 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The role of haptic communication in dyadic collaborative object manipulation tasks
Mar 02, 2022
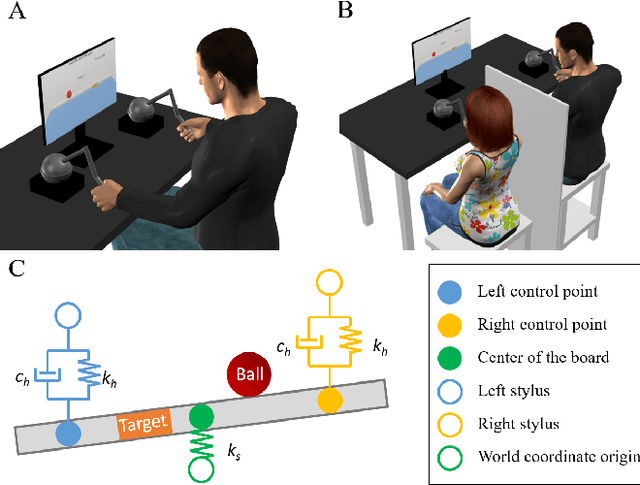
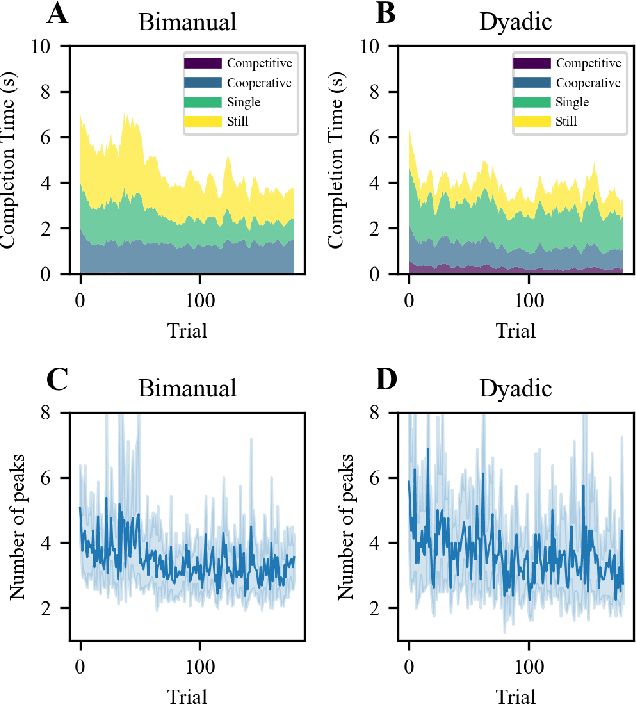
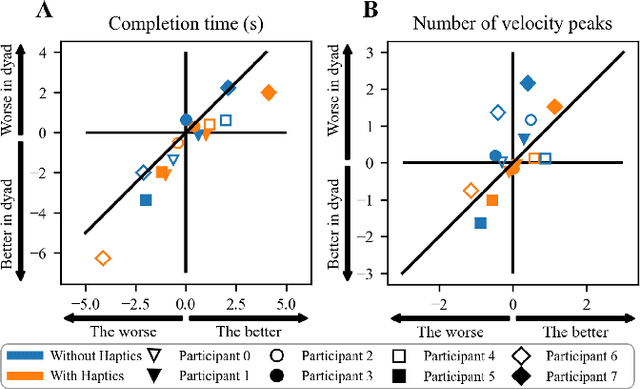
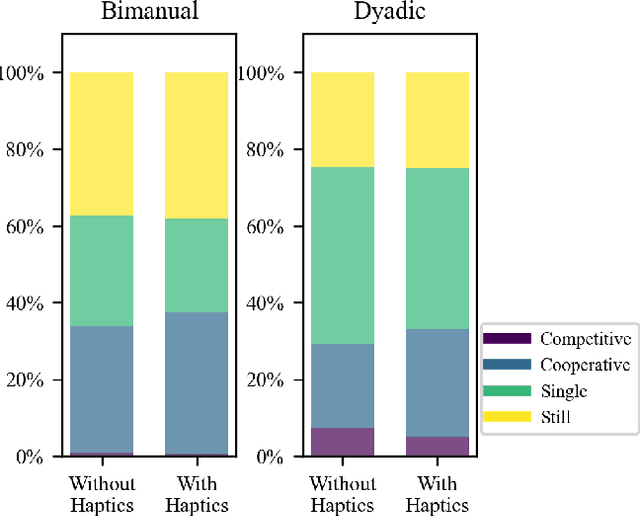
Intuitive and efficient physical human-robot collaboration relies on the mutual observability of the human and the robot, i.e. the two entities being able to interpret each other's intentions and actions. This is remedied by a myriad of methods involving human sensing or intention decoding, as well as human-robot turn-taking and sequential task planning. However, the physical interaction establishes a rich channel of communication through forces, torques and haptics in general, which is often overlooked in industrial implementations of human-robot interaction. In this work, we investigate the role of haptics in human collaborative physical tasks, to identify how to integrate physical communication in human-robot teams. We present a task to balance a ball at a target position on a board either bimanually by one participant, or dyadically by two participants, with and without haptic information. The task requires that the two sides coordinate with each other, in real-time, to balance the ball at the target. We found that with training the completion time and number of velocity peaks of the ball decreased, and that participants gradually became consistent in their braking strategy. Moreover we found that the presence of haptic information improved the performance (decreased completion time) and led to an increase in overall cooperative movements. Overall, our results show that humans can better coordinate with one another when haptic feedback is available. These results also highlight the likely importance of haptic communication in human-robot physical interaction, both as a tool to infer human intentions and to make the robot behaviour interpretable to humans.
L1-regularized neural ranking for risk stratification and its application to prediction of time to distant metastasis in luminal node negative chemotherapy naïve breast cancer patients
Aug 23, 2021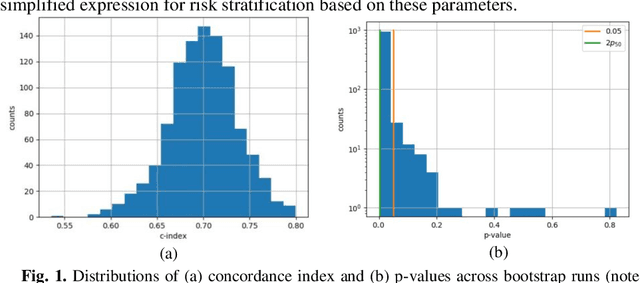

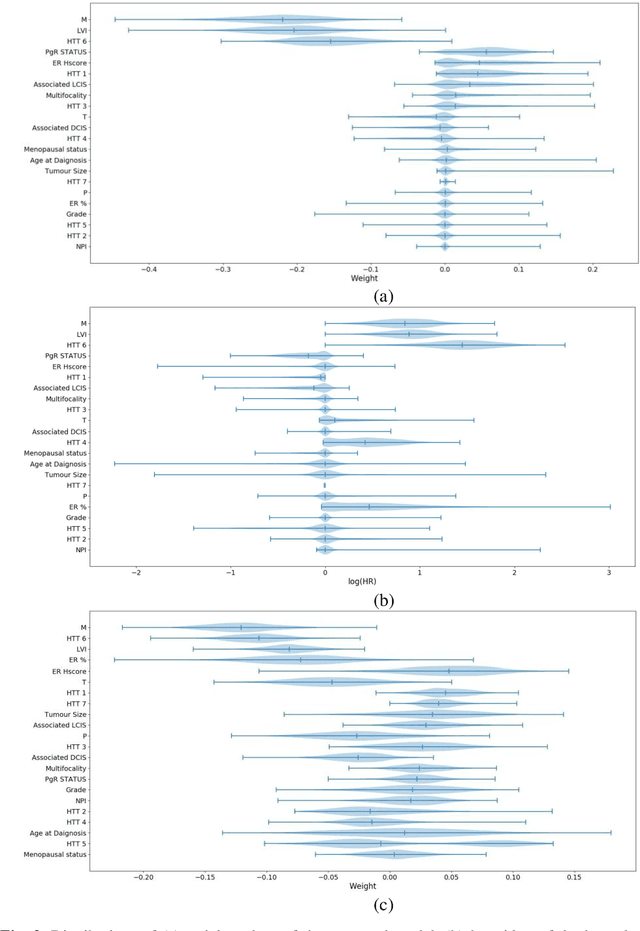
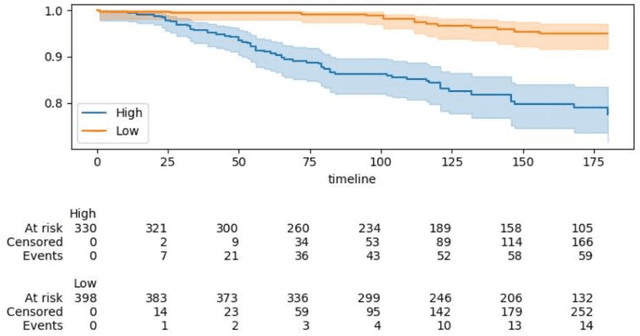
Can we predict if an early stage cancer patient is at high risk of developing distant metastasis and what clinicopathological factors are associated with such a risk? In this paper, we propose a ranking based censoring-aware machine learning model for answering such questions. The proposed model is able to generate an interpretable formula for risk stratifi-cation using a minimal number of clinicopathological covariates through L1-regulrization. Using this approach, we analyze the association of time to distant metastasis (TTDM) with various clinical parameters for early stage, luminal (ER+ or HER2-) breast cancer patients who received endocrine therapy but no chemotherapy (n = 728). The TTDM risk stratification formula obtained using the proposed approach is primarily based on mitotic score, histolog-ical tumor type and lymphovascular invasion. These findings corroborate with the known role of these covariates in increased risk for distant metastasis. Our analysis shows that the proposed risk stratification formula can discriminate between cases with high and low risk of distant metastasis (p-value < 0.005) and can also rank cases based on their time to distant metastasis with a concordance-index of 0.73.
Robust Learning of Fixed-Structure Bayesian Networks in Nearly-Linear Time
May 12, 2021We study the problem of learning Bayesian networks where an $\epsilon$-fraction of the samples are adversarially corrupted. We focus on the fully-observable case where the underlying graph structure is known. In this work, we present the first nearly-linear time algorithm for this problem with a dimension-independent error guarantee. Previous robust algorithms with comparable error guarantees are slower by at least a factor of $(d/\epsilon)$, where $d$ is the number of variables in the Bayesian network and $\epsilon$ is the fraction of corrupted samples. Our algorithm and analysis are considerably simpler than those in previous work. We achieve this by establishing a direct connection between robust learning of Bayesian networks and robust mean estimation. As a subroutine in our algorithm, we develop a robust mean estimation algorithm whose runtime is nearly-linear in the number of nonzeros in the input samples, which may be of independent interest.
Robust Real-Time Pedestrian Detection on Embedded Devices
Dec 13, 2020
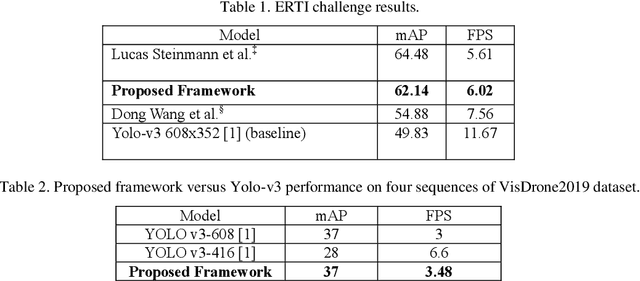
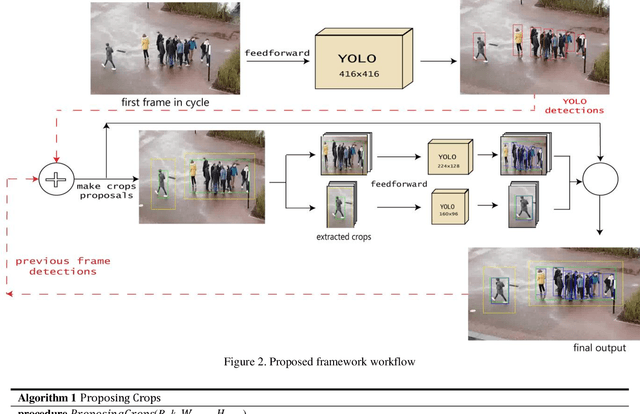

Detection of pedestrians on embedded devices, such as those on-board of robots and drones, has many applications including road intersection monitoring, security, crowd monitoring and surveillance, to name a few. However, the problem can be challenging due to continuously-changing camera viewpoint and varying object appearances as well as the need for lightweight algorithms suitable for embedded systems. This paper proposes a robust framework for pedestrian detection in many footages. The framework performs fine and coarse detections on different image regions and exploits temporal and spatial characteristics to attain enhanced accuracy and real time performance on embedded boards. The framework uses the Yolo-v3 object detection [1] as its backbone detector and runs on the Nvidia Jetson TX2 embedded board, however other detectors and/or boards can be used as well. The performance of the framework is demonstrated on two established datasets and its achievement of the second place in CVPR 2019 Embedded Real-Time Inference (ERTI) Challenge.
Leveraging Smooth Attention Prior for Multi-Agent Trajectory Prediction
Mar 08, 2022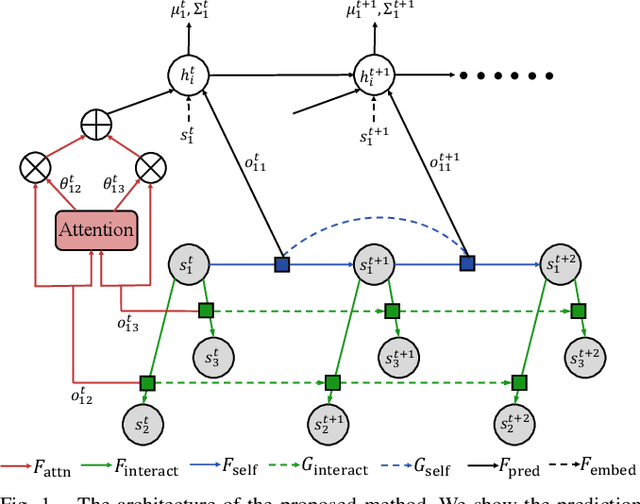
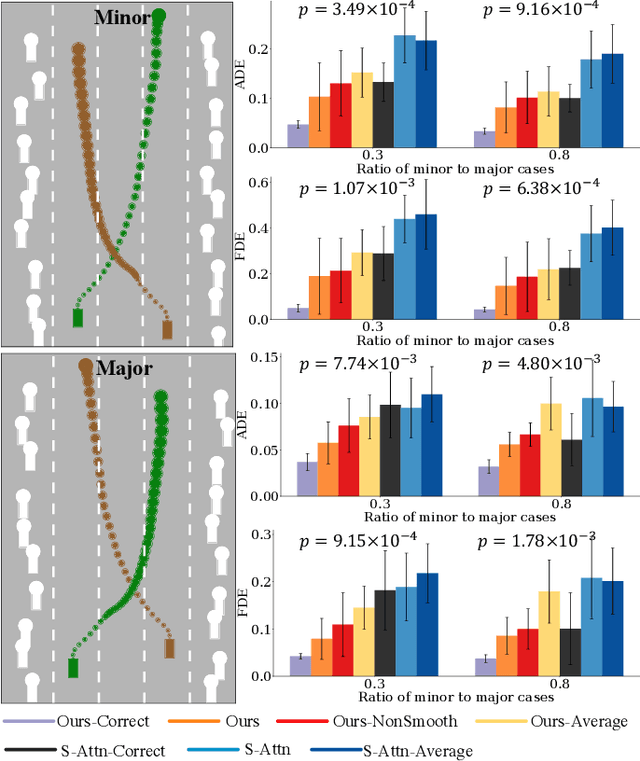
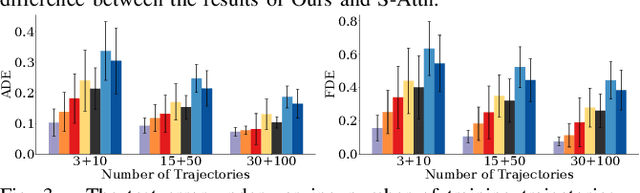
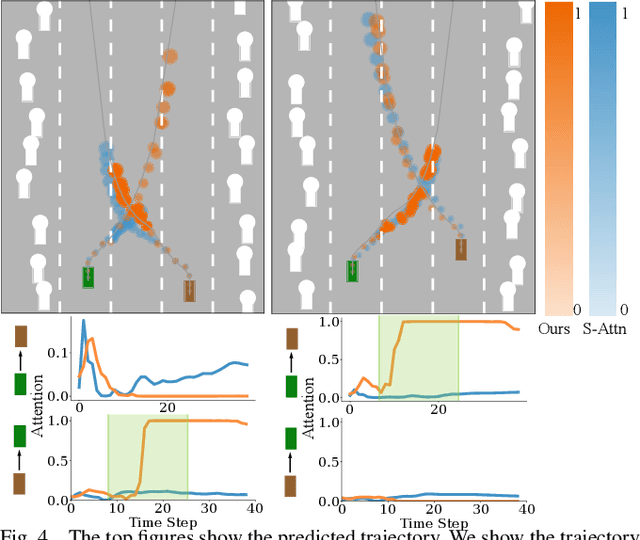
Multi-agent interactions are important to model for forecasting other agents' behaviors and trajectories. At a certain time, to forecast a reasonable future trajectory, each agent needs to pay attention to the interactions with only a small group of most relevant agents instead of unnecessarily paying attention to all the other agents. However, existing attention modeling works ignore that human attention in driving does not change rapidly, and may introduce fluctuating attention across time steps. In this paper, we formulate an attention model for multi-agent interactions based on a total variation temporal smoothness prior and propose a trajectory prediction architecture that leverages the knowledge of these attended interactions. We demonstrate how the total variation attention prior along with the new sequence prediction loss terms leads to smoother attention and more sample-efficient learning of multi-agent trajectory prediction, and show its advantages in terms of prediction accuracy by comparing it with the state-of-the-art approaches on both synthetic and naturalistic driving data. We demonstrate the performance of our algorithm for trajectory prediction on the INTERACTION dataset on our website.
* 8 pages
Real-time Ionospheric Imaging of S4 Scintillation from Limited Data with Parallel Kalman Filters and Smoothness
May 11, 2021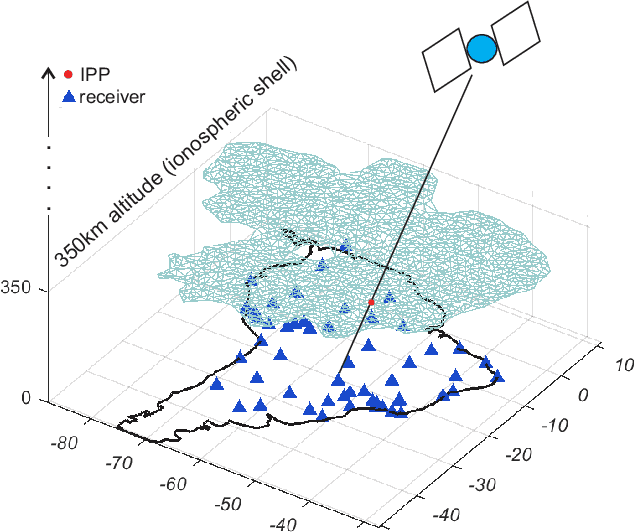
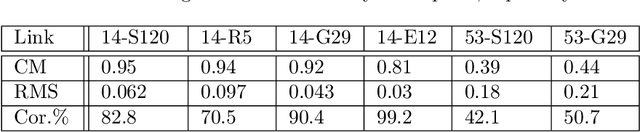
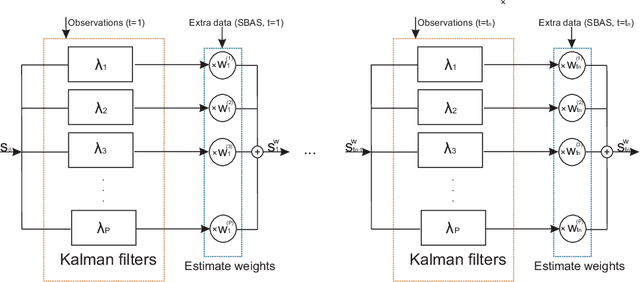
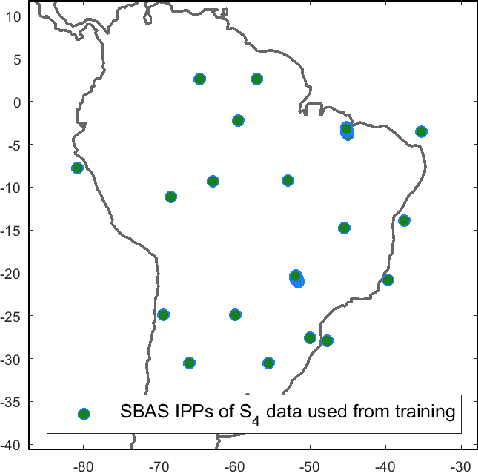
In this paper, we propose a Bayesian framework to create two dimensional ionospheric images of high spatio-temporal resolution to monitor ionospheric irregularities as measured by the S4 index. Here, we recast the standard Bayesian recursive filtering for a linear Gaussian state-space model, also referred to as the Kalman filter, first by augmenting the (pierce point) observation model with connectivity information stemming from the insight and assumptions/standard modeling about the spatial distribution of the scintillation activity on the ionospheric shell at 350 km altitude. Thus, we achieve to handle the limited spatio-temporal observations. Then, by introducing a set of Kalman filters running in parallel, we mitigate the uncertainty related to a tuning parameter of the proposed augmented model. The output images are a weighted average of the state estimates of the individual filters. We demonstrate our approach by rendering two dimensional real-time ionospheric images of S4 amplitude scintillation at 350 km over South America with temporal resolution of one minute. Furthermore, we employ extra S4 data that was not used in producing these ionospheric images, to check and verify the ability of our images to predict this extra data in particular ionospheric pierce points. Our results show that in areas with a network of ground receivers with a relatively good coverage (e.g. within a couple of kilometers distance) the produced images can provide reliable real-time results. Our proposed algorithmic framework can be readily used to visualize real-time ionospheric images taking as inputs the available scintillation data provided from freely available web-servers.
A Novel Deep Learning Model for Hotel Demand and Revenue Prediction amid COVID-19
Mar 08, 2022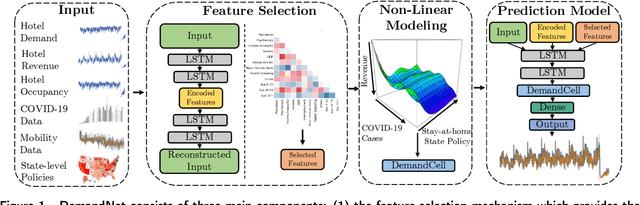
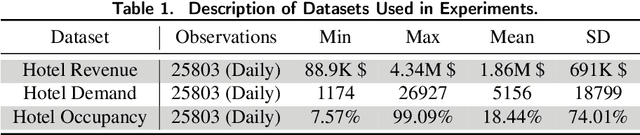
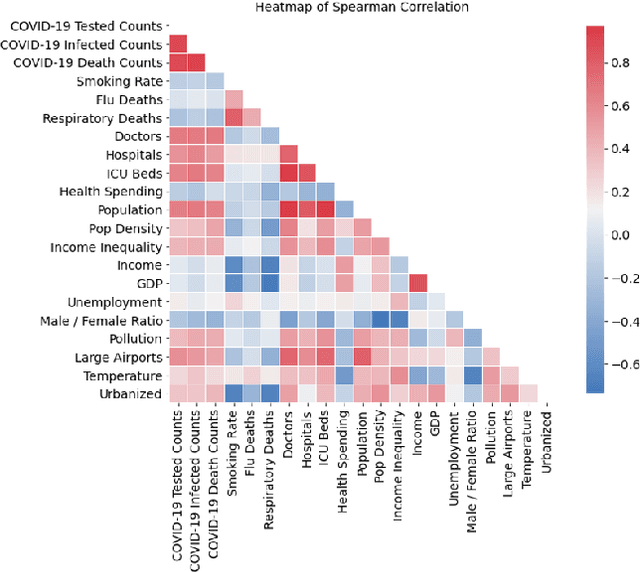
The COVID-19 pandemic has significantly impacted the tourism and hospitality sector. Public policies such as travel restrictions and stay-at-home orders had significantly affected tourist activities and service businesses' operations and profitability. To this end, it is essential to develop an interpretable forecast model that supports managerial and organizational decision-making. We developed DemandNet, a novel deep learning framework for predicting time series data under the influence of the COVID-19 pandemic. The framework starts by selecting the top static and dynamic features embedded in the time series data. Then, it includes a nonlinear model which can provide interpretable insight into the previously seen data. Lastly, a prediction model is developed to leverage the above characteristics to make robust long-term forecasts. We evaluated the framework using daily hotel demand and revenue data from eight cities in the US. Our findings reveal that DemandNet outperforms the state-of-art models and can accurately predict the impact of the COVID-19 pandemic on hotel demand and revenues.
* 55th Hawaii International Conference on System Sciences (HICSS) 2022
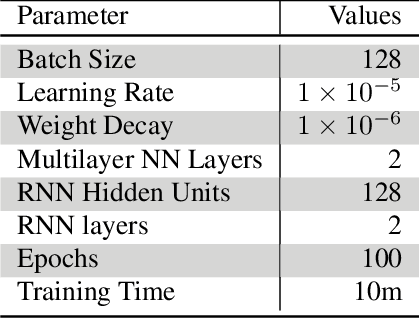
Heterogeneous graph neural network for power allocation in multicarrier-division duplex cell-free massive MIMO systems
May 05, 2022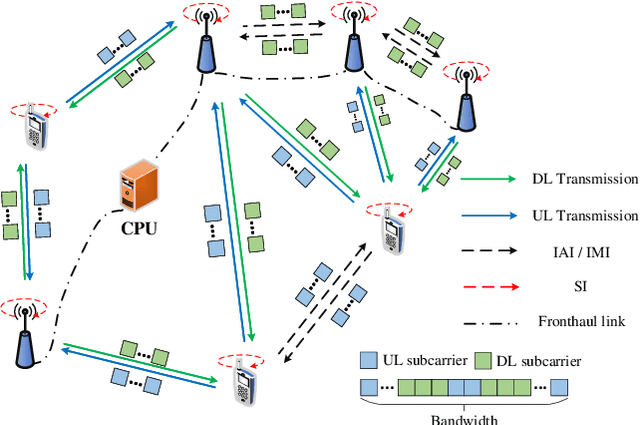
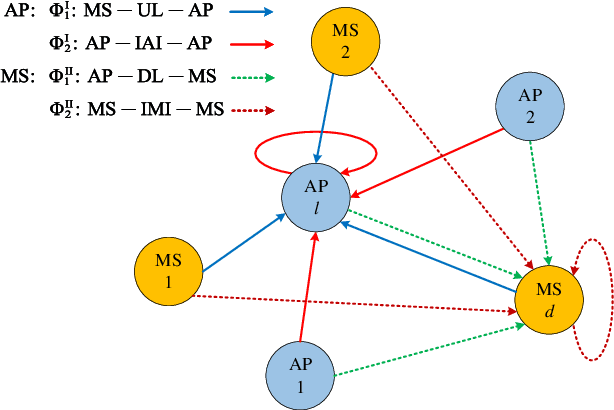
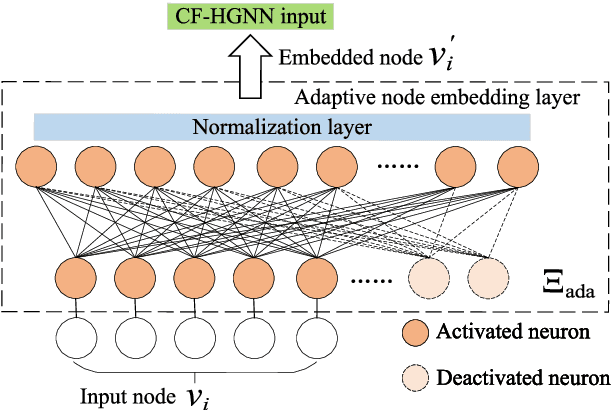
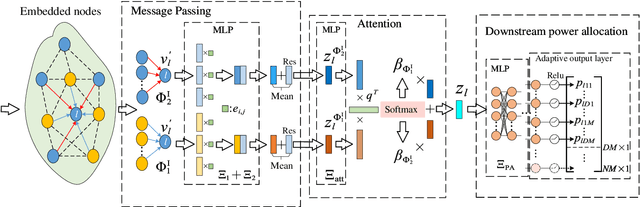
In-band full duplex-based cell-free (IBFD-CF) systems suffer from severe interference problem including self-interference (SI) and cross-link interference (CLI), especially when cell-free (CF) systems are operated in a distributed way. To this end, we propose multicarrier-division duplex (MDD) as an enabler for full-duplex (FD)-style operation in distributed CF massive MIMO systems, where DL and UL transmissions take place simultaneously at the same frequency band but mutually orthogonal subcarrier sets. In order to maximize the spectral efficiency (SE) in the proposed systems, we present heterogeneous graph neural network specific for CF systems (CF-HGNN), which consists of an adaptive node embedding layer, meta-path based message passing, meta-path based attention and downstream power allocation learning. In particular, the adaptive node embedding layer can handle the varying number of access points (APs), mobile stations (MSs) and subcarriers, and the involved attention mechanism enables each AP/MS node in CF-HGNN to aggregate the information from interfering path and communication path with different priorities. Numerical results show that CF-HGNN is capable of using $10^4$ times less operation time to achieve the 99% performance of the SE of quadratic transform and successive convex approximation (QT-SCA). Additionally, CF-HGNN also significantly outperforms unfair greedy method in terms of SE performance. Furthermore, CF-HGNN exhibits good adaptivity to varying number of nodes and subcarriers, and also generalization ability to different sizes of CF network.
On Parametric Optimal Execution and Machine Learning Surrogates
Apr 28, 2022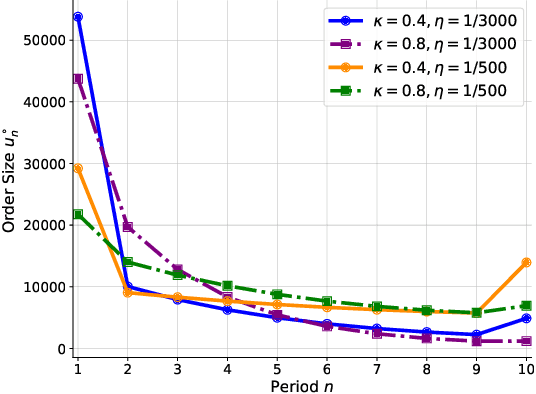

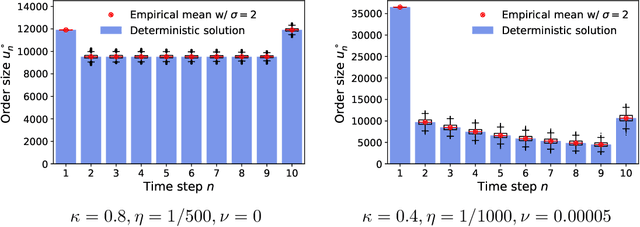
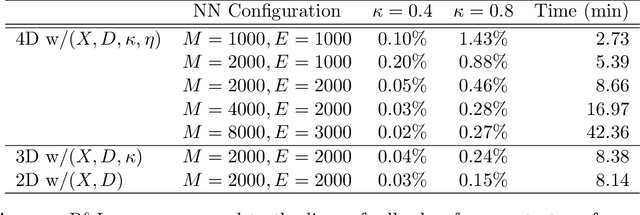
We investigate optimal order execution problems in discrete time with instantaneous price impact and stochastic resilience. First, in the setting of linear transient price impact we derive a closed-form recursion for the optimal strategy, extending the deterministic results from Obizhaeva and Wang (J Financial Markets, 2013). Second, we develop a numerical algorithm based on dynamic programming and deep learning for the case of nonlinear transient price impact as proposed by Bouchaud et al. (Quant. Finance, 2004). Specifically, we utilize an actor-critic framework that constructs two neural-network (NN) surrogates for the value function and the feedback control. The flexible scalability of NN functional approximators enables parametric learning, i.e., incorporating several model or market parameters as part of the input space. Precise calibration of price impact, resilience, etc., is known to be extremely challenging and hence it is critical to understand sensitivity of the execution policy to these parameters. Our NN learner organically scales across multiple input dimensions and is shown to accurately approximate optimal strategies across a wide range of parameter configurations. We provide a fully reproducible Jupyter Notebook with our NN implementation, which is of independent pedagogical interest, demonstrating the ease of use of NN surrogates in (parametric) stochastic control problems.
Transformer Decoders with MultiModal Regularization for Cross-Modal Food Retrieval
Apr 20, 2022



Cross-modal image-recipe retrieval has gained significant attention in recent years. Most work focuses on improving cross-modal embeddings using unimodal encoders, that allow for efficient retrieval in large-scale databases, leaving aside cross-attention between modalities which is more computationally expensive. We propose a new retrieval framework, T-Food (Transformer Decoders with MultiModal Regularization for Cross-Modal Food Retrieval) that exploits the interaction between modalities in a novel regularization scheme, while using only unimodal encoders at test time for efficient retrieval. We also capture the intra-dependencies between recipe entities with a dedicated recipe encoder, and propose new variants of triplet losses with dynamic margins that adapt to the difficulty of the task. Finally, we leverage the power of the recent Vision and Language Pretraining (VLP) models such as CLIP for the image encoder. Our approach outperforms existing approaches by a large margin on the Recipe1M dataset. Specifically, we achieve absolute improvements of 8.1 % (72.6 R@1) and +10.9 % (44.6 R@1) on the 1k and 10k test sets respectively. The code is available here:https://github.com/mshukor/TFood