 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
PathNavigate: A Training-Free Pathology Agent with Surprise-Guided Scan and Shared Slide Memory for Whole-Slide Image VQA
May 22, 2026Whole-slide image visual question answering (WSI-VQA) frames pathology as an extreme-context search problem: to answer a free-form clinical query, a system must first navigate a gigapixel slide under a strict inspection budget to locate sparse, high-resolution evidence. Existing approaches largely fall into two paradigms: i) supervised pathology multimodal large language models (MLLMs) and agents can absorb localization and reasoning into learned modules, but they often couple navigation to task-specific supervision and retraining, limiting their practicality; ii) training-free pathology agents avoid this cost by keeping core models frozen, but often follow a question-first design, constructing the initial candidate set mainly from query-conditioned relevance. This can miss decisive morphology that is not named in the question, and force heavier inference-time scaffolding. To address this challenge, we introduce PathNavigate, a training-free pathology agent built around a scan-search-readout routine. Before question matching, PathNavigate scans the current slide at low magnification with a shared online memory module over frozen pathology features, producing a slide-specific surprise field that marks an abnormal-region pool. It then applies question-conditioned PLIP relevance only within this pool to select high-magnification search targets. Finally, it extracts local high-magnification evidence and answers with a frozen perceptor-adjudicator stack, using the same online memory as slide-level context. Experiments on WSI-VQA and SlideBench-BCNB show that the proposed scan-search-readout design improves answer accuracy and yields more interpretable evidence-selection trajectories with higher efficiency.The code is available online.
HAAF: Hierarchical Adaptation and Alignment of Foundation Models for Few-Shot Pathology Anomaly Detection
Jan 24, 2026Precision pathology relies on detecting fine-grained morphological abnormalities within specific Regions of Interest (ROIs), as these local, texture-rich cues - rather than global slide contexts - drive expert diagnostic reasoning. While Vision-Language (V-L) models promise data efficiency by leveraging semantic priors, adapting them faces a critical Granularity Mismatch, where generic representations fail to resolve such subtle defects. Current adaptation methods often treat modalities as independent streams, failing to ground semantic prompts in ROI-specific visual contexts. To bridge this gap, we propose the Hierarchical Adaptation and Alignment Framework (HAAF). At its core is a novel Cross-Level Scaled Alignment (CLSA) mechanism that enforces a sequential calibration order: visual features first inject context into text prompts to generate content-adaptive descriptors, which then spatially guide the visual encoder to spotlight anomalies. Additionally, a dual-branch inference strategy integrates semantic scores with geometric prototypes to ensure stability in few-shot settings. Experiments on four benchmarks show HAAF significantly outperforms state-of-the-art methods and effectively scales with domain-specific backbones (e.g., CONCH) in low-resource scenarios.
3D Wavelet-Based Structural Priors for Controlled Diffusion in Whole-Body Low-Dose PET Denoising
Jan 11, 2026Low-dose Positron Emission Tomography (PET) imaging reduces patient radiation exposure but suffers from increased noise that degrades image quality and diagnostic reliability. Although diffusion models have demonstrated strong denoising capability, their stochastic nature makes it challenging to enforce anatomically consistent structures, particularly in low signal-to-noise regimes and volumetric whole-body imaging. We propose Wavelet-Conditioned ControlNet (WCC-Net), a fully 3D diffusion-based framework that introduces explicit frequency-domain structural priors via wavelet representations to guide volumetric PET denoising. By injecting wavelet-based structural guidance into a frozen pretrained diffusion backbone through a lightweight control branch, WCC-Net decouples anatomical structure from noise while preserving generative expressiveness and 3D structural continuity. Extensive experiments demonstrate that WCC-Net consistently outperforms CNN-, GAN-, and diffusion-based baselines. On the internal 1/20-dose test set, WCC-Net improves PSNR by +1.21 dB and SSIM by +0.008 over a strong diffusion baseline, while reducing structural distortion (GMSD) and intensity error (NMAE). Moreover, WCC-Net generalizes robustly to unseen dose levels (1/50 and 1/4), achieving superior quantitative performance and improved volumetric anatomical consistency.
Enabling Weakly-Supervised Temporal Action Localization from On-Device Learning of the Video Stream
Aug 25, 2022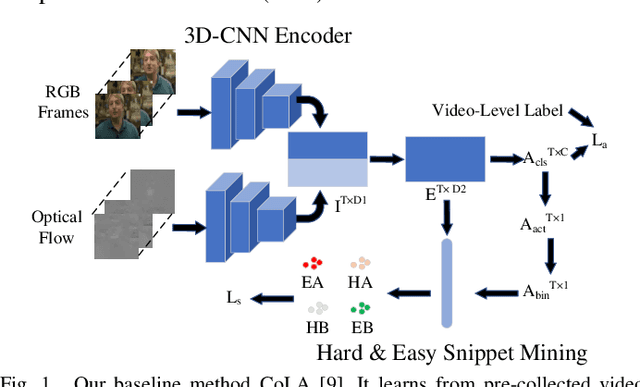
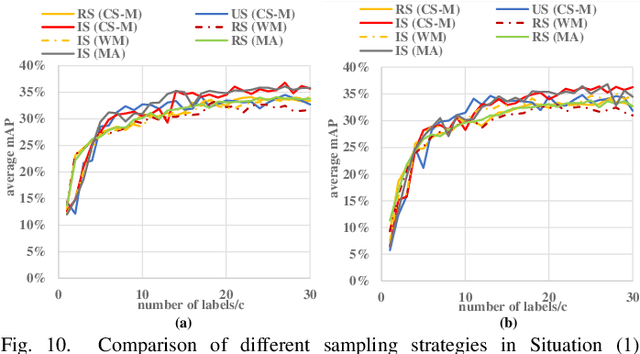
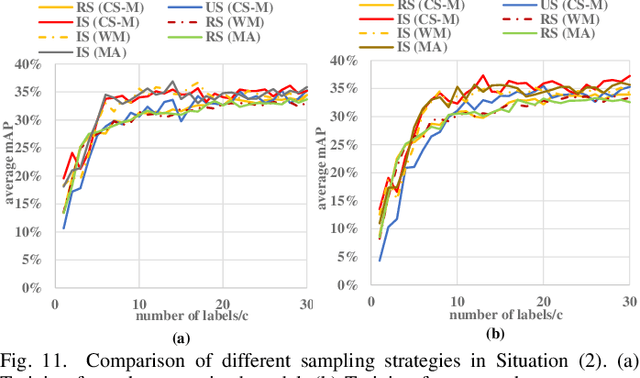
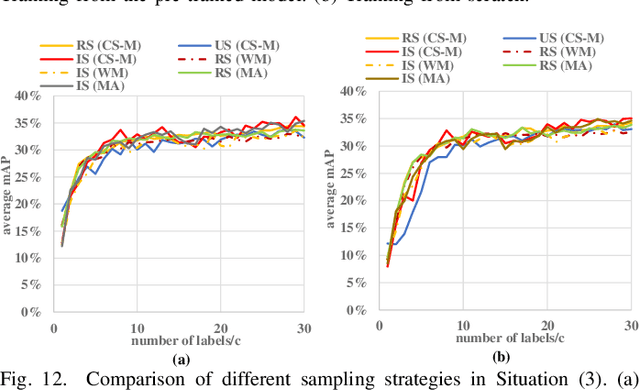
Detecting actions in videos have been widely applied in on-device applications. Practical on-device videos are always untrimmed with both action and background. It is desirable for a model to both recognize the class of action and localize the temporal position where the action happens. Such a task is called temporal action location (TAL), which is always trained on the cloud where multiple untrimmed videos are collected and labeled. It is desirable for a TAL model to continuously and locally learn from new data, which can directly improve the action detection precision while protecting customers' privacy. However, it is non-trivial to train a TAL model, since tremendous video samples with temporal annotations are required. However, annotating videos frame by frame is exorbitantly time-consuming and expensive. Although weakly-supervised TAL (W-TAL) has been proposed to learn from untrimmed videos with only video-level labels, such an approach is also not suitable for on-device learning scenarios. In practical on-device learning applications, data are collected in streaming. Dividing such a long video stream into multiple video segments requires lots of human effort, which hinders the exploration of applying the TAL tasks to realistic on-device learning applications. To enable W-TAL models to learn from a long, untrimmed streaming video, we propose an efficient video learning approach that can directly adapt to new environments. We first propose a self-adaptive video dividing approach with a contrast score-based segment merging approach to convert the video stream into multiple segments. Then, we explore different sampling strategies on the TAL tasks to request as few labels as possible. To the best of our knowledge, we are the first attempt to directly learn from the on-device, long video stream.
Sustainable AI Processing at the Edge
Jul 04, 2022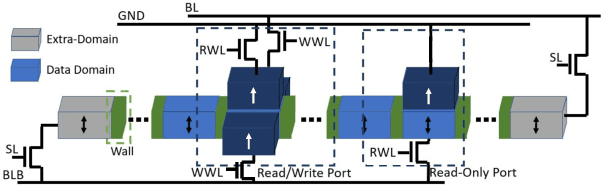
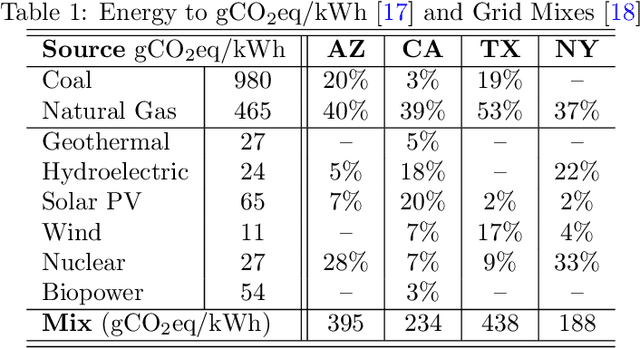
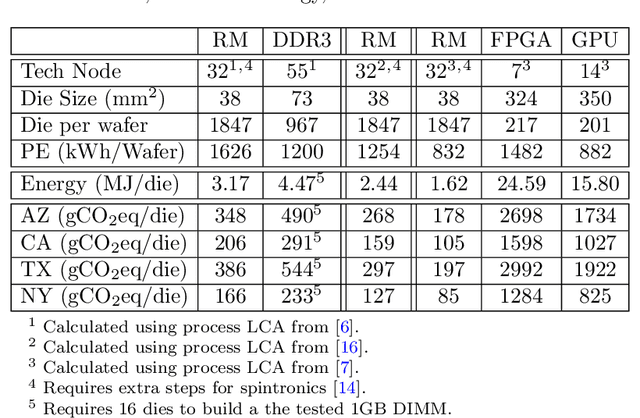
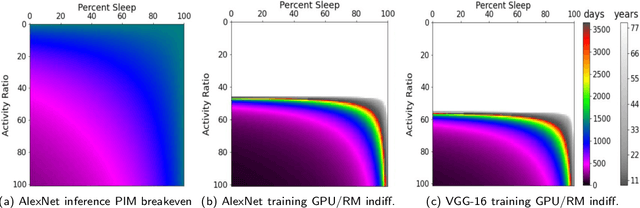
Edge computing is a popular target for accelerating machine learning algorithms supporting mobile devices without requiring the communication latencies to handle them in the cloud. Edge deployments of machine learning primarily consider traditional concerns such as SWaP constraints (Size, Weight, and Power) for their installations. However, such metrics are not entirely sufficient to consider environmental impacts from computing given the significant contributions from embodied energy and carbon. In this paper we explore the tradeoffs of convolutional neural network acceleration engines for both inference and on-line training. In particular, we explore the use of processing-in-memory (PIM) approaches, mobile GPU accelerators, and recently released FPGAs, and compare them with novel Racetrack memory PIM. Replacing PIM-enabled DDR3 with Racetrack memory PIM can recover its embodied energy as quickly as 1 year. For high activity ratios, mobile GPUs can be more sustainable but have higher embodied energy to overcome compared to PIM-enabled Racetrack memory.
EF-Train: Enable Efficient On-device CNN Training on FPGA Through Data Reshaping for Online Adaptation or Personalization
Feb 18, 2022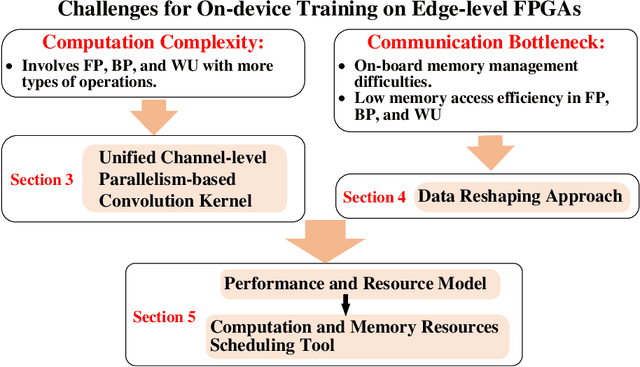
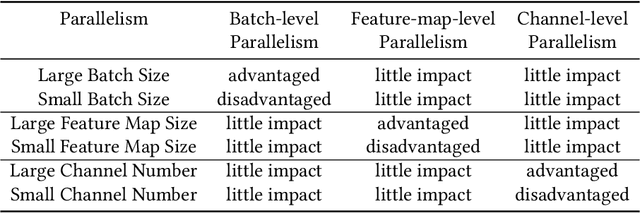
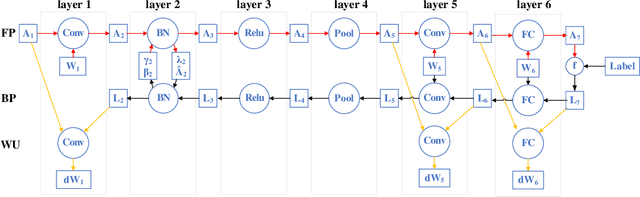
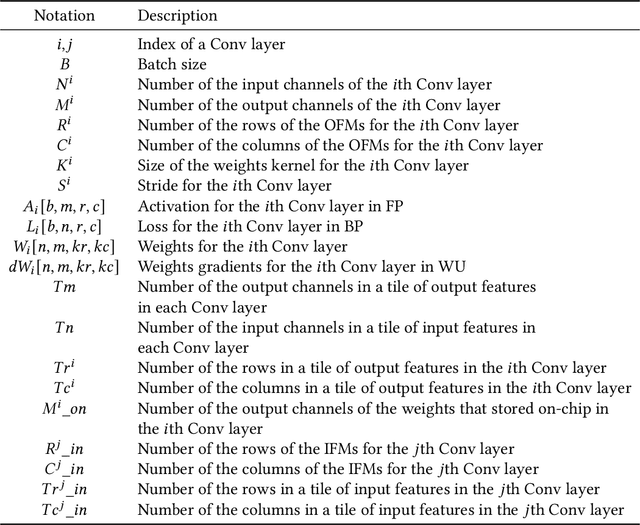
Conventionally, DNN models are trained once in the cloud and deployed in edge devices such as cars, robots, or unmanned aerial vehicles (UAVs) for real-time inference. However, there are many cases that require the models to adapt to new environments, domains, or new users. In order to realize such domain adaption or personalization, the models on devices need to be continuously trained on the device. In this work, we design EF-Train, an efficient DNN training accelerator with a unified channel-level parallelism-based convolution kernel that can achieve end-to-end training on resource-limited low-power edge-level FPGAs. It is challenging to implement on-device training on resource-limited FPGAs due to the low efficiency caused by different memory access patterns among forward, backward propagation, and weight update. Therefore, we developed a data reshaping approach with intra-tile continuous memory allocation and weight reuse. An analytical model is established to automatically schedule computation and memory resources to achieve high energy efficiency on edge FPGAs. The experimental results show that our design achieves 46.99 GFLOPS and 6.09GFLOPS/W in terms of throughput and energy efficiency, respectively.