 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semantic Instance Segmentation of 3D Scenes Through Weak Bounding Box Supervision
Jun 02, 2022
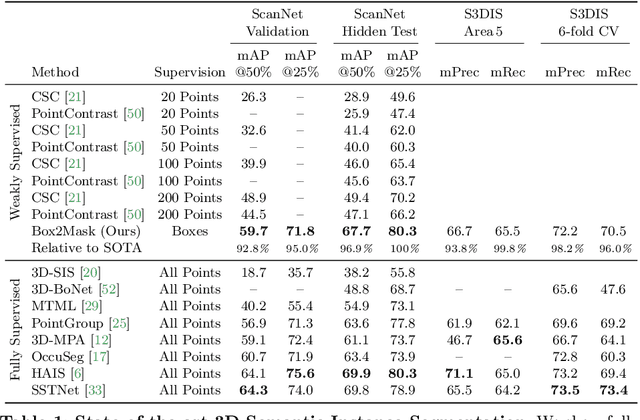
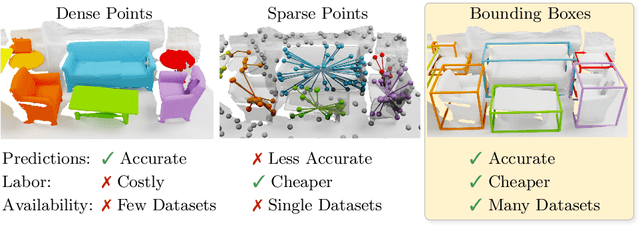
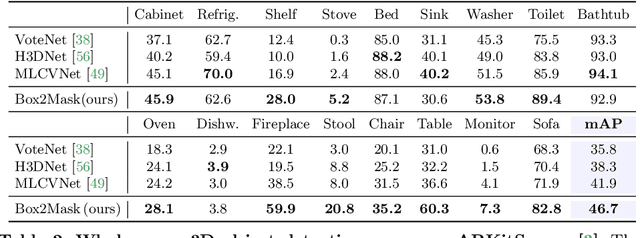
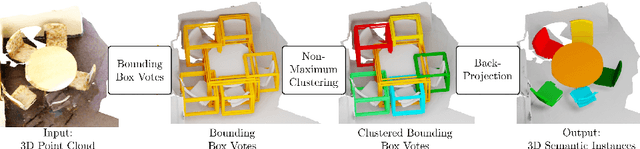
Current 3D segmentation methods heavily rely on large-scale point-cloud datasets, which are notoriously laborious to annotate. Few attempts have been made to circumvent the need for dense per-point annotations. In this work, we look at weakly-supervised 3D instance semantic segmentation. The key idea is to leverage 3D bounding box labels which are easier and faster to annotate. Indeed, we show that it is possible to train dense segmentation models using only weak bounding box labels. At the core of our method, Box2Mask, lies a deep model, inspired by classical Hough voting, that directly votes for bounding box parameters, and a clustering method specifically tailored to bounding box votes. This goes beyond commonly used center votes, which would not fully exploit the bounding box annotations. On ScanNet test, our weakly supervised model attains leading performance among other weakly supervised approaches (+18 mAP50). Remarkably, it also achieves 97% of the performance of fully supervised models. To prove the practicality of our approach, we show segmentation results on the recently released ARKitScenes dataset which is annotated with 3D bounding boxes only, and obtain, for the first time, compelling 3D instance segmentation results.
SQuALITY: Building a Long-Document Summarization Dataset the Hard Way
May 23, 2022

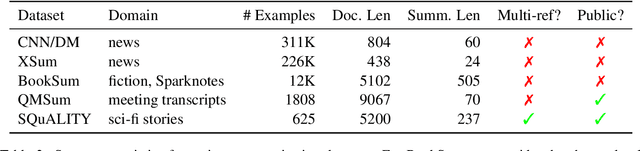

Summarization datasets are often assembled either by scraping naturally occurring public-domain summaries -- which are nearly always in difficult-to-work-with technical domains -- or by using approximate heuristics to extract them from everyday text -- which frequently yields unfaithful summaries. In this work, we turn to a slower but more straightforward approach to developing summarization benchmark data: We hire highly-qualified contractors to read stories and write original summaries from scratch. To amortize reading time, we collect five summaries per document, with the first giving an overview and the subsequent four addressing specific questions. We use this protocol to collect SQuALITY, a dataset of question-focused summaries built on the same public-domain short stories as the multiple-choice dataset QuALITY (Pang et al., 2021). Experiments with state-of-the-art summarization systems show that our dataset is challenging and that existing automatic evaluation metrics are weak indicators of quality.
Ultra-low Latency Spiking Neural Networks with Spatio-Temporal Compression and Synaptic Convolutional Block
Mar 18, 2022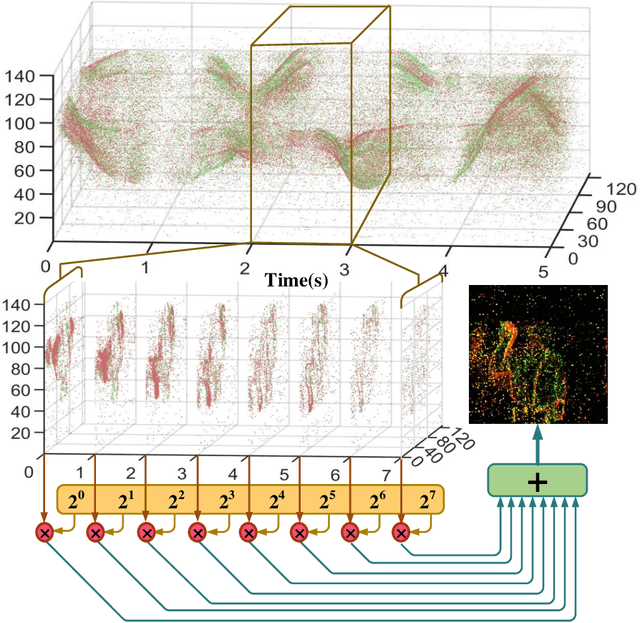
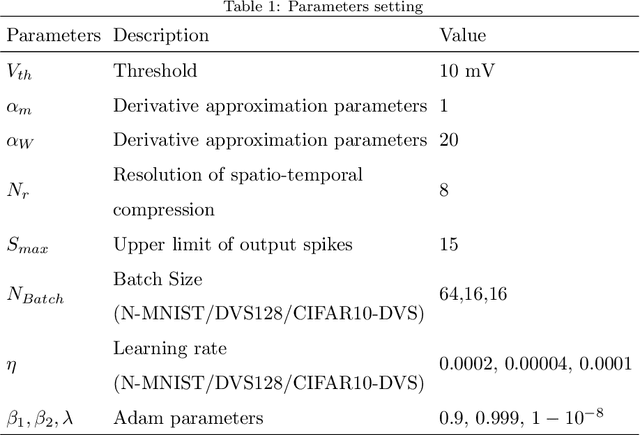
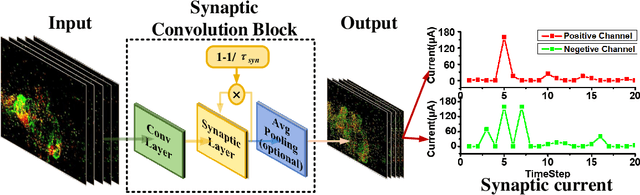
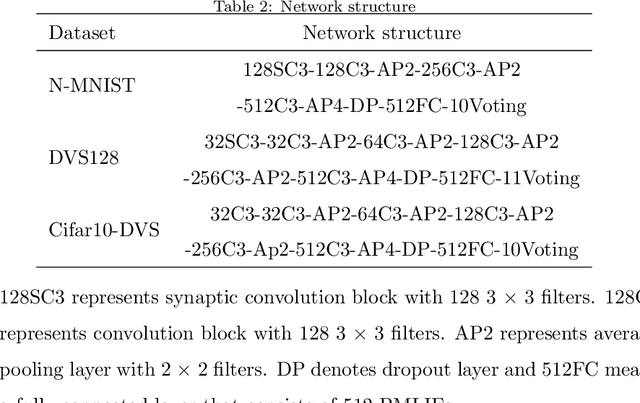
Spiking neural networks (SNNs), as one of the brain-inspired models, has spatio-temporal information processing capability, low power feature, and high biological plausibility. The effective spatio-temporal feature makes it suitable for event streams classification. However, neuromorphic datasets, such as N-MNIST, CIFAR10-DVS, DVS128-gesture, need to aggregate individual events into frames with a new higher temporal resolution for event stream classification, which causes high training and inference latency. In this work, we proposed a spatio-temporal compression method to aggregate individual events into a few time steps of synaptic current to reduce the training and inference latency. To keep the accuracy of SNNs under high compression ratios, we also proposed a synaptic convolutional block to balance the dramatic change between adjacent time steps. And multi-threshold Leaky Integrate-and-Fire (LIF) with learnable membrane time constant is introduced to increase its information processing capability. We evaluate the proposed method for event streams classification tasks on neuromorphic N-MNIST, CIFAR10-DVS, DVS128 gesture datasets. The experiment results show that our proposed method outperforms the state-of-the-art accuracy on nearly all datasets, using fewer time steps.
Concurrent Neural Tree and Data Preprocessing AutoML for Image Classification
May 25, 2022
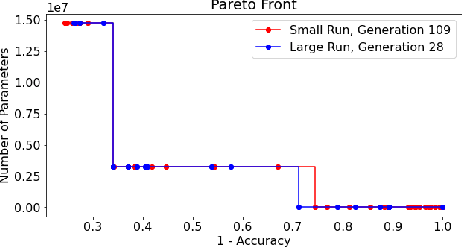

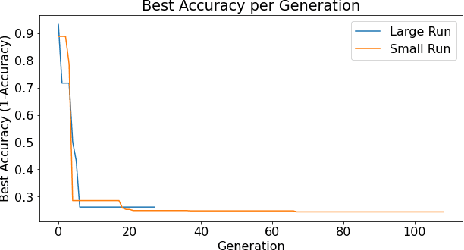
Deep Neural Networks (DNN's) are a widely-used solution for a variety of machine learning problems. However, it is often necessary to invest a significant amount of a data scientist's time to pre-process input data, test different neural network architectures, and tune hyper-parameters for optimal performance. Automated machine learning (autoML) methods automatically search the architecture and hyper-parameter space for optimal neural networks. However, current state-of-the-art (SOTA) methods do not include traditional methods for manipulating input data as part of the algorithmic search space. We adapt the Evolutionary Multi-objective Algorithm Design Engine (EMADE), a multi-objective evolutionary search framework for traditional machine learning methods, to perform neural architecture search. We also integrate EMADE's signal processing and image processing primitives. These primitives allow EMADE to manipulate input data before ingestion into the simultaneously evolved DNN. We show that including these methods as part of the search space shows potential to provide benefits to performance on the CIFAR-10 image classification benchmark dataset.
Beam Squint Assisted User Localization in Near-Field Communications Systems
May 23, 2022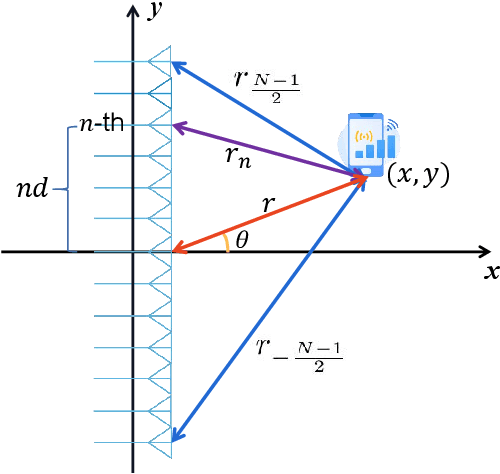
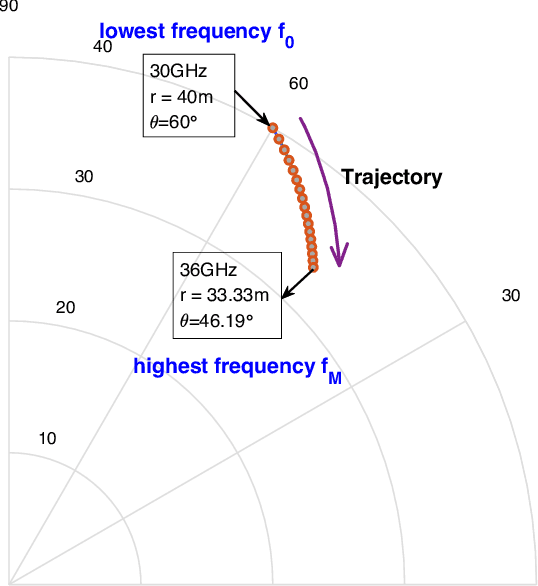
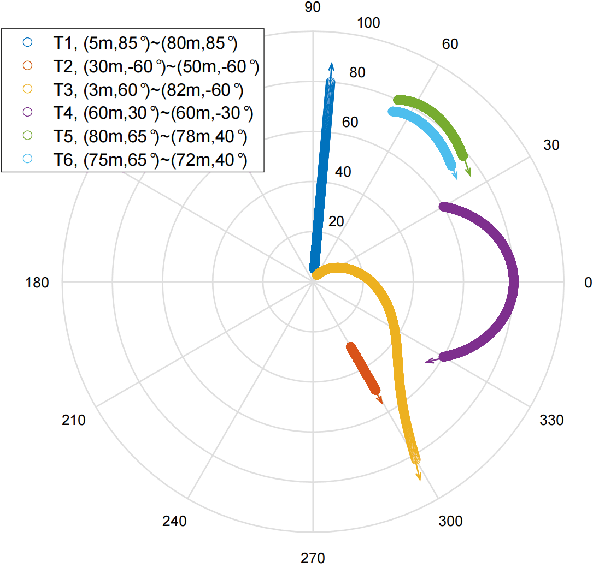
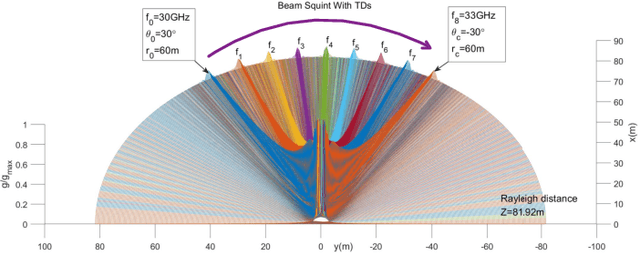
The beam squint phenomenon in massive multi-input and multi-output wideband communications has been widely concerned recently, which generally deteriorates the beamforming performance. In this paper, we find that with the aid of the time-delay lines (TDs), the range and trajectory of the beam squint of a near-field communications system can be freely controlled, and hence it is possible to reversely utilize the beam squint for user localization. We derive the trajectory equation for near-field beam squint points and design a way to control the trajectory of these beam squint points. With the proposed design, beamforming from different subcarriers would purposely point to different angles and different distances such that users from different positions would receive the maximum power at different subcarriers. Hence, one can simply find the different users' position from the beam squint effect. Simulation results demonstrate the effectiveness of the proposed scheme.
The Importance of Future Information in Credit Card Fraud Detection
Apr 11, 2022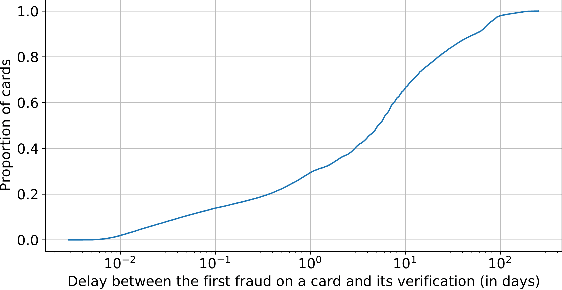
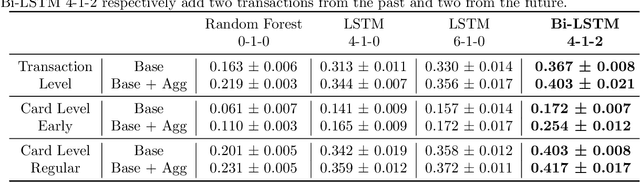
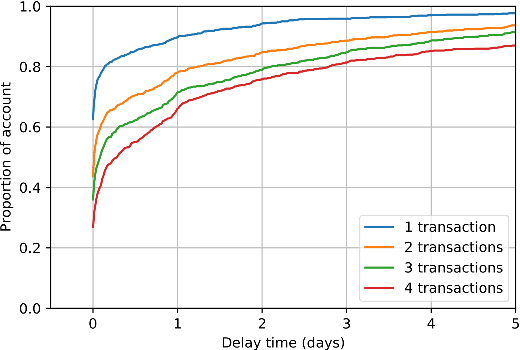
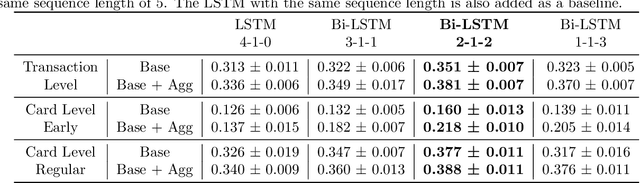
Fraud detection systems (FDS) mainly perform two tasks: (i) real-time detection while the payment is being processed and (ii) posterior detection to block the card retrospectively and avoid further frauds. Since human verification is often necessary and the payment processing time is limited, the second task manages the largest volume of transactions. In the literature, fraud detection challenges and algorithms performance are widely studied but the very formulation of the problem is never disrupted: it aims at predicting if a transaction is fraudulent based on its characteristics and the past transactions of the cardholder. Yet, in posterior detection, verification often takes days, so new payments on the card become available before a decision is taken. This is our motivation to propose a new paradigm: posterior fraud detection with "future" information. We start by providing evidence of the on-time availability of subsequent transactions, usable as extra context to improve detection. We then design a Bidirectional LSTM to make use of these transactions. On a real-world dataset with over 30 million transactions, it achieves higher performance than a regular LSTM, which is the state-of-the-art classifier for fraud detection that only uses the past context. We also introduce new metrics to show that the proposal catches more frauds, more compromised cards, and based on their earliest frauds. We believe that future works on this new paradigm will have a significant impact on the detection of compromised cards.
Unveiling Transformers with LEGO: a synthetic reasoning task
Jun 09, 2022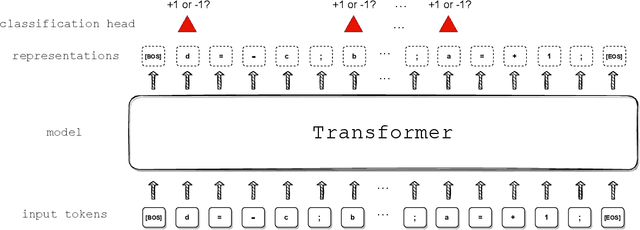
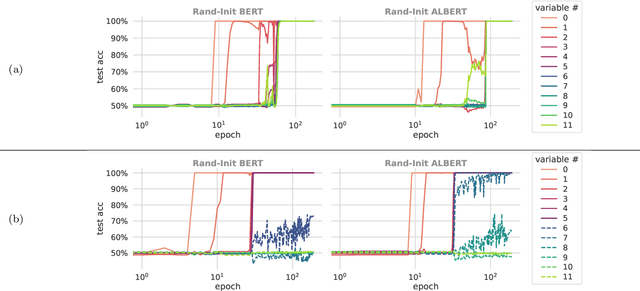
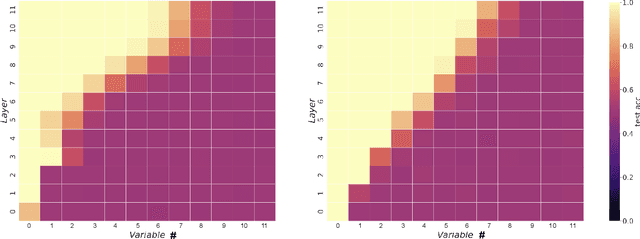
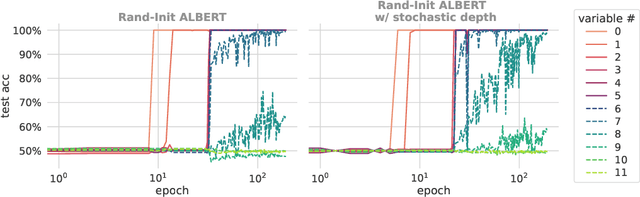
We propose a synthetic task, LEGO (Learning Equality and Group Operations), that encapsulates the problem of following a chain of reasoning, and we study how the transformer architecture learns this task. We pay special attention to data effects such as pretraining (on seemingly unrelated NLP tasks) and dataset composition (e.g., differing chain length at training and test time), as well as architectural variants such as weight-tied layers or adding convolutional components. We study how the trained models eventually succeed at the task, and in particular, we are able to understand (to some extent) some of the attention heads as well as how the information flows in the network. Based on these observations we propose a hypothesis that here pretraining helps merely due to being a smart initialization rather than some deep knowledge stored in the network. We also observe that in some data regime the trained transformer finds "shortcut" solutions to follow the chain of reasoning, which impedes the model's ability to generalize to simple variants of the main task, and moreover we find that one can prevent such shortcut with appropriate architecture modification or careful data preparation. Motivated by our findings, we begin to explore the task of learning to execute C programs, where a convolutional modification to transformers, namely adding convolutional structures in the key/query/value maps, shows an encouraging edge.
Learning heterophilious edge to drop: A general framework for boosting graph neural networks
May 23, 2022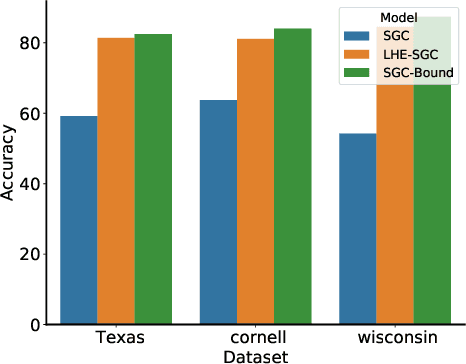
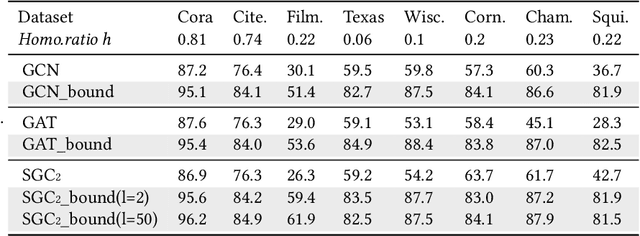
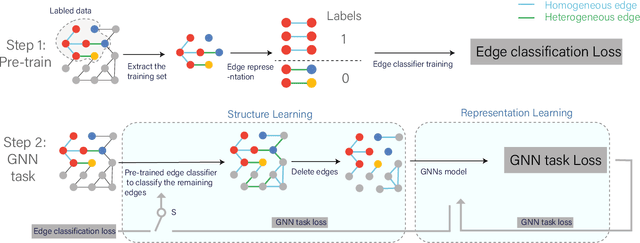
Graph Neural Networks (GNNs) aim at integrating node contents with graph structure to learn nodes/graph representations. Nevertheless, it is found that most of existing GNNs do not work well on data with high heterophily level that accounts for a large proportion of edges between different class labels. Recently, many efforts to tackle this problem focus on optimizing the way of feature learning. From another angle, this work aims at mitigating the negative impacts of heterophily by optimizing graph structure for the first time. Specifically, on assumption that graph smoothing along heterophilious edges can hurt prediction performance, we propose a structure learning method called LHE to identify heterophilious edges to drop. A big advantage of this solution is that it can boost GNNs without careful modification of feature learning strategy. Extensive experiments demonstrate the remarkable performance improvement of GNNs with \emph{LHE} on multiple datasets across full spectrum of homophily level.
The ACM Multimedia 2022 Computational Paralinguistics Challenge: Vocalisations, Stuttering, Activity, & Mosquitoes
May 13, 2022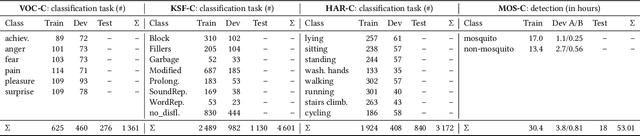

The ACM Multimedia 2022 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the Vocalisations and Stuttering Sub-Challenges, a classification on human non-verbal vocalisations and speech has to be made; the Activity Sub-Challenge aims at beyond-audio human activity recognition from smartwatch sensor data; and in the Mosquitoes Sub-Challenge, mosquitoes need to be detected. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the usual ComPaRE and BoAW features, the auDeep toolkit, and deep feature extraction from pre-trained CNNs using the DeepSpectRum toolkit; in addition, we add end-to-end sequential modelling, and a log-mel-128-BNN.
Visualizing CoAtNet Predictions for Aiding Melanoma Detection
May 21, 2022
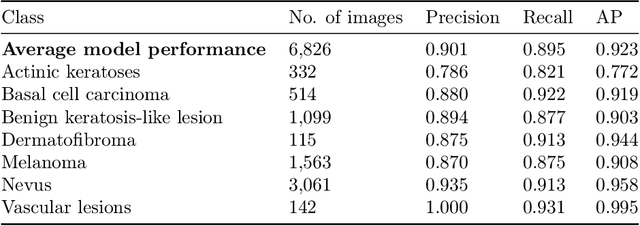
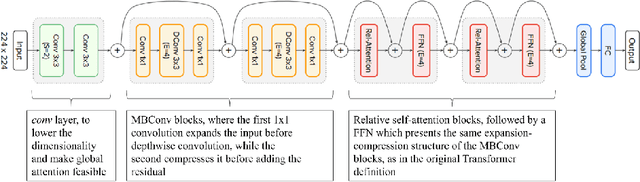
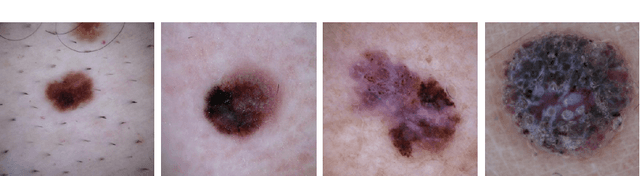
Melanoma is considered to be the most aggressive form of skin cancer. Due to the similar shape of malignant and benign cancerous lesions, doctors spend considerably more time when diagnosing these findings. At present, the evaluation of malignancy is performed primarily by invasive histological examination of the suspicious lesion. Developing an accurate classifier for early and efficient detection can minimize and monitor the harmful effects of skin cancer and increase patient survival rates. This paper proposes a multi-class classification task using the CoAtNet architecture, a hybrid model that combines the depthwise convolution matrix operation of traditional convolutional neural networks with the strengths of Transformer models and self-attention mechanics to achieve better generalization and capacity. The proposed multi-class classifier achieves an overall precision of 0.901, recall 0.895, and AP 0.923, indicating high performance compared to other state-of-the-art networks.