 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved LiDAR Odometry and Mapping using Deep Semantic Segmentation and Novel Outliers Detection
Mar 05, 2024Perception is a key element for enabling intelligent autonomous navigation. Understanding the semantics of the surrounding environment and accurate vehicle pose estimation are essential capabilities for autonomous vehicles, including self-driving cars and mobile robots that perform complex tasks. Fast moving platforms like self-driving cars impose a hard challenge for localization and mapping algorithms. In this work, we propose a novel framework for real-time LiDAR odometry and mapping based on LOAM architecture for fast moving platforms. Our framework utilizes semantic information produced by a deep learning model to improve point-to-line and point-to-plane matching between LiDAR scans and build a semantic map of the environment, leading to more accurate motion estimation using LiDAR data. We observe that including semantic information in the matching process introduces a new type of outlier matches to the process, where matching occur between different objects of the same semantic class. To this end, we propose a novel algorithm that explicitly identifies and discards potential outliers in the matching process. In our experiments, we study the effect of improving the matching process on the robustness of LiDAR odometry against high speed motion. Our experimental evaluations on KITTI dataset demonstrate that utilizing semantic information and rejecting outliers significantly enhance the robustness of LiDAR odometry and mapping when there are large gaps between scan acquisition poses, which is typical for fast moving platforms.
Robust Real-Time Pedestrian Detection on Embedded Devices
Dec 13, 2020
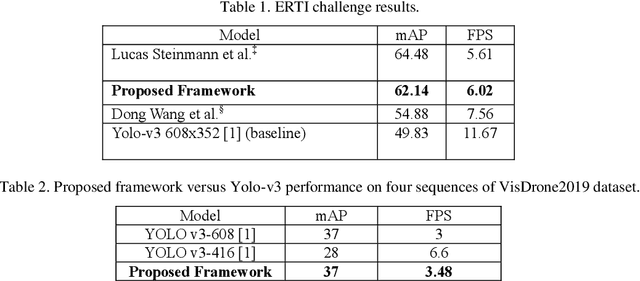
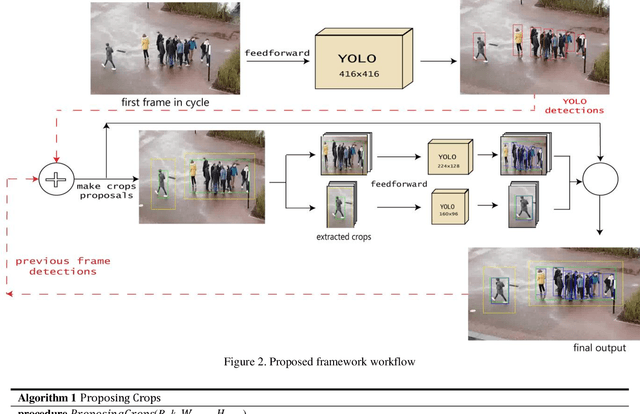

Detection of pedestrians on embedded devices, such as those on-board of robots and drones, has many applications including road intersection monitoring, security, crowd monitoring and surveillance, to name a few. However, the problem can be challenging due to continuously-changing camera viewpoint and varying object appearances as well as the need for lightweight algorithms suitable for embedded systems. This paper proposes a robust framework for pedestrian detection in many footages. The framework performs fine and coarse detections on different image regions and exploits temporal and spatial characteristics to attain enhanced accuracy and real time performance on embedded boards. The framework uses the Yolo-v3 object detection [1] as its backbone detector and runs on the Nvidia Jetson TX2 embedded board, however other detectors and/or boards can be used as well. The performance of the framework is demonstrated on two established datasets and its achievement of the second place in CVPR 2019 Embedded Real-Time Inference (ERTI) Challenge.
Multi Projection Fusion for Real-time Semantic Segmentation of 3D LiDAR Point Clouds
Nov 06, 2020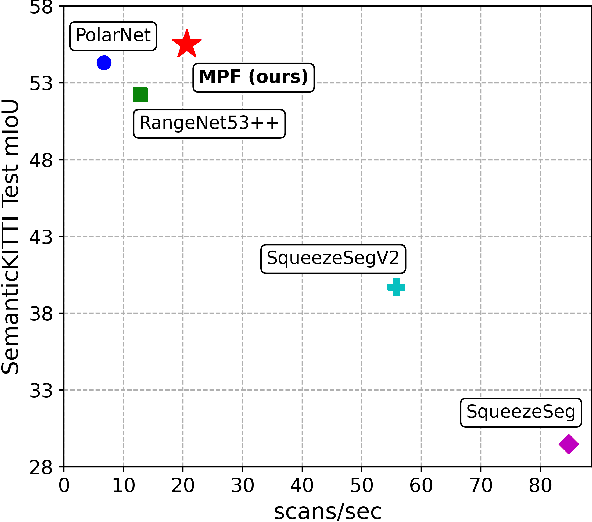
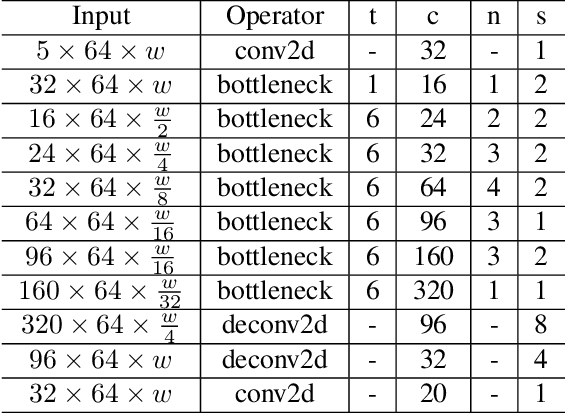
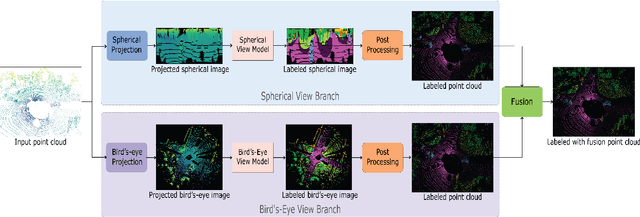
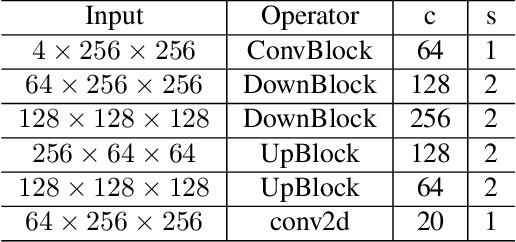
Semantic segmentation of 3D point cloud data is essential for enhanced high-level perception in autonomous platforms. Furthermore, given the increasing deployment of LiDAR sensors onboard of cars and drones, a special emphasis is also placed on non-computationally intensive algorithms that operate on mobile GPUs. Previous efficient state-of-the-art methods relied on 2D spherical projection of point clouds as input for 2D fully convolutional neural networks to balance the accuracy-speed trade-off. This paper introduces a novel approach for 3D point cloud semantic segmentation that exploits multiple projections of the point cloud to mitigate the loss of information inherent in single projection methods. Our Multi-Projection Fusion (MPF) framework analyzes spherical and bird's-eye view projections using two separate highly-efficient 2D fully convolutional models then combines the segmentation results of both views. The proposed framework is validated on the SemanticKITTI dataset where it achieved a mIoU of 55.5 which is higher than state-of-the-art projection-based methods RangeNet++ and PolarNet while being 1.6x faster than the former and 3.1x faster than the latter.
Robust Real-time Pedestrian Detection in Aerial Imagery on Jetson TX2
May 16, 2019
Detection of pedestrians in aerial imagery captured by drones has many applications including intersection monitoring, patrolling, and surveillance, to name a few. However, the problem is involved due to continuouslychanging camera viewpoint and object appearance as well as the need for lightweight algorithms to run on on-board embedded systems. To address this issue, the paper proposes a framework for pedestrian detection in videos based on the YOLO object detection network [6] while having a high throughput of more than 5 FPS on the Jetson TX2 embedded board. The framework exploits deep learning for robust operation and uses a pre-trained model without the need for any additional training which makes it flexible to apply on different setups with minimum amount of tuning. The method achieves ~81 mAP when applied on a sample video from the Embedded Real-Time Inference (ERTI) Challenge where pedestrians are monitored by a UAV.