 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient textual explanations for complex road and traffic scenarios based on semantic segmentation
May 26, 2022
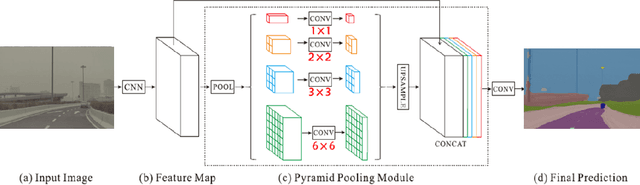

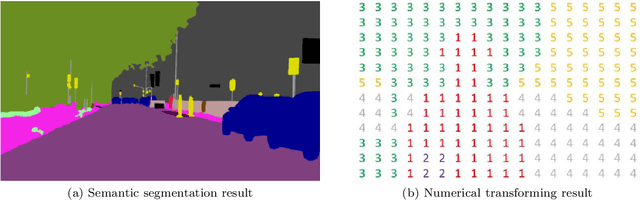
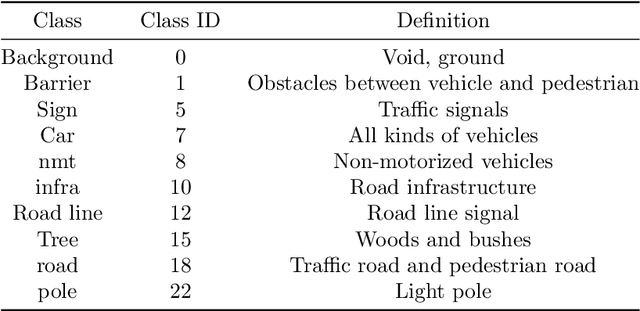
The complex driving environment brings great challenges to the visual perception of autonomous vehicles. The accuracy of visual perception drops off sharply under diverse weather conditions and uncertain traffic flow. Black box model makes it difficult to interpret the mechanisms of visual perception. To enhance the user acceptance and reliability of the visual perception system, a textual explanation of the scene evolvement is essential. It analyzes the geometry and topology structure in the complex environment and offers clues to decision and control. However, the existing scene explanation has been implemented as a separate model. It cannot detect comprehensive textual information and requires a high computational load and time consumption. Thus, this study proposed a comprehensive and efficient textual explanation model for complex road and traffic scenarios. From 336k video frames of the driving environment, critical images of complex road and traffic scenarios were selected into a dataset. Through transfer learning, this study established an accurate and efficient segmentation model to gain semantic information. Based on the XGBoost algorithm, a comprehensive model was developed. The model obtained textual information including road types, the motion of conflict objects, and scenario complexity. The approach was verified on the real-world road. It improved the perception accuracy of critical traffic elements to 78.8%. The time consumption reached 13 minutes for each epoch, which was 11.5 times more efficient compared with the pre-trained network. The textual information analyzed from the model was also accordant with reality. The findings explain how autonomous vehicle detects the driving environment, which lays a foundation for subsequent decision and control. It can improve the perception ability by enriching the prior knowledge and judgments for complex traffic situations.
Multi-objective Pointer Network for Combinatorial Optimization
Apr 25, 2022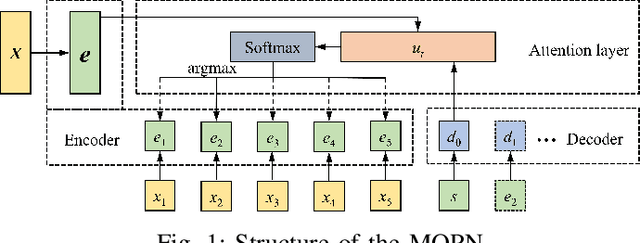
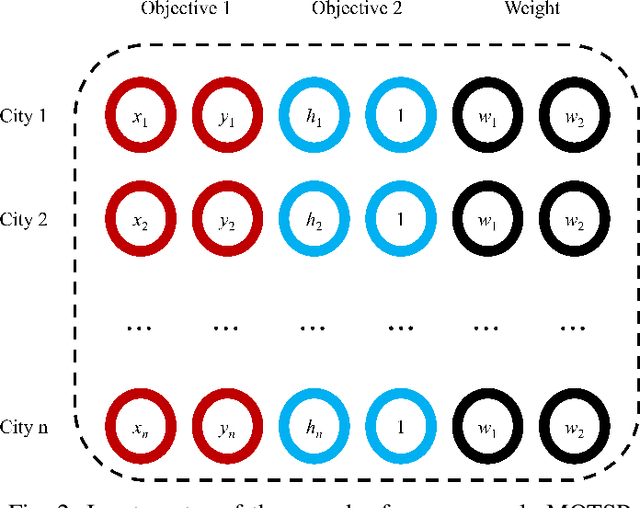
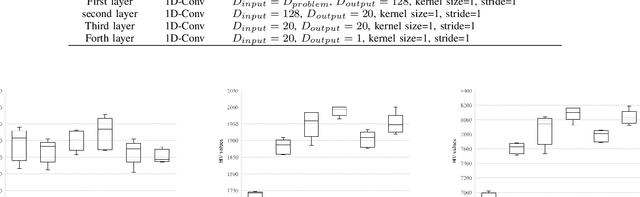
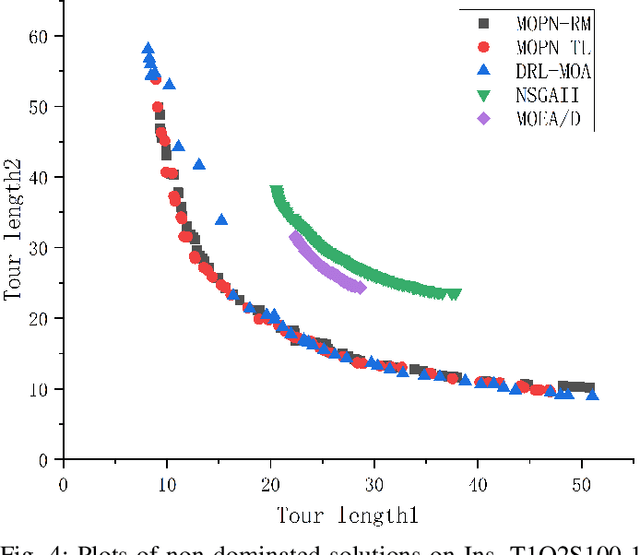
Multi-objective combinatorial optimization problems (MOCOPs), one type of complex optimization problems, widely exist in various real applications. Although meta-heuristics have been successfully applied to address MOCOPs, the calculation time is often much longer. Recently, a number of deep reinforcement learning (DRL) methods have been proposed to generate approximate optimal solutions to the combinatorial optimization problems. However, the existing studies on DRL have seldom focused on MOCOPs. This study proposes a single-model deep reinforcement learning framework, called multi-objective Pointer Network (MOPN), where the input structure of PN is effectively improved so that the single PN is capable of solving MOCOPs. In addition, two training strategies, based on representative model and transfer learning, respectively, are proposed to further enhance the performance of MOPN in different application scenarios. Moreover, compared to classical meta-heuristics, MOPN only consumes much less time on forward propagation to obtain the Pareto front. Meanwhile, MOPN is insensitive to problem scale, meaning that a trained MOPN is able to address MOCOPs with different scales. To verify the performance of MOPN, extensive experiments are conducted on three multi-objective traveling salesman problems, in comparison with one state-of-the-art model DRL-MOA and three classical multi-objective meta-heuristics. Experimental results demonstrate that the proposed model outperforms all the comparative methods with only 20\% to 40\% training time of DRL-MOA.
Environmental Sensing Options for Robot Teams: A Computational Complexity Perspective
May 10, 2022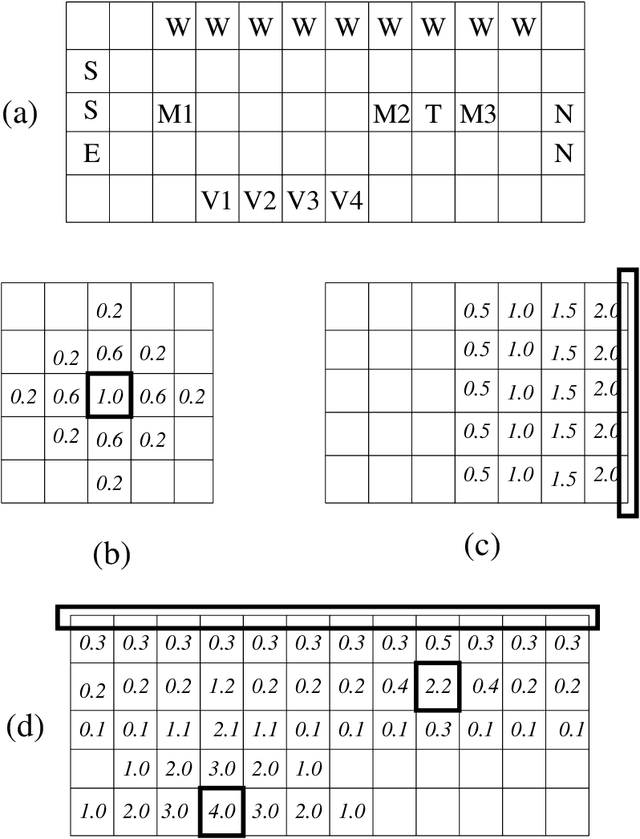
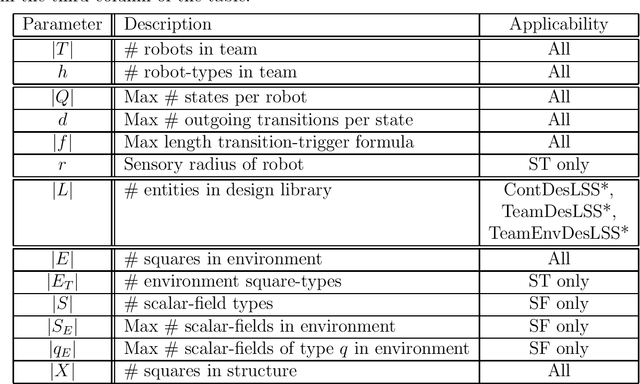
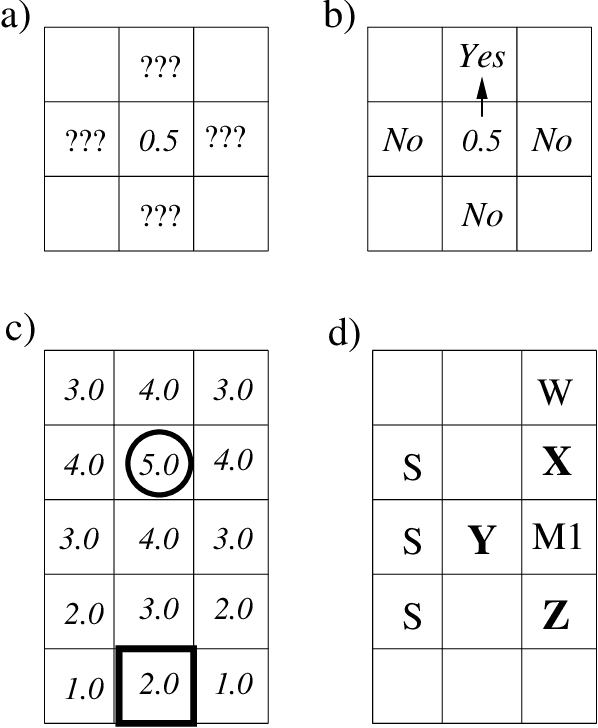
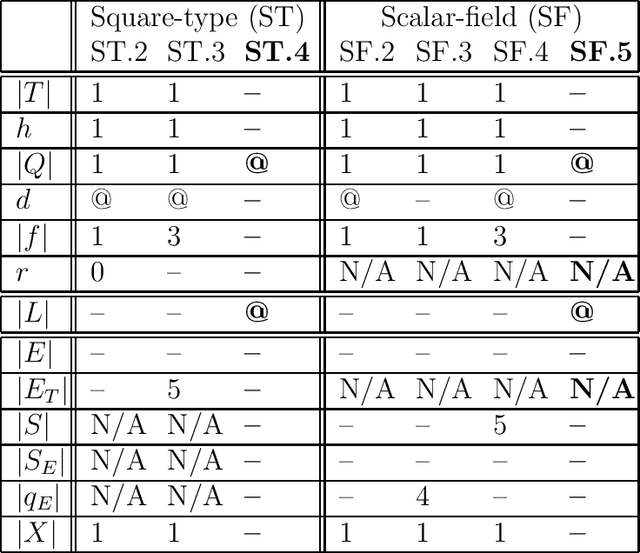
Visual and scalar-field (e.g., chemical) sensing are two of the options robot teams can use to perceive their environments when performing tasks. We give the first comparison of the computational characteristic of visual and scalar-field sensing, phrased in terms of the computational complexities of verifying and designing teams of robots to efficiently and robustly perform distributed construction tasks. This is done relative a basic model in which teams of robots with deterministic finite-state controllers operate in a synchronous error-free manner in 2D grid-based environments. Our results show that for both types of sensing, all of our problems are polynomial-time intractable in general and remain intractable under a variety of restrictions on parameters characterizing robot controllers, teams, and environments. That being said, these results also include restricted situations for each of our problems in which those problems are effectively polynomial-time tractable. Though there are some differences, our results suggest that (at least in this stage of our investigation) verification and design problems relative to visual and scalar-field sensing have roughly the same patterns and types of tractability and intractability results.
Communication Efficient Distributed Learning for Kernelized Contextual Bandits
Jun 10, 2022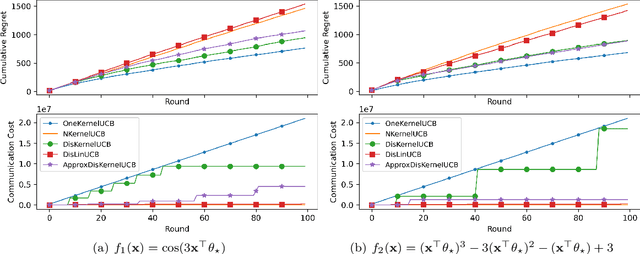
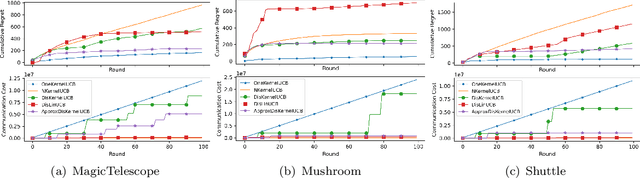
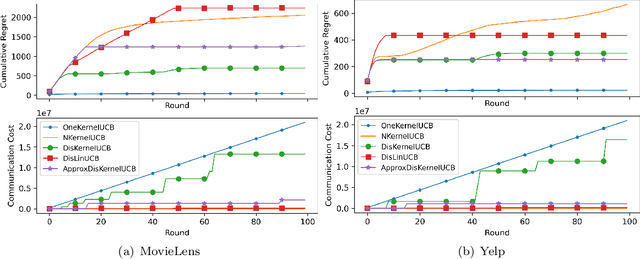
We tackle the communication efficiency challenge of learning kernelized contextual bandits in a distributed setting. Despite the recent advances in communication-efficient distributed bandit learning, existing solutions are restricted to simple models like multi-armed bandits and linear bandits, which hamper their practical utility. In this paper, instead of assuming the existence of a linear reward mapping from the features to the expected rewards, we consider non-linear reward mappings, by letting agents collaboratively search in a reproducing kernel Hilbert space (RKHS). This introduces significant challenges in communication efficiency as distributed kernel learning requires the transfer of raw data, leading to a communication cost that grows linearly w.r.t. time horizon $T$. We addresses this issue by equipping all agents to communicate via a common Nystr\"{o}m embedding that gets updated adaptively as more data points are collected. We rigorously proved that our algorithm can attain sub-linear rate in both regret and communication cost.
Dyadic aggregated autoregressive (DASAR) model for time-frequency representation of biomedical signals
May 13, 2021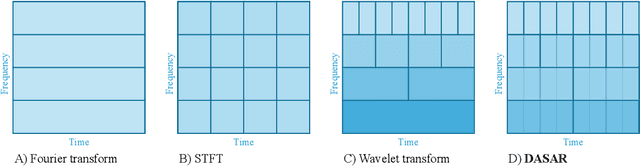
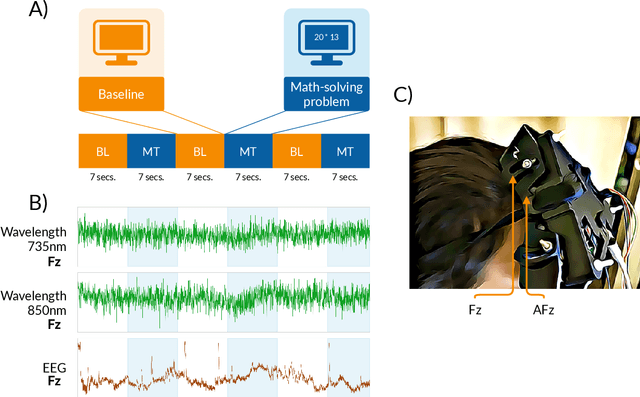
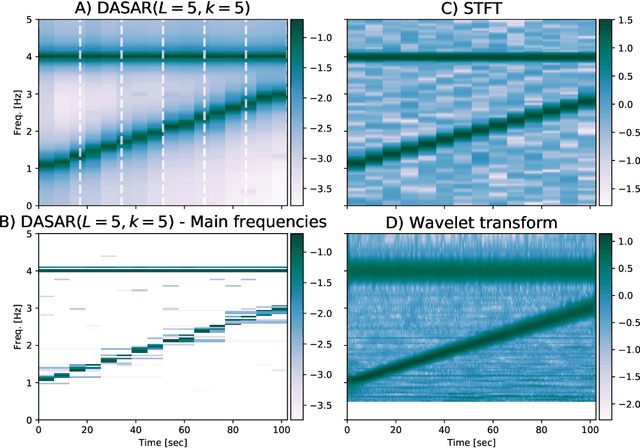
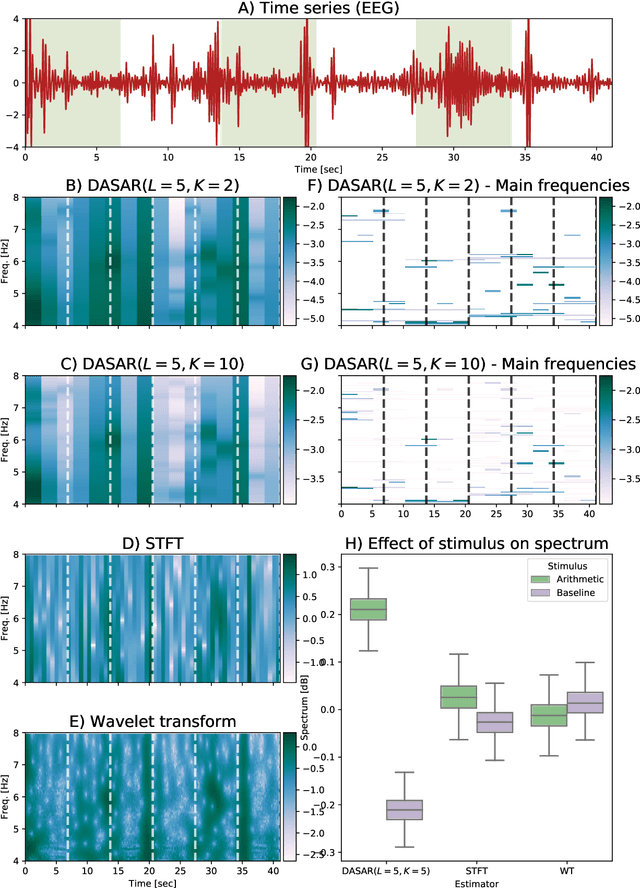
This paper introduces a new time-frequency representation method for biomedical signals: the dyadic aggregated autoregressive (DASAR) model. Signals, such as electroencephalograms (EEGs) and functional near-infrared spectroscopy (fNIRS), exhibit physiological information through time-evolving spectrum components at specific frequency intervals: 0-50 Hz (EEG) or 0-150 mHz (fNIRS). Spectrotemporal features in signals are conventionally estimated using short-time Fourier transform (STFT) and wavelet transform (WT). However, both methods may not offer the most robust or compact representation despite their widespread use in biomedical contexts. The presented method, DASAR, improves precise frequency identification and tracking of interpretable frequency components with a parsimonious set of parameters. DASAR achieves these characteristics by assuming that the biomedical time-varying spectrum comprises several independent stochastic oscillators with (piecewise) time-varying frequencies. Local stationarity can be assumed within dyadic subdivisions of the recordings, while the stochastic oscillators can be modeled with an aggregation of second-order autoregressive models (ASAR). DASAR can provide a more accurate representation of the (highly contrasted) EEG and fNIRS frequency ranges by increasing the estimation accuracy in user-defined spectrum region of interest (SROI). A mental arithmetic experiment on a hybrid EEG-fNIRS was conducted to assess the efficiency of the method. Our proposed technique, STFT, and WT were applied on both biomedical signals to discover potential oscillators that improve the discrimination between the task condition and its baseline. The results show that DASAR provided the highest spectrum differentiation and it was the only method that could identify Mayer waves as narrow-band artifacts at 97.4-97.5 mHz.
Attention-based Domain Adaptation for Time Series Forecasting
Feb 17, 2021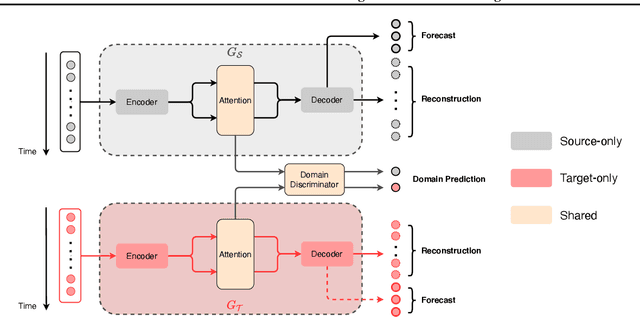
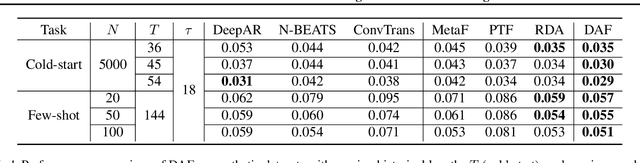

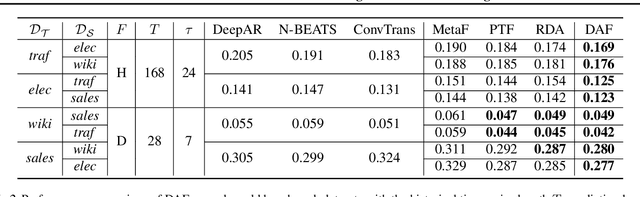
Recent years have witnessed deep neural networks gaining increasing popularity in the field of time series forecasting. A primary reason of their success is their ability to effectively capture complex temporal dynamics across multiple related time series. However, the advantages of these deep forecasters only start to emerge in the presence of a sufficient amount of data. This poses a challenge for typical forecasting problems in practice, where one either has a small number of time series, or limited observations per time series, or both. To cope with the issue of data scarcity, we propose a novel domain adaptation framework, Domain Adaptation Forecaster (DAF), that leverages the statistical strengths from another relevant domain with abundant data samples (source) to improve the performance on the domain of interest with limited data (target). In particular, we propose an attention-based shared module with a domain discriminator across domains as well as private modules for individual domains. This allows us to jointly train the source and target domains by generating domain-invariant latent features while retraining domain-specific features. Extensive experiments on various domains demonstrate that our proposed method outperforms state-of-the-art baselines on synthetic and real-world datasets.
N$^2$M$^2$: Learning Navigation for Arbitrary Mobile Manipulation Motions in Unseen and Dynamic Environments
Jun 17, 2022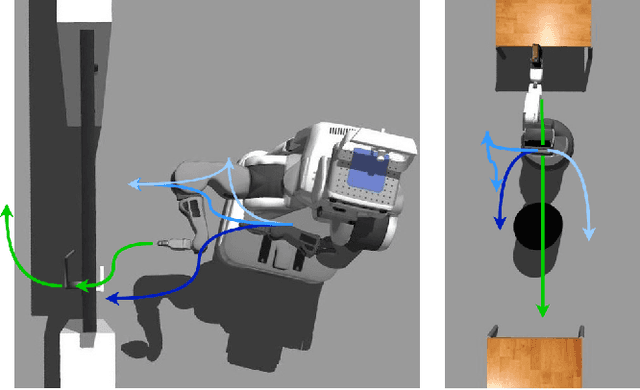
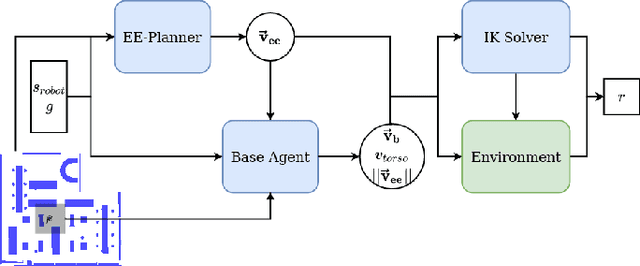


Despite its importance in both industrial and service robotics, mobile manipulation remains a significant challenge as it requires a seamless integration of end-effector trajectory generation with navigation skills as well as reasoning over long-horizons. Existing methods struggle to control the large configuration space, and to navigate dynamic and unknown environments. In previous work, we proposed to decompose mobile manipulation tasks into a simplified motion generator for the end-effector in task space and a trained reinforcement learning agent for the mobile base to account for kinematic feasibility of the motion. In this work, we introduce Neural Navigation for Mobile Manipulation (N$^2$M$^2$) which extends this decomposition to complex obstacle environments and enables it to tackle a broad range of tasks in real world settings. The resulting approach can perform unseen, long-horizon tasks in unexplored environments while instantly reacting to dynamic obstacles and environmental changes. At the same time, it provides a simple way to define new mobile manipulation tasks. We demonstrate the capabilities of our proposed approach in extensive simulation and real-world experiments on multiple kinematically diverse mobile manipulators. Code and videos are publicly available at http://mobile-rl.cs.uni-freiburg.de.
What Makes A Good Fisherman? Linear Regression under Self-Selection Bias
May 06, 2022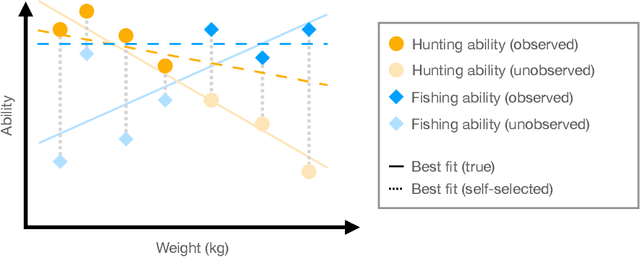
In the classical setting of self-selection, the goal is to learn $k$ models, simultaneously from observations $(x^{(i)}, y^{(i)})$ where $y^{(i)}$ is the output of one of $k$ underlying models on input $x^{(i)}$. In contrast to mixture models, where we observe the output of a randomly selected model, here the observed model depends on the outputs themselves, and is determined by some known selection criterion. For example, we might observe the highest output, the smallest output, or the median output of the $k$ models. In known-index self-selection, the identity of the observed model output is observable; in unknown-index self-selection, it is not. Self-selection has a long history in Econometrics and applications in various theoretical and applied fields, including treatment effect estimation, imitation learning, learning from strategically reported data, and learning from markets at disequilibrium. In this work, we present the first computationally and statistically efficient estimation algorithms for the most standard setting of this problem where the models are linear. In the known-index case, we require poly$(1/\varepsilon, k, d)$ sample and time complexity to estimate all model parameters to accuracy $\varepsilon$ in $d$ dimensions, and can accommodate quite general selection criteria. In the more challenging unknown-index case, even the identifiability of the linear models (from infinitely many samples) was not known. We show three results in this case for the commonly studied $\max$ self-selection criterion: (1) we show that the linear models are indeed identifiable, (2) for general $k$ we provide an algorithm with poly$(d) \exp(\text{poly}(k))$ sample and time complexity to estimate the regression parameters up to error $1/\text{poly}(k)$, and (3) for $k = 2$ we provide an algorithm for any error $\varepsilon$ and poly$(d, 1/\varepsilon)$ sample and time complexity.
Minimum projective linearizations of trees in linear time
Feb 17, 2021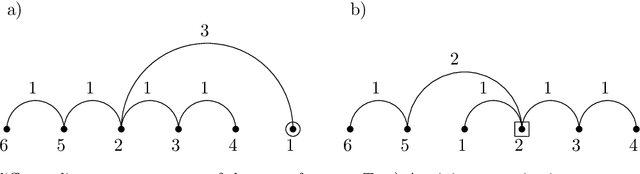

The minimum linear arrangement problem (MLA) consists of finding a mapping $\pi$ from vertices of a graph to integers that minimizes $\sum_{uv\in E}|\pi(u) - \pi(v)|$. For trees, various algorithms are available to solve the problem in polynomial time; the best known runs in subquadratic time in $n=|V|$. There exist variants of the MLA in which the arrangements are constrained to certain classes of projectivity. Iordanskii, and later Hochberg and Stallmann (HS), put forward $O(n)$-time algorithms that solve the problem when arrangements are constrained to be planar. We also consider linear arrangements of rooted trees that are constrained to be projective. Gildea and Temperley (GT) sketched an algorithm for the projectivity constraint which, as they claimed, runs in $O(n)$ but did not provide any justification of its cost. In contrast, Park and Levy claimed that GT's algorithm runs in $O(n \log d_{max})$ where $d_{max}$ is the maximum degree but did not provide sufficient detail. Here we correct an error in HS's algorithm for the planar case, show its relationship with the projective case, and derive an algorithm for the projective case that runs undoubtlessly in $O(n)$-time.
Depression Diagnosis and Forecast based on Mobile Phone Sensor Data
May 10, 2022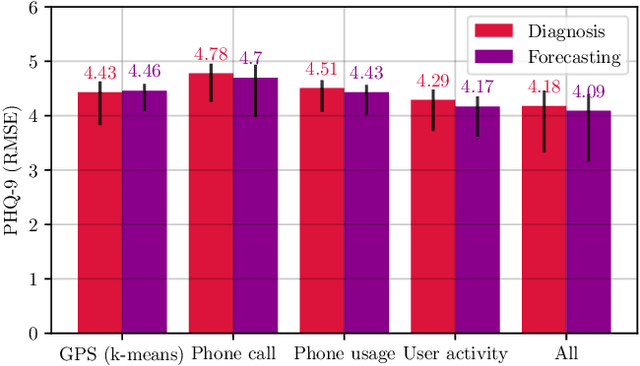
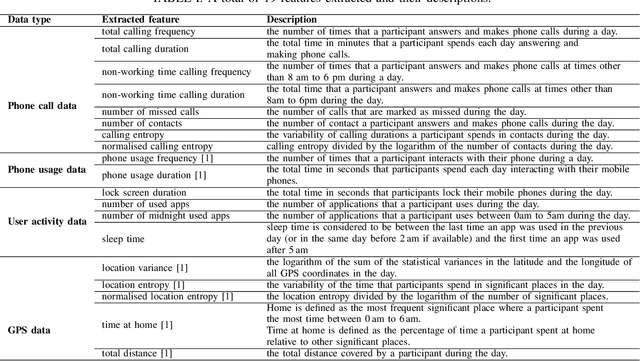

Previous studies have shown the correlation between sensor data collected from mobile phones and human depression states. Compared to the traditional self-assessment questionnaires, the passive data collected from mobile phones is easier to access and less time-consuming. In particular, passive mobile phone data can be collected on a flexible time interval, thus detecting moment-by-moment psychological changes and helping achieve earlier interventions. Moreover, while previous studies mainly focused on depression diagnosis using mobile phone data, depression forecasting has not received sufficient attention. In this work, we extract four types of passive features from mobile phone data, including phone call, phone usage, user activity, and GPS features. We implement a long short-term memory (LSTM) network in a subject-independent 10-fold cross-validation setup to model both a diagnostic and a forecasting tasks. Experimental results show that the forecasting task achieves comparable results with the diagnostic task, which indicates the possibility of forecasting depression from mobile phone sensor data. Our model achieves an accuracy of 77.0 % for major depression forecasting (binary), an accuracy of 53.7 % for depression severity forecasting (5 classes), and a best RMSE score of 4.094 (PHQ-9, range from 0 to 27).