 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Cognitive Evaluation of Online Learners through Automatically Generated Questions
Jun 06, 2021
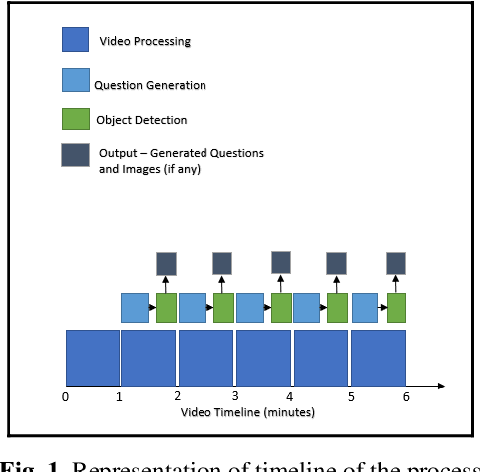
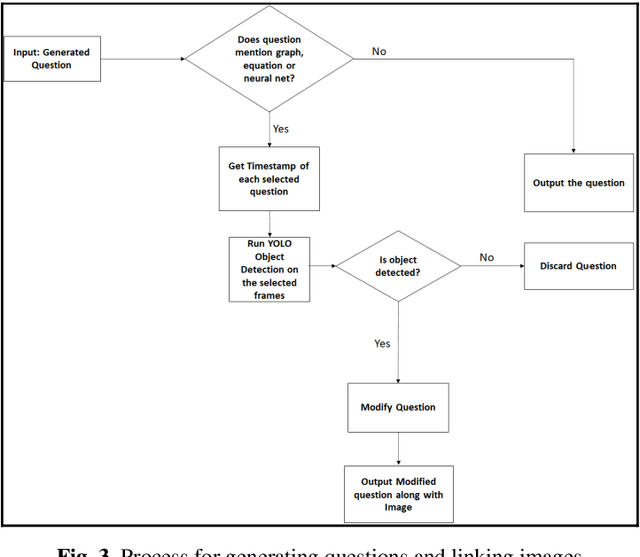

With the increased adoption of E-learning platforms, keeping online learners engaged throughout a lesson is challenging. One approach to tackle this challenge is to probe learn-ers periodically by asking questions. The paper presents an approach to generate questions from a given video lecture automatically. The generated questions are aimed to evaluate learners' lower-level cognitive abilities. The approach automatically extracts text from video lectures to generates wh-kinds of questions. When learners respond with an answer, the proposed approach further evaluates the response and provides feedback. Besides enhancing learner's engagement, this approach's main benefits are that it frees instructors from design-ing questions to check the comprehension of a topic. Thus, instructors can spend this time productively on other activities.
WebFace260M: A Benchmark for Million-Scale Deep Face Recognition
Apr 21, 2022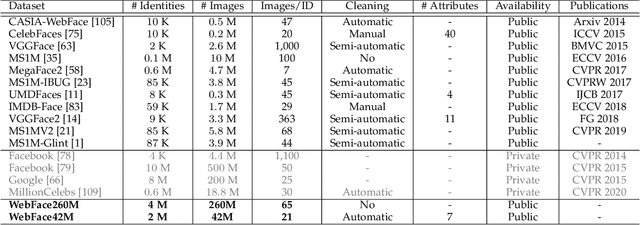

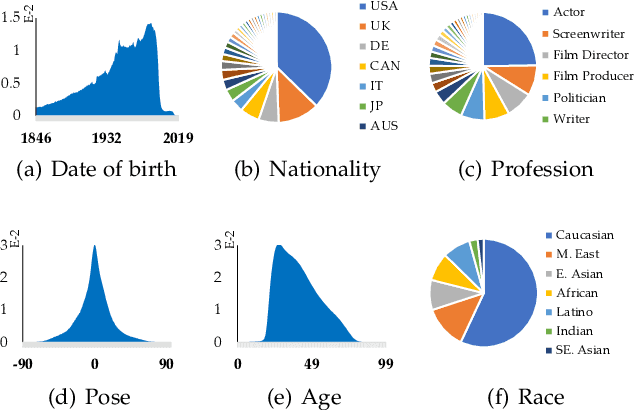
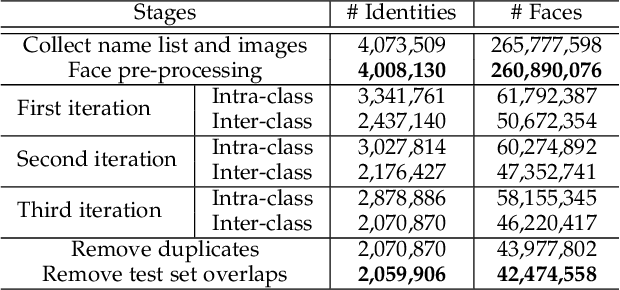
Face benchmarks empower the research community to train and evaluate high-performance face recognition systems. In this paper, we contribute a new million-scale recognition benchmark, containing uncurated 4M identities/260M faces (WebFace260M) and cleaned 2M identities/42M faces (WebFace42M) training data, as well as an elaborately designed time-constrained evaluation protocol. Firstly, we collect 4M name lists and download 260M faces from the Internet. Then, a Cleaning Automatically utilizing Self-Training (CAST) pipeline is devised to purify the tremendous WebFace260M, which is efficient and scalable. To the best of our knowledge, the cleaned WebFace42M is the largest public face recognition training set and we expect to close the data gap between academia and industry. Referring to practical deployments, Face Recognition Under Inference Time conStraint (FRUITS) protocol and a new test set with rich attributes are constructed. Besides, we gather a large-scale masked face sub-set for biometrics assessment under COVID-19. For a comprehensive evaluation of face matchers, three recognition tasks are performed under standard, masked and unbiased settings, respectively. Equipped with this benchmark, we delve into million-scale face recognition problems. A distributed framework is developed to train face recognition models efficiently without tampering with the performance. Enabled by WebFace42M, we reduce 40% failure rate on the challenging IJB-C set and rank 3rd among 430 entries on NIST-FRVT. Even 10% data (WebFace4M) shows superior performance compared with the public training sets. Furthermore, comprehensive baselines are established under the FRUITS-100/500/1000 milliseconds protocols. The proposed benchmark shows enormous potential on standard, masked and unbiased face recognition scenarios. Our WebFace260M website is https://www.face-benchmark.org.
Explain to Not Forget: Defending Against Catastrophic Forgetting with XAI
May 11, 2022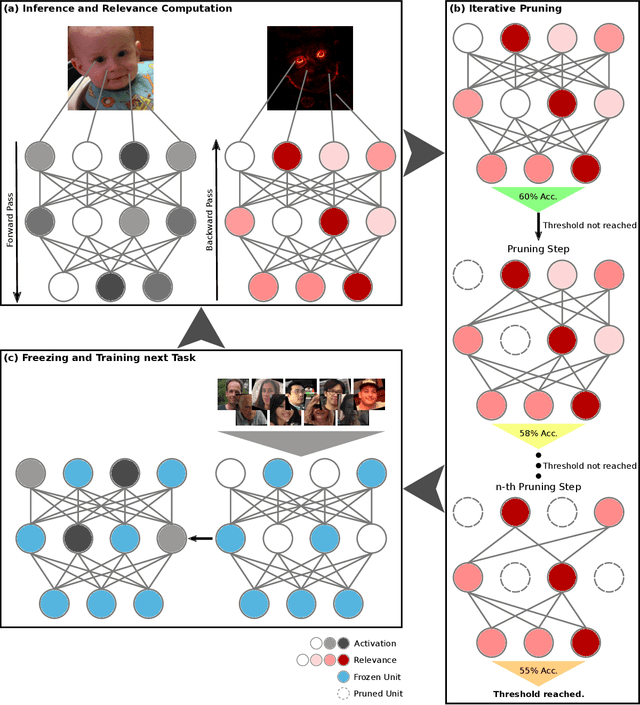
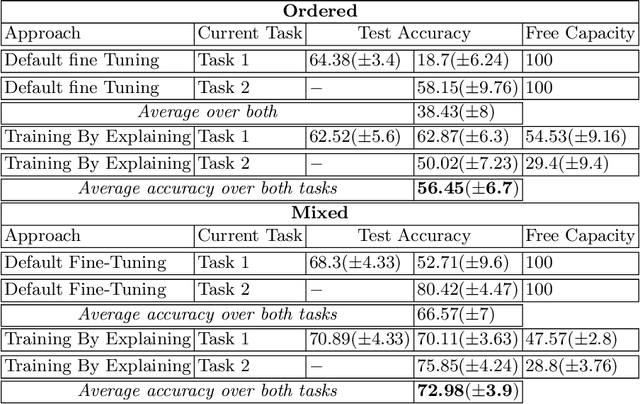
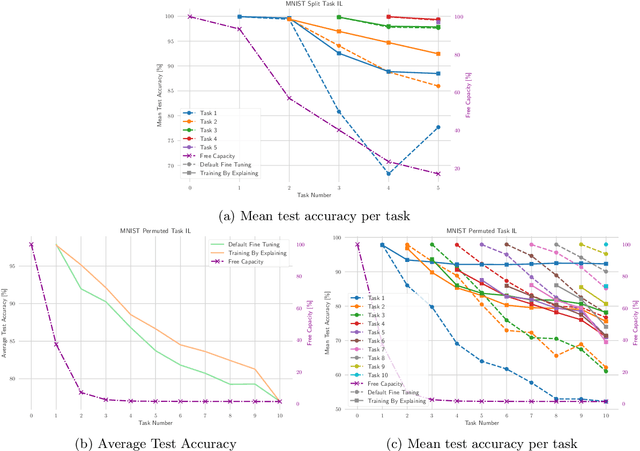
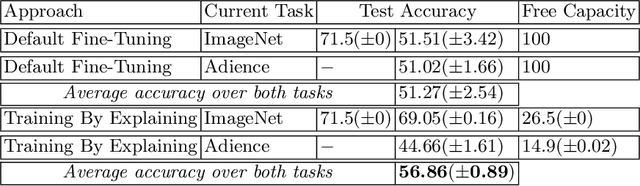
The ability to continuously process and retain new information like we do naturally as humans is a feat that is highly sought after when training neural networks. Unfortunately, the traditional optimization algorithms often require large amounts of data available during training time and updates wrt. new data are difficult after the training process has been completed. In fact, when new data or tasks arise, previous progress may be lost as neural networks are prone to catastrophic forgetting. Catastrophic forgetting describes the phenomenon when a neural network completely forgets previous knowledge when given new information. We propose a novel training algorithm called training by explaining in which we leverage Layer-wise Relevance Propagation in order to retain the information a neural network has already learned in previous tasks when training on new data. The method is evaluated on a range of benchmark datasets as well as more complex data. Our method not only successfully retains the knowledge of old tasks within the neural networks but does so more resource-efficiently than other state-of-the-art solutions.
Gradient flows and randomised thresholding: sparse inversion and classification
Mar 22, 2022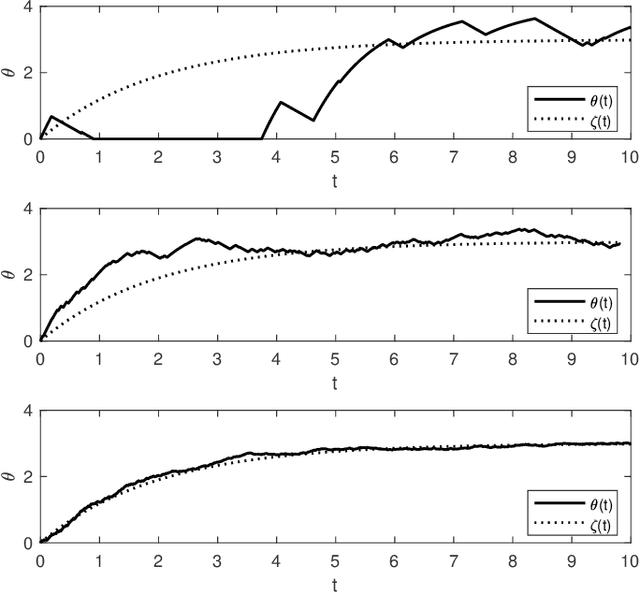
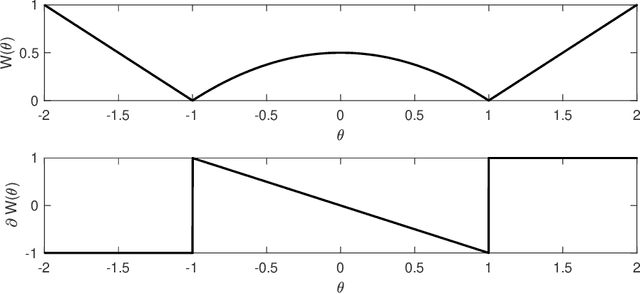

Sparse inversion and classification problems are ubiquitous in modern data science and imaging. They are often formulated as non-smooth minimisation problems. In sparse inversion, we minimise, e.g., the sum of a data fidelity term and an L1/LASSO regulariser. In classification, we consider, e.g., the sum of a data fidelity term and a non-smooth Ginzburg--Landau energy. Standard (sub)gradient descent methods have shown to be inefficient when approaching such problems. Splitting techniques are much more useful: here, the target function is partitioned into a sum of two subtarget functions -- each of which can be efficiently optimised. Splitting proceeds by performing optimisation steps alternately with respect to each of the two subtarget functions. In this work, we study splitting from a stochastic continuous-time perspective. Indeed, we define a differential inclusion that follows one of the two subtarget function's negative subgradient at each point in time. The choice of the subtarget function is controlled by a binary continuous-time Markov process. The resulting dynamical system is a stochastic approximation of the underlying subgradient flow. We investigate this stochastic approximation for an L1-regularised sparse inversion flow and for a discrete Allen-Cahn equation minimising a Ginzburg--Landau energy. In both cases, we study the longtime behaviour of the stochastic dynamical system and its ability to approximate the underlying subgradient flow at any accuracy. We illustrate our theoretical findings in a simple sparse estimation problem and also in a low-dimensional classification problem.
Unified Chinese License Plate Detection and Recognition with High Efficiency
May 07, 2022

Recently, deep learning-based methods have reached an excellent performance on License Plate (LP) detection and recognition tasks. However, it is still challenging to build a robust model for Chinese LPs since there are not enough large and representative datasets. In this work, we propose a new dataset named Chinese Road Plate Dataset (CRPD) that contains multi-objective Chinese LP images as a supplement to the existing public benchmarks. The images are mainly captured with electronic monitoring systems with detailed annotations. To our knowledge, CRPD is the largest public multi-objective Chinese LP dataset with annotations of vertices. With CRPD, a unified detection and recognition network with high efficiency is presented as the baseline. The network is end-to-end trainable with totally real-time inference efficiency (30 fps with 640p). The experiments on several public benchmarks demonstrate that our method has reached competitive performance. The code and dataset will be publicly available at https://github.com/yxgong0/CRPD.
Optimizing UAV Recharge Scheduling for Heterogeneous and Persistent Aerial Service
May 25, 2022
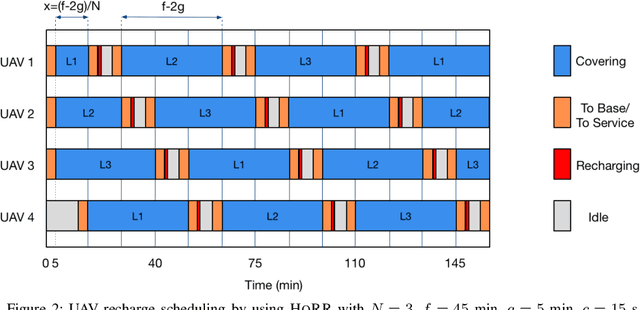
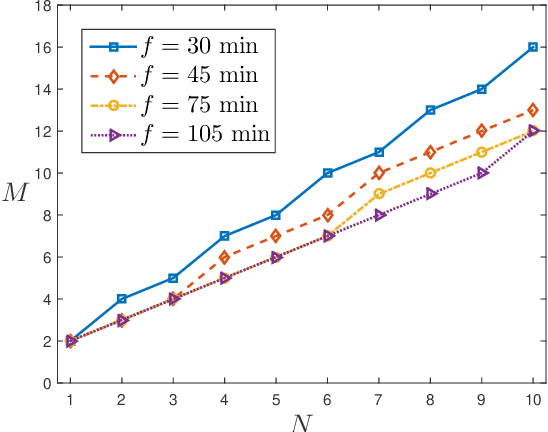
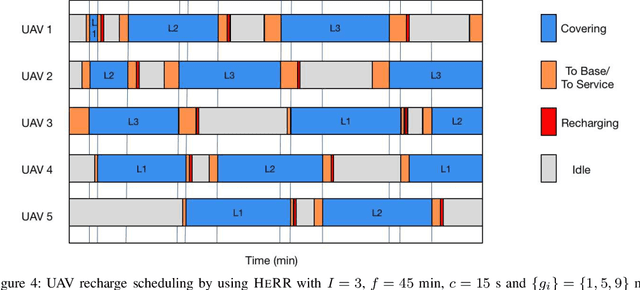
The adoption of UAVs in communication networks is becoming reality thanks to the deployment of advanced solutions for connecting UAVs and using them as communication relays. However, the use of UAVs introduces novel energy constraints and scheduling challenges in the dynamic management of network devices, due to the need to call back and recharge, or substitute, UAVs that run out of energy. In this paper, we design UAV recharging schemes under realistic assumptions on limited flight times and time consuming charging operations. Such schemes are designed to minimize the size of the fleet to be devoted to a persistent service of a set of aerial locations, hence its cost. We consider a fleet of homogeneous UAVs both under homogeneous and heterogeneous service topologies. For UAVs serving aerial locations with homogeneous distances to a recharge station, we design a simple scheduling, that we name HORR, which we prove to be feasible and optimal, in the sense that it uses the minimum possible number of UAVs to guarantee the coverage of the aerial service locations. For the case of non-evenly distributed aerial locations, we demonstrate that the problem becomes NP-hard, and design a lightweight recharging scheduling scheme, PHERR, that extends the operation of HORR to the heterogeneous case, leveraging the partitioning of the set of service locations. We show that PHERR is near-optimal because it approaches the performance limits identified through a lower bound that we formulate on the total fleet size.
Interpretable Machine Learning Models for Modal Split Prediction in Transportation Systems
Mar 27, 2022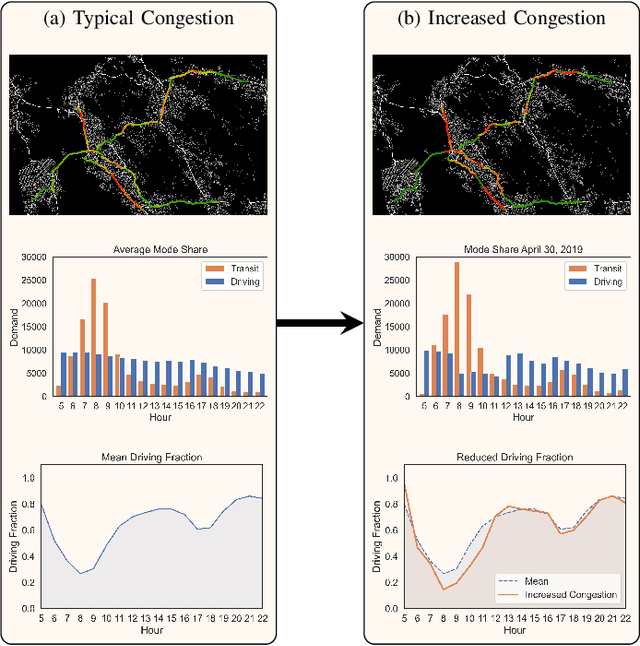
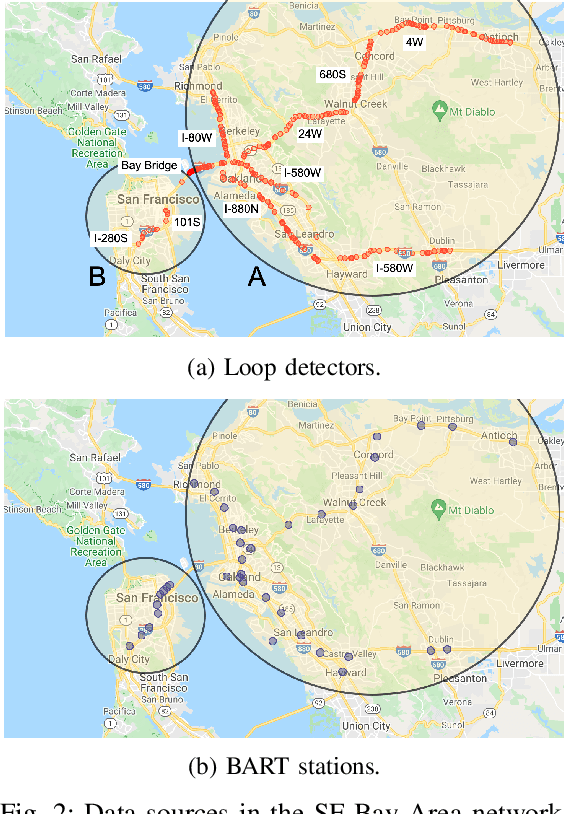
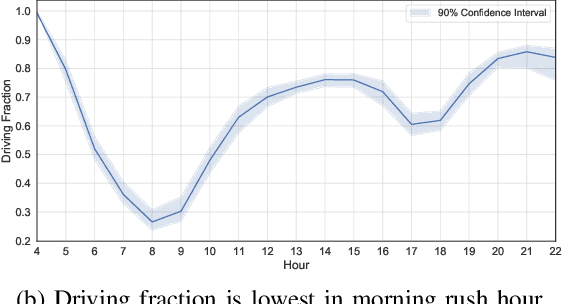
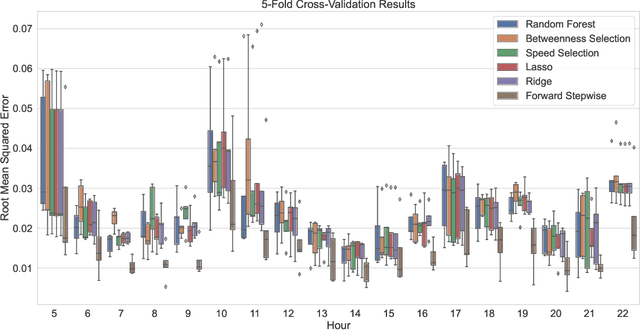
Modal split prediction in transportation networks has the potential to support network operators in managing traffic congestion and improving transit service reliability. We focus on the problem of hourly prediction of the fraction of travelers choosing one mode of transportation over another using high-dimensional travel time data. We use logistic regression as base model and employ various regularization techniques for variable selection to prevent overfitting and resolve multicollinearity issues. Importantly, we interpret the prediction accuracy results with respect to the inherent variability of modal splits and travelers' aggregate responsiveness to changes in travel time. By visualizing model parameters, we conclude that the subset of segments found important for predictive accuracy changes from hour-to-hour and include segments that are topologically central and/or highly congested. We apply our approach to the San Francisco Bay Area freeway and rapid transit network and demonstrate superior prediction accuracy and interpretability of our method compared to pre-specified variable selection methods.
Neuro-Symbolic Artificial Intelligence (AI) for Intent based Semantic Communication
May 22, 2022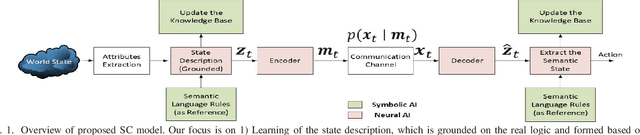
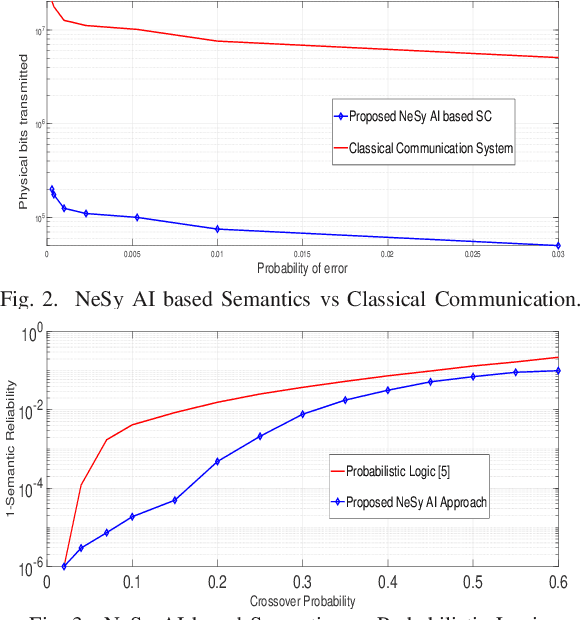
Intent-based networks that integrate sophisticated machine reasoning technologies will be a cornerstone of future wireless 6G systems. Intent-based communication requires the network to consider the semantics (meanings) and effectiveness (at end-user) of the data transmission. This is essential if 6G systems are to communicate reliably with fewer bits while simultaneously providing connectivity to heterogeneous users. In this paper, contrary to state of the art, which lacks explainability of data, the framework of neuro-symbolic artificial intelligence (NeSy AI) is proposed as a pillar for learning causal structure behind the observed data. In particular, the emerging concept of generative flow networks (GFlowNet) is leveraged for the first time in a wireless system to learn the probabilistic structure which generates the data. Further, a novel optimization problem for learning the optimal encoding and decoding functions is rigorously formulated with the intent of achieving higher semantic reliability. Novel analytical formulations are developed to define key metrics for semantic message transmission, including semantic distortion, semantic similarity, and semantic reliability. These semantic measure functions rely on the proposed definition of semantic content of the knowledge base and this information measure is reflective of the nodes' reasoning capabilities. Simulation results validate the ability to communicate efficiently (with less bits but same semantics) and significantly better compared to a conventional system which does not exploit the reasoning capabilities.
Constraint-Based Causal Structure Learning from Undersampled Graphs
May 18, 2022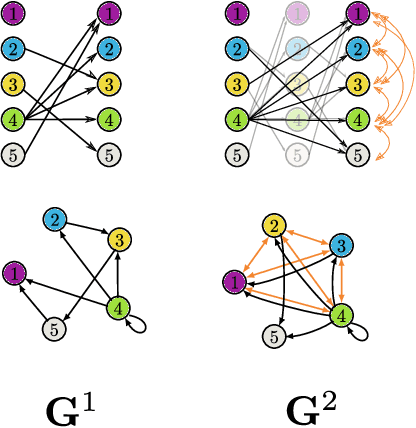
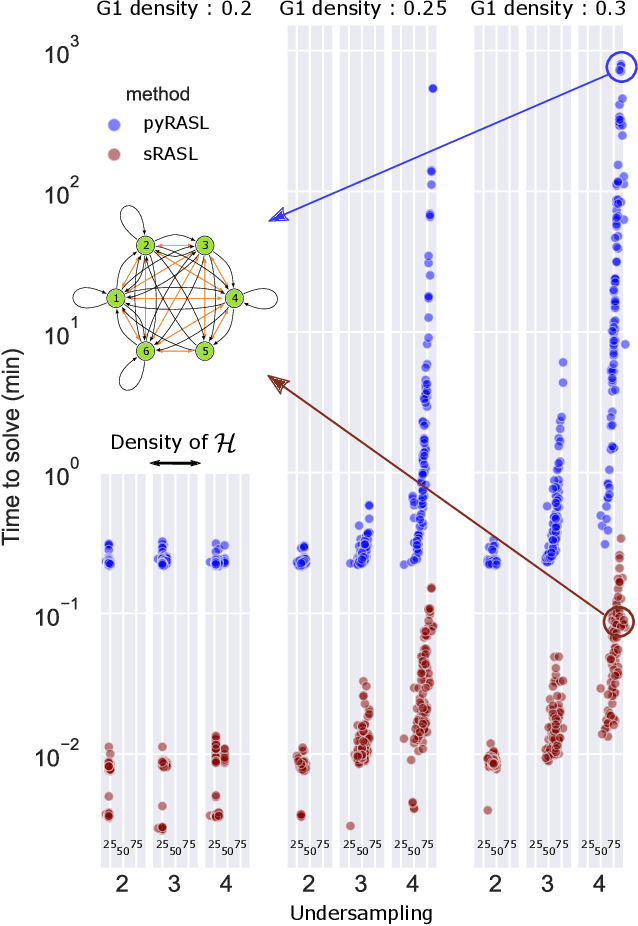
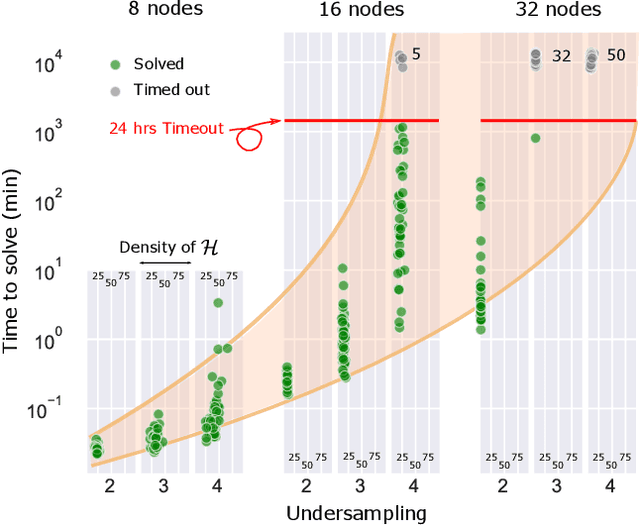
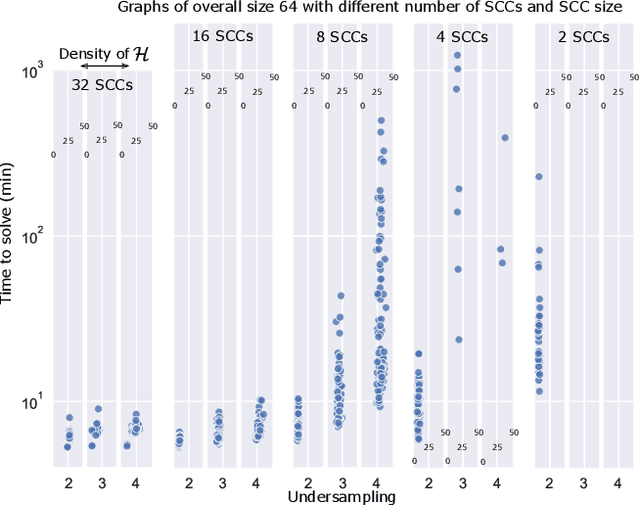
Graphical structures estimated by causal learning algorithms from time series data can provide highly misleading causal information if the causal timescale of the generating process fails to match the measurement timescale of the data. Although this problem has been recently recognized, practitioners have limited resources to respond to it, and so must continue using models that they know are likely misleading. Existing methods either (a) require that the difference between causal and measurement timescales is known; or (b) can handle only very small number of random variables when the timescale difference is unknown; or (c) apply to only pairs of variables, though with fewer assumptions about prior knowledge; or (d) return impractically too many solutions. This paper addresses all four challenges. We combine constraint programming with both theoretical insights into the problem structure and prior information about admissible causal interactions. The resulting system provides a practical approach that scales to significantly larger sets (>100) of random variables, does not require precise knowledge of the timescale difference, supports edge misidentification and parametric connection strengths, and can provide the optimum choice among many possible solutions. The cumulative impact of these improvements is gain of multiple orders of magnitude in speed and informativeness.
An Online Semantic Mapping System for Extending and Enhancing Visual SLAM
Mar 08, 2022



We present a real-time semantic mapping approach for mobile vision systems with a 2D to 3D object detection pipeline and rapid data association for generated landmarks. Besides the semantic map enrichment the associated detections are further introduced as semantic constraints into a simultaneous localization and mapping (SLAM) system for pose correction purposes. This way, we are able generate additional meaningful information that allows to achieve higher-level tasks, while simultaneously leveraging the view-invariance of object detections to improve the accuracy and the robustness of the odometry estimation. We propose tracklets of locally associated object observations to handle ambiguous and false predictions and an uncertainty-based greedy association scheme for an accelerated processing time. Our system reaches real-time capabilities with an average iteration duration of 65~ms and is able to improve the pose estimation of a state-of-the-art SLAM by up to 68% on a public dataset. Additionally, we implemented our approach as a modular ROS package that makes it straightforward for integration in arbitrary graph-based SLAM methods.