 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pick up the PACE: Fast and Simple Domain Adaptation via Ensemble Pseudo-Labeling
May 26, 2022
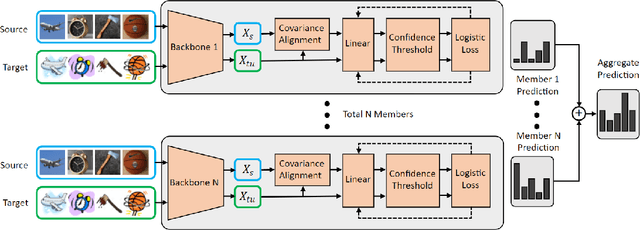
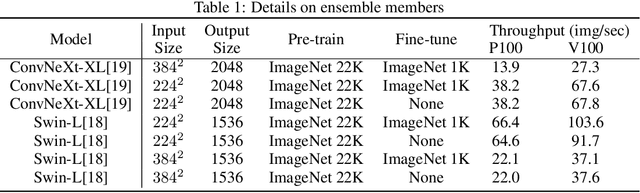
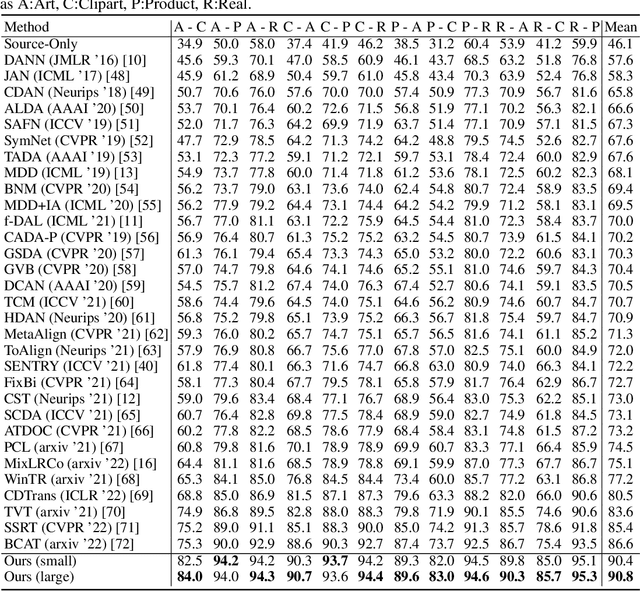
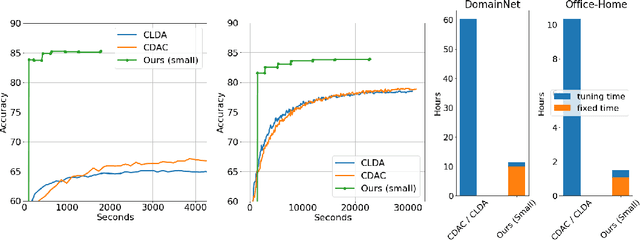
Domain Adaptation (DA) has received widespread attention from deep learning researchers in recent years because of its potential to improve test accuracy with out-of-distribution labeled data. Most state-of-the-art DA algorithms require an extensive amount of hyperparameter tuning and are computationally intensive due to the large batch sizes required. In this work, we propose a fast and simple DA method consisting of three stages: (1) domain alignment by covariance matching, (2) pseudo-labeling, and (3) ensembling. We call this method $\textbf{PACE}$, for $\textbf{P}$seudo-labels, $\textbf{A}$lignment of $\textbf{C}$ovariances, and $\textbf{E}$nsembles. PACE is trained on top of fixed features extracted from an ensemble of modern pretrained backbones. PACE exceeds previous state-of-the-art by $\textbf{5 - 10 \%}$ on most benchmark adaptation tasks without training a neural network. PACE reduces training time and hyperparameter tuning time by $82\%$ and $97\%$, respectively, when compared to state-of-the-art DA methods. Code is released here: https://github.com/Chris210634/PACE-Domain-Adaptation
Test-Time Personalization with a Transformer for Human Pose Estimation
Jul 05, 2021
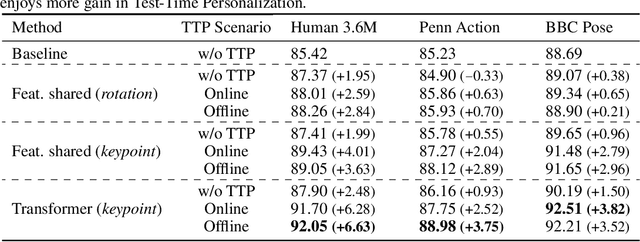
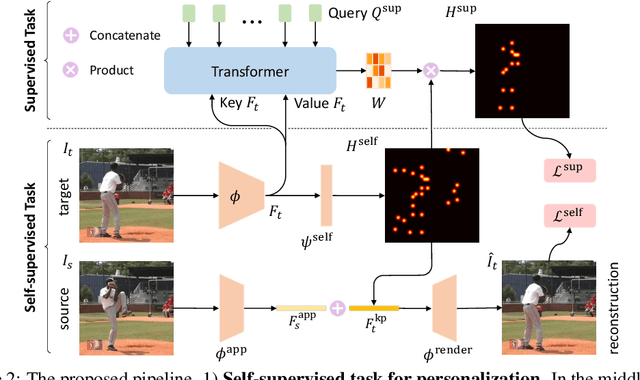
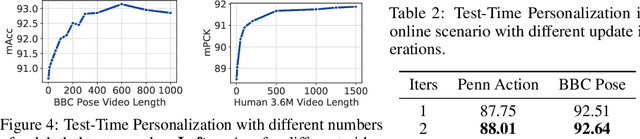
We propose to personalize a human pose estimator given a set of test images of a person without using any manual annotations. While there is a significant advancement in human pose estimation, it is still very challenging for a model to generalize to different unknown environments and unseen persons. Instead of using a fixed model for every test case, we adapt our pose estimator during test time to exploit person-specific information. We first train our model on diverse data with both a supervised and a self-supervised pose estimation objectives jointly. We use a Transformer model to build a transformation between the self-supervised keypoints and the supervised keypoints. During test time, we personalize and adapt our model by fine-tuning with the self-supervised objective. The pose is then improved by transforming the updated self-supervised keypoints. We experiment with multiple datasets and show significant improvements on pose estimations with our self-supervised personalization.
Open challenges for Machine Learning based Early Decision-Making research
Apr 27, 2022
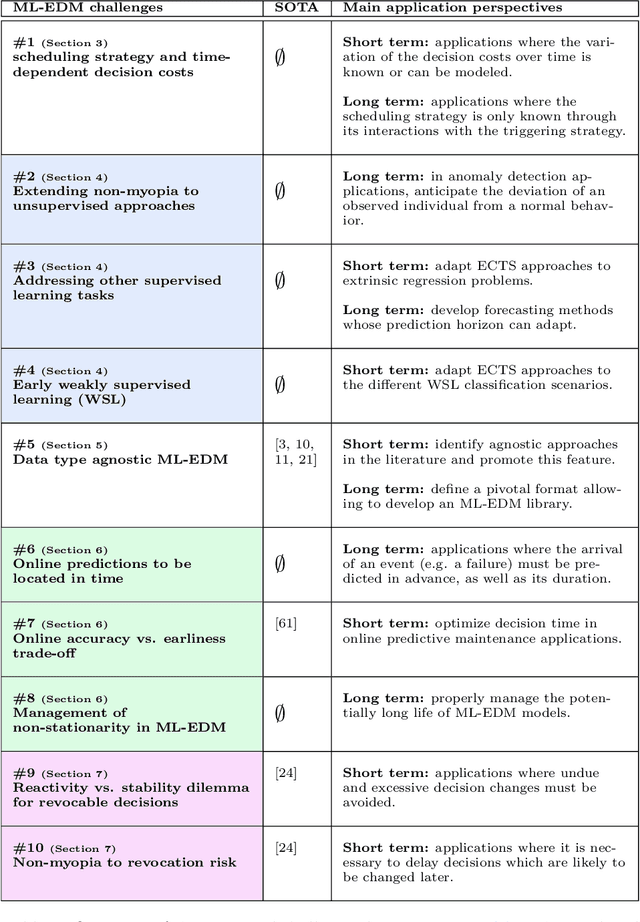
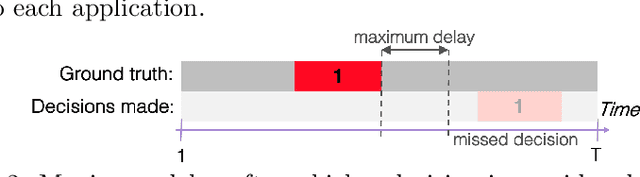
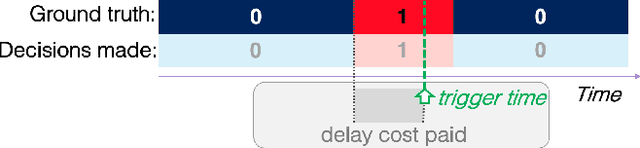
More and more applications require early decisions, i.e. taken as soon as possible from partially observed data. However, the later a decision is made, the more its accuracy tends to improve, since the description of the problem to hand is enriched over time. Such a compromise between the earliness and the accuracy of decisions has been particularly studied in the field of Early Time Series Classification. This paper introduces a more general problem, called Machine Learning based Early Decision Making (ML-EDM), which consists in optimizing the decision times of models in a wide range of settings where data is collected over time. After defining the ML-EDM problem, ten challenges are identified and proposed to the scientific community to further research in this area. These challenges open important application perspectives, discussed in this paper.
Surround-View Cameras based Holistic Visual Perception for Automated Driving
Jun 11, 2022
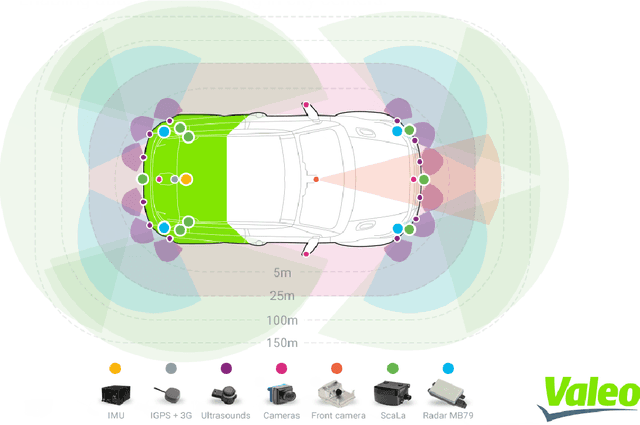


The formation of eyes led to the big bang of evolution. The dynamics changed from a primitive organism waiting for the food to come into contact for eating food being sought after by visual sensors. The human eye is one of the most sophisticated developments of evolution, but it still has defects. Humans have evolved a biological perception algorithm capable of driving cars, operating machinery, piloting aircraft, and navigating ships over millions of years. Automating these capabilities for computers is critical for various applications, including self-driving cars, augmented reality, and architectural surveying. Near-field visual perception in the context of self-driving cars can perceive the environment in a range of $0-10$ meters and 360{\deg} coverage around the vehicle. It is a critical decision-making component in the development of safer automated driving. Recent advances in computer vision and deep learning, in conjunction with high-quality sensors such as cameras and LiDARs, have fueled mature visual perception solutions. Until now, far-field perception has been the primary focus. Another significant issue is the limited processing power available for developing real-time applications. Because of this bottleneck, there is frequently a trade-off between performance and run-time efficiency. We concentrate on the following issues in order to address them: 1) Developing near-field perception algorithms with high performance and low computational complexity for various visual perception tasks such as geometric and semantic tasks using convolutional neural networks. 2) Using Multi-Task Learning to overcome computational bottlenecks by sharing initial convolutional layers between tasks and developing optimization strategies that balance tasks.
Grad-GradaGrad? A Non-Monotone Adaptive Stochastic Gradient Method
Jun 14, 2022
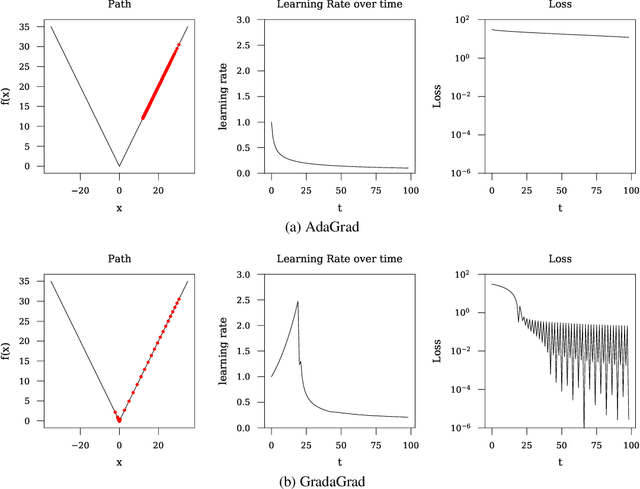
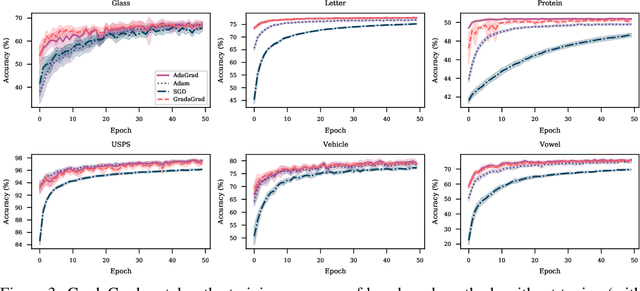
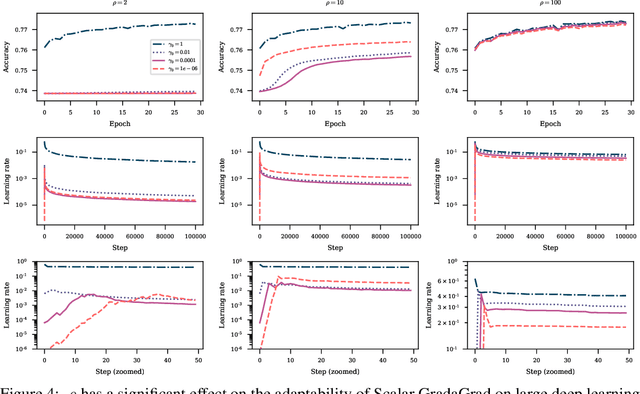
The classical AdaGrad method adapts the learning rate by dividing by the square root of a sum of squared gradients. Because this sum on the denominator is increasing, the method can only decrease step sizes over time, and requires a learning rate scaling hyper-parameter to be carefully tuned. To overcome this restriction, we introduce GradaGrad, a method in the same family that naturally grows or shrinks the learning rate based on a different accumulation in the denominator, one that can both increase and decrease. We show that it obeys a similar convergence rate as AdaGrad and demonstrate its non-monotone adaptation capability with experiments.
Identity Testing for High-Dimensional Distributions via Entropy Tensorization
Jul 19, 2022
We present improved algorithms and matching statistical and computational lower bounds for the problem of identity testing $n$-dimensional distributions. In the identity testing problem, we are given as input an explicit distribution $\mu$, an $\varepsilon>0$, and access to a sampling oracle for a hidden distribution $\pi$. The goal is to distinguish whether the two distributions $\mu$ and $\pi$ are identical or are at least $\varepsilon$-far apart. When there is only access to full samples from the hidden distribution $\pi$, it is known that exponentially many samples may be needed, and hence previous works have studied identity testing with additional access to various conditional sampling oracles. We consider here a significantly weaker conditional sampling oracle, called the Coordinate Oracle, and provide a fairly complete computational and statistical characterization of the identity testing problem in this new model. We prove that if an analytic property known as approximate tensorization of entropy holds for the visible distribution $\mu$, then there is an efficient identity testing algorithm for any hidden $\pi$ that uses $\tilde{O}(n/\varepsilon)$ queries to the Coordinate Oracle. Approximate tensorization of entropy is a classical tool for proving optimal mixing time bounds of Markov chains for high-dimensional distributions, and recently has been established for many families of distributions via spectral independence. We complement our algorithmic result for identity testing with a matching $\Omega(n/\varepsilon)$ statistical lower bound for the number of queries under the Coordinate Oracle. We also prove a computational phase transition: for sparse antiferromagnetic Ising models over $\{+1,-1\}^n$, in the regime where approximate tensorization of entropy fails, there is no efficient identity testing algorithm unless RP=NP.
FCN-Pose: A Pruned and Quantized CNN for Robot Pose Estimation for Constrained Devices
May 26, 2022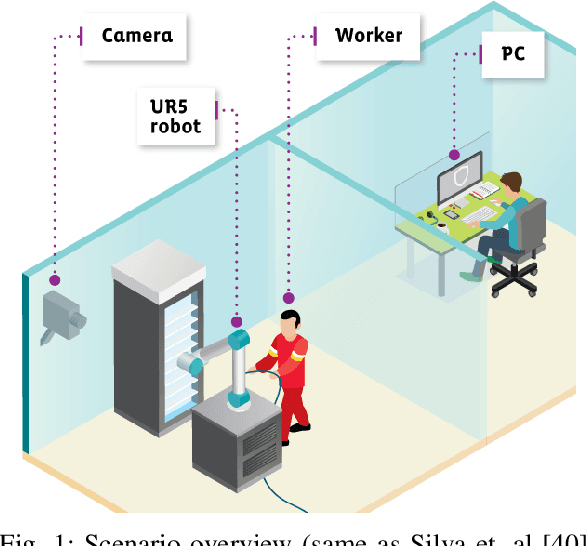
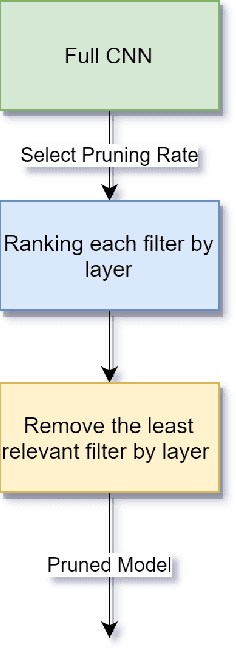
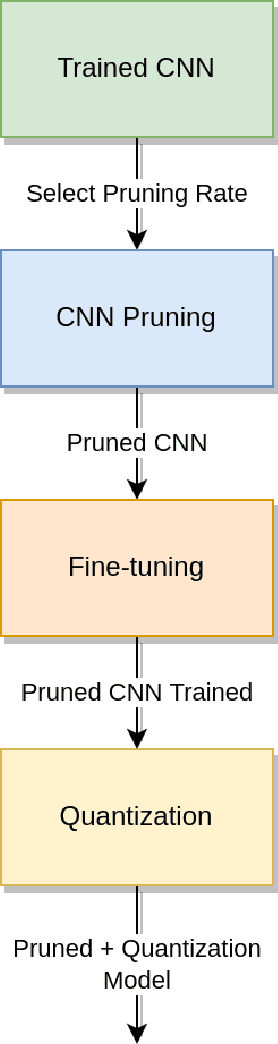
IoT devices suffer from resource limitations, such as processor, RAM, and disc storage. These limitations become more evident when handling demanding applications, such as deep learning, well-known for their heavy computational requirements. A case in point is robot pose estimation, an application that predicts the critical points of the desired image object. One way to mitigate processing and storage problems is compressing that deep learning application. This paper proposes a new CNN for the pose estimation while applying the compression techniques of pruning and quantization to reduce his demands and improve the response time. While the pruning process reduces the total number of parameters required for inference, quantization decreases the precision of the floating-point. We run the approach using a pose estimation task for a robotic arm and compare the results in a high-end device and a constrained device. As metrics, we consider the number of Floating-point Operations Per Second(FLOPS), the total of mathematical computations, the calculation of parameters, the inference time, and the number of video frames processed per second. In addition, we undertake a qualitative evaluation where we compare the output image predicted for each pruned network with the corresponding original one. We reduce the originally proposed network to a 70% pruning rate, implying an 88.86% reduction in parameters, 94.45% reduction in FLOPS, and for the disc storage, we reduced the requirement in 70% while increasing error by a mere $1\%$. With regard input image processing, this metric increases from 11.71 FPS to 41.9 FPS for the Desktop case. When using the constrained device, image processing augmented from 2.86 FPS to 10.04 FPS. The higher processing rate of image frames achieved by the proposed approach allows a much shorter response time.
Self-supervised Vector-Quantization in Visual SLAM using Deep Convolutional Autoencoders
Jul 14, 2022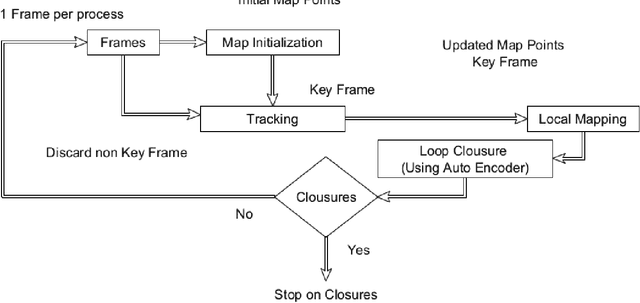
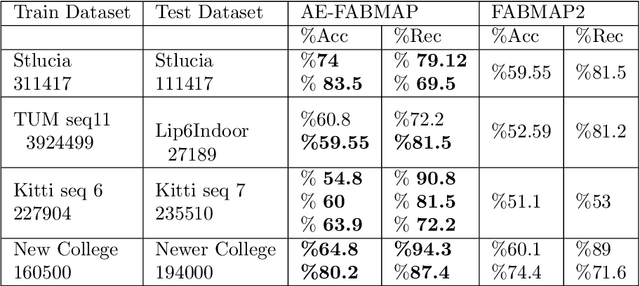


In this paper, we introduce AE-FABMAP, a new self-supervised bag of words-based SLAM method. We also present AE-ORB-SLAM, a modified version of the current state of the art BoW-based path planning algorithm. That is, we have used a deep convolutional autoencoder to find loop closures. In the context of bag of words visual SLAM, vector quantization (VQ) is considered as the most time-consuming part of the SLAM procedure, which is usually performed in the offline phase of the SLAM algorithm using unsupervised algorithms such as Kmeans++. We have addressed the loop closure detection part of the BoW-based SLAM methods in a self-supervised manner, by integrating an autoencoder for doing vector quantization. This approach can increase the accuracy of large-scale SLAM, where plenty of unlabeled data is available. The main advantage of using a self-supervised is that it can help reducing the amount of labeling. Furthermore, experiments show that autoencoders are far more efficient than semi-supervised methods like graph convolutional neural networks, in terms of speed and memory consumption. We integrated this method into the state of the art long range appearance based visual bag of word SLAM, FABMAP2, also in ORB-SLAM. Experiments demonstrate the superiority of this approach in indoor and outdoor datasets over regular FABMAP2 in all cases, and it achieves higher accuracy in loop closure detection and trajectory generation.
Communication Acceleration of Local Gradient Methods via an Accelerated Primal-Dual Algorithm with Inexact Prox
Jul 08, 2022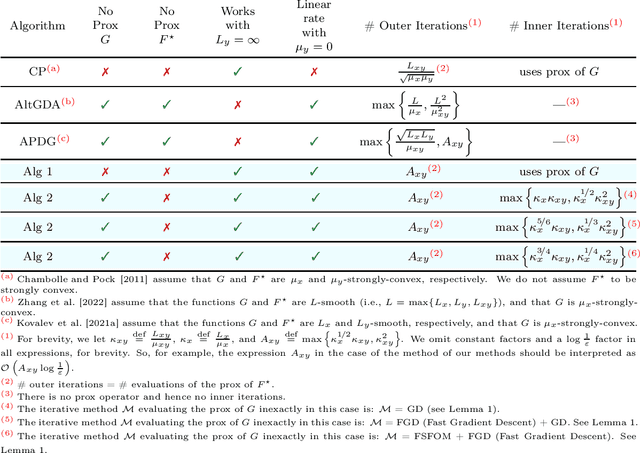
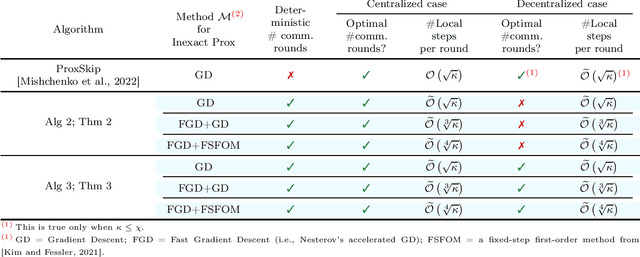
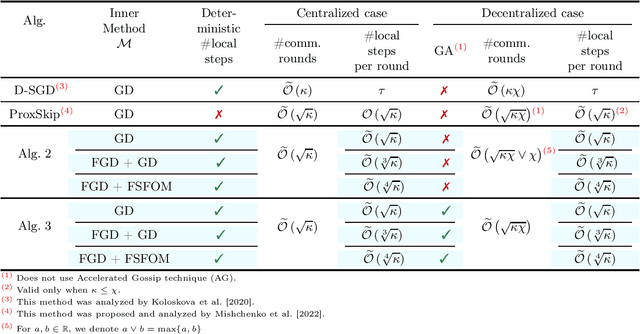
Inspired by a recent breakthrough of Mishchenko et al (2022), who for the first time showed that local gradient steps can lead to provable communication acceleration, we propose an alternative algorithm which obtains the same communication acceleration as their method (ProxSkip). Our approach is very different, however: it is based on the celebrated method of Chambolle and Pock (2011), with several nontrivial modifications: i) we allow for an inexact computation of the prox operator of a certain smooth strongly convex function via a suitable gradient-based method (e.g., GD, Fast GD or FSFOM), ii) we perform a careful modification of the dual update step in order to retain linear convergence. Our general results offer the new state-of-the-art rates for the class of strongly convex-concave saddle-point problems with bilinear coupling characterized by the absence of smoothness in the dual function. When applied to federated learning, we obtain a theoretically better alternative to ProxSkip: our method requires fewer local steps ($O(\kappa^{1/3})$ or $O(\kappa^{1/4})$, compared to $O(\kappa^{1/2})$ of ProxSkip), and performs a deterministic number of local steps instead. Like ProxSkip, our method can be applied to optimization over a connected network, and we obtain theoretical improvements here as well.
Active Learning-based Isolation Forest (ALIF): Enhancing Anomaly Detection in Decision Support Systems
Jul 08, 2022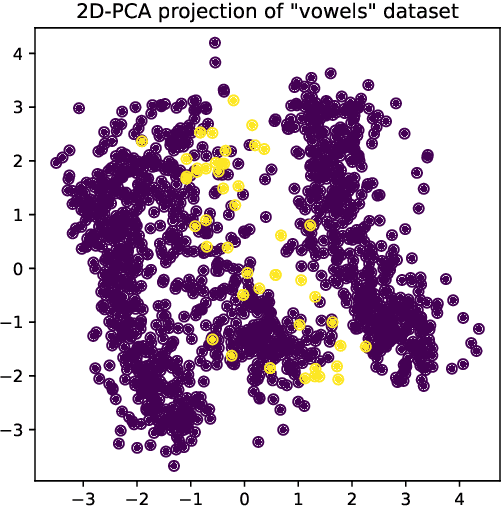

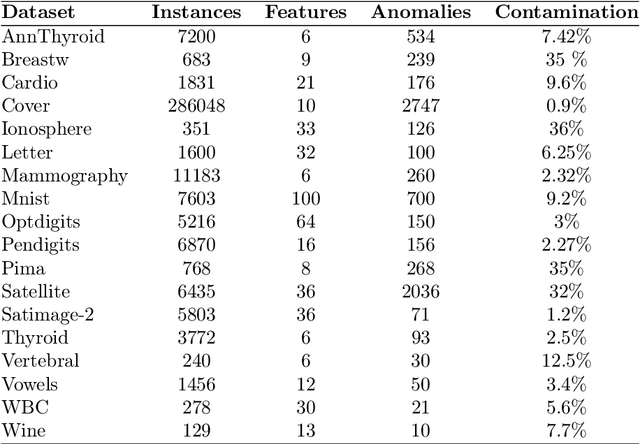
The detection of anomalous behaviours is an emerging need in many applications, particularly in contexts where security and reliability are critical aspects. While the definition of anomaly strictly depends on the domain framework, it is often impractical or too time consuming to obtain a fully labelled dataset. The use of unsupervised models to overcome the lack of labels often fails to catch domain specific anomalies as they rely on general definitions of outlier. This paper suggests a new active learning based approach, ALIF, to solve this problem by reducing the number of required labels and tuning the detector towards the definition of anomaly provided by the user. The proposed approach is particularly appealing in the presence of a Decision Support System (DSS), a case that is increasingly popular in real-world scenarios. While it is common that DSS embedded with anomaly detection capabilities rely on unsupervised models, they don't have a way to improve their performance: ALIF is able to enhance the capabilities of DSS by exploiting the user feedback during common operations. ALIF is a lightweight modification of the popular Isolation Forest that proved superior performances with respect to other state-of-art algorithms in a multitude of real anomaly detection datasets.