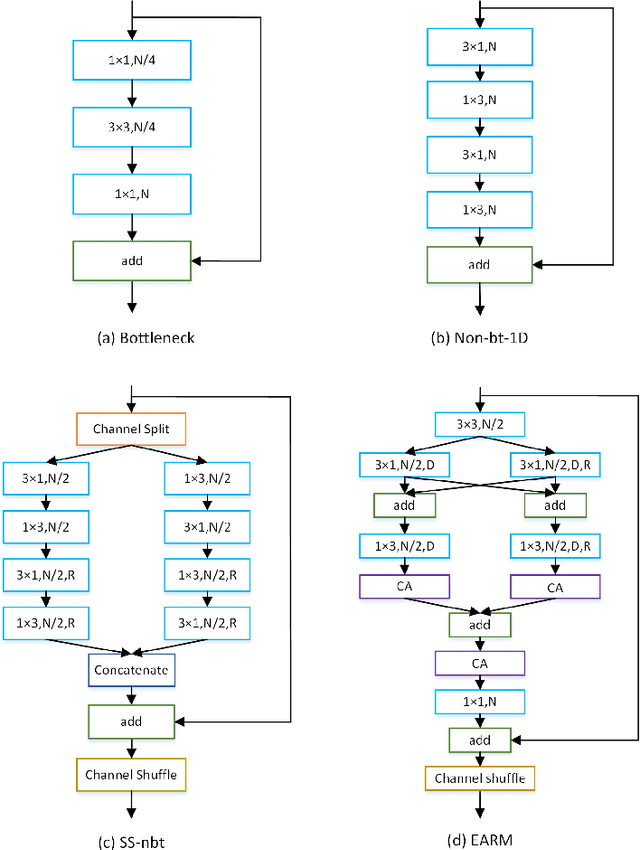
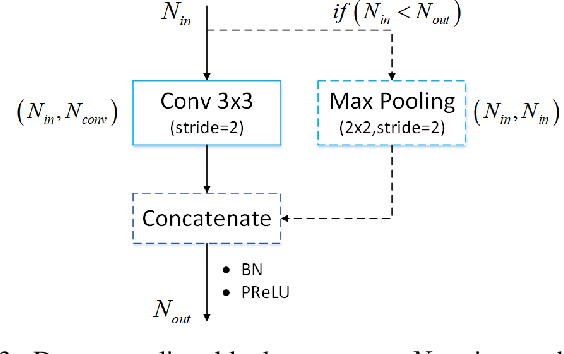
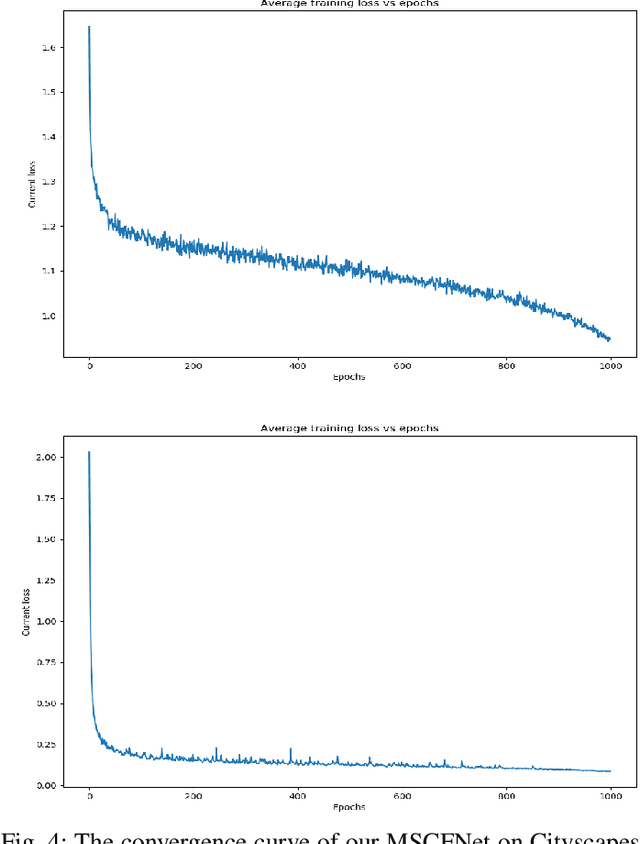
In recent years, how to strike a good trade-off between accuracy and inference speed has become the core issue for real-time semantic segmentation applications, which plays a vital role in real-world scenarios such as autonomous driving systems and drones. In this study, we devise a novel lightweight network using a multi-scale context fusion (MSCFNet) scheme, which explores an asymmetric encoder-decoder architecture to dispose this problem. More specifically, the encoder adopts some developed efficient asymmetric residual (EAR) modules, which are composed of factorization depth-wise convolution and dilation convolution. Meanwhile, instead of complicated computation, simple deconvolution is applied in the decoder to further reduce the amount of parameters while still maintaining high segmentation accuracy. Also, MSCFNet has branches with efficient attention modules from different stages of the network to well capture multi-scale contextual information. Then we combine them before the final classification to enhance the expression of the features and improve the segmentation efficiency. Comprehensive experiments on challenging datasets have demonstrated that the proposed MSCFNet, which contains only 1.15M parameters, achieves 71.9\% Mean IoU on the Cityscapes testing dataset and can run at over 50 FPS on a single Titan XP GPU configuration.
MaskGIT: Masked Generative Image Transformer
Feb 08, 2022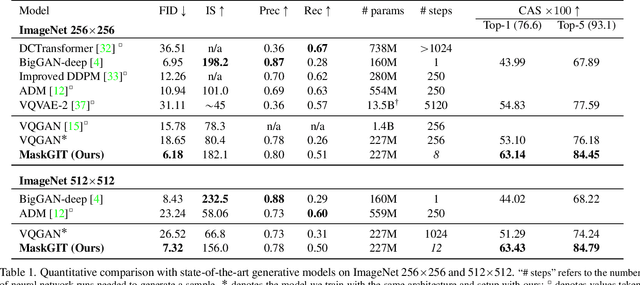

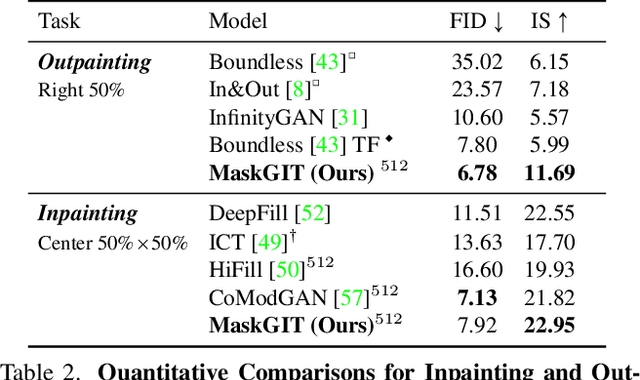
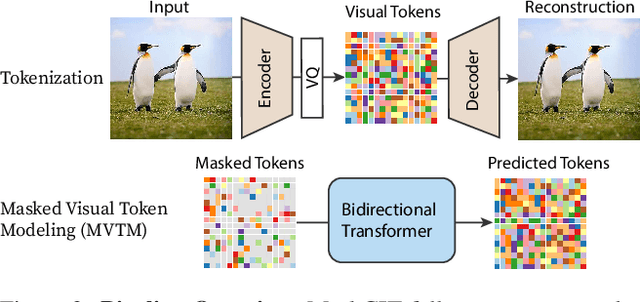
Generative transformers have experienced rapid popularity growth in the computer vision community in synthesizing high-fidelity and high-resolution images. The best generative transformer models so far, however, still treat an image naively as a sequence of tokens, and decode an image sequentially following the raster scan ordering (i.e. line-by-line). We find this strategy neither optimal nor efficient. This paper proposes a novel image synthesis paradigm using a bidirectional transformer decoder, which we term MaskGIT. During training, MaskGIT learns to predict randomly masked tokens by attending to tokens in all directions. At inference time, the model begins with generating all tokens of an image simultaneously, and then refines the image iteratively conditioned on the previous generation. Our experiments demonstrate that MaskGIT significantly outperforms the state-of-the-art transformer model on the ImageNet dataset, and accelerates autoregressive decoding by up to 64x. Besides, we illustrate that MaskGIT can be easily extended to various image editing tasks, such as inpainting, extrapolation, and image manipulation.
Efficient-Dyn: Dynamic Graph Representation Learning via Event-based Temporal Sparse Attention Network
Jan 04, 2022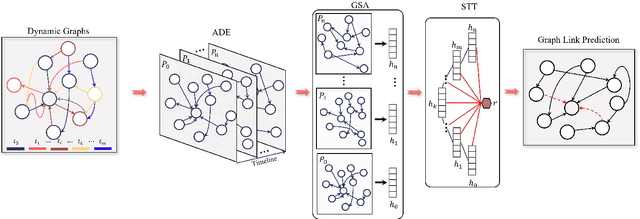
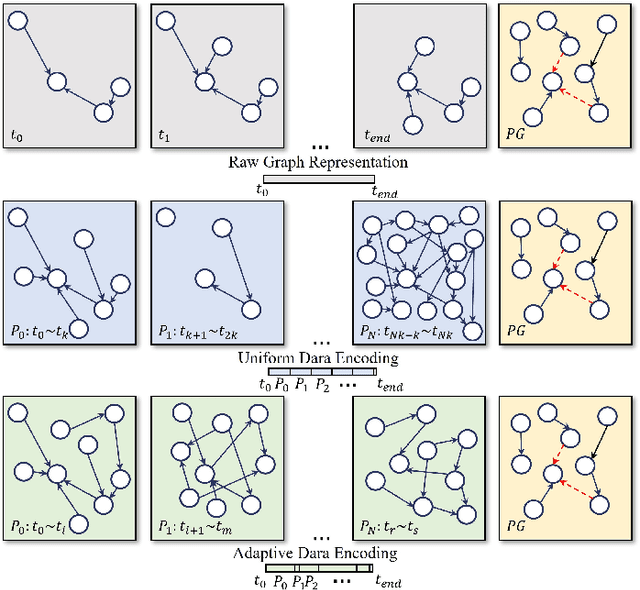
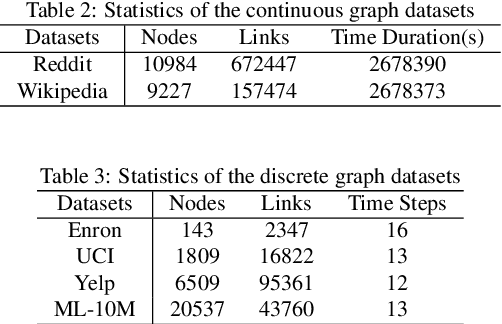
Static graph neural networks have been widely used in modeling and representation learning of graph structure data. However, many real-world problems, such as social networks, financial transactions, recommendation systems, etc., are dynamic, that is, nodes and edges are added or deleted over time. Therefore, in recent years, dynamic graph neural networks have received more and more attention from researchers. In this work, we propose a novel dynamic graph neural network, Efficient-Dyn. It adaptively encodes temporal information into a sequence of patches with an equal amount of temporal-topological structure. Therefore, while avoiding the use of snapshots to cause information loss, it also achieves a finer time granularity, which is close to what continuous networks could provide. In addition, we also designed a lightweight module, Sparse Temporal Transformer, to compute node representations through both structural neighborhoods and temporal dynamics. Since the fully-connected attention conjunction is simplified, the computation cost is far lower than the current state-of-the-arts. Link prediction experiments are conducted on both continuous and discrete graph datasets. Through comparing with several state-of-the-art graph embedding baselines, the experimental results demonstrate that Efficient-Dyn has a faster inference speed while having competitive performance.
EF-Train: Enable Efficient On-device CNN Training on FPGA Through Data Reshaping for Online Adaptation or Personalization
Feb 18, 2022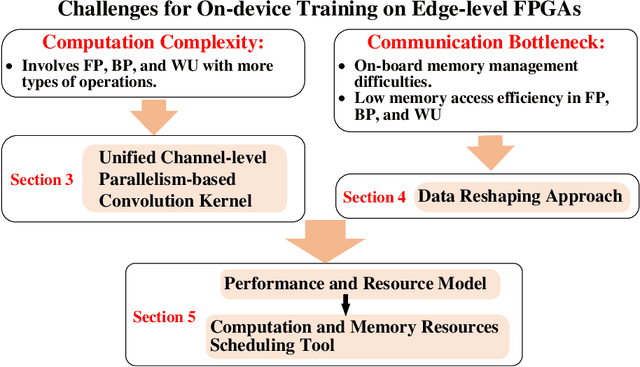
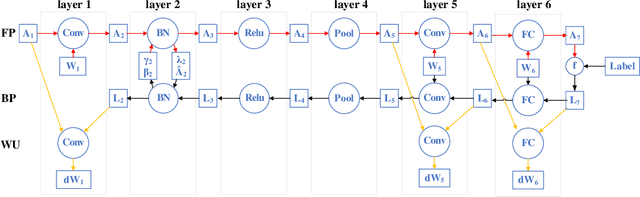
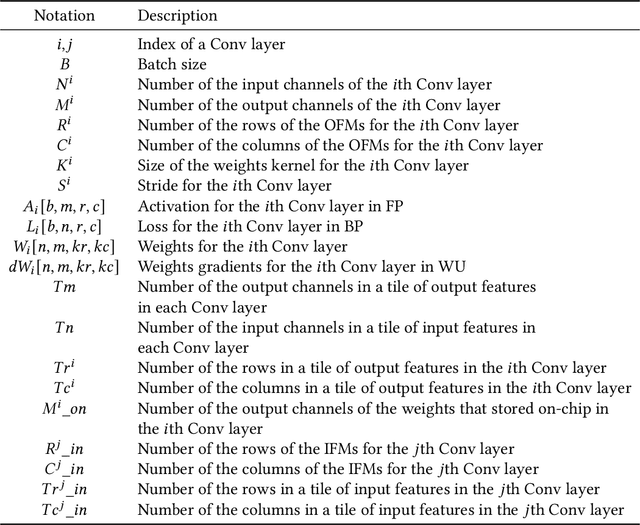
Conventionally, DNN models are trained once in the cloud and deployed in edge devices such as cars, robots, or unmanned aerial vehicles (UAVs) for real-time inference. However, there are many cases that require the models to adapt to new environments, domains, or new users. In order to realize such domain adaption or personalization, the models on devices need to be continuously trained on the device. In this work, we design EF-Train, an efficient DNN training accelerator with a unified channel-level parallelism-based convolution kernel that can achieve end-to-end training on resource-limited low-power edge-level FPGAs. It is challenging to implement on-device training on resource-limited FPGAs due to the low efficiency caused by different memory access patterns among forward, backward propagation, and weight update. Therefore, we developed a data reshaping approach with intra-tile continuous memory allocation and weight reuse. An analytical model is established to automatically schedule computation and memory resources to achieve high energy efficiency on edge FPGAs. The experimental results show that our design achieves 46.99 GFLOPS and 6.09GFLOPS/W in terms of throughput and energy efficiency, respectively.
Signal Decomposition Using Masked Proximal Operators
Feb 18, 2022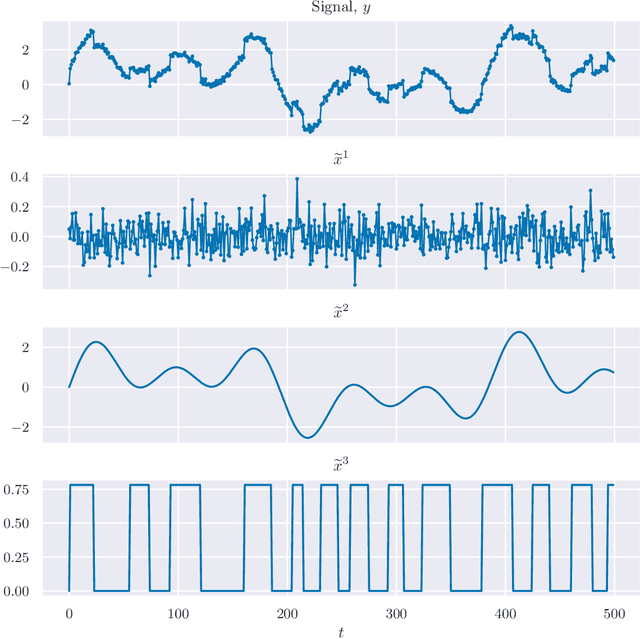
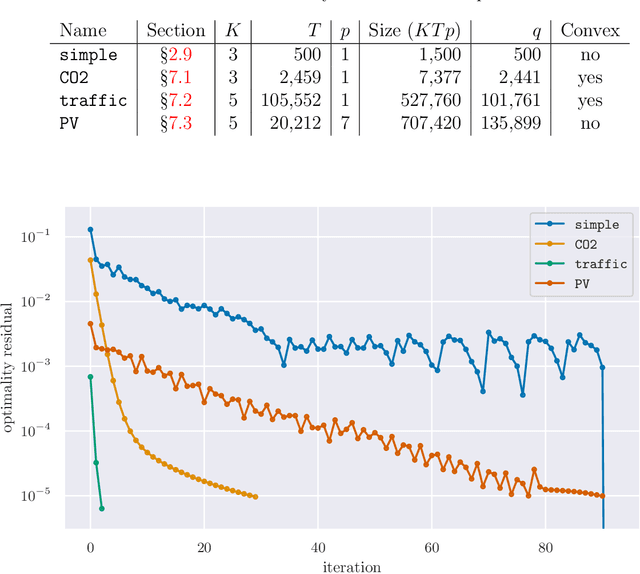
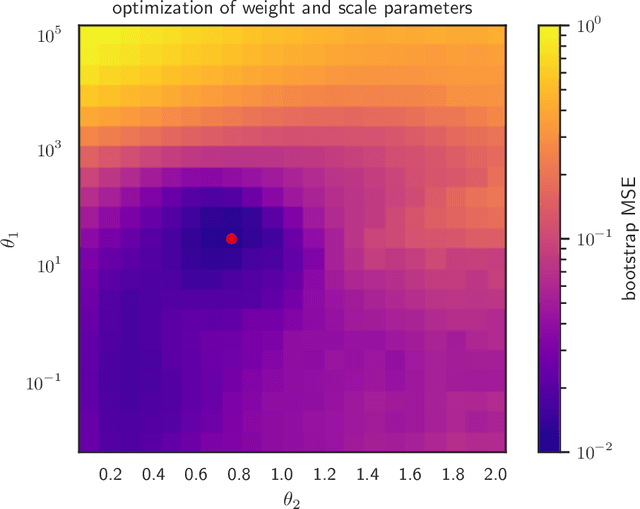
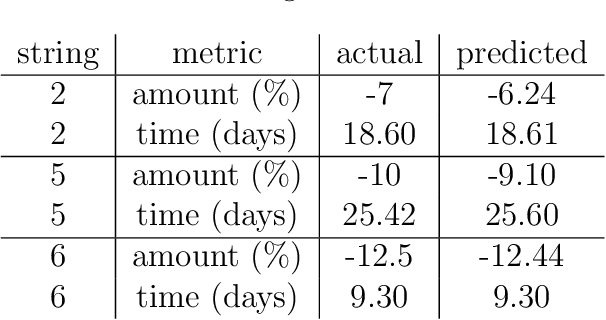
We consider the well-studied problem of decomposing a vector time series signal into components with different characteristics, such as smooth, periodic, nonnegative, or sparse. We propose a simple and general framework in which the components are defined by loss functions (which include constraints), and the signal decomposition is carried out by minimizing the sum of losses of the components (subject to the constraints). When each loss function is the negative log-likelihood of a density for the signal component, our method coincides with maximum a posteriori probability (MAP) estimation; but it also includes many other interesting cases. We give two distributed optimization methods for computing the decomposition, which find the optimal decomposition when the component class loss functions are convex, and are good heuristics when they are not. Both methods require only the masked proximal operator of each of the component loss functions, a generalization of the well-known proximal operator that handles missing entries in its argument. Both methods are distributed, i.e., handle each component separately. We derive tractable methods for evaluating the masked proximal operators of some loss functions that, to our knowledge, have not appeared in the literature.
A Real-World Implementation of Unbiased Lift-based Bidding System
Feb 23, 2022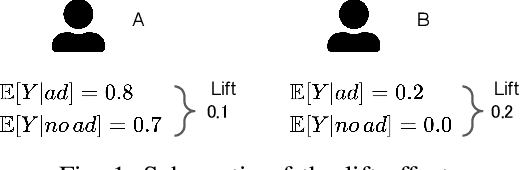
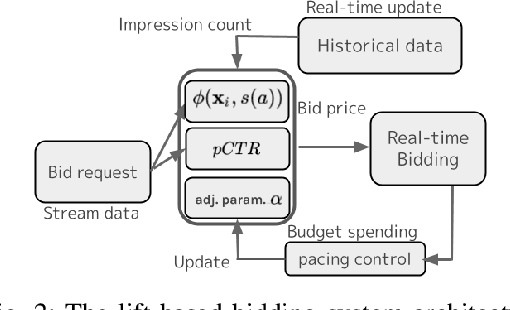
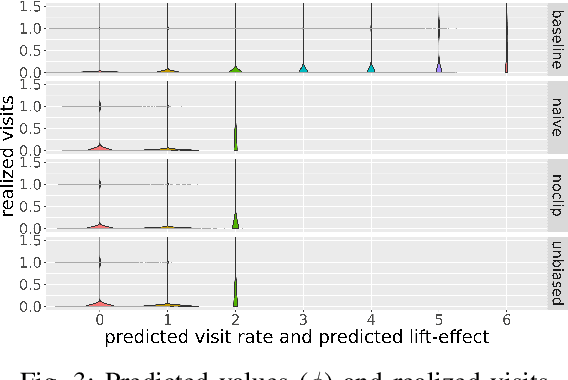
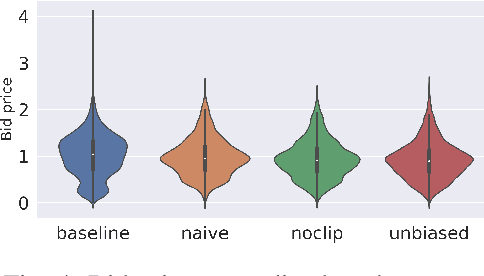
In display ad auctions of Real-Time Bid-ding (RTB), a typical Demand-Side Platform (DSP)bids based on the predicted probability of click and conversion right after an ad impression. Recent studies find such a strategy is suboptimal and propose a better bidding strategy named lift-based bidding.Lift-based bidding simply bids the price according to the lift effect of the ad impression and achieves maximization of target metrics such as sales. Despiteits superiority, lift-based bidding has not yet been widely accepted in the advertising industry. For one reason, lift-based bidding is less profitable for DSP providers under the current billing rule. Second, thepractical usefulness of lift-based bidding is not widely understood in the online advertising industry due to the lack of a comprehensive investigation of its impact.We here propose a practically-implementable lift-based bidding system that perfectly fits the current billing rules. We conduct extensive experiments usinga real-world advertising campaign and examine the performance under various settings. We find that lift-based bidding, especially unbiased lift-based bidding is most profitable for both DSP providers and advertisers. Our ablation study highlights that lift-based bidding has a good property for currently dominant first price auctions. The results will motivate the online