 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
View-labels Are Indispensable: A Multifacet Complementarity Study of Multi-view Clustering
May 05, 2022
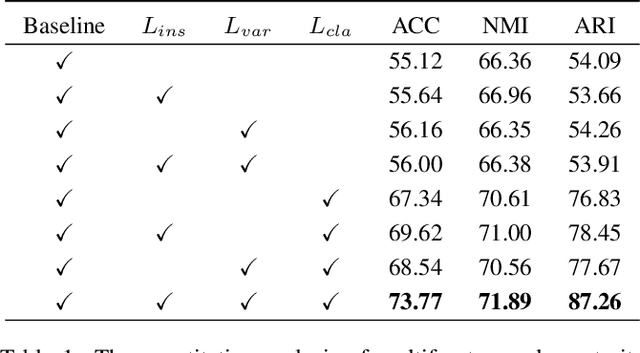
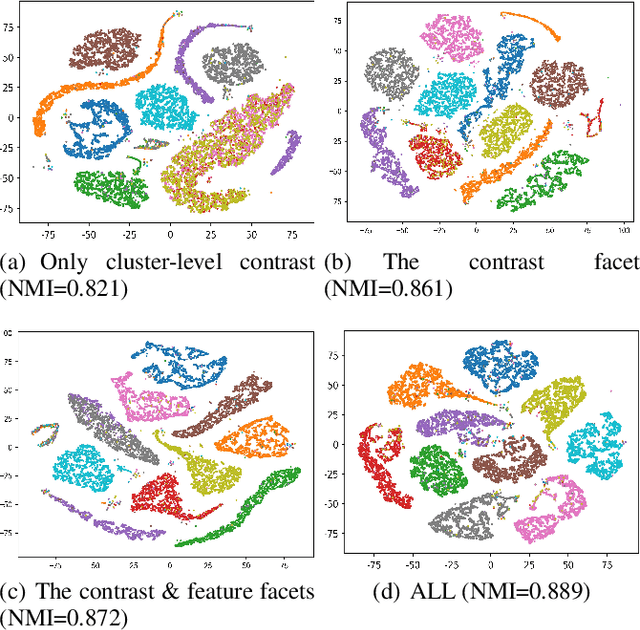
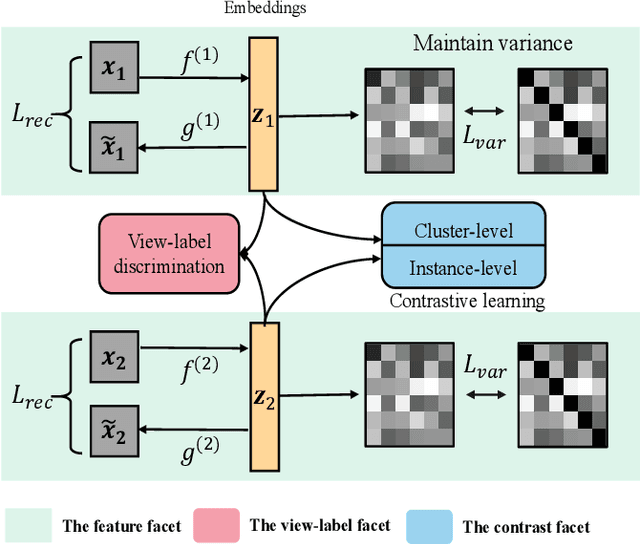
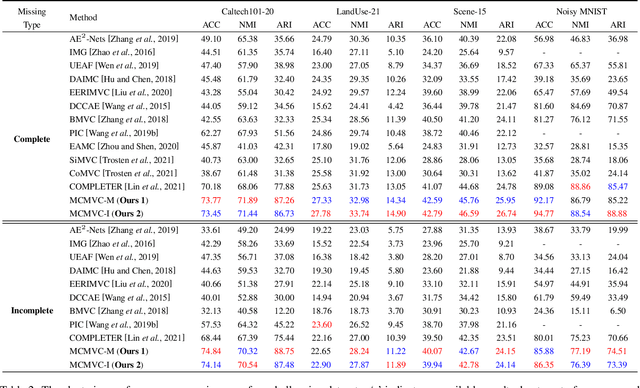
Consistency and complementarity are two key ingredients for boosting multi-view clustering (MVC). Recently with the introduction of popular contrastive learning, the consistency learning of views has been further enhanced in MVC, leading to promising performance. However, by contrast, the complementarity has not received sufficient attention except just in the feature facet, where the Hilbert Schmidt Independence Criterion (HSIC) term or the independent encoder-decoder network is usually adopted to capture view-specific information. This motivates us to reconsider the complementarity learning of views comprehensively from multiple facets including the feature-, view-label- and contrast- facets, while maintaining the view consistency. We empirically find that all the facets contribute to the complementarity learning, especially the view-label facet, which is usually neglected by existing methods. Based on this, we develop a novel \underline{M}ultifacet \underline{C}omplementarity learning framework for \underline{M}ulti-\underline{V}iew \underline{C}lustering (MCMVC), which fuses multifacet complementarity information, especially explicitly embedding the view-label information. To our best knowledge, it is the first time to use view-labels explicitly to guide the complementarity learning of views. Compared with the SOTA baseline, MCMVC achieves remarkable improvements, e.g., by average margins over $5.00\%$ and $7.00\%$ respectively in complete and incomplete MVC settings on Caltech101-20 in terms of three evaluation metrics.
An Automatic Detection Method Of Cerebral Aneurysms In Time-Of-Flight Magnetic Resonance Angiography Images Based On Attention 3D U-Net
Oct 26, 2021

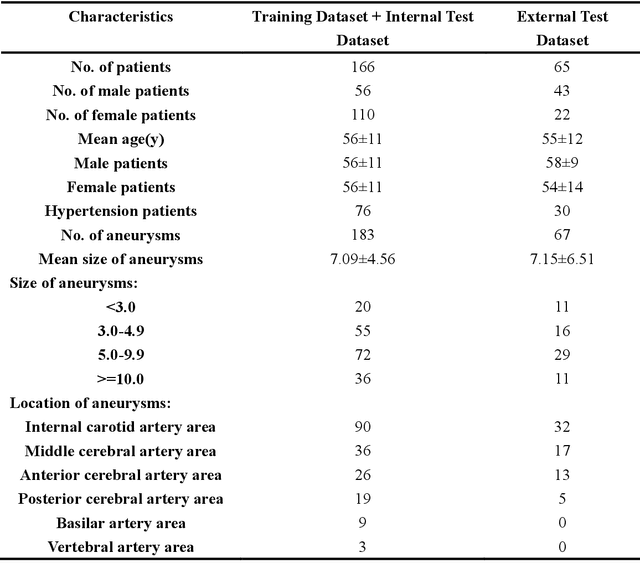
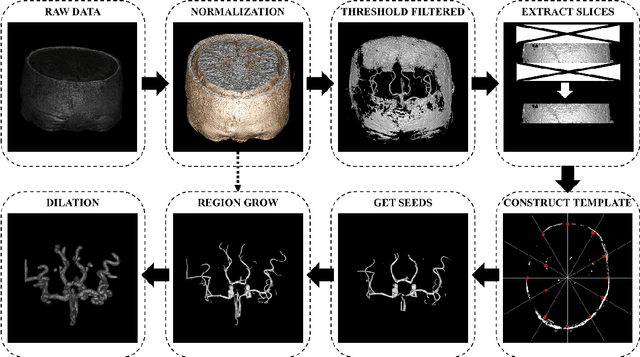
Background:Subarachnoid hemorrhage caused by ruptured cerebral aneurysm often leads to fatal consequences.However,if the aneurysm can be found and treated during asymptomatic periods,the probability of rupture can be greatly reduced.At present,time-of-flight magnetic resonance angiography is one of the most commonly used non-invasive screening techniques for cerebral aneurysm,and the application of deep learning technology in aneurysm detection can effectively improve the screening effect of aneurysm.Existing studies have found that three-dimensional features play an important role in aneurysm detection,but they require a large amount of training data and have problems such as a high false positive rate. Methods:This paper proposed a novel method for aneurysm detection.First,a fully automatic cerebral artery segmentation algorithm without training data was used to extract the volume of interest,and then the 3D U-Net was improved by the 3D SENet module to establish an aneurysm detection model.Eventually a set of fully automated,end-to-end aneurysm detection methods have been formed. Results:A total of 231 magnetic resonance angiography image data were used in this study,among which 132 were training sets,34 were internal test sets and 65 were external test sets.The presented method obtained 97.89% sensitivity in the five-fold cross-validation and obtained 91.0% sensitivity with 2.48 false positives/case in the detection of the external test sets. Conclusions:Compared with the results of our previous studies and other studies,the method in this paper achieves a very competitive sensitivity with less training data and maintains a low false positive rate.As the only method currently using 3D U-Net for aneurysm detection,it proves the feasibility and superior performance of this network in aneurysm detection,and also explores the potential of the channel attention mechanism in this task.
Optimal control of point-to-point navigation in turbulent time-dependent flows using Reinforcement Learning
Feb 27, 2021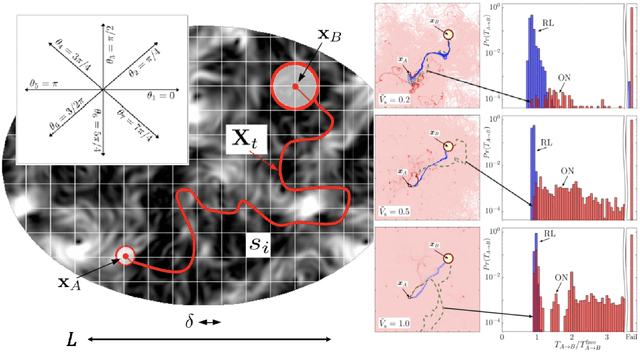
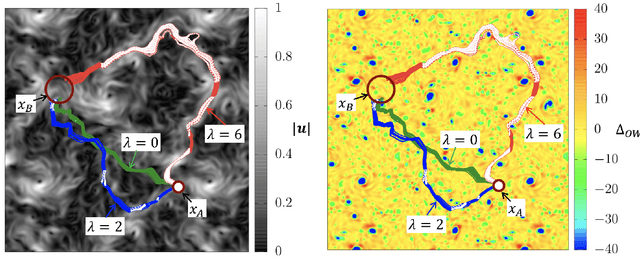
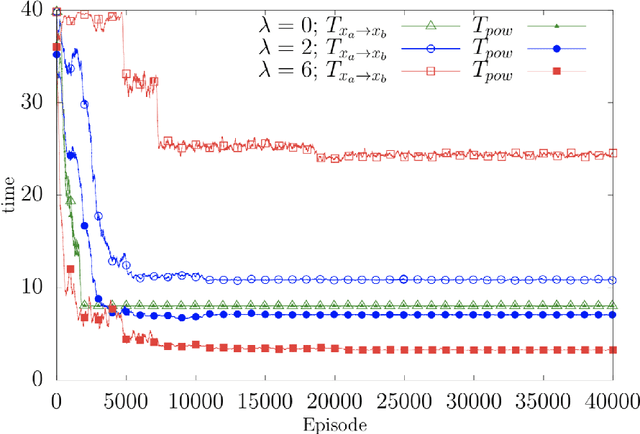
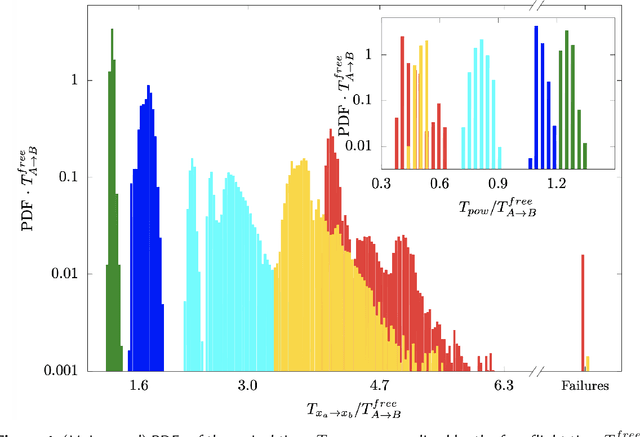
We present theoretical and numerical results concerning the problem to find the path that minimizes the time to navigate between two given points in a complex fluid under realistic navigation constraints. We contrast deterministic Optimal Navigation (ON) control with stochastic policies obtained by Reinforcement Learning (RL) algorithms. We show that Actor-Critic RL algorithms are able to find quasi-optimal solutions in the presence of either time-independent or chaotically evolving flow configurations. For our application, ON solutions develop unstable behavior within the typical duration of the navigation process, and are therefore not useful in practice. We first explore navigation of turbulent flow using a constant propulsion speed. Based on a discretized phase-space, the propulsion direction is adjusted with the aim to minimize the time spent to reach the target. Further, we explore a case where additional control is obtained by allowing the engine to power off. Exploiting advection of the underlying flow, allows the target to be reached with less energy consumption. In this case, we optimize a linear combination between the total navigation time and the total time the engine is switched off. Our approach can be generalized to other setups, for example, navigation under imperfect environmental forecast or with different models for the moving vessel.
Continual and Sliding Window Release for Private Empirical Risk Minimization
Mar 07, 2022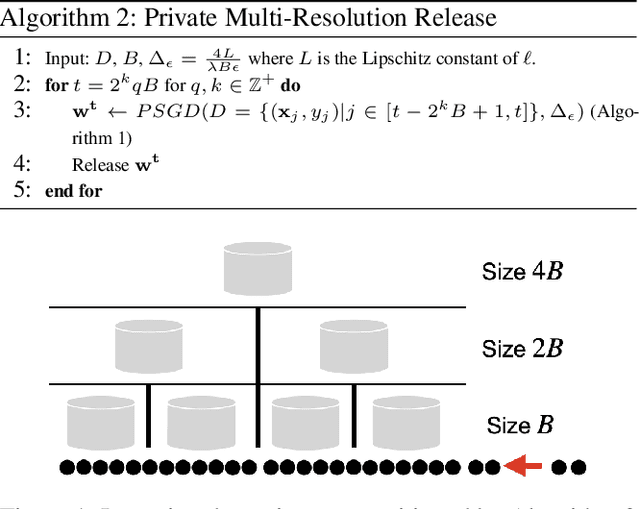
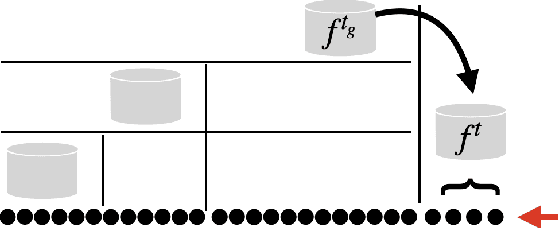
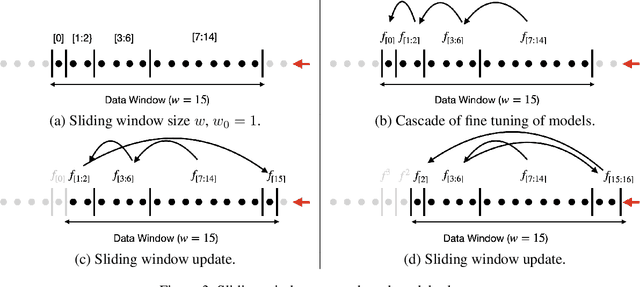
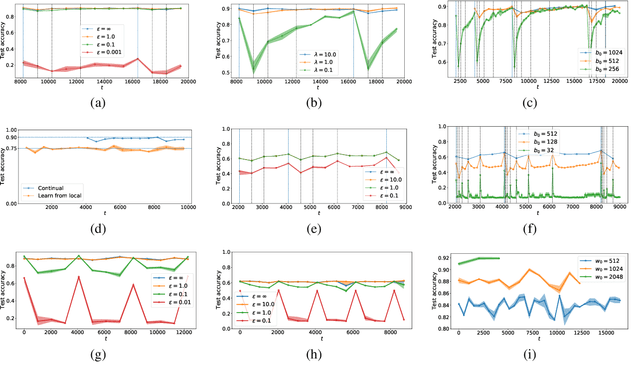
It is difficult to continually update private machine learning models with new data while maintaining privacy. Data incur increasing privacy loss -- as measured by differential privacy -- when they are used in repeated computations. In this paper, we describe regularized empirical risk minimization algorithms that continually release models for a recent window of data. One version of the algorithm uses the entire data history to improve the model for the recent window. The second version uses a sliding window of constant size to improve the model, ensuring more relevant models in case of evolving data. The algorithms operate in the framework of stochastic gradient descent. We prove that even with releasing a model at each time-step over an infinite time horizon, the privacy cost of any data point is bounded by a constant $\epsilon$ differential privacy, and the accuracy of the output models are close to optimal. Experiments on MNIST and Arxiv publications data show results consistent with the theory.
ActionFormer: Localizing Moments of Actions with Transformers
Feb 16, 2022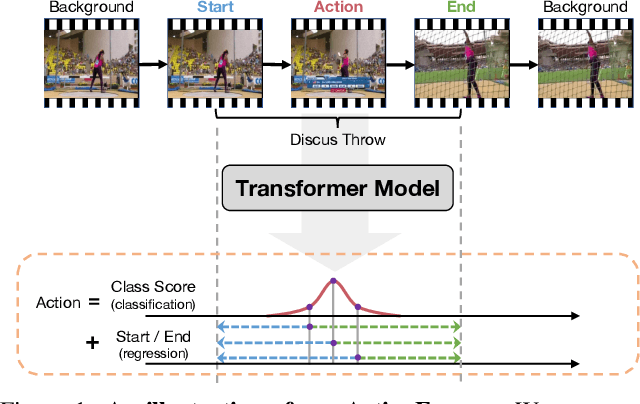
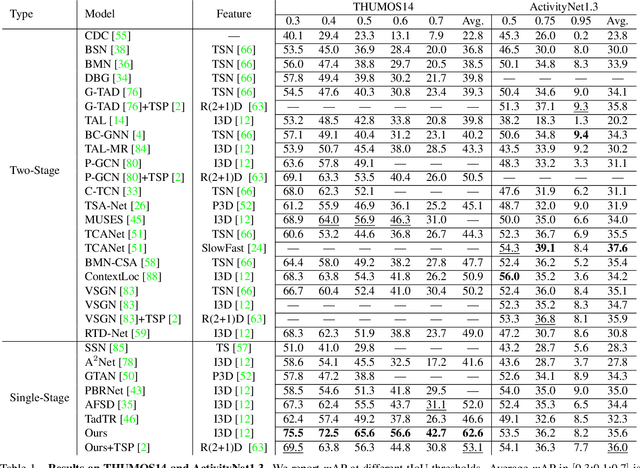
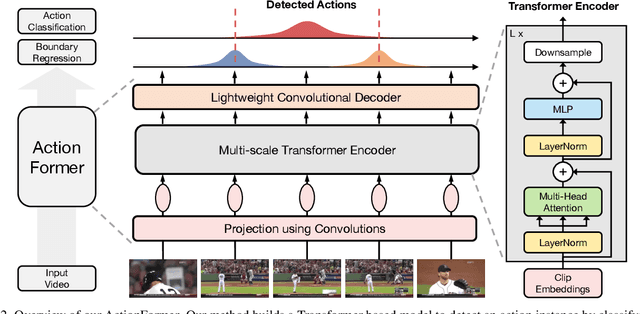
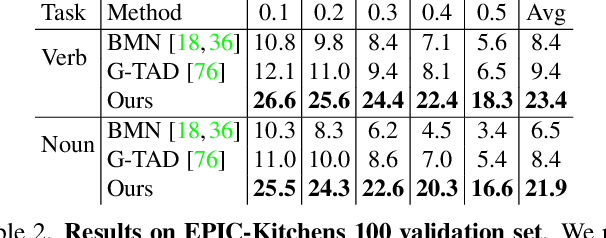
Self-attention based Transformer models have demonstrated impressive results for image classification and object detection, and more recently for video understanding. Inspired by this success, we investigate the application of Transformer networks for temporal action localization in videos. To this end, we present ActionFormer -- a simple yet powerful model to identify actions in time and recognize their categories in a single shot, without using action proposals or relying on pre-defined anchor windows. ActionFormer combines a multiscale feature representation with local self-attention, and uses a light-weighted decoder to classify every moment in time and estimate the corresponding action boundaries. We show that this orchestrated design results in major improvements upon prior works. Without bells and whistles, ActionFormer achieves 65.6% mAP at tIoU=0.5 on THUMOS14, outperforming the best prior model by 8.7 absolute percentage points and crossing the 60% mAP for the first time. Further, ActionFormer demonstrates strong results on ActivityNet 1.3 (36.0% average mAP) and the more recent EPIC-Kitchens 100 (+13.5% average mAP over prior works). Our code is available at http://github.com/happyharrycn/actionformer_release
Neural Galerkin Scheme with Active Learning for High-Dimensional Evolution Equations
Mar 02, 2022


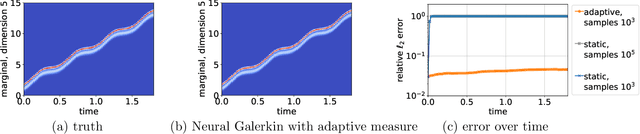
Machine learning methods have been shown to give accurate predictions in high dimensions provided that sufficient training data are available. Yet, many interesting questions in science and engineering involve situations where initially no data are available and the principal aim is to gather insights from a known model. Here we consider this problem in the context of systems whose evolution can be described by partial differential equations (PDEs). We use deep learning to solve these equations by generating data on-the-fly when and where they are needed, without prior information about the solution. The proposed Neural Galerkin schemes derive nonlinear dynamical equations for the network weights by minimization of the residual of the time derivative of the solution, and solve these equations using standard integrators for initial value problems. The sequential learning of the weights over time allows for adaptive collection of new input data for residual estimation. This step uses importance sampling informed by the current state of the solution, in contrast with other machine learning methods for PDEs that optimize the network parameters globally in time. This active form of data acquisition is essential to enable the approximation power of the neural networks and to break the curse of dimensionality faced by non-adaptative learning strategies. The applicability of the method is illustrated on several numerical examples involving high-dimensional PDEs, including advection equations with many variables, as well as Fokker-Planck equations for systems with several interacting particles.
Wavelet-based clustering for time-series trend detection
Nov 17, 2020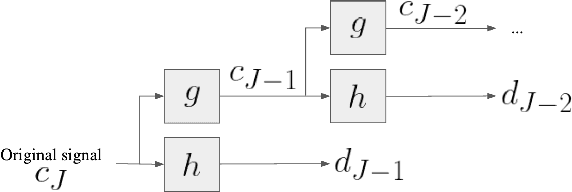
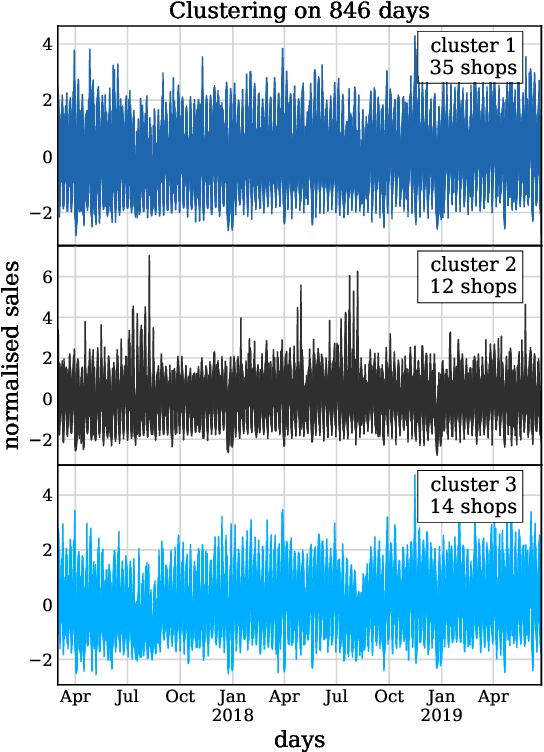
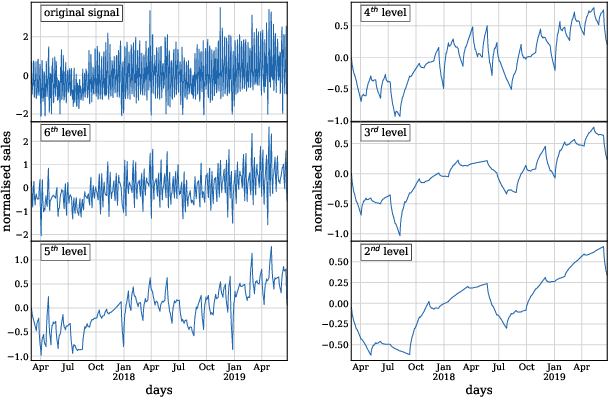
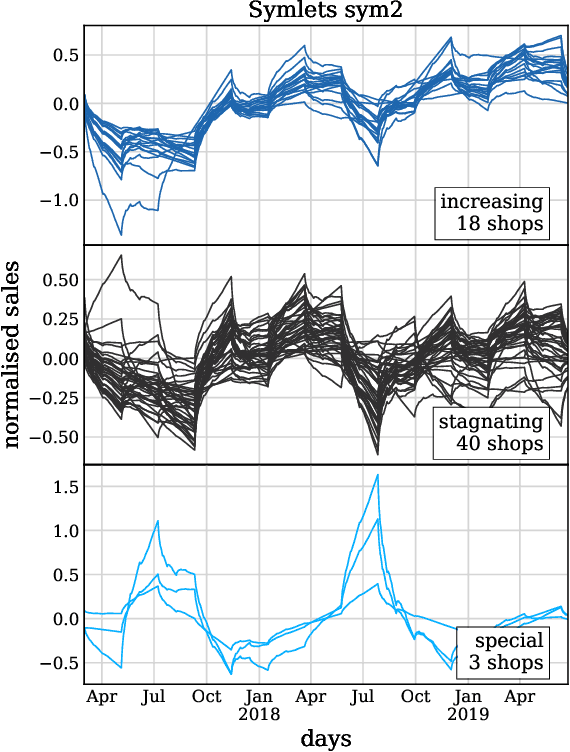
In this paper, we introduce a method performing clustering of time-series on the basis of their trend (increasing, stagnating/decreasing, and seasonal behavior). The clustering is performed using $k$-means method on a selection of coefficients obtained by discrete wavelet transform, reducing drastically the dimensionality. The method is applied on an use case for the clustering of a 864 daily sales revenue time-series for 61 retail shops. The results are presented for different mother wavelets. The importance of each wavelet coefficient and its level is discussed thanks to a principal component analysis along with a reconstruction of the signal from the selected wavelet coefficients.
Photorealistic Monocular 3D Reconstruction of Humans Wearing Clothing
Apr 19, 2022
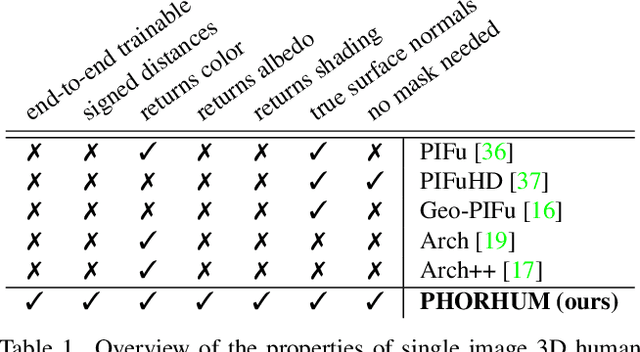
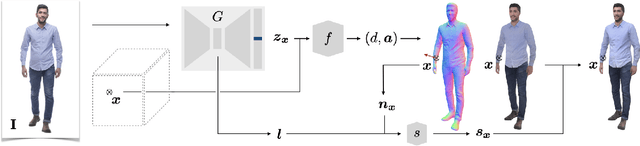
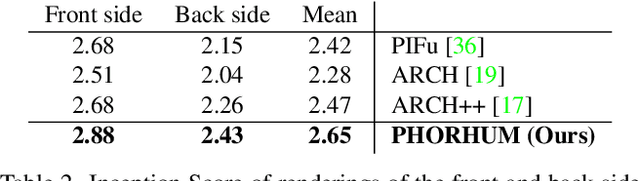
We present PHORHUM, a novel, end-to-end trainable, deep neural network methodology for photorealistic 3D human reconstruction given just a monocular RGB image. Our pixel-aligned method estimates detailed 3D geometry and, for the first time, the unshaded surface color together with the scene illumination. Observing that 3D supervision alone is not sufficient for high fidelity color reconstruction, we introduce patch-based rendering losses that enable reliable color reconstruction on visible parts of the human, and detailed and plausible color estimation for the non-visible parts. Moreover, our method specifically addresses methodological and practical limitations of prior work in terms of representing geometry, albedo, and illumination effects, in an end-to-end model where factors can be effectively disentangled. In extensive experiments, we demonstrate the versatility and robustness of our approach. Our state-of-the-art results validate the method qualitatively and for different metrics, for both geometric and color reconstruction.
Pre-trained Language Models as Re-Annotators
May 11, 2022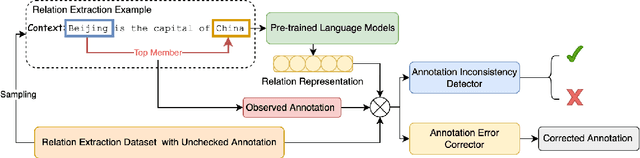

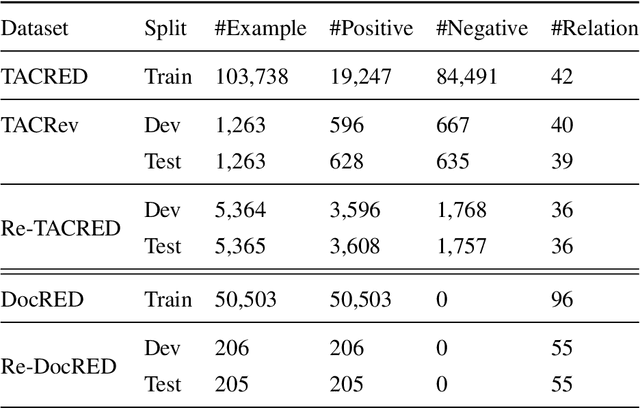
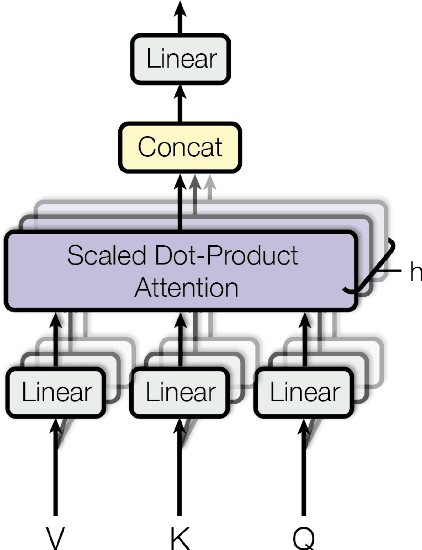
Annotation noise is widespread in datasets, but manually revising a flawed corpus is time-consuming and error-prone. Hence, given the prior knowledge in Pre-trained Language Models and the expected uniformity across all annotations, we attempt to reduce annotation noise in the corpus through two tasks automatically: (1) Annotation Inconsistency Detection that indicates the credibility of annotations, and (2) Annotation Error Correction that rectifies the abnormal annotations. We investigate how to acquire semantic sensitive annotation representations from Pre-trained Language Models, expecting to embed the examples with identical annotations to the mutually adjacent positions even without fine-tuning. We proposed a novel credibility score to reveal the likelihood of annotation inconsistencies based on the neighbouring consistency. Then, we fine-tune the Pre-trained Language Models based classifier with cross-validation for annotation correction. The annotation corrector is further elaborated with two approaches: (1) soft labelling by Kernel Density Estimation and (2) a novel distant-peer contrastive loss. We study the re-annotation in relation extraction and create a new manually revised dataset, Re-DocRED, for evaluating document-level re-annotation. The proposed credibility scores show promising agreement with human revisions, achieving a Binary F1 of 93.4 and 72.5 in detecting inconsistencies on TACRED and DocRED respectively. Moreover, the neighbour-aware classifiers based on distant-peer contrastive learning and uncertain labels achieve Macro F1 up to 66.2 and 57.8 in correcting annotations on TACRED and DocRED respectively. These improvements are not merely theoretical: Rather, automatically denoised training sets demonstrate up to 3.6% performance improvement for state-of-the-art relation extraction models.
End-to-End Human-Gaze-Target Detection with Transformers
Mar 24, 2022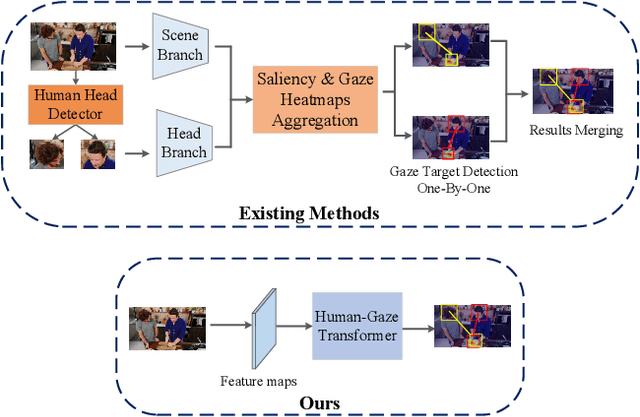
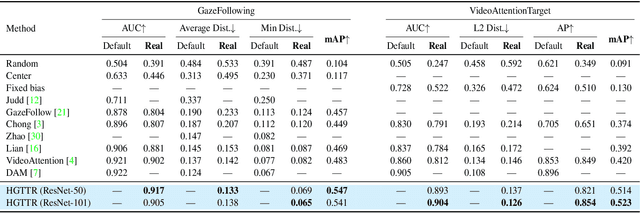
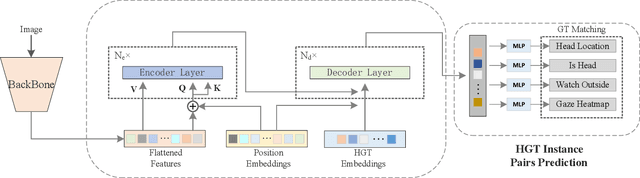
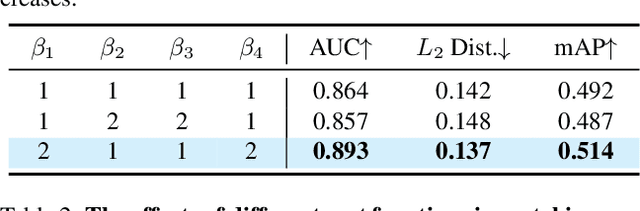
In this paper, we propose an effective and efficient method for Human-Gaze-Target (HGT) detection, i.e., gaze following. Current approaches decouple the HGT detection task into separate branches of salient object detection and human gaze prediction, employing a two-stage framework where human head locations must first be detected and then be fed into the next gaze target prediction sub-network. In contrast, we redefine the HGT detection task as detecting human head locations and their gaze targets, simultaneously. By this way, our method, named Human-Gaze-Target detection TRansformer or HGTTR, streamlines the HGT detection pipeline by eliminating all other additional components. HGTTR reasons about the relations of salient objects and human gaze from the global image context. Moreover, unlike existing two-stage methods that require human head locations as input and can predict only one human's gaze target at a time, HGTTR can directly predict the locations of all people and their gaze targets at one time in an end-to-end manner. The effectiveness and robustness of our proposed method are verified with extensive experiments on the two standard benchmark datasets, GazeFollowing and VideoAttentionTarget. Without bells and whistles, HGTTR outperforms existing state-of-the-art methods by large margins (6.4 mAP gain on GazeFollowing and 10.3 mAP gain on VideoAttentionTarget) with a much simpler architecture.