 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Time-Varying Topology Identification via Prediction-Correction Algorithms
Oct 22, 2020
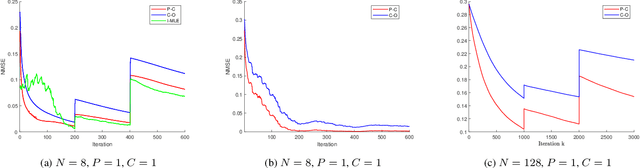
Signal processing and machine learning algorithms for data supported over graphs, require the knowledge of the graph topology. Unless this information is given by the physics of the problem (e.g., water supply networks, power grids), the topology has to be learned from data. Topology identification is a challenging task, as the problem is often ill-posed, and becomes even harder when the graph structure is time-varying. In this paper, we address the problem of dynamic topology identification by building on recent results from time-varying optimization, devising a general-purpose online algorithm operating in non-stationary environments. Because of its iteration-constrained nature, the proposed approach exhibits an intrinsic temporal-regularization of the graph topology without explicitly enforcing it. As a case-study, we specialize our method to the Gaussian graphical model (GGM) problem and corroborate its performance.
Vision-based Autonomous Driving for Unstructured Environments Using Imitation Learning
Feb 21, 2022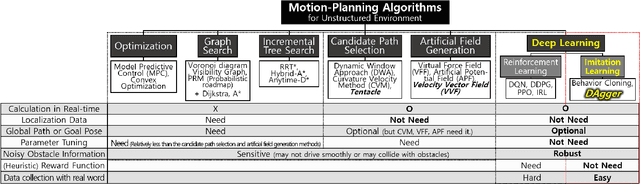

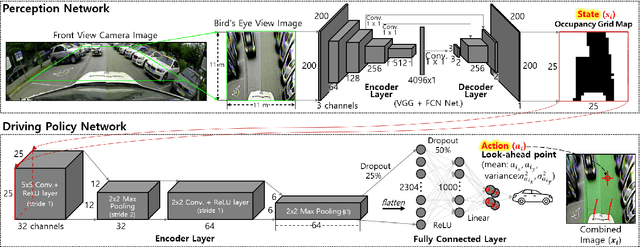

Unstructured environments are difficult for autonomous driving. This is because various unknown obstacles are lied in drivable space without lanes, and its width and curvature change widely. In such complex environments, searching for a path in real-time is difficult. Also, inaccurate localization data reduce the path tracking accuracy, increasing the risk of collision. Instead of searching and tracking the path, an alternative approach has been proposed that reactively avoids obstacles in real-time. Some methods are available for tracking global path while avoiding obstacles using the candidate paths and the artificial potential field. However, these methods require heuristics to find specific parameters for handling various complex environments. In addition, it is difficult to track the global path accurately in practice because of inaccurate localization data. If the drivable space is not accurately recognized (i.e., noisy state), the vehicle may not smoothly drive or may collide with obstacles. In this study, a method in which the vehicle drives toward drivable space only using a vision-based occupancy grid map is proposed. The proposed method uses imitation learning, where a deep neural network is trained with expert driving data. The network can learn driving patterns suited for various complex and noisy situations because these situations are contained in the training data. Experiments with a vehicle in actual parking lots demonstrated the limitations of general model-based methods and the effectiveness of the proposed imitation learning method.
Dynamic clustering of time series data
Jan 28, 2020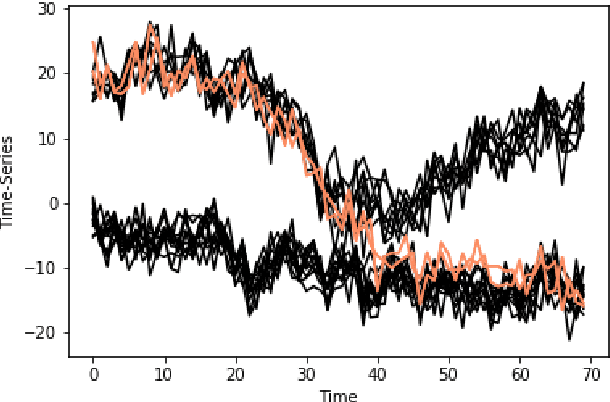
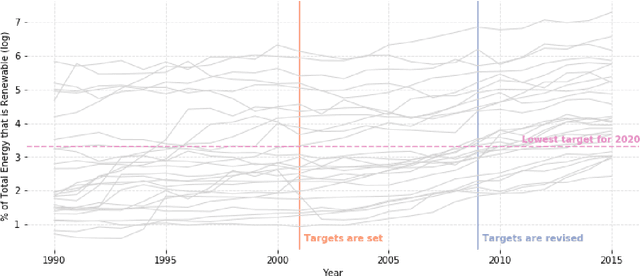
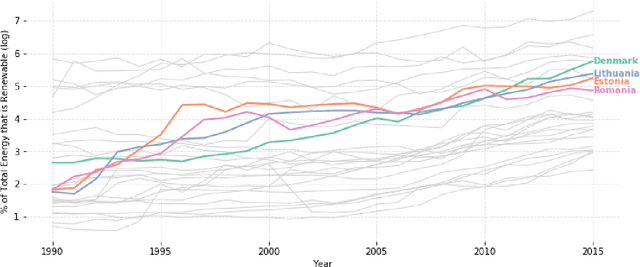
We propose a new method for clustering multivariate time-series data based on Dynamic Linear Models. Whereas usual time-series clustering methods obtain static membership parameters, our proposal allows each time-series to dynamically change their cluster memberships over time. In this context, a mixture model is assumed for the time series and a flexible Dirichlet evolution for mixture weights allows for smooth membership changes over time. Posterior estimates and predictions can be obtained through Gibbs sampling, but a more efficient method for obtaining point estimates is presented, based on Stochastic Expectation-Maximization and Gradient Descent. Finally, two applications illustrate the usefulness of our proposed model to model both univariate and multivariate time-series: World Bank indicators for the renewable energy consumption of EU nations and the famous Gapminder dataset containing life-expectancy and GDP per capita for various countries.
Estimating Individual Treatment Effects with Time-Varying Confounders
Aug 27, 2020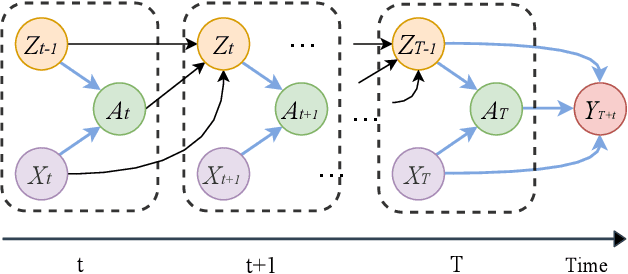
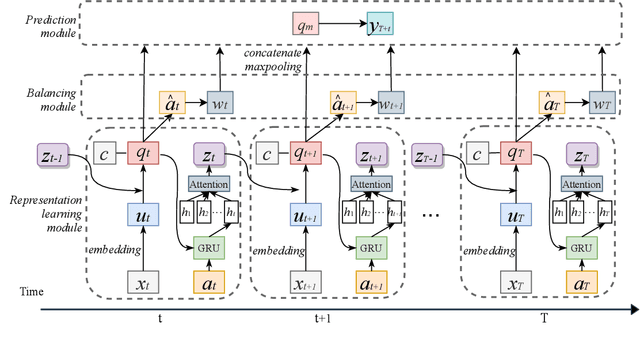
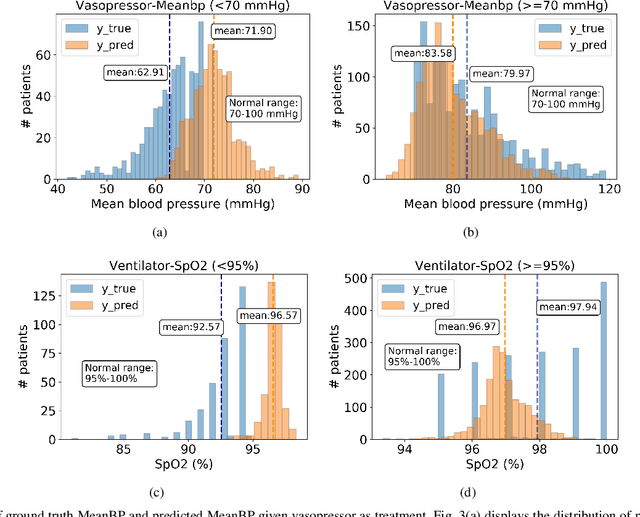

Estimating the individual treatment effect (ITE) from observational data is meaningful and practical in healthcare. Existing work mainly relies on the strong ignorability assumption that no hidden confounders exist, which may lead to bias in estimating causal effects. Some studies consider the hidden confounders are designed for static environment and not easily adaptable to a dynamic setting. In fact, most observational data (e.g., electronic medical records) is naturally dynamic and consists of sequential information. In this paper, we propose Deep Sequential Weighting (DSW) for estimating ITE with time-varying confounders. Specifically, DSW infers the hidden confounders by incorporating the current treatment assignments and historical information using a deep recurrent weighting neural network. The learned representations of hidden confounders combined with current observed data are leveraged for potential outcome and treatment predictions. We compute the time-varying inverse probabilities of treatment for re-weighting the population. We conduct comprehensive comparison experiments on fully-synthetic, semi-synthetic and real-world datasets to evaluate the performance of our model and baselines. Results demonstrate that our model can generate unbiased and accurate treatment effect by conditioning both time-varying observed and hidden confounders, paving the way for personalized medicine.
Private Sequential Hypothesis Testing for Statisticians: Privacy, Error Rates, and Sample Size
Apr 10, 2022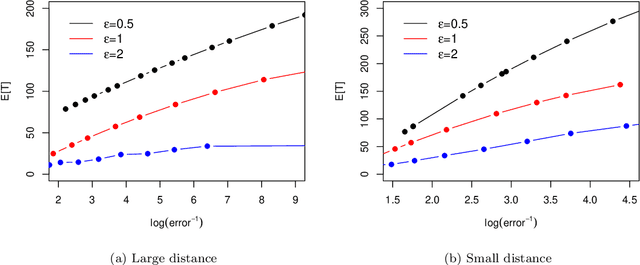
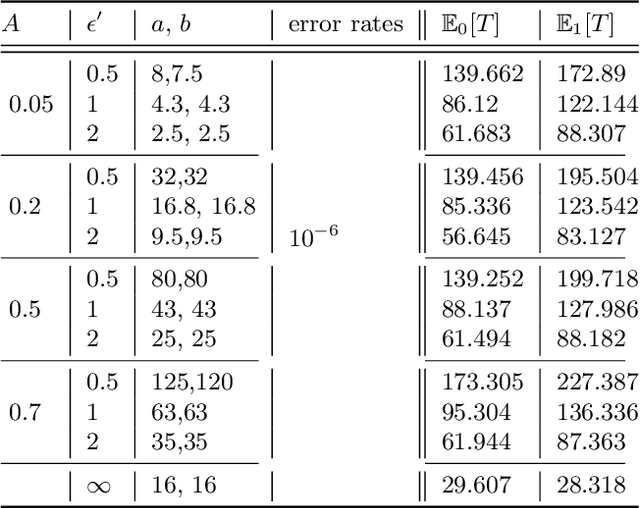
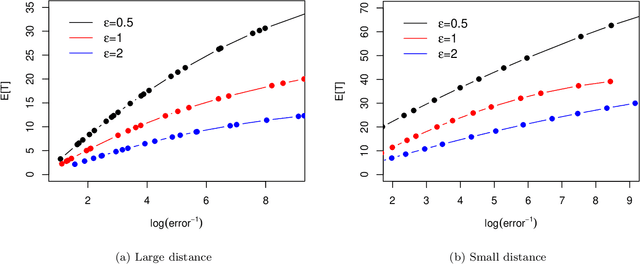
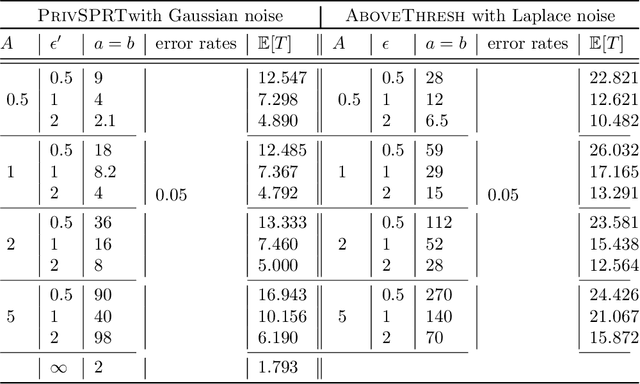
The sequential hypothesis testing problem is a class of statistical analyses where the sample size is not fixed in advance. Instead, the decision-process takes in new observations sequentially to make real-time decisions for testing an alternative hypothesis against a null hypothesis until some stopping criterion is satisfied. In many common applications of sequential hypothesis testing, the data can be highly sensitive and may require privacy protection; for example, sequential hypothesis testing is used in clinical trials, where doctors sequentially collect data from patients and must determine when to stop recruiting patients and whether the treatment is effective. The field of differential privacy has been developed to offer data analysis tools with strong privacy guarantees, and has been commonly applied to machine learning and statistical tasks. In this work, we study the sequential hypothesis testing problem under a slight variant of differential privacy, known as Renyi differential privacy. We present a new private algorithm based on Wald's Sequential Probability Ratio Test (SPRT) that also gives strong theoretical privacy guarantees. We provide theoretical analysis on statistical performance measured by Type I and Type II error as well as the expected sample size. We also empirically validate our theoretical results on several synthetic databases, showing that our algorithms also perform well in practice. Unlike previous work in private hypothesis testing that focused only on the classical fixed sample setting, our results in the sequential setting allow a conclusion to be reached much earlier, and thus saving the cost of collecting additional samples.
On the Fitness Landscapes of Interdependency Models in the Travelling Thief Problem
Feb 28, 2022
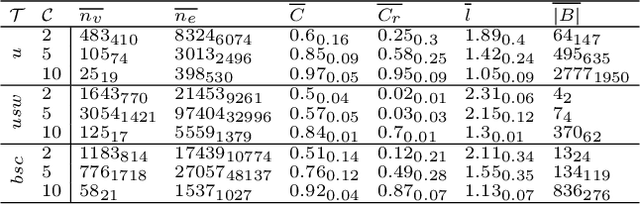
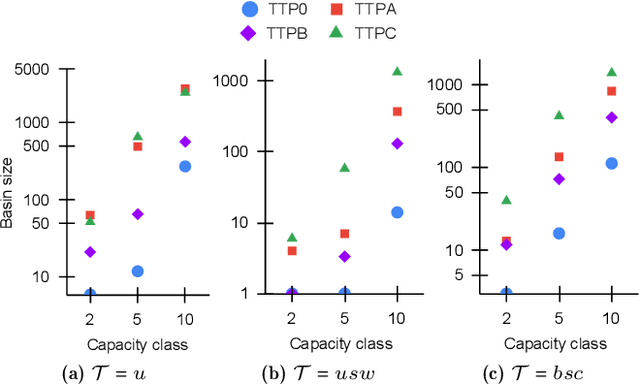
Since its inception in 2013, the Travelling Thief Problem (TTP) has been widely studied as an example of problems with multiple interconnected sub-problems. The dependency in this model arises when tying the travelling time of the "thief" to the weight of the knapsack. However, other forms of dependency as well as combinations of dependencies should be considered for investigation, as they are often found in complex real-world problems. Our goal is to study the impact of different forms of dependency in the TTP using a simple local search algorithm. To achieve this, we use Local Optima Networks, a technique for analysing the fitness landscape.
Look Outside the Room: Synthesizing A Consistent Long-Term 3D Scene Video from A Single Image
Mar 17, 2022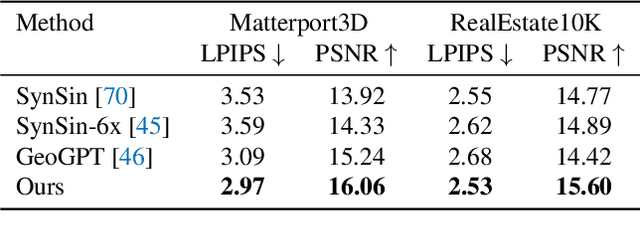
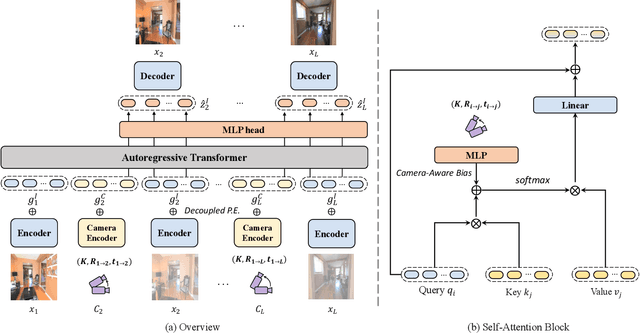
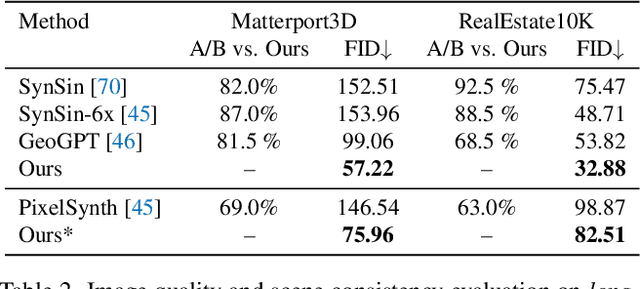
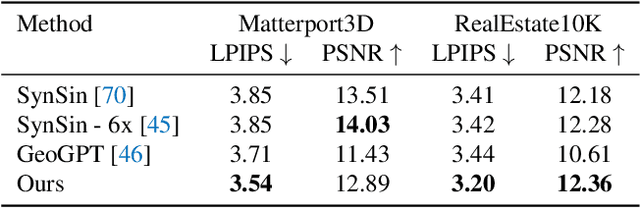
Novel view synthesis from a single image has recently attracted a lot of attention, and it has been primarily advanced by 3D deep learning and rendering techniques. However, most work is still limited by synthesizing new views within relatively small camera motions. In this paper, we propose a novel approach to synthesize a consistent long-term video given a single scene image and a trajectory of large camera motions. Our approach utilizes an autoregressive Transformer to perform sequential modeling of multiple frames, which reasons the relations between multiple frames and the corresponding cameras to predict the next frame. To facilitate learning and ensure consistency among generated frames, we introduce a locality constraint based on the input cameras to guide self-attention among a large number of patches across space and time. Our method outperforms state-of-the-art view synthesis approaches by a large margin, especially when synthesizing long-term future in indoor 3D scenes. Project page at https://xrenaa.github.io/look-outside-room/.
Network state Estimation using Raw Video Analysis: vQoS-GAN based non-intrusive Deep Learning Approach
Mar 22, 2022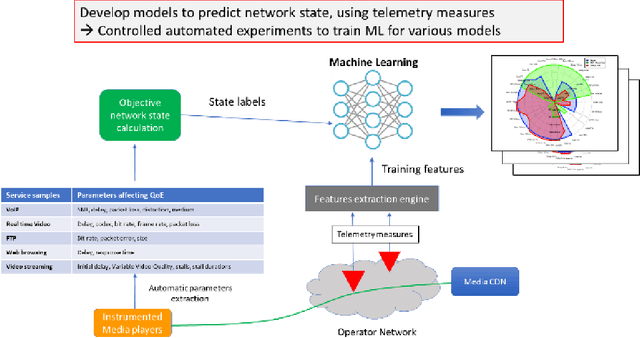

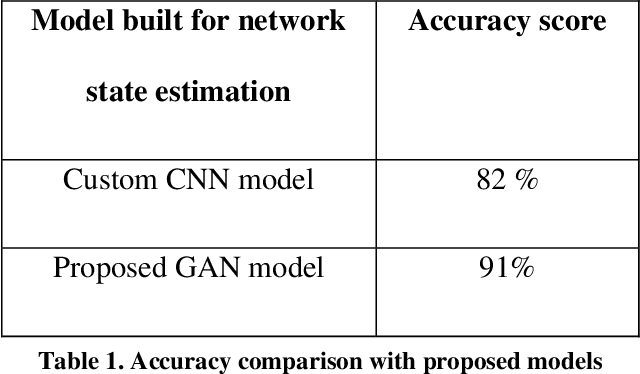

Content based providers transmits real time complex signal such as video data from one region to another. During this transmission process, the signals usually end up distorted or degraded where the actual information present in the video is lost. This normally happens in the streaming video services applications. Hence there is a need to know the level of degradation that happened in the receiver side. This video degradation can be estimated by network state parameters like data rate and packet loss values. Our proposed solution vQoS GAN (video Quality of Service Generative Adversarial Network) can estimate the network state parameters from the degraded received video data using a deep learning approach of semi supervised generative adversarial network algorithm. A robust and unique design of deep learning network model has been trained with the video data along with data rate and packet loss class labels and achieves over 95 percent of training accuracy. The proposed semi supervised generative adversarial network can additionally reconstruct the degraded video data to its original form for a better end user experience.
Multi-Task Deep Residual Echo Suppression with Echo-aware Loss
Feb 21, 2022

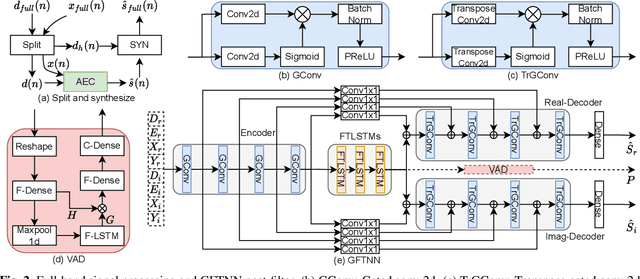
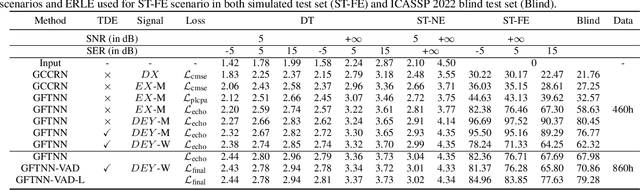
This paper introduces the NWPU Team's entry to the ICASSP 2022 AEC Challenge. We take a hybrid approach that cascades a linear AEC with a neural post-filter. The former is used to deal with the linear echo components while the latter suppresses the residual non-linear echo components. We use gated convolutional F-T-LSTM neural network (GFTNN) as the backbone and shape the post-filter by a multi-task learning (MTL) framework, where a voice activity detection (VAD) module is adopted as an auxiliary task along with echo suppression, with the aim to avoid over suppression that may cause speech distortion. Moreover, we adopt an echo-aware loss function, where the mean square error (MSE) loss can be optimized particularly for every time-frequency bin (TF-bin) according to the signal-to-echo ratio (SER), leading to further suppression on the echo. Extensive ablation study shows that the time delay estimation (TDE) module in neural post-filter leads to better perceptual quality, and an adaptive filter with better convergence will bring consistent performance gain for the post-filter. Besides, we find that using the linear echo as the input of our neural post-filter is a better choice than using the reference signal directly. In the ICASSP 2022 AEC-Challenge, our approach has ranked the 1st place on word accuracy (WAcc) (0.817) and the 3rd place on both mean opinion score (MOS) (4.502) and the final score (0.864).
Neural Part Priors: Learning to Optimize Part-Based Object Completion in RGB-D Scans
Mar 17, 2022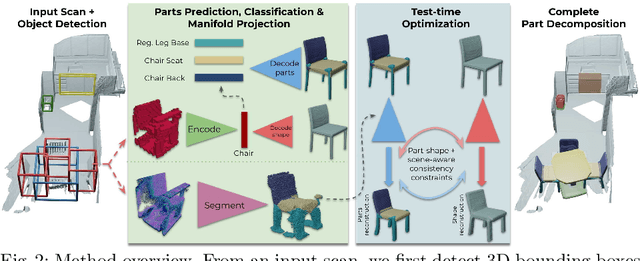
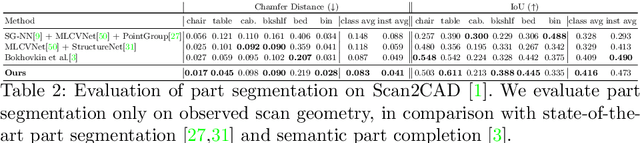
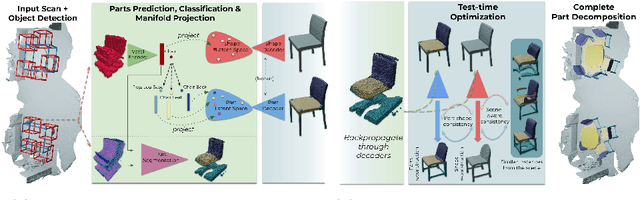
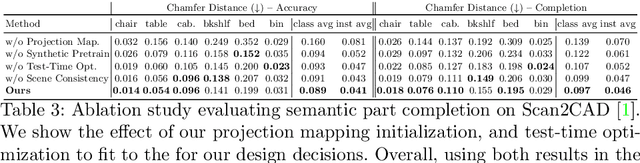
3D object recognition has seen significant advances in recent years, showing impressive performance on real-world 3D scan benchmarks, but lacking in object part reasoning, which is fundamental to higher-level scene understanding such as inter-object similarities or object functionality. Thus, we propose to leverage large-scale synthetic datasets of 3D shapes annotated with part information to learn Neural Part Priors (NPPs), optimizable spaces characterizing geometric part priors. Crucially, we can optimize over the learned part priors in order to fit to real-world scanned 3D scenes at test time, enabling robust part decomposition of the real objects in these scenes that also estimates the complete geometry of the object while fitting accurately to the observed real geometry. Moreover, this enables global optimization over geometrically similar detected objects in a scene, which often share strong geometric commonalities, enabling scene-consistent part decompositions. Experiments on the ScanNet dataset demonstrate that NPPs significantly outperforms state of the art in part decomposition and object completion in real-world scenes.