 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Where were my keys? -- Aggregating Spatial-Temporal Instances of Objects for Efficient Retrieval over Long Periods of Time
Oct 25, 2021
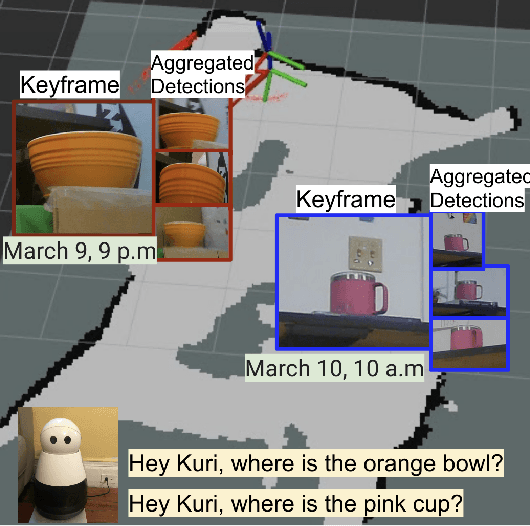

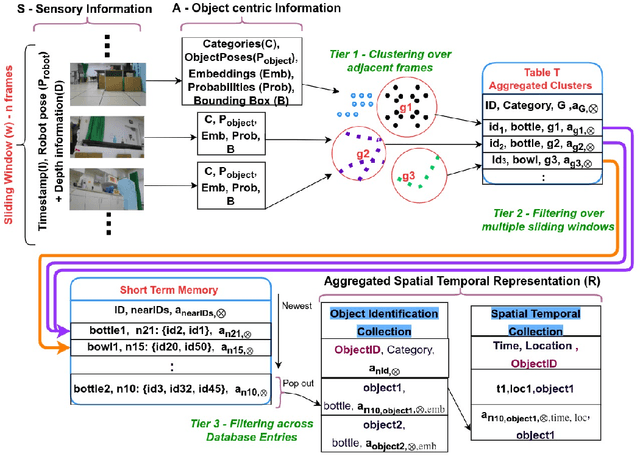
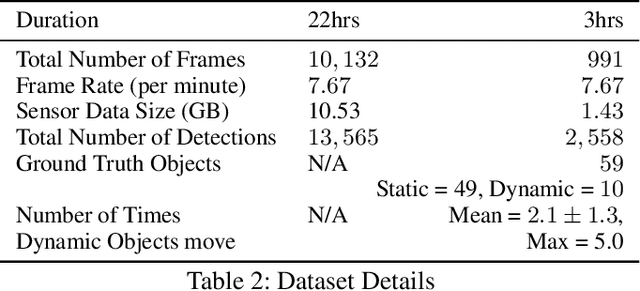
Robots equipped with situational awareness can help humans efficiently find their lost objects by leveraging spatial and temporal structure. Existing approaches to video and image retrieval do not take into account the unique constraints imposed by a moving camera with a partial view of the environment. We present a Detection-based 3-level hierarchical Association approach, D3A, to create an efficient query-able spatial-temporal representation of unique object instances in an environment. D3A performs online incremental and hierarchical learning to identify keyframes that best represent the unique objects in the environment. These keyframes are learned based on both spatial and temporal features and once identified their corresponding spatial-temporal information is organized in a key-value database. D3A allows for a variety of query patterns such as querying for objects with/without the following: 1) specific attributes, 2) spatial relationships with other objects, and 3) time slices. For a given set of 150 queries, D3A returns a small set of candidate keyframes (which occupy only 0.17% of the total sensory data) with 81.98\% mean accuracy in 11.7 ms. This is 47x faster and 33% more accurate than a baseline that naively stores the object matches (detections) in the database without associating spatial-temporal information.
Exploration strategies for articulatory synthesis of complex syllable onsets
Apr 20, 2022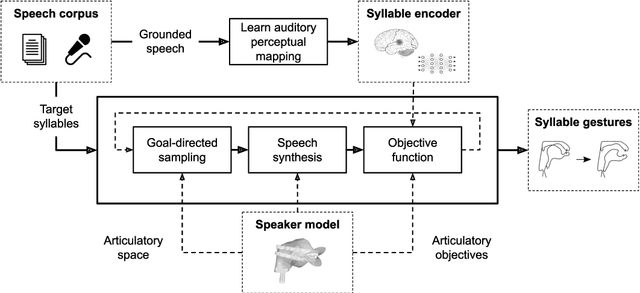

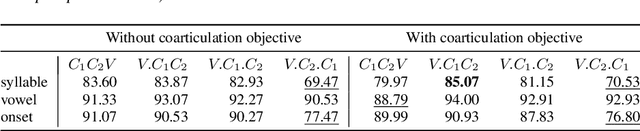
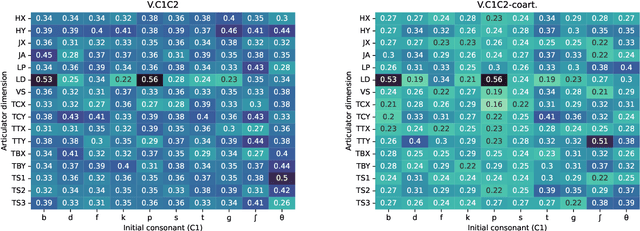
High-quality articulatory speech synthesis has many potential applications in speech science and technology. However, developing appropriate mappings from linguistic specification to articulatory gestures is difficult and time consuming. In this paper we construct an optimisation-based framework as a first step towards learning these mappings without manual intervention. We demonstrate the production of syllables with complex onsets and discuss the quality of the articulatory gestures with reference to coarticulation.
Minimal Explanations for Neural Network Predictions
May 19, 2022

Explaining neural network predictions is known to be a challenging problem. In this paper, we propose a novel approach which can be effectively exploited, either in isolation or in combination with other methods, to enhance the interpretability of neural model predictions. For a given input to a trained neural model, our aim is to compute a smallest set of input features so that the model prediction changes when these features are disregarded by setting them to an uninformative baseline value. While computing such minimal explanations is computationally intractable in general for fully-connected neural networks, we show that the problem becomes solvable in polynomial time by a greedy algorithm under mild assumptions on the network's activation functions. We then show that our tractability result extends seamlessly to more advanced neural architectures such as convolutional and graph neural networks. We conduct experiments to showcase the capability of our method for identifying the input features that are essential to the model's prediction.
Large Neighborhood Search based on Neural Construction Heuristics
May 10, 2022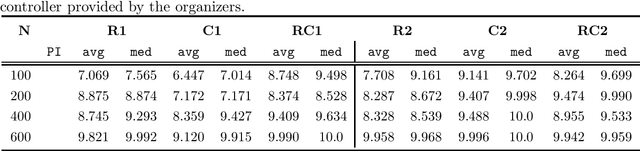
We propose a Large Neighborhood Search (LNS) approach utilizing a learned construction heuristic based on neural networks as repair operator to solve the vehicle routing problem with time windows (VRPTW). Our method uses graph neural networks to encode the problem and auto-regressively decodes a solution and is trained with reinforcement learning on the construction task without requiring any labels for supervision. The neural repair operator is combined with a local search routine, heuristic destruction operators and a selection procedure applied to a small population to arrive at a sophisticated solution approach. The key idea is to use the learned model to re-construct the partially destructed solution and to introduce randomness via the destruction heuristics (or the stochastic policy itself) to effectively explore a large neighborhood.
Real-time Registration and Reconstruction with Cylindrical LiDAR Images
Dec 06, 2021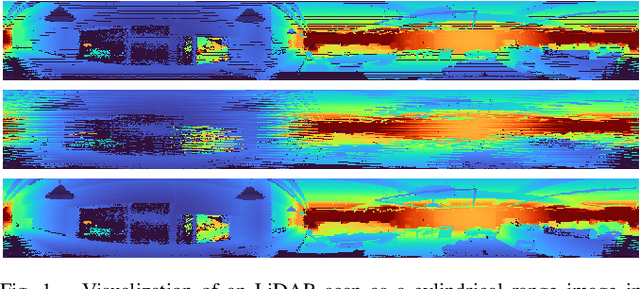

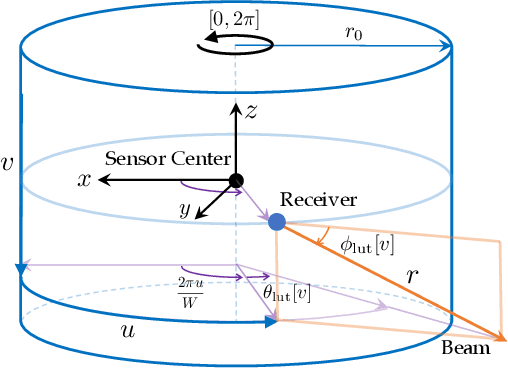

Spinning LiDAR data are prevalent for 3D perception tasks, yet its cylindrical image form is less studied. Conventional approaches regard scans as point clouds, and they either rely on expensive Euclidean 3D nearest neighbor search for data association or depend on projected range images for further processing. We revisit the LiDAR scan formation and present a cylindrical range image representation for data from raw scans, equipped with an efficient calibrated spherical projective model. With our formulation, we 1) collect a large dataset of LiDAR data consisting of both indoor and outdoor sequences accompanied with pseudo-ground truth poses; 2) evaluate the projective and conventional registration approaches on the sequences with both synthetic and real-world transformations; 3) transfer state-of-the-art RGB-D algorithms to LiDAR that runs up to 180 Hz for registration and 150 Hz for dense reconstruction. The dataset and tools will be released.
Effects of Auxiliary Knowledge on Continual Learning
Jun 03, 2022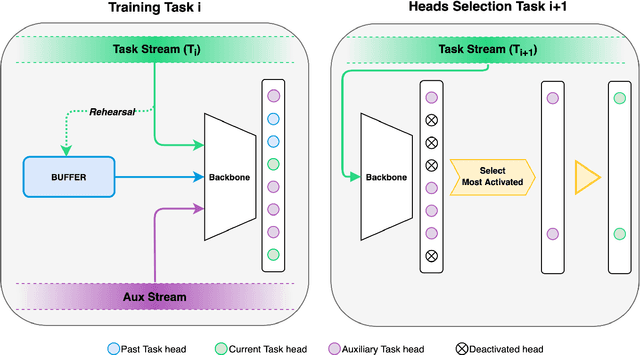
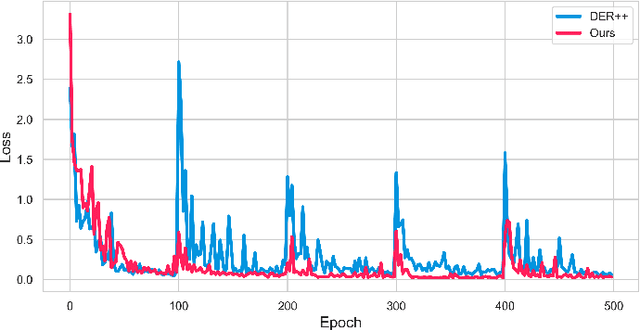
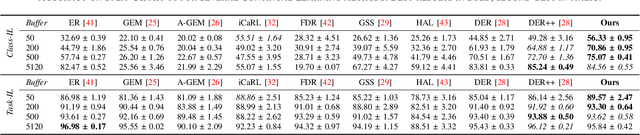
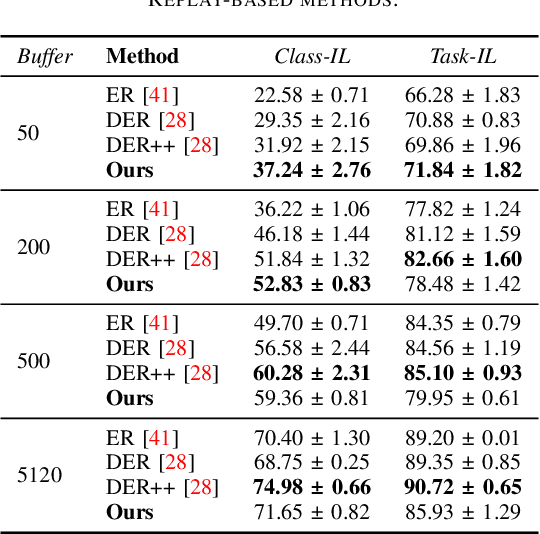
In Continual Learning (CL), a neural network is trained on a stream of data whose distribution changes over time. In this context, the main problem is how to learn new information without forgetting old knowledge (i.e., Catastrophic Forgetting). Most existing CL approaches focus on finding solutions to preserve acquired knowledge, so working on the past of the model. However, we argue that as the model has to continually learn new tasks, it is also important to put focus on the present knowledge that could improve following tasks learning. In this paper we propose a new, simple, CL algorithm that focuses on solving the current task in a way that might facilitate the learning of the next ones. More specifically, our approach combines the main data stream with a secondary, diverse and uncorrelated stream, from which the network can draw auxiliary knowledge. This helps the model from different perspectives, since auxiliary data may contain useful features for the current and the next tasks and incoming task classes can be mapped onto auxiliary classes. Furthermore, the addition of data to the current task is implicitly making the classifier more robust as we are forcing the extraction of more discriminative features. Our method can outperform existing state-of-the-art models on the most common CL Image Classification benchmarks.
HiVLP: Hierarchical Vision-Language Pre-Training for Fast Image-Text Retrieval
May 31, 2022
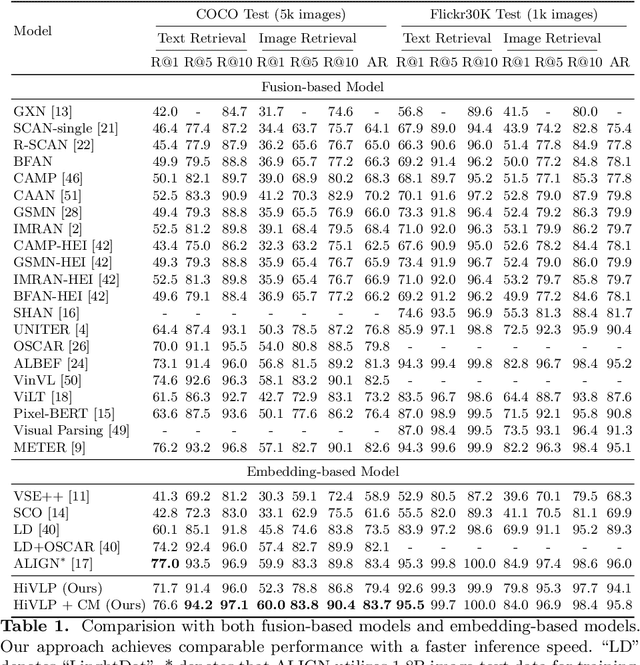
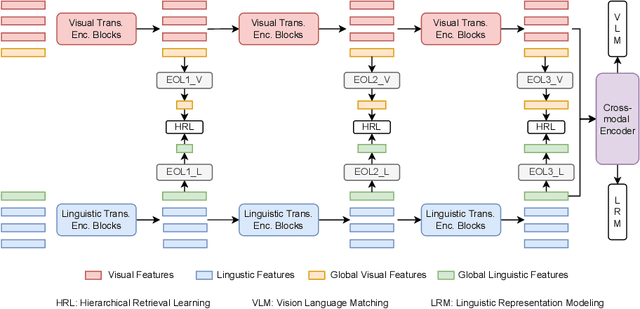
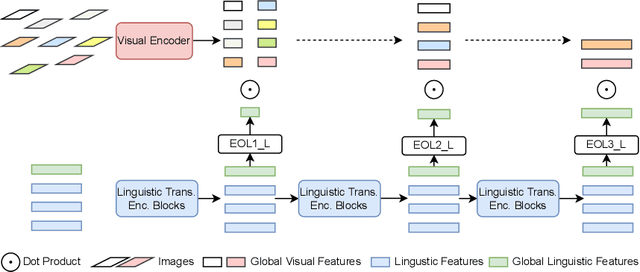
In the past few years, the emergence of vision-language pre-training (VLP) has brought cross-modal retrieval to a new era. However, due to the latency and computation demand, it is commonly challenging to apply VLP in a real-time online retrieval system. To alleviate the defect, this paper proposes a \textbf{Hi}erarchical \textbf{V}ision-\textbf{}Language \textbf{P}re-Training (\textbf{HiVLP}) for fast Image-Text Retrieval (ITR). Specifically, we design a novel hierarchical retrieval objective, which uses the representation of different dimensions for coarse-to-fine ITR, i.e., using low-dimensional representation for large-scale coarse retrieval and high-dimensional representation for small-scale fine retrieval. We evaluate our proposed HiVLP on two popular image-text retrieval benchmarks, i.e., Flickr30k and COCO. Extensive experiments demonstrate that our HiVLP not only has fast inference speed but also can be easily scaled to large-scale ITR scenarios. The detailed results show that HiVLP is $1,427$$\sim$$120,649\times$ faster than the fusion-based model UNITER and 2$\sim$5 faster than the fastest embedding-based model LightingDot in different candidate scenarios. It also achieves about +4.9 AR on COCO and +3.8 AR on Flickr30K than LightingDot and achieves comparable performance with the state-of-the-art (SOTA) fusion-based model METER.
Graph Neural Networks for Learning Real-Time Prices in Electricity Market
Jun 19, 2021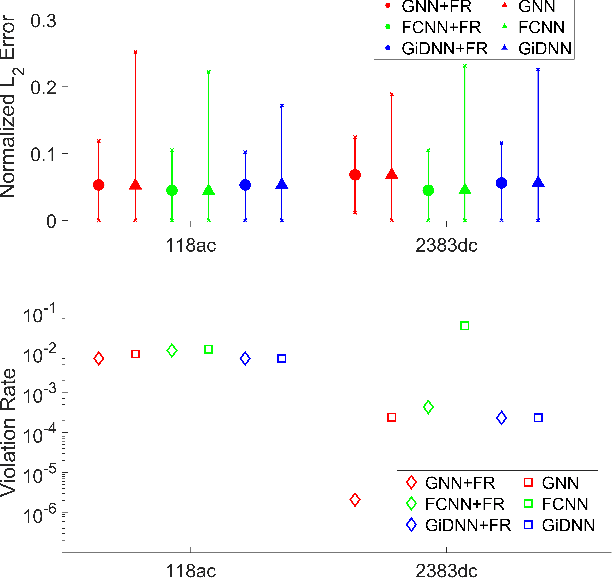
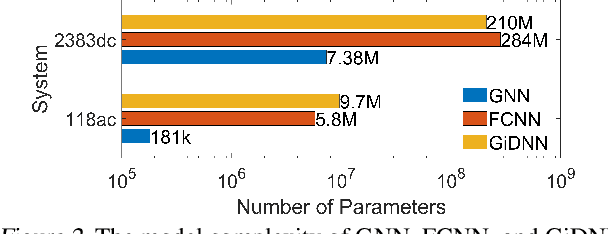
Solving the optimal power flow (OPF) problem in real-time electricity market improves the efficiency and reliability in the integration of low-carbon energy resources into the power grids. To address the scalability and adaptivity issues of existing end-to-end OPF learning solutions, we propose a new graph neural network (GNN) framework for predicting the electricity market prices from solving OPFs. The proposed GNN-for-OPF framework innovatively exploits the locality property of prices and introduces physics-aware regularization, while attaining reduced model complexity and fast adaptivity to varying grid topology. Numerical tests have validated the learning efficiency and adaptivity improvements of our proposed method over existing approaches.
Mean-Field Analysis of Two-Layer Neural Networks: Global Optimality with Linear Convergence Rates
May 19, 2022
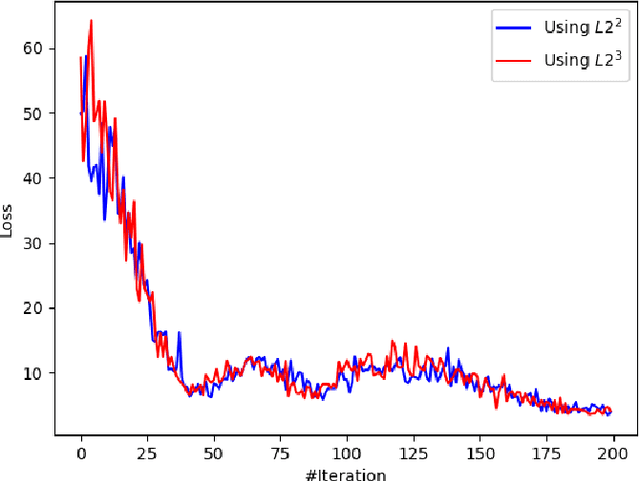
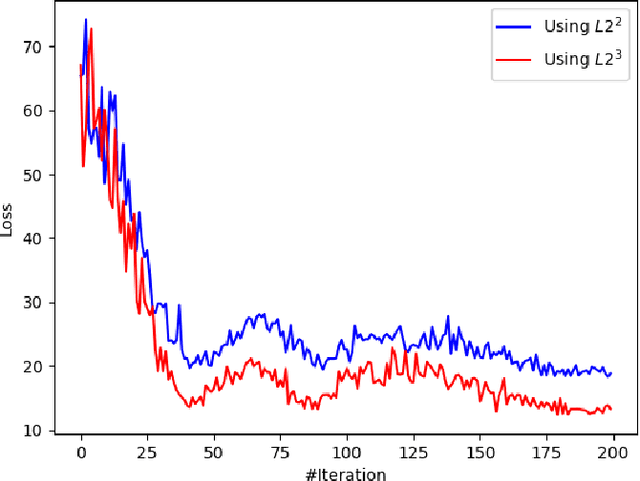
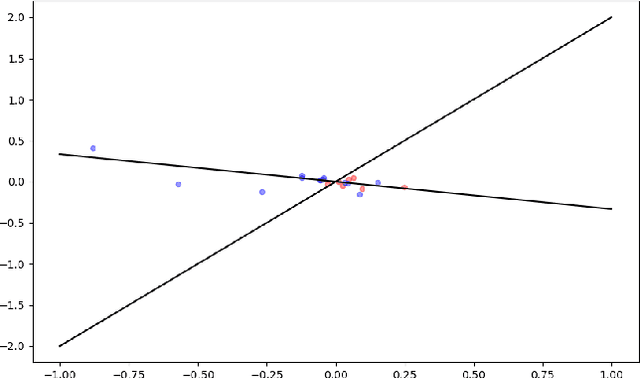
We consider optimizing two-layer neural networks in the mean-field regime where the learning dynamics of network weights can be approximated by the evolution in the space of probability measures over the weight parameters associated with the neurons. The mean-field regime is a theoretically attractive alternative to the NTK (lazy training) regime which is only restricted locally in the so-called neural tangent kernel space around specialized initializations. Several prior works (\cite{mei2018mean, chizat2018global}) establish the asymptotic global optimality of the mean-field regime, but it is still challenging to obtain a quantitative convergence rate due to the complicated nonlinearity of the training dynamics. This work establishes a new linear convergence result for two-layer neural networks trained by continuous-time noisy gradient descent in the mean-field regime. Our result relies on a novelty logarithmic Sobolev inequality for two-layer neural networks, and uniform upper bounds on the logarithmic Sobolev constants for a family of measures determined by the evolving distribution of hidden neurons.
Timing is Everything: Learning to Act Selectively with Costly Actions and Budgetary Constraints
Jun 06, 2022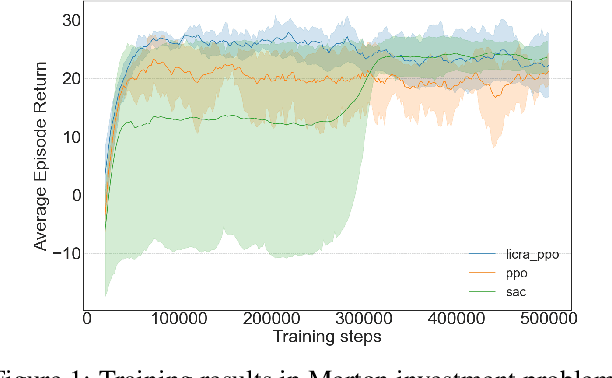
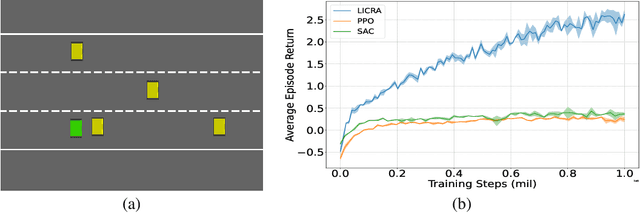
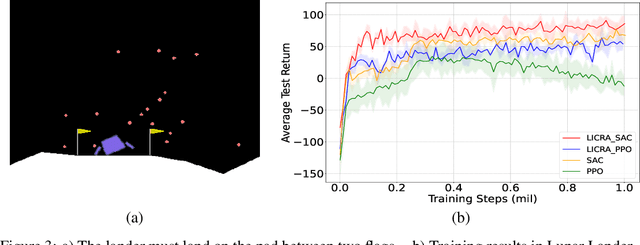
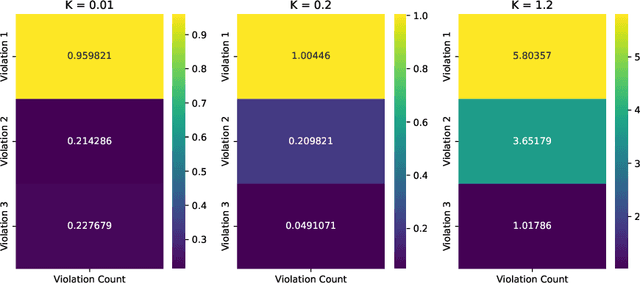
Many real-world settings involve costs for performing actions; transaction costs in financial systems and fuel costs being common examples. In these settings, performing actions at each time step quickly accumulates costs leading to vastly suboptimal outcomes. Additionally, repeatedly acting produces wear and tear and ultimately, damage. Determining when to act is crucial for achieving successful outcomes and yet, the challenge of efficiently learning to behave optimally when actions incur minimally bounded costs remains unresolved. In this paper, we introduce a reinforcement learning (RL) framework named Learnable Impulse Control Reinforcement Algorithm (LICRA), for learning to optimally select both when to act and which actions to take when actions incur costs. At the core of LICRA is a nested structure that combines RL and a form of policy known as impulse control which learns to maximise objectives when actions incur costs. We prove that LICRA, which seamlessly adopts any RL method, converges to policies that optimally select when to perform actions and their optimal magnitudes. We then augment LICRA to handle problems in which the agent can perform at most $k<\infty$ actions and more generally, faces a budget constraint. We show LICRA learns the optimal value function and ensures budget constraints are satisfied almost surely. We demonstrate empirically LICRA's superior performance against benchmark RL methods in OpenAI gym's Lunar Lander and in Highway environments and a variant of the Merton portfolio problem within finance.