 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Graph Recovery in Neuroimaging through Answer Set Programming
Jun 10, 2025Learning graphical causal structures from time series data presents significant challenges, especially when the measurement frequency does not match the causal timescale of the system. This often leads to a set of equally possible underlying causal graphs due to information loss from sub-sampling (i.e., not observing all possible states of the system throughout time). Our research addresses this challenge by incorporating the effects of sub-sampling in the derivation of causal graphs, resulting in more accurate and intuitive outcomes. We use a constraint optimization approach, specifically answer set programming (ASP), to find the optimal set of answers. ASP not only identifies the most probable underlying graph, but also provides an equivalence class of possible graphs for expert selection. In addition, using ASP allows us to leverage graph theory to further prune the set of possible solutions, yielding a smaller, more accurate answer set significantly faster than traditional approaches. We validate our approach on both simulated data and empirical structural brain connectivity, and demonstrate its superiority over established methods in these experiments. We further show how our method can be used as a meta-approach on top of established methods to obtain, on average, 12% improvement in F1 score. In addition, we achieved state of the art results in terms of precision and recall of reconstructing causal graph from sub-sampled time series data. Finally, our method shows robustness to varying degrees of sub-sampling on realistic simulations, whereas other methods perform worse for higher rates of sub-sampling.
ION-C: Integration of Overlapping Networks via Constraints
Nov 06, 2024In many causal learning problems, variables of interest are often not all measured over the same observations, but are instead distributed across multiple datasets with overlapping variables. Tillman et al. (2008) presented the first algorithm for enumerating the minimal equivalence class of ground-truth DAGs consistent with all input graphs by exploiting local independence relations, called ION. In this paper, this problem is formulated as a more computationally efficient answer set programming (ASP) problem, which we call ION-C, and solved with the ASP system clingo. The ION-C algorithm was run on random synthetic graphs with varying sizes, densities, and degrees of overlap between subgraphs, with overlap having the largest impact on runtime, number of solution graphs, and agreement within the output set. To validate ION-C on real-world data, we ran the algorithm on overlapping graphs learned from data from two successive iterations of the European Social Survey (ESS), using a procedure for conducting joint independence tests to prevent inconsistencies in the input.
Constraint-Based Causal Structure Learning from Undersampled Graphs
May 18, 2022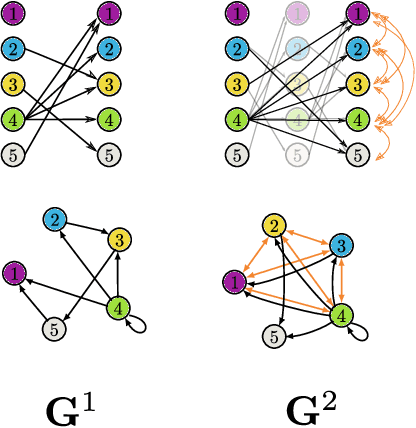
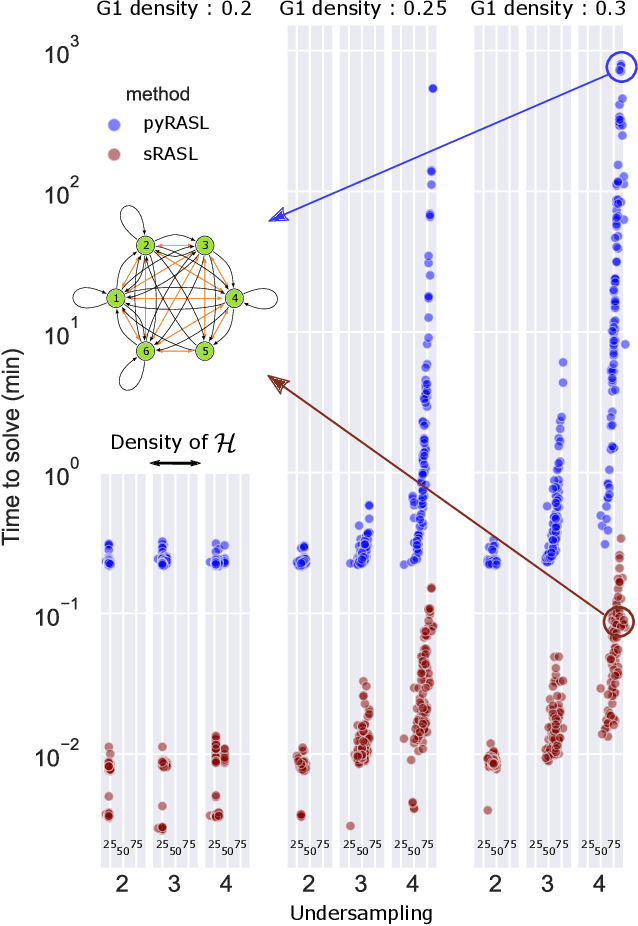
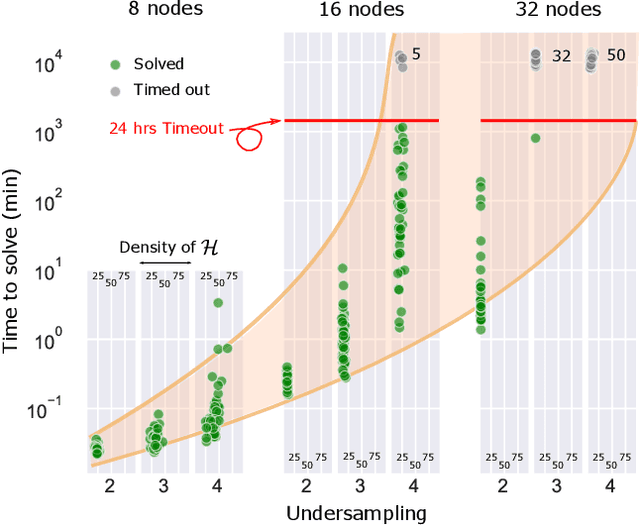
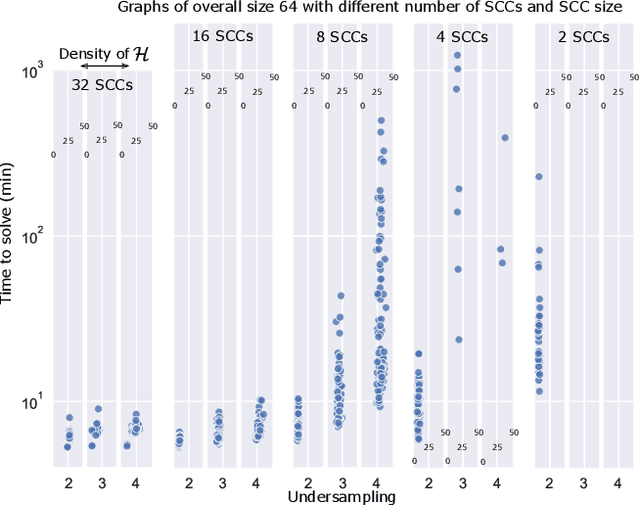
Graphical structures estimated by causal learning algorithms from time series data can provide highly misleading causal information if the causal timescale of the generating process fails to match the measurement timescale of the data. Although this problem has been recently recognized, practitioners have limited resources to respond to it, and so must continue using models that they know are likely misleading. Existing methods either (a) require that the difference between causal and measurement timescales is known; or (b) can handle only very small number of random variables when the timescale difference is unknown; or (c) apply to only pairs of variables, though with fewer assumptions about prior knowledge; or (d) return impractically too many solutions. This paper addresses all four challenges. We combine constraint programming with both theoretical insights into the problem structure and prior information about admissible causal interactions. The resulting system provides a practical approach that scales to significantly larger sets (>100) of random variables, does not require precise knowledge of the timescale difference, supports edge misidentification and parametric connection strengths, and can provide the optimum choice among many possible solutions. The cumulative impact of these improvements is gain of multiple orders of magnitude in speed and informativeness.
Radiologist-Level COVID-19 Detection Using CT Scans with Detail-Oriented Capsule Networks
Apr 16, 2020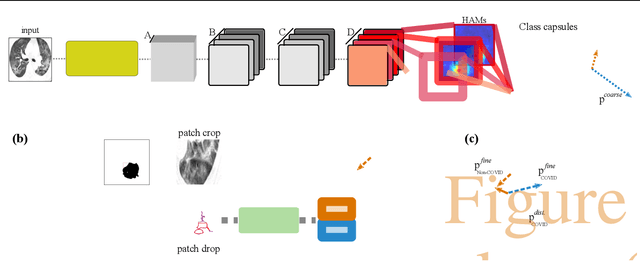

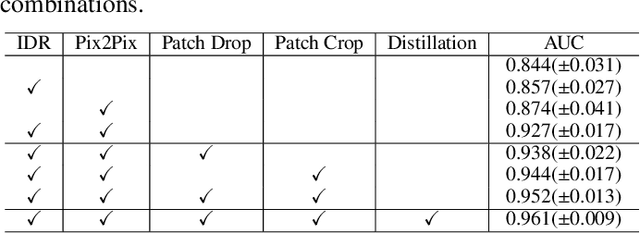
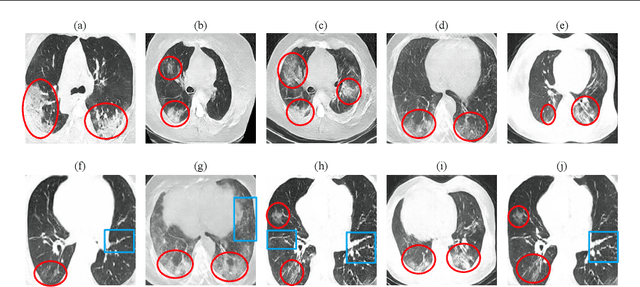
Radiographic images offer an alternative method for the rapid screening and monitoring of Coronavirus Disease 2019 (COVID-19) patients. This approach is limited by the shortage of radiology experts who can provide a timely interpretation of these images. Motivated by this challenge, our paper proposes a novel learning architecture, called Detail-Oriented Capsule Networks (DECAPS), for the automatic diagnosis of COVID-19 from Computed Tomography (CT) scans. Our network combines the strength of Capsule Networks with several architecture improvements meant to boost classification accuracies. First, DECAPS uses an Inverted Dynamic Routing mechanism which increases model stability by preventing the passage of information from non-descriptive regions. Second, DECAPS employs a Peekaboo training procedure which uses a two-stage patch crop and drop strategy to encourage the network to generate activation maps for every target concept. The network then uses the activation maps to focus on regions of interest and combines both coarse and fine-grained representations of the data. Finally, we use a data augmentation method based on conditional generative adversarial networks to deal with the issue of data scarcity. Our model achieves 84.3% precision, 91.5% recall, and 96.1% area under the ROC curve, significantly outperforming state-of-the-art methods. We compare the performance of the DECAPS model with three experienced, well-trained thoracic radiologists and show that the architecture significantly outperforms them. While further studies on larger datasets are required to confirm this finding, our results imply that architectures like DECAPS can be used to assist radiologists in the CT scan mediated diagnosis of COVID-19.
Greedy AutoAugment
Aug 02, 2019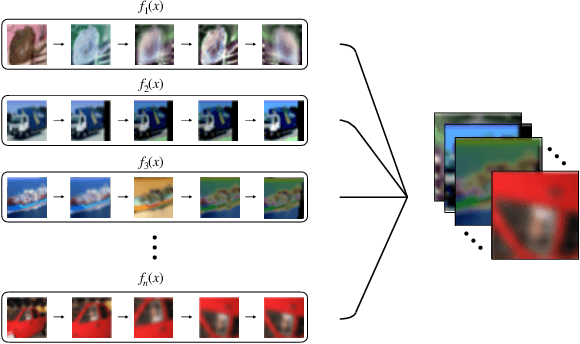

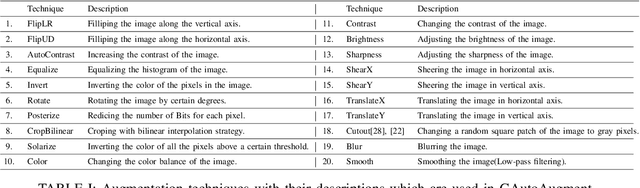
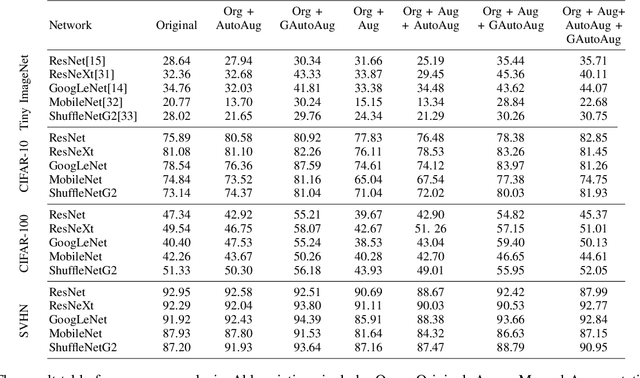
A major problem in data augmentation is the number of possibilities in the search space of operations. The search space includes mixtures of all of the possible data augmentation techniques, the magnitude of these operations, and the probability of applying data augmentation for each image. In this paper, we propose Greedy AutoAugment as a highly efficient searching algorithm to find the best augmentation policies. We combine the searching process with a simple procedure to increase the size of training data. Our experiments show that the proposed method can be used as a reliable addition to the ANN infrastructures for increasing the accuracy of classification results.