 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSufficient Conditions for Stability of Minimum-Norm Interpolating Deep ReLU Networks
Feb 14, 2026Algorithmic stability is a classical framework for analyzing the generalization error of learning algorithms. It predicts that an algorithm has small generalization error if it is insensitive to small perturbations in the training set such as the removal or replacement of a training point. While stability has been demonstrated for numerous well-known algorithms, this framework has had limited success in analyses of deep neural networks. In this paper we study the algorithmic stability of deep ReLU homogeneous neural networks that achieve zero training error using parameters with the smallest $L_2$ norm, also known as the minimum-norm interpolation, a phenomenon that can be observed in overparameterized models trained by gradient-based algorithms. We investigate sufficient conditions for such networks to be stable. We find that 1) such networks are stable when they contain a (possibly small) stable sub-network, followed by a layer with a low-rank weight matrix, and 2) such networks are not guaranteed to be stable even when they contain a stable sub-network, if the following layer is not low-rank. The low-rank assumption is inspired by recent empirical and theoretical results which demonstrate that training deep neural networks is biased towards low-rank weight matrices, for minimum-norm interpolation and weight-decay regularization.
Supervised sparse auto-encoders as unconstrained feature models for semantic composition
Jan 31, 2026Sparse auto-encoders (SAEs) have re-emerged as a prominent method for mechanistic interpretability, yet they face two significant challenges: the non-smoothness of the $L_1$ penalty, which hinders reconstruction and scalability, and a lack of alignment between learned features and human semantics. In this paper, we address these limitations by adapting unconstrained feature models-a mathematical framework from neural collapse theory-and by supervising the task. We supervise (decoder-only) SAEs to reconstruct feature vectors by jointly learning sparse concept embeddings and decoder weights. Validated on Stable Diffusion 3.5, our approach demonstrates compositional generalization, successfully reconstructing images with concept combinations unseen during training, and enabling feature-level intervention for semantic image editing without prompt modification.
Minimal Explanations for Neural Network Predictions
May 19, 2022

Explaining neural network predictions is known to be a challenging problem. In this paper, we propose a novel approach which can be effectively exploited, either in isolation or in combination with other methods, to enhance the interpretability of neural model predictions. For a given input to a trained neural model, our aim is to compute a smallest set of input features so that the model prediction changes when these features are disregarded by setting them to an uninformative baseline value. While computing such minimal explanations is computationally intractable in general for fully-connected neural networks, we show that the problem becomes solvable in polynomial time by a greedy algorithm under mild assumptions on the network's activation functions. We then show that our tractability result extends seamlessly to more advanced neural architectures such as convolutional and graph neural networks. We conduct experiments to showcase the capability of our method for identifying the input features that are essential to the model's prediction.
Confronting Machine Learning With Financial Research
Feb 28, 2021This study aims to examine the challenges and applications of machine learning for financial research. Machine learning algorithms have been developed for certain data environments which substantially differ from the one we encounter in finance. Not only do difficulties arise due to some of the idiosyncrasies of financial markets, there is a fundamental tension between the underlying paradigm of machine learning and the research philosophy in financial economics. Given the peculiar features of financial markets and the empirical framework within social science, various adjustments have to be made to the conventional machine learning methodology. We discuss some of the main challenges of machine learning in finance and examine how these could be accounted for. Despite some of the challenges, we argue that machine learning could be unified with financial research to become a robust complement to the econometrician's toolbox. Moreover, we discuss the various applications of machine learning in the research process such as estimation, empirical discovery, testing, causal inference and prediction.
Double-descent curves in neural networks: a new perspective using Gaussian processes
Feb 16, 2021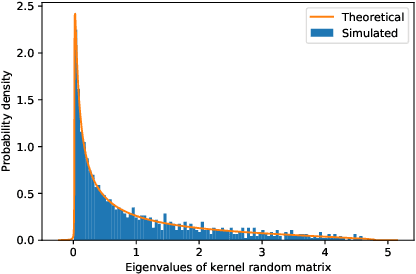
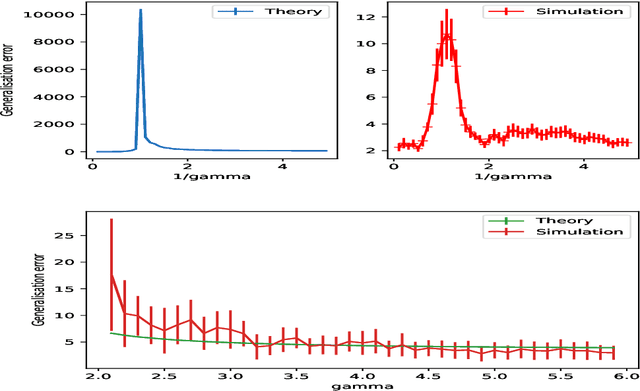
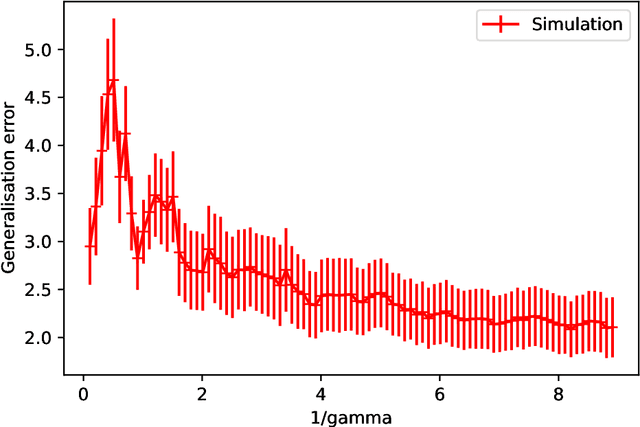
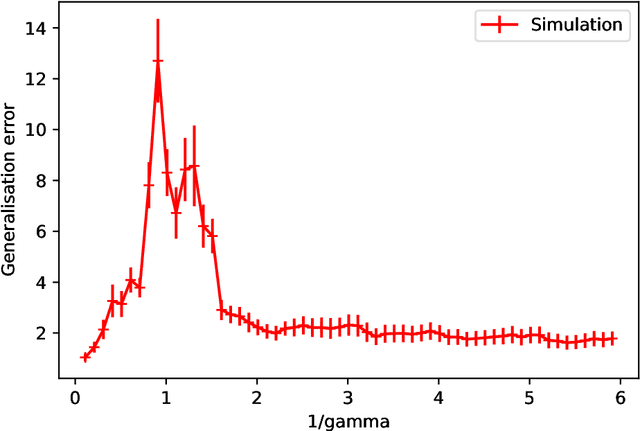
Double-descent curves in neural networks describe the phenomenon that the generalisation error initially descends with increasing parameters, then grows after reaching an optimal number of parameters which is less than the number of data points, but then descends again in the overparameterised regime. Here we use a neural network Gaussian process (NNGP) which maps exactly to a fully connected network (FCN) in the infinite width limit, combined with techniques from random matrix theory, to calculate this generalisation behaviour, with a particular focus on the overparameterised regime. We verify our predictions with numerical simulations of the corresponding Gaussian process regressions. An advantage of our NNGP approach is that the analytical calculations are easier to interpret. We argue that neural network generalization performance improves in the overparameterised regime precisely because that is where they converge to their equivalent Gaussian process.