 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Approaching sales forecasting using recurrent neural networks and transformers
Apr 16, 2022
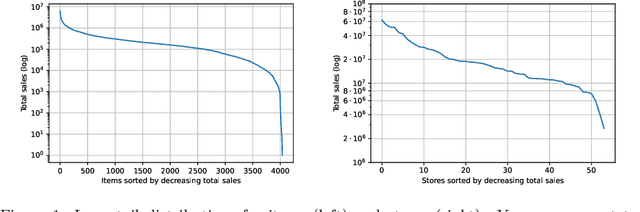
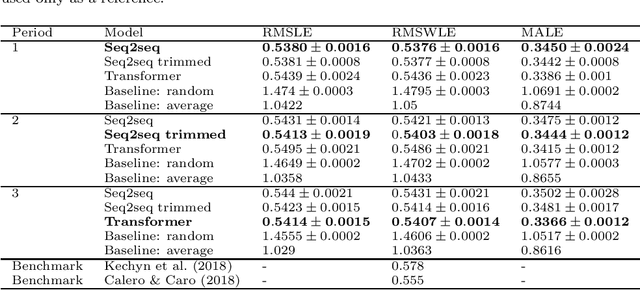
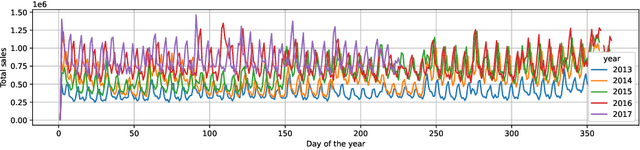
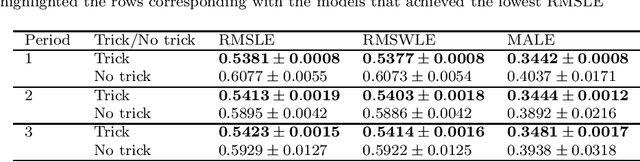
Accurate and fast demand forecast is one of the hot topics in supply chain for enabling the precise execution of the corresponding downstream processes (inbound and outbound planning, inventory placement, network planning, etc). We develop three alternatives to tackle the problem of forecasting the customer sales at day/store/item level using deep learning techniques and the Corporaci\'on Favorita data set, published as part of a Kaggle competition. Our empirical results show how good performance can be achieved by using a simple sequence to sequence architecture with minimal data preprocessing effort. Additionally, we describe a training trick for making the model more time independent and hence improving generalization over time. The proposed solution achieves a RMSLE of around 0.54, which is competitive with other more specific solutions to the problem proposed in the Kaggle competition.
INDIGO: Intrinsic Multimodality for Domain Generalization
Jun 13, 2022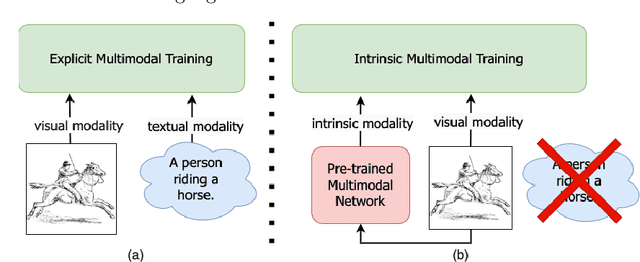
For models to generalize under unseen domains (a.k.a domain generalization), it is crucial to learn feature representations that are domain-agnostic and capture the underlying semantics that makes up an object category. Recent advances towards weakly supervised vision-language models that learn holistic representations from cheap weakly supervised noisy text annotations have shown their ability on semantic understanding by capturing object characteristics that generalize under different domains. However, when multiple source domains are involved, the cost of curating textual annotations for every image in the dataset can blow up several times, depending on their number. This makes the process tedious and infeasible, hindering us from directly using these supervised vision-language approaches to achieve the best generalization on an unseen domain. Motivated from this, we study how multimodal information from existing pre-trained multimodal networks can be leveraged in an "intrinsic" way to make systems generalize under unseen domains. To this end, we propose IntriNsic multimodality for DomaIn GeneralizatiOn (INDIGO), a simple and elegant way of leveraging the intrinsic modality present in these pre-trained multimodal networks along with the visual modality to enhance generalization to unseen domains at test-time. We experiment on several Domain Generalization settings (ClosedDG, OpenDG, and Limited sources) and show state-of-the-art generalization performance on unseen domains. Further, we provide a thorough analysis to develop a holistic understanding of INDIGO.
Real-Time Super-Resolution System of 4K-Video Based on Deep Learning
Jul 12, 2021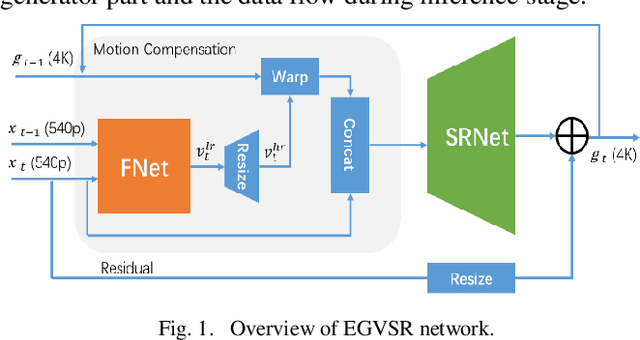
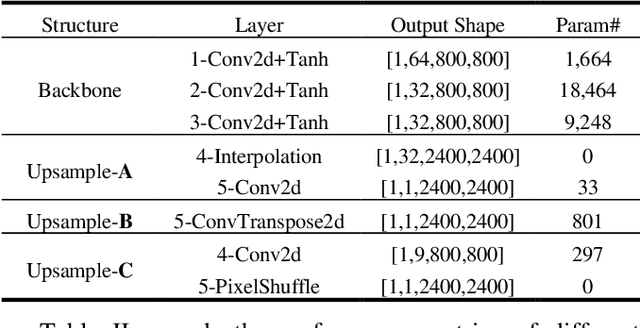
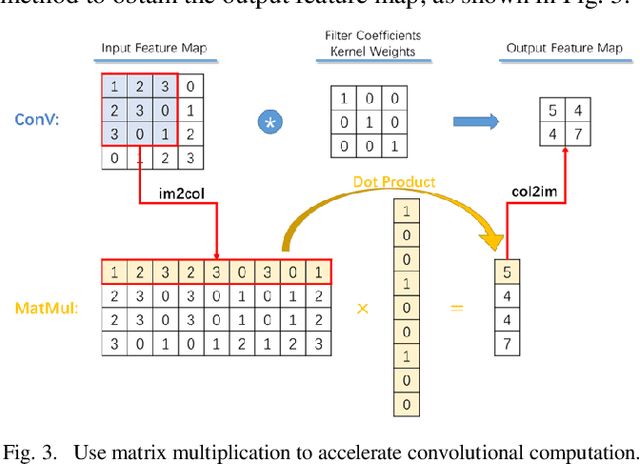

Video super-resolution (VSR) technology excels in reconstructing low-quality video, avoiding unpleasant blur effect caused by interpolation-based algorithms. However, vast computation complexity and memory occupation hampers the edge of deplorability and the runtime inference in real-life applications, especially for large-scale VSR task. This paper explores the possibility of real-time VSR system and designs an efficient and generic VSR network, termed EGVSR. The proposed EGVSR is based on spatio-temporal adversarial learning for temporal coherence. In order to pursue faster VSR processing ability up to 4K resolution, this paper tries to choose lightweight network structure and efficient upsampling method to reduce the computation required by EGVSR network under the guarantee of high visual quality. Besides, we implement the batch normalization computation fusion, convolutional acceleration algorithm and other neural network acceleration techniques on the actual hardware platform to optimize the inference process of EGVSR network. Finally, our EGVSR achieves the real-time processing capacity of 4K@29.61FPS. Compared with TecoGAN, the most advanced VSR network at present, we achieve 85.04% reduction of computation density and 7.92x performance speedups. In terms of visual quality, the proposed EGVSR tops the list of most metrics (such as LPIPS, tOF, tLP, etc.) on the public test dataset Vid4 and surpasses other state-of-the-art methods in overall performance score. The source code of this project can be found on https://github.com/Thmen/EGVSR.
Separable Self-attention for Mobile Vision Transformers
Jun 06, 2022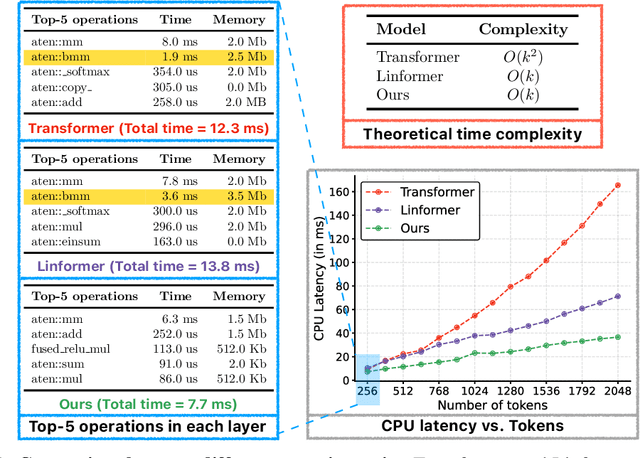

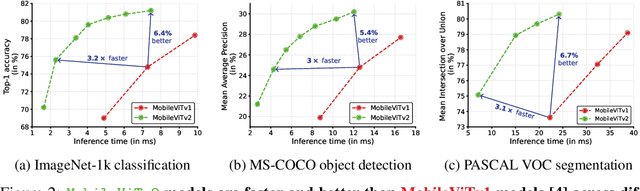

Mobile vision transformers (MobileViT) can achieve state-of-the-art performance across several mobile vision tasks, including classification and detection. Though these models have fewer parameters, they have high latency as compared to convolutional neural network-based models. The main efficiency bottleneck in MobileViT is the multi-headed self-attention (MHA) in transformers, which requires $O(k^2)$ time complexity with respect to the number of tokens (or patches) $k$. Moreover, MHA requires costly operations (e.g., batch-wise matrix multiplication) for computing self-attention, impacting latency on resource-constrained devices. This paper introduces a separable self-attention method with linear complexity, i.e. $O(k)$. A simple yet effective characteristic of the proposed method is that it uses element-wise operations for computing self-attention, making it a good choice for resource-constrained devices. The improved model, MobileViTv2, is state-of-the-art on several mobile vision tasks, including ImageNet object classification and MS-COCO object detection. With about three million parameters, MobileViTv2 achieves a top-1 accuracy of 75.6% on the ImageNet dataset, outperforming MobileViT by about 1% while running $3.2\times$ faster on a mobile device. Our source code is available at: \url{https://github.com/apple/ml-cvnets}
Failure Detection in Medical Image Classification: A Reality Check and Benchmarking Testbed
May 27, 2022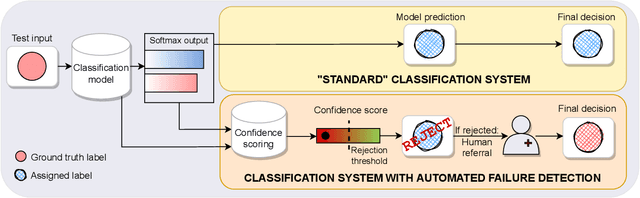
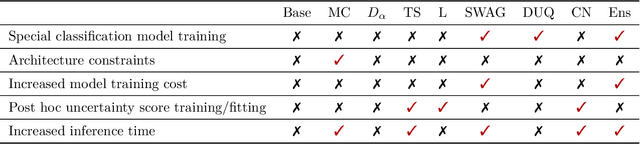
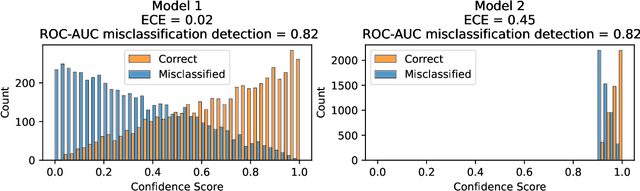
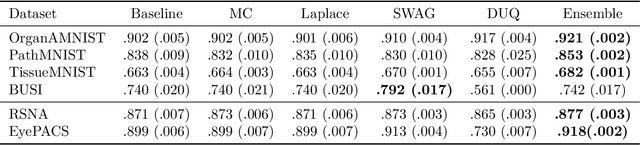
Failure detection in automated image classification is a critical safeguard for clinical deployment. Detected failure cases can be referred to human assessment, ensuring patient safety in computer-aided clinical decision making. Despite its paramount importance, there is insufficient evidence about the ability of state-of-the-art confidence scoring methods to detect test-time failures of classification models in the context of medical imaging. This paper provides a reality check, establishing the performance of in-domain misclassification detection methods, benchmarking 9 confidence scores on 6 medical imaging datasets with different imaging modalities, in multiclass and binary classification settings. Our experiments show that the problem of failure detection is far from being solved. We found that none of the benchmarked advanced methods proposed in the computer vision and machine learning literature can consistently outperform a simple softmax baseline. Our developed testbed facilitates future work in this important area.
Conditional Versus Adversarial Euler-based Generators For Time Series
Feb 10, 2021
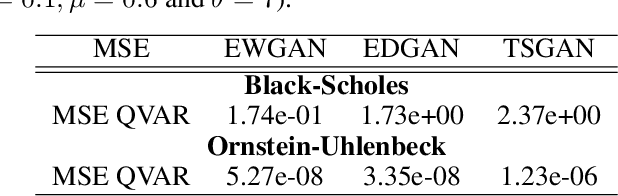

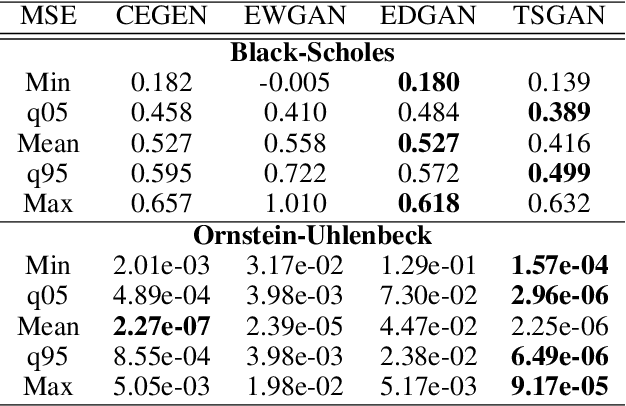
We introduce new generative models for time series based on Euler discretization that do not require any pre-stationarization procedure. Specifically, we develop two GAN based methods, relying on the adaptation of Wasserstein GANs (Arjovsky et al., 2017) and DVD GANs (Clark et al., 2019b) to time series. Alternatively, we consider a conditional Euler Generator (CEGEN) minimizing a distance between the induced conditional densities. In the context of It\^o processes, we theoretically validate this approach and demonstrate using the Bures metric that reaching a low loss level provides accurate estimations for both the drift and the volatility terms of the underlying process. Tests on simple models show how the Euler discretization and the use of Wasserstein distance allow the proposed GANs and (more considerably) CEGEN to outperform state-of-the-art Time Series GAN generation( Yoon et al., 2019b) on time structure metrics. In higher dimensions we observe that CEGEN manages to get the correct covariance structures. Finally we illustrate how our model can be combined to a Monte Carlo simulator in a low data context by using a transfer learning technique
Curriculum Learning for Goal-Oriented Semantic Communications with a Common Language
Apr 21, 2022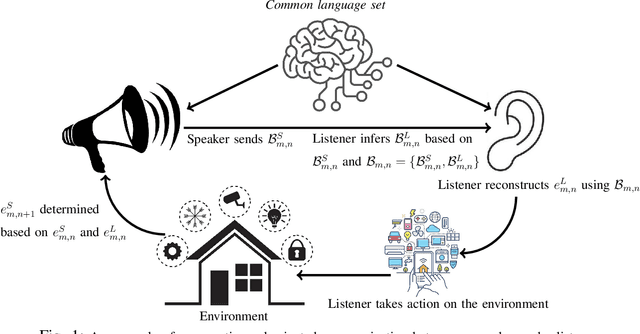
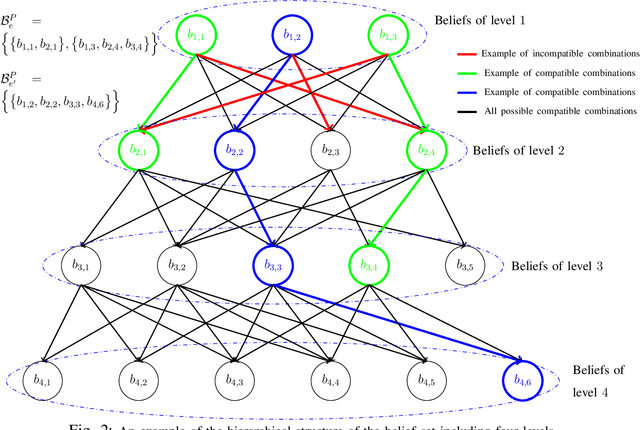
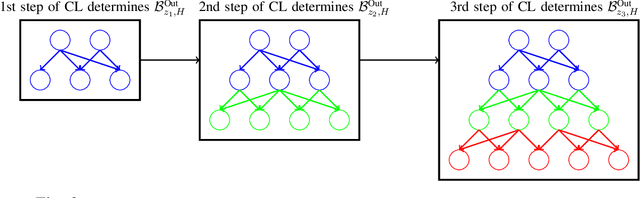
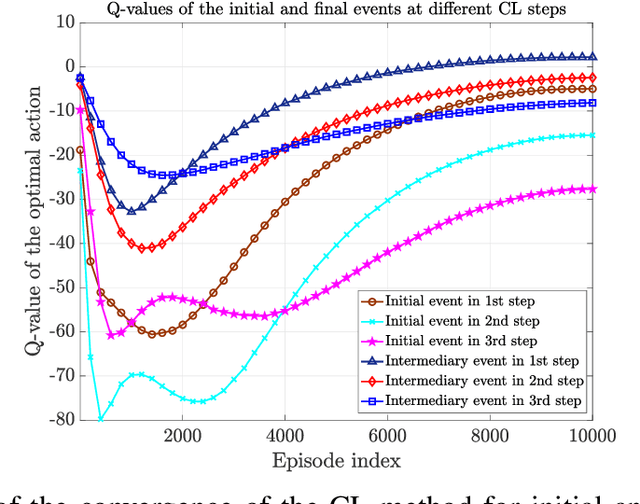
Goal-oriented semantic communication will be a pillar of next-generation wireless networks. Despite significant recent efforts in this area, most prior works are focused on specific data types (e.g., image or audio), and they ignore the goal and effectiveness aspects of semantic transmissions. In contrast, in this paper, a holistic goal-oriented semantic communication framework is proposed to enable a speaker and a listener to cooperatively execute a set of sequential tasks in a dynamic environment. A common language based on a hierarchical belief set is proposed to enable semantic communications between speaker and listener. The speaker, acting as an observer of the environment, utilizes the beliefs to transmit an initial description of its observation (called event) to the listener. The listener is then able to infer on the transmitted description and complete it by adding related beliefs to the transmitted beliefs of the speaker. As such, the listener reconstructs the observed event based on the completed description, and it then takes appropriate action in the environment based on the reconstructed event. An optimization problem is defined to determine the perfect and abstract description of the events while minimizing the transmission and inference costs with constraints on the task execution time and belief efficiency. Then, a novel bottom-up curriculum learning (CL) framework based on reinforcement learning is proposed to solve the optimization problem and enable the speaker and listener to gradually identify the structure of the belief set and the perfect and abstract description of the events. Simulation results show that the proposed CL method outperforms traditional RL in terms of convergence time, task execution cost and time, reliability, and belief efficiency.
UnICORNN: A recurrent model for learning very long time dependencies
Mar 09, 2021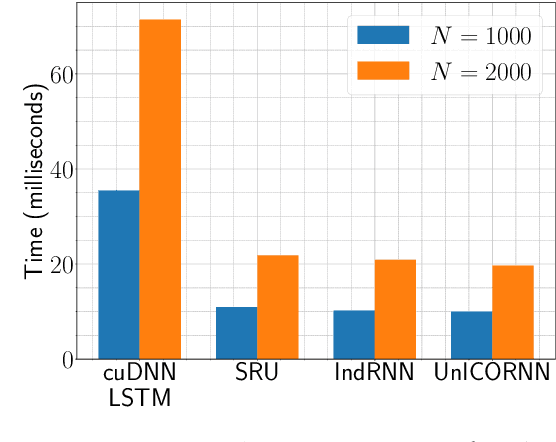
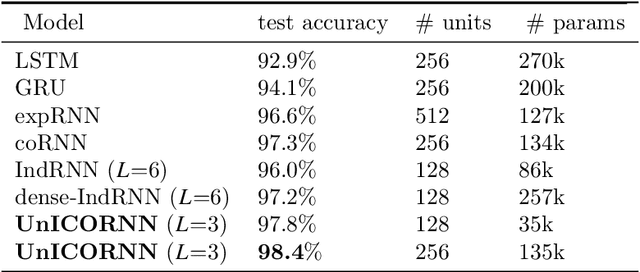

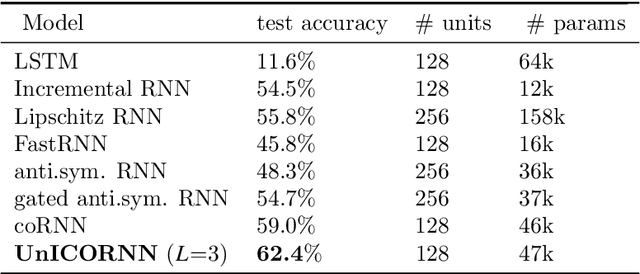
The design of recurrent neural networks (RNNs) to accurately process sequential inputs with long-time dependencies is very challenging on account of the exploding and vanishing gradient problem. To overcome this, we propose a novel RNN architecture which is based on a structure preserving discretization of a Hamiltonian system of second-order ordinary differential equations that models networks of oscillators. The resulting RNN is fast, invertible (in time), memory efficient and we derive rigorous bounds on the hidden state gradients to prove the mitigation of the exploding and vanishing gradient problem. A suite of experiments are presented to demonstrate that the proposed RNN provides state of the art performance on a variety of learning tasks with (very) long time-dependencies.
Sound Event Classification in an Industrial Environment: Pipe Leakage Detection Use Case
May 05, 2022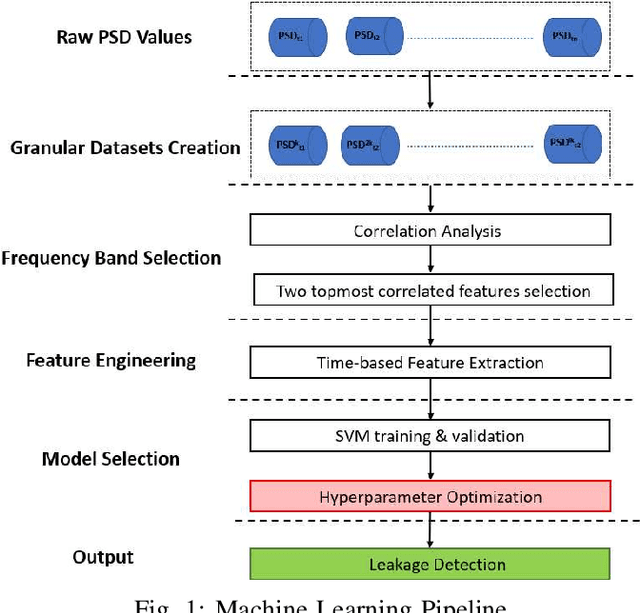
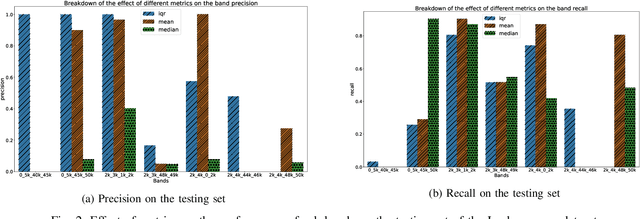
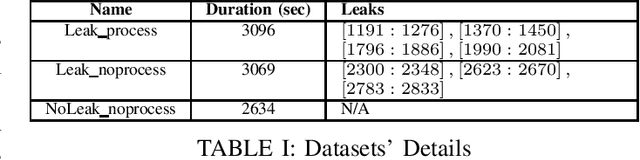
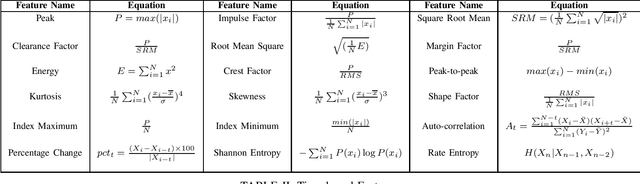
In this work, a multi-stage Machine Learning (ML) pipeline is proposed for pipe leakage detection in an industrial environment. As opposed to other industrial and urban environments, the environment under study includes many interfering background noises, complicating the identification of leaks. Furthermore, the harsh environmental conditions limit the amount of data collected and impose the use of low-complexity algorithms. To address the environment's constraints, the developed ML pipeline applies multiple steps, each addressing the environment's challenges. The proposed ML pipeline first reduces the data dimensionality by feature selection techniques and then incorporates time correlations by extracting time-based features. The resultant features are fed to a Support Vector Machine (SVM) of low-complexity that generalizes well to a small amount of data. An extensive experimental procedure was carried out on two datasets, one with background industrial noise and one without, to evaluate the validity of the proposed pipeline. The SVM hyper-parameters and parameters specific to the pipeline steps were tuned as part of the experimental procedure. The best models obtained from the dataset with industrial noise and leaks were applied to datasets without noise and with and without leaks to test their generalizability. The results show that the model produces excellent results with 99\% accuracy and an F1-score of 0.93 and 0.9 for the respective datasets.
A Deep Reinforcement Learning Framework for Rapid Diagnosis of Whole Slide Pathological Images
May 05, 2022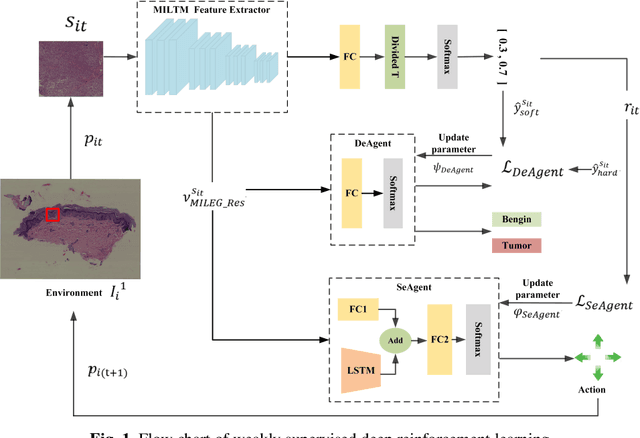
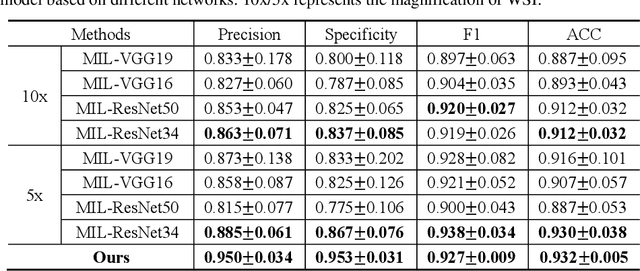
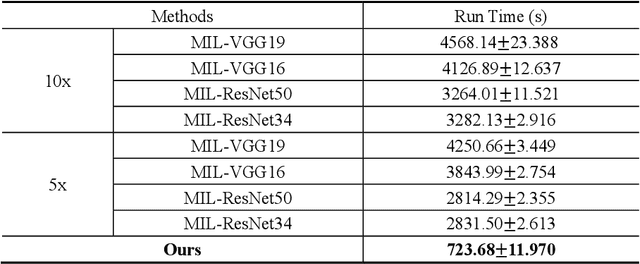
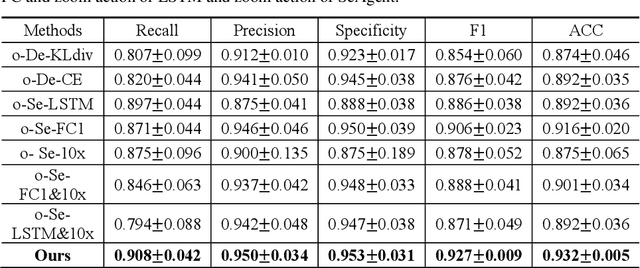
The deep neural network is a research hotspot for histopathological image analysis, which can improve the efficiency and accuracy of diagnosis for pathologists or be used for disease screening. The whole slide pathological image can reach one gigapixel and contains abundant tissue feature information, which needs to be divided into a lot of patches in the training and inference stages. This will lead to a long convergence time and large memory consumption. Furthermore, well-annotated data sets are also in short supply in the field of digital pathology. Inspired by the pathologist's clinical diagnosis process, we propose a weakly supervised deep reinforcement learning framework, which can greatly reduce the time required for network inference. We use neural network to construct the search model and decision model of reinforcement learning agent respectively. The search model predicts the next action through the image features of different magnifications in the current field of view, and the decision model is used to return the predicted probability of the current field of view image. In addition, an expert-guided model is constructed by multi-instance learning, which not only provides rewards for search model, but also guides decision model learning by the knowledge distillation method. Experimental results show that our proposed method can achieve fast inference and accurate prediction of whole slide images without any pixel-level annotations.